一种基于非易失性内存文件系统的元数据管理方法与流程
本发明属于计算机存储器管理的技术领域,具体涉及考虑非易失性内存磨损均衡的文件系统的元数据管理方法。
背景技术:
随着新型非易失性存储器的出现,企业界和学术界提出将存储密度大、读写速度快、可按字节寻址和抗震动的非易失性内存制作为持久性的数据存储设备,称为存储级内存(storageclassmemory,简称scm)。
为了管理存储级内存,已经设计出多种内存文件系统。例如ibm设计的pmfs,“systemsoftwareforpersistentmemory,”inproc.9thacmeuro.conf.comput.syst.,pp15:1—15:15,2014,isbn:978-1-4503-2704-6(“面向持久性内存的系统软件”,第9届美国计算机学会欧洲计算机系统会议,第15篇1到15页,2014年,isbn:978-1-4503-2704-6)。重庆大学自主研发的simfs,“designinganefficientpersistentin-memoryfilesystem”,2015ieeenon-volatilememorysystemandapplicationssymposium,pp1-6,2015,doi:10.1109/nvmsa.2015.7304365(“高效持续性内存文件系统设计”,2015年电气和电子工程师协会非易失性内存系统及应用研讨会,第1-6页,doi:10.1109/nvmsa.2015.7304365)。
虽然已经设计出了多种内存文件系统用于管理存储级内存,但非易失性内存还存在一些挑战。非易失性内存面临的主要挑战是每一个存储单元只能经受有限次写操作(105~108次),在超过此数目之后,由于频繁的膨胀和收缩,加热电阻会发生脱落,导致存储单元再也无法改变相态。解决非易失性内存耐久性问题的主要办法是采用磨损均衡来协调写地址的不平衡性,避免局部存储单元由于更为频繁的写操作而率先磨损失效。
由于非易失性内存写次数有限制的原因,对写频繁的操作,比如元数据的修改必须实现磨损均衡。而常规的元数据管理方式是:固定一块区域用于记录所有元数据的信息,这种方法的最大缺点是在反复的修改元数据时,容易对非易失性内存造成损毁。因此,常规的元数据管理方式不能适用于内存文件系统。
现有技术中,文件索引节点inode元数据管理方法有两种:
第一种是树形结构,这种方式下文件索引节点的存储管理都很灵活,而且便于扩张,但是这种方法查找速度慢而且存储空间开销大。例如:bpfs用树形结构组织inode,使得inode的分配、回收和物理空间的选择非常灵活,扩展性好,但是同时也使得inode的检索更加复杂,查询inode耗时较多,并且诸多中间节点会造成较大的存储空间开销。
第二种是数组结构,将所有文件索引节点存放在固定区域,而且文件索引节点大小为定值,因此可以通过文件索引节点号直接定位文件索引节点的地址,这种方法可以迅速找到文件的文件索引节点,但是扩展性较差,需要固定文件索引节点数量,即固定系统支持的文件总量;且固定一块区域极易造成磨损。
例如:pmfs的日志管理方式就是在非易失性内存上利用连续的物理区域来保证pmfs文件系统的元数据一致性,它没有实现文件数据写的一致性。由于它的元数据固定在这块物理区域,每次写都在这块物理地址区域,容易造成这块物理区域磨损,即不能实现这块区域的磨损均衡。
本说明书中,常用术语的说明如下:
mmumemorymanagementunit存储器管理单元,
inoinode的结点号,
映射表查找inode物理位置的索引表,
m指每个物理页写的counter最大上限。
技术实现要素:
针对现有技术存在的问题,本发明所要解决的技术问题就是提供一种基于非易失性内存文件系统的元数据管理方法,它能够保证非易失性内存写的磨损均衡,还能够快速访问到元数据。
要解决上述技术问题,本发明包括以下步骤:
步骤1、把文件索引节点以数组形式组织为一个索引节点区,索引节点区的每个文件索引节点都有一个固定的编号;
步骤2、依照系统页表的格式给文件索引节点区建立一个映射表,映射表的最高级指针存放在文件系统的超级块中;
步骤3、在操作系统中为文件索引节点区保留一段第一虚拟地址空间,每个文件索引节点通过ino号和索引节点区的起始虚拟地址得到自己对应的虚拟地址;在挂载文件系统时,操作系统解析第一虚拟地址空间对应的系统页表第一表项;
步骤4、查看文件系统的超级块,把文件系统超级块中保存的索引节点区的映射表的最高级指针插入到第一表项,建立起索引节点区的虚拟地址空间到物理地址空间的映射关系。
在上述步骤4中,包括以下步骤:
步骤1)、根据inode的ino号和索引节点区的起始虚拟地址,通过硬件mmu和映射表将inode的虚拟地址转换为物理地址,从而找到该inode所在的物理页并在物理页上修改inode信息,同时给该inode所在的物理页的counter值加1;
步骤2)、检查counter,如果counter值超过定值m值,则申请一个新页,将超过counter值的页的信息拷贝到新页上,利用cpu提供的原子操作,在映射表里用新页替换掉counter值超过m的页;
步骤3)、释放掉超过counter值的物理页。
优选地,还包括步骤5、在挂载文件系统时,初始化一个inode空闲链表,将所有没有使用的inode的ino放到链表上去,并将inode链表的表头存储到文件系统超级块中。当创建文件时,在超级块中取出inode链表,并从空闲链表的头部取出一个ino,更新保存在超级块中的inode链表信息。当回收inode时,将inode的ino挂到inode链表的尾部。
与现有技术相比,本发明的元数据管理方法没有将inode的数据存储在固定的物理区域,而是通过进程页表的方式管理inode。在内核虚拟地址空间中预留一段给索引节点区,在文件系统的超级块中记录这段起始虚拟地址。挂载文件系统时,创建并初始化一个映射表,其形式与文件系统的页表相同。把映射表插入到索引节点区的内核虚拟地址空间对应的内核页表中,查看文件系统的超级块,把文件系统的超级块中保存的索引节点区的映射表的最高级指针插入到第一表项,从而建立起索引节点区的虚拟地址空间到物理地址空间的映射关系。
本发明的技术效果是:
1、通过counter值,动态分配页和映射表的管理机制,实现元数据的写磨损均衡。
本发明的元数据管理方法把索引节点区组织为一个连续的虚拟空间,而真正存放索引节点的物理内存却可以任意地散布在非易失性内存设备中。用“映射表”维护虚拟空间到物理空间的映射关系。所以,一个索引节点的虚拟地址不必改变,却可以任意改变它的物理地址,只要修改它对应的映射表就可以。基于这种构思,索引节点区就不必存储在固定的物理区域。这样做的目的是避免反复在同一块区域修改索引节点的信息而导致写磨损。
本发明实现磨损均衡的具体方式有:
第1)、利用映射表存储索引节点所在的物理页地址。当需要修改索引节点信息时,执行如下步骤:1)利用索引节点号和存储在超级块里的起始虚拟地址计算该索引节点的虚拟地址;2)然后利用处理已有的地址转换硬件mmu和索引节点的虚拟地址读取索引节点的物理内存。通过这种方式,可以保证索引节点在逻辑上是固定的,但实际的物理存储位置却可以任意改变,从而实现磨损均衡。
第2)、当索引节点所在的物理页的counter达到m,则申请一个新页,将counter超过m的物理页的信息拷贝到新页上,然后用新页的物理地址替换couner超过m的物理页的索引。这个替换操作可以利用处理器提供的原子操作高速地原子性地完成。
第3)、当分配一个新的索引节点时,如果该索引节点所在的物理页不存在,则从空闲空间申请一个写次数最少的页,从而实现非易失性存储整体的磨损均衡。
2、采用逻辑数组方式组织文件索引节点,即在内核预留一段连续虚拟地址空间索引节点区,每个inode通过ino号和索引节点区的起始虚拟地址得到自己对应的虚拟地址,然后通过硬件mmu和映射表将虚拟地址转化为物理地址,从而快速的找到inode。充分利用了硬件机制来快速找到inode。
附图说明
本发明的附图说明如下:
图1为系统页表和索引节点映射表的结构图;
图2为本发明的流程图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明:
本发明包括以下步骤:
步骤1、把文件索引节点以数组形式组织为一个索引节点区,索引节点区的每个文件索引节点都有一个固定的编号;
步骤2、定义操作系统规定的进程的页表为“系统页表”。依照系统页表的格式给索引节点区建立一个映射表,映射表的最高级指针存放在文件系统的超级块中;
系统页表的一个例子如图1所示。图1左侧是linux系统的页表。它共有四层,分别是页全局目录(pgd)、页上级目录(pud)、页中级目录(pmd)和页表项(pte)。通常情况下,每级页表都由一个或多个页面组成。每个页面包含有512个8字节的表项,前三级中每个表项存放的都是下一级页表某个物理页的起始物理地址,第四级pte页表项中保存的是一个文件数据页的起始物理地址。图1右侧是本发明提出的索引节点映射表。超级块中存有指向inode页表的指针。该三层文件页表也分为pud、pmd和pte三层。上级页表项存放的是下级页表页面的起始物理地址,pte的页表项存放的是文件数据页的起始物理地址。基于这种结构,文件可以获得连续的虚拟地址空间,而真正的文件数据却可以分散存储在物理内存中。
步骤3、在操作系统中为索引节点区保留一段第一虚拟地址空间,每个文件索引节点通过ino号和索引节点区的起始虚拟地址得到自己对应的虚拟地址;在挂载文件系统时,操作系统解析第一虚拟地址空间对应的系统页表第一表项;
操作系统获取系统页表最高级(如pgd)的页面的指针。利用虚拟地址的对应字段计算出该虚拟地址所属的下一级页表(如pud)的页表项在最高级页表中的偏移。例如linux现在的虚拟地址中用48位索引一个物理页。这48位分为5段,第一段(9位)表示虚拟地址对应的pud页面的指针在pgd页面里的存放位置。如第一段的值是252,就表示该虚拟地址对应的pud页面的指针存在pgd页面的第252项。依次类推,直到找到索引节点的映射表所需的页表的第一页表项。可以是第1级(pgd)、第2级(pud)、第3级(pmd)甚至第4级(pte)的一个页表项。
步骤4、查看文件系统的超级块,把超级块中保存的索引节点区的映射表的最高级指针插入到第一表项,建立起索引节点区的虚拟地址空间到物理地址空间的映射关系。
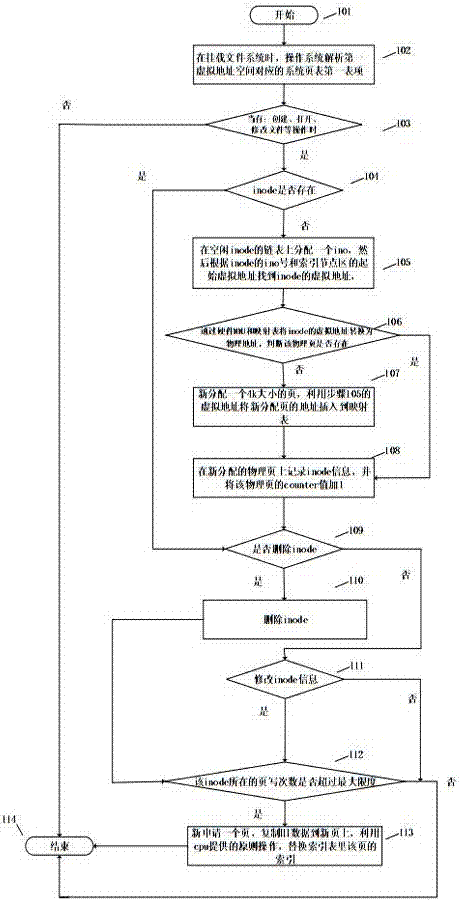
本发明的流程图如图2所示,该流程开始于步骤101,然后:
在步骤102,在挂载文件系统时,操作系统解析第一虚拟地址空间对应的系统页表第一表项;
在步骤103,当有创建、打开、修改文件操作的情况下,执行步骤104;否则执行步骤114。
在步骤104,判断inode是否存在,如果存在,则执行步骤109,否则执行步骤105;
在步骤105,在空闲inode的链表上分配一个ino号,根据inode的ino号和索引节点区的起始虚拟地址找到inode的虚拟地址,执行步骤106;
在步骤106,通过硬件mmu和映射表将inode的虚拟地址转换为物理地址,判断该物理页是否存在,如果存在,执行步骤108,否则执行步骤107;
在步骤107,新分配一个4k大小的页,利用步骤105的虚拟地址将新分配页的地址插入到映射表,然后执行步骤108;
在步骤108,在新分配的物理页上记录inode信息,并将该物理页的counter值加1,执行步骤109;
在步骤109,是否删除inode,如果是,执行110,否则执行步骤111;
在步骤110,删除inode,执行步骤112;
在步骤111,修改inode信息,如果修改则执行112,否则执行114;
在步骤112,该inode所在的页写次数是否超过最大限度,是,则执行步骤113,否则执行步骤114;
在步骤113,新申请一个页,复制旧数据到新页上,利用cpu提供的原则操作,替换索引表里该页的索引;
在步骤114,结束。
本发明的流程对文件索引节点inode的操作有三类:
1、分配inode:当创建文件时,需要为文件分配一个inode。
具体方法是:在空闲inode的链表上分配一个ino号,然后根据inode的ino号和索引节点区的起始虚拟地址找到inode的虚拟地址,然后利用硬件mmu和映射表将inode的虚拟地址转化为物理地址,通过物理地址找到inode所在的物理页。如果该物理页存在,则在该物理页上存储新分配的inode的信息,并给该物理页的counter值加1;检查counter,如果counter值超过定值m值,则申请一个新页,将超过counter值的页的信息拷贝到新页上。然后利用cpu提供的原子操作,用新页在映射表里替换掉counter值超过m的页。然后释放掉超过counter值的物理页。如果该inode所属的物理页不存在,则新分配一个物理页,存储新分配的inode,并给该物理页的counter值加1,同时在映射表里插入新分配的页的物理地址。
2、修改inode:修改inode的信息,比如:访问一个文件,或者修改了文件。
具体的方法是:通过索引节点区起始虚拟地址和ino号计算出inode的虚拟地址,通过硬件mmu和映射表将inode的虚拟地址转换为物理地址,从而找到该inode所在的物理页并在物理页上修改inode信息。同时给inode所在物理页的counter值加1,检查counter,如果counter值超过定值m值,则申请一个新页,将超过counter值的页的信息拷贝到新页上。然后利用cpu提供的原子操作,用新页在映射表里替换掉counter值超过m的页。然后释放掉超过counter值的物理页。
3、释放inode:当文件被删除时,需要释放掉该文件的inode,并回收ino。
具体方法是:将inode的ino号回收并存放到inode空闲链表上,然后在映射表里将inode对应的索引填充为0。
- 还没有人留言评论。精彩留言会获得点赞!