一种结构聚类的生成方法及系统与流程
本发明属于数据处理技术领域,尤其涉及一种结构聚类的生成方法及系统。
背景技术:
随着信息技术的快速发展,各种真实的网络所形成的图数据随处可见。例如社交网络、通信网络以及生物网络。每种网络中都包含对应的社区结构,发现这些隐含的社区结构在现实生活中意义重大并且有很多的应用。如在生物网络中,一个社区可能代表具有相同性质的分子。在社交网络中,一个社区可能代表着关系比较紧密的团体。
另外,随着硬件技术的发展,硬件在大多数应用上已经不是主要的瓶颈,尤其是各种高性能计算机的快速发展。如何利用这些高性能计算机设计高效的算法(高性能计算)已经吸引了众多学者的研究,尤其是对大数据的处理。这其中主要包括基于多台计算机的mapreduce算法和基于openmp以及mpi框架的多核算法的研究。
图的聚类是发现这些社区的一个重要的手段。在过去十年里,针对图的聚类,研究人员提出了大量的模型和相关的算法。向我们展示了一个图的聚类和社区的检测算法。在这些算法中,scan算法(structuralclusteringalgorithmonnetworks,图的结构聚类算法)是一个非常卓越的模型,并且在实际应用中取得了很好的效果。相对于其他的图的聚类算法,scan不仅能够找到图中的社区还能发现边界点(outliers)和桥结点(hubs)。
scan算法思想和基于密度聚类的dbcsan算法(density-basedspatialclusteringofapplicationswithnoise,基于密度的聚类算法)很相似。具体地说,scan算法首先定义了图中边的两个结点的结构相似性。如过一条边的结构相似性大于给定的阈值ε,就会保存它,若否则删除。最终,当与某个结点相关联的并且满足结构相似性的边的个数为设置的阈值k时,称该结点为一个核心点。然后该算法从该核心点出发,不断的扩展,从而得到其中一个聚类。从这个过程可以发现,在算法的执行过程中,需要计算这个图中所有边的结构相似性。在现实世界的网络中,一个图有上亿条边甚至超过十亿条边,处理如此大的图数据,现有技术采用的方法为使用基于多台机器的mapreduce算法实现。mapreduce主要是基于分布式存储的方式,让多台计算机共同完成一个庞大的任务,多台计算即处理同一事物,必然涉及到不同计算机之间的数据交换,同时,因为图的边的数量庞大,scan算法在大规模图数据中计算每条边的结构相似性时存在耗时的问题。
技术实现要素:
本发明所要解决的技术问题在于提供一种结构聚类的生成方法及系统,旨在解决现有scan算法在大规模图数据中计算每条边的结构相似性时存在耗时的问题。
本发明是这样实现的,一种结构聚类的生成方法,包括:
接收待处理的无向无权简单图,遍历所述无向无权简单图得到所有未处理的结点;
按照结构相似性并行算法判断当前未处理的结点是否为核心结点,若否,则判断下一未处理的结点是否为核心结点;
若是,则生成新的聚类并编号,并将所述当前未处理的结点的所有未处理且直接可达的邻居插入预置队列;
判断所述预置队列是否为空,若为空,则执行所述按照结构相似性并行算法判断当前未处理的结点是否为核心结点的步骤;
若不为空,则弹出所述预置队列的队首元素,将所述队首元素划分至所述新的聚类,并将所述队首元素的所有可达且未处理的邻居插入所述预置队列中;
判断所述无向无权简单图中是否存在未处理的结点,若存在,则执行所述按照结构相似性并行算法判断当前未处理的结点是否为核心结点的步骤,若不存在,则结束算法,得到目标聚类。
进一步地,分别以u和v表示所述无向无权简单图中的任意一条边的两个端点,则所述按照结构相似性并行算法判断当前未处理的结点是否为核心结点包括:
分别获取u和v的按照其邻居的结点编号排序的邻接链表及邻居结点;
分别以u和v的邻居结点的个数表示u和v的结点度数,计算u和v的结点度数之和,并以计算得到的结点度数之和表示以u和v为两个端点的边的度数;
计算得到所述无向无权简单图中所有边的度数和,将所述所有边的度数和按照预置等分点平均分成若干计算任务块,每一计算任务块对应每一计算进程,每一所述计算进程用于遍历每一条边的两个端点的邻接链表,以获取每一条边的两个端点的共同邻居的个数;
获取所有计算进程的编号,根据计算进程的编号分配计算任务块,以使所述计算进程根据所述计算任务块计算得到每一条边的两个端点的共同邻居的个数;
计算每一条边的两个端点的结构相似形,其中,以γ(v)表示v的邻居结点的个数,以γ(u)表示u的邻居结点的个数,以σ(u,v)表示以u和v为端点的边,则:
判断计算得出的结构相似性的值是否满足预置的结构相似性阈值,若满足,则获取结点v中结构相似性大于预置的结构相似性阈值的邻居个数;
若结点v大于预置的结构相似性阈值的邻居个数大于等于预置邻居个数值时,则判断v为核心结点。
进一步地,分别以u和v表示所述无向无权简单图中的任意一条边的两个端点,则所述按照结构相似性并行算法判断当前未处理的结点是否为核心结点包括:
获取所述无向无权简单图的所有的边,得到边集合;
按照预置切片大小将所述边集合分成等份的若干切片;
将切片分配给所有计算进程,以使所述计算进程计算所述切片内所有边的结构相似性;
判断计算得出的结构相似性的值是否满足预置的结构相似性阈值,若满足,则获取结点v中结构相似性大于预置的结构相似性阈值的邻居个数;
若结点v大于预置的结构相似性阈值的邻居个数大于等于预置邻居个数值时,则判断v为核心结点。
进一步地,所述将切片分配给所有计算进程,以使所述计算进程计算所述切片内所有边的结构相似性包括:
获取所有计算进程的运行状态;
将切片随机分配给运行状态为空闲的计算进程,以使所述计算进程计算所述切片内所有边的结构相似性;
当接收到计算进程发送的任务申请指令时,发送新的切片给对应的计算进程;
判断是否存在未计算的切片,若存在,则执行所述将切片随机分配给运行状态为空闲的计算进程的步骤,若不存在,则结束计算。
进一步地,所述将切片随机分配给运行状态为空闲的计算进程具体包括:
将切片和上锁指令发送给运行状态为空闲的计算进程,以使所述计算进程计算所述切片内所有边的结构相似性并进行上锁;
则所述当接收到计算进程发送的任务申请指令时,发送新的切片给对应的计算进程包括:
当接收到计算进程发送的任务申请指令时,发送解锁指令给发送任务申请指令的计算进程,以使所述发送任务申请指令的计算进程进行解锁;
接收所述发送任务申请指令的计算进程发送的解锁完毕信息,将新的切片和上锁指令发送给所述发送任务申请指令的计算进程,以使计算进程计算所述新的切片内所有边的结构相似性并重新上锁。
本发明还提供了一种结构聚类的生成系统,包括:
图像遍历单元,用于接收待处理的无向无权简单图,遍历所述无向无权简单图得到所有未处理的结点;
结点判断单元,用于按照结构相似性并行算法判断当前未处理的结点是否为核心结点,若否,则判断下一未处理的结点是否为核心结点,若是,则生成新的聚类并编号,并将所述当前未处理的结点的所有未处理且直接可达的邻居插入预置队列;
队列判断单元,用于判断所述预置队列是否为空,若为空,则激活所述结点判断单元执行所述按照结构相似性并行算法判断当前未处理的结点是否为核心结点的步骤,若不为空,则弹出所述预置队列的队首元素,将所述队首元素划分至所述新的聚类,并将所述队首元素的所有可达且未处理的邻居插入所述预置队列中;
进程判断单元,用于判断所述无向无权简单图中是否存在未处理的结点,若存在,则激活所述结点判断单元执行所述按照结构相似性并行算法判断当前未处理的结点是否为核心结点的步骤,若不存在,则结束算法,得到目标聚类。
进一步地,分别以u和v表示所述无向无权简单图中的任意一条边的两个端点,则所述结点判断单元具体用于:
分别获取u和v的按照其邻居的结点编号排序的邻接链表及邻居结点;
分别以u和v的邻居结点的个数表示u和v的结点度数,计算u和v的结点度数之和,并以计算得到的结点度数之和表示以u和v为两个端点的边的度数;
计算得到所述无向无权简单图中所有边的度数和,将所述所有边的度数和按照预置等分点平均分成若干计算任务块,每一计算任务块对应每一计算进程,每一所述计算进程用于遍历每一条边的两个端点的邻接链表,以获取每一条边的两个端点的共同邻居的个数;
获取所有计算进程的编号,根据计算进程的编号分配计算任务块,以使所述计算进程根据所述计算任务块计算得到每一条边的两个端点的共同邻居的个数;
计算每一条边的两个端点的结构相似形,其中,以γ(v)表示v的邻居结点的个数,以γ(u)表示u的邻居结点的个数,以σ(u,v)表示以u和v为端点的边,则:
判断计算得出的结构相似性的值是否满足预置的结构相似性阈值,若满足,则获取结点v中结构相似性大于预置的结构相似性阈值的邻居个数;
若结点v大于预置的结构相似性阈值的邻居个数大于等于预置邻居个数值时,则判断v为核心结点。
进一步地,分别以u和v表示所述无向无权简单图中的任意一条边的两个端点,则所述结点判断单元包括:
切片分配模块,用于获取所述无向无权简单图的所有的边,得到边集合,按照预置切片大小将所述边集合分成等份的若干切片,将切片分配给所有计算进程,以使所述计算进程计算所述切片内所有边的结构相似性;
结点判断模块,用于判断计算得出的结构相似性的值是否满足预置的结构相似性阈值,若满足,则获取结点v中结构相似性大于预置的结构相似性阈值的邻居个数,若结点v大于预置的结构相似性阈值的邻居个数大于等于预置邻居个数值时,则判断v为核心结点。
进一步地,所述切片分配模块具体包括:
切片分配子模块,用于获取所有计算进程的运行状态,将切片随机分配给运行状态为空闲的计算进程,以使所述计算进程计算所述切片内所有边的结构相似性;
进程判断子模块,用于当接收到计算进程发送的任务申请指令时,发送新的切片给对应的计算进程,判断是否存在未计算的切片,若存在,则执行所述将切片随机分配给运行状态为空闲的计算进程的步骤,若不存在,则结束计算。
进一步地,所述切片分配子模块具体用于:
将切片和上锁指令发送给运行状态为空闲的计算进程,以使所述计算进程计算所述切片内所有边的结构相似性并进行上锁;
则进程判断子模块具体用于:
当接收到计算进程发送的任务申请指令时,发送解锁指令给发送任务申请指令的计算进程,以使所述发送任务申请指令的计算进程进行解锁;
接收所述发送任务申请指令的计算进程发送的解锁完毕信息,将新的切片和上锁指令发送给所述发送任务申请指令的计算进程,以使计算进程计算所述新的切片内所有边的结构相似性并重新上锁。
本发明与现有技术相比,有益效果在于:本发明实施例通过遍历无向无权简单图得到未处理的结点,按照结构相似性并行算法判断并得到核心结点,根据核心结点进行聚类,最终得到目标聚类。本发明实施例通过并行算法,提高了计算的时间效率。
附图说明
图1是本发明实施例提供的一种结构聚类的生成方法的流程图;
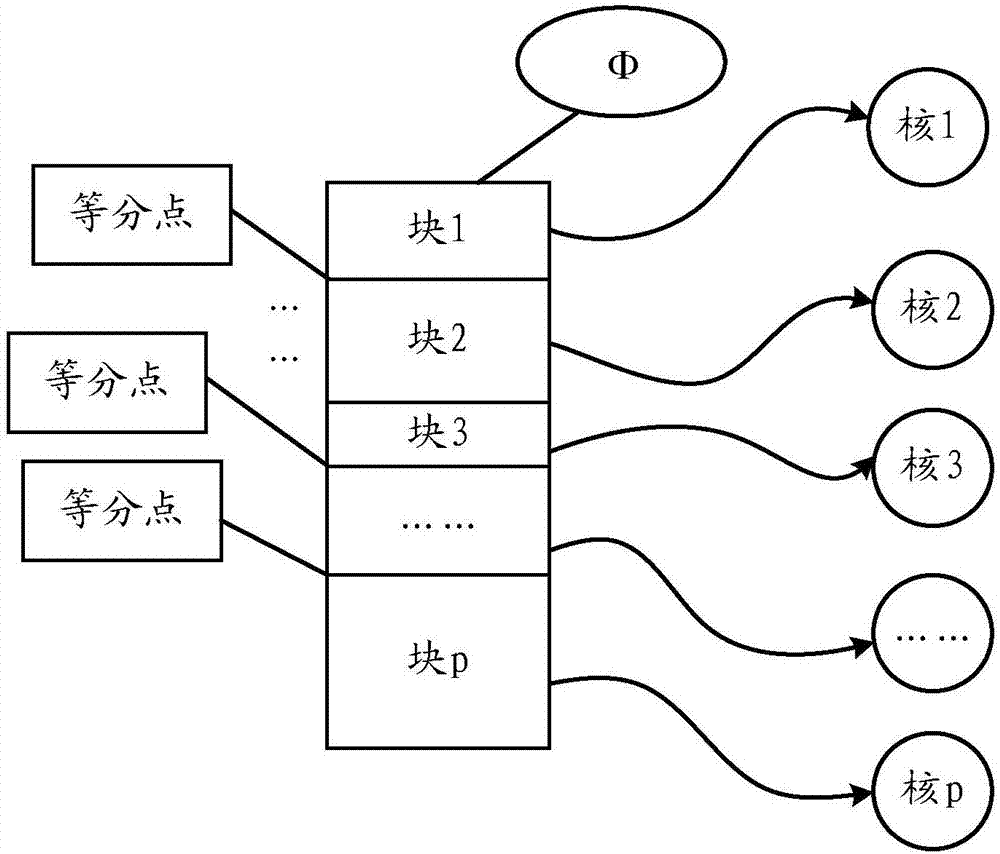
图2是本发明实施例提供的基于结点度的负载均衡策略的等分示意图;
图3是本发明实施例提供的基于结点度的负载均衡策略的工作流程图;
图4是本发明实施例提供的基于切片的负载均衡策略的分配示意图;
图5是本发明实施例提供的基于切片的负载均衡策略的工作流程图;
图6是本发明实施例提供的一种结构聚类的生成系统的结构示意图;
图7是本发明实施例提供的结点判断单元的结构示意图;
图8是本发明实施例提供的切片分配模块的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
图1示出了本发明实施例提供的一种结构聚类的生成方法,包括:
s101,接收待处理的无向无权简单图,遍历所述无向无权简单图得到所有未处理的结点;
s102,按照结构相似性并行算法判断当前未处理的结点是否为核心结点,若否,则判断下一未处理的结点是否为核心结点;
s103,若是,则生成新的聚类并编号,并将所述当前未处理的结点的所有未处理且直接可达的邻居插入预置队列;
s104,判断所述预置队列是否为空,若为空,则执行所述按照结构相似性并行算法判断当前未处理的结点是否为核心结点的步骤;
s105,若不为空,则弹出所述预置队列的队首元素,将所述队首元素划分至所述新的聚类,并将所述队首元素的所有可达且未处理的邻居插入所述预置队列中;
s106,判断所述无向无权简单图中是否存在未处理的结点,若存在,则执行所述按照结构相似性并行算法判断当前未处理的结点是否为核心结点的步骤,若不存在,则结束算法,得到目标聚类。
进一步地,分别以u和v表示所述无向无权简单图中的任意一条边的两个端点,则所述按照结构相似性并行算法判断当前未处理的结点是否为核心结点包括:
分别获取u和v的按照其邻居的结点编号排序的邻接链表及邻居结点;
分别以u和v的邻居结点的个数表示u和v的结点度数,计算u和v的结点度数之和,并以计算得到的结点度数之和表示以u和v为两个端点的边的度数;
计算得到所述无向无权简单图中所有边的度数和,将所述所有边的度数和按照预置等分点平均分成若干计算任务块,每一计算任务块对应每一计算进程,每一所述计算进程用于遍历每一条边的两个端点的邻接链表,以获取每一条边的两个端点的共同邻居的个数;
获取所有计算进程的编号,根据计算进程的编号分配计算任务块,以使所述计算进程根据所述计算任务块计算得到每一条边的两个端点的共同邻居的个数;
计算每一条边的两个端点的结构相似形,其中,以γ(v)表示v的邻居结点的个数,以γ(u)表示u的邻居结点的个数,以σ(u,v)表示以u和v为端点的边,则:
判断计算得出的结构相似性的值是否满足预置的结构相似性阈值,若满足,则获取结点v中结构相似性大于预置的结构相似性阈值的邻居个数;
若结点v大于预置的结构相似性阈值的邻居个数大于等于预置邻居个数值时,则判断v为核心结点。
进一步地,分别以u和v表示所述无向无权简单图中的任意一条边的两个端点,则所述按照结构相似性并行算法判断当前未处理的结点是否为核心结点包括:
获取所述无向无权简单图的所有的边,得到边集合;
按照预置切片大小将所述边集合分成等份的若干切片;
将切片分配给所有计算进程,以使所述计算进程计算所述切片内所有边的结构相似性;
判断计算得出的结构相似性的值是否满足预置的结构相似性阈值,若满足,则获取结点v中结构相似性大于预置的结构相似性阈值的邻居个数;
若结点v大于预置的结构相似性阈值的邻居个数大于等于预置邻居个数值时,则判断v为核心结点。
进一步地,所述将切片分配给所有计算进程,以使所述计算进程计算所述切片内所有边的结构相似性包括:
获取所有计算进程的运行状态;
将切片随机分配给运行状态为空闲的计算进程,以使所述计算进程计算所述切片内所有边的结构相似性;
当接收到计算进程发送的任务申请指令时,发送新的切片给对应的计算进程;
判断是否存在未计算的切片,若存在,则执行所述将切片随机分配给运行状态为空闲的计算进程的步骤,若不存在,则结束计算。
进一步地,所述将切片随机分配给运行状态为空闲的计算进程具体包括:
将切片和上锁指令发送给运行状态为空闲的计算进程,以使所述计算进程计算所述切片内所有边的结构相似性并进行上锁;
则所述当接收到计算进程发送的任务申请指令时,发送新的切片给对应的计算进程包括:
当接收到计算进程发送的任务申请指令时,发送解锁指令给发送任务申请指令的计算进程,以使所述发送任务申请指令的计算进程进行解锁;
接收所述发送任务申请指令的计算进程发送的解锁完毕信息,将新的切片和上锁指令发送给所述发送任务申请指令的计算进程,以使计算进程计算所述新的切片内所有边的结构相似性并重新上锁。
在现实世界的网络中,一个图有上亿条边随处可见,甚至有超过十亿条边,处理如此大的图数据,现有技术中使用基于多台机器的mapreduce算法实现。mapreduce主要是基于分布式存储的方式,让多台计算机共同完成一个庞大的任务。使用它主要是考虑到内存空间的不足,从而将任务拆分,让多台计算机同时计算。但是,首先多台计算处理同一事物,必然涉及到不同计算机之间的数据交换;其次,随着硬件技术的发展内存已经不再是考虑的主要元素。对于一切实际的问题更在乎的是算法的效率以及运行时间。基于此,本发明实施例将采用基于共享内存的多核框架下实现scan算法过程中的相似性的计算。在共享内存的模式下进行算法的实现,由于数据的共享,所以不涉及大量的数据交换过程,但是与此同时,实际应用中必须注意对共享数据的写保护。因此在本实施中充分的利用锁机制。锁主要用于线程(即计算进程)之间的同步,其最重要的特点是相互排斥,这意味着一个锁只能由一个线程拥有。只要该线程释放该锁后,其他线程才能占有。不同锁的相同的操所需要的时间不同。在本实施例提供的算法的具体实现中使用原子锁,该锁的上锁和解锁操作所花费的时间最少。
如背景技术所述,针对scan算在大规模图数据中计算每条边的结构相似性耗时的问题,本实施例采用基于openmp多核框架的方法,实现计算结构相似性的并行算法实现,从而实现在时间效率上,随着核数的增多,计算的时间呈近似线性下降的效果,同时针对多核计算,本实施例提出了两种有效的负载均衡策略。
为了进一步地说明本实施例中提供的scan的并行计算相似性过程,首先介绍scan模型的几个关键概念。
在无向无权简单图g=(v,e)中v代表图中的结点,e代表图的所有边,每个结点的邻居定义为γ(v)={w∈v|(v,w)∈e}∪{v},根据此定义得到两个结点的结构相似性定义:
如果u和v不形成一条边,则σ(u,v)=0,在scan模型中,首先指定结构相似性的阈值假设为ε,从而得到ε-neighborhood(ε邻居)的定义:
nε(v)={w∈γ(v)|σ(w,v)≥ε}----------(2)
当一个结点被称作核心结点当且仅当|nε(v)|≥μ,即
如果v直接可达u,u直接可达w,则称v可达w,具体形式如下:
如果存在一个结点v,满足reachε,μ(v,w)并且reachε,μ(v,u),则称u和w满足结构连通性(connectε,μ(u,w))。
根据上述定义得到scan模型对于聚类的定义:
scan算法是找出网络中所有满足上述定义的聚类,在该模型中存在一些点,这些点不属于任何聚类,但是他们却连接着不同的聚类,本实施例中称之为:桥(hubs),其他的既不是桥也不属于任何聚类的点,称为边界点(outliers)。scan模型首先找到一个核心结点,然后从该结点出发以广度优先遍历的方式(breadth-firstsearch)找到所有的可达邻居,并将他们规划为一个聚类。当所有结点都被访问过,算法结束。该算法对于大规模图数据的社区搜索具有很好的效果,但是需要计算图中的所有边的相似性,在单核计算模式下,极其耗时。
基于此,本实施例提供了两种负载均衡策略,为了阐述本实施例的两种负载均衡策略,先简单阐述scan算法的主要步骤,其中无向无权简单图表示为g=(v,e),g代表图,v是图中所有结点的集合,e是图中所有边的集合,则:
a、对于每个未处理的结点v∈v,如果v是核心结点,执行步骤b,否则继续执行步骤b;
b、生成一个新的聚类及聚类编号(id号),并将v结点所有的未处理的且直接可达的邻居插入到预置队列q;
c、如果队列q不为空,执行步骤d,若为空,则执行步骤a;
d、弹出队列q的队首元素(first),并将其划分到步骤b所生成的聚类中,同时将队首元素的所有可达且未处理的邻居插入到队列q中。
在步骤a中需要判断结点v是否为核心结点,而该步骤需要计算每条边的(两个端点)的结构相似性,根据公式(1):如果u、v之间存在一条边,则边uv的相似性计算如下:
本实施例主要解决在判断核心结点的过程中的算法耗时问题,提出了基于openmp的两种并行计算机制,包括:
一、基于结点度的负载均衡策略
根据公式(2)中的计算结构相似性的公式,例如结点u、v,必须找到u和v的共同邻居的个数。因此当结点u和v的邻接链表按其邻居的结点编号排序后,同时遍历u和v的邻接链表,找到他们的共同邻居的个数即|γ(v)∩γ(u)|。以v的邻居个数作为v的结点度数,遍历v和u邻接链表的时间复杂度是u和v的结点度数之和:degree(v)+degree(u),所以对于整个图来说,该过程的整体时间复杂度为:σ(uv∈e)(degree(v)+degree(u))。在本实施例中,可以根据计算机处理器的核的数量(p),将时间复杂度平均分成p份,每份的大小为:
二、基于切片的负载均衡策略
由上述基于结点度的负载均衡策略可知,即使在上述均衡策略中将存储了该无向无权简单图的所有边的集合(φ)的边数平均分成p等分,也不能保证每个核会同时完成各自的任务,尤其当p较小时即每等份包含较多的边时,每个核完成各自任务的时间差距将变得很大。即某些核可能已经完成了分配给它的任务而另外的核仍然需要执行很长的时间,这样会造成核之间的运行时间的巨大的鸿沟。
基于上述原因,在本均衡策略中,将无向无权简单图中所有的边的集合分成等份的切片,切片大小在1000万到5000万之间,切片大小是指边的条数,并且在具体应用中切片的大小只要小于总变数的千分之一,计算机各核的速率基本相同,在具体应用中切片不宜过大,太大会造成进程之间的计算等待,也不宜过小,过小会造成频繁的上锁解锁操作,从而降低时间效率。
本均衡策略中,对存储了该无向无权简单图的所有边的集合φ的所有切片采用动态任务调配机制,即切片随机分配给任意计算机的核,如图4所示。每一个核根据接收到的切片计算每条边的相似性,只要该核所分配的任务已经执行完后,将向存储了该无向无权简单图的所有边的集合φ申请得到新的任务。
如图5所示,所有切片的大小(所含边的条数)是相同的,任务刚开始,每个核得到一个任务,执行完成,则申请下一个任务。但是,下个任务被哪个核所执行是不确定的。例如切片n可能被任意一个核所执行,哪个核谁先申请则由先申请的核执行。本策略的主要算法流程如图5所示,在实际应用中,本概策略具有良好的运行效果,四核时,运行速度是单核的3.45倍,八核是单核的7.23倍,二十核是单核的18.5倍,随着核数的递增,时间效率几乎是线性增长。
在具体应用中,本均衡策略在整个图的邻接链表中,在结点数组中为每个结点增加一个记录直接可达邻居个数的字段,并且每个进程在修改该字段值的时候用的原子锁机制实现互斥的访问。
图6示出了本发明实施例提供的一种结构聚类的生成系统,包括:
图像遍历单元601,用于接收待处理的无向无权简单图,遍历所述无向无权简单图得到所有未处理的结点;
结点判断单元602,用于按照结构相似性并行算法判断当前未处理的结点是否为核心结点,若否,则判断下一未处理的结点是否为核心结点,若是,则生成新的聚类并编号,并将所述当前未处理的结点的所有未处理且直接可达的邻居插入预置队列;
队列判断单元603,用于判断所述预置队列是否为空,若为空,则激活结点判断单元602执行所述按照结构相似性并行算法判断当前未处理的结点是否为核心结点的步骤,若不为空,则弹出所述预置队列的队首元素,将所述队首元素划分至所述新的聚类,并将所述队首元素的所有可达且未处理的邻居插入所述预置队列中;
进程判断单元604,用于判断所述无向无权简单图中是否存在未处理的结点,若存在,则激活结点判断单元602执行所述按照结构相似性并行算法判断当前未处理的结点是否为核心结点的步骤,若不存在,则结束算法,得到目标聚类。
进一步地,分别以u和v表示所述无向无权简单图中的任意一条边的两个端点,则结点判断单元602具体用于:
分别获取u和v的按照其邻居的结点编号排序的邻接链表及邻居结点;
分别以u和v的邻居结点的个数表示u和v的结点度数,计算u和v的结点度数之和,并以计算得到的结点度数之和表示以u和v为两个端点的边的度数;
计算得到所述无向无权简单图中所有边的度数和,将所述所有边的度数和按照预置等分点平均分成若干计算任务块,每一计算任务块对应每一计算进程,每一所述计算进程用于遍历每一条边的两个端点的邻接链表,以获取每一条边的两个端点的共同邻居的个数;
获取所有计算进程的编号,根据计算进程的编号分配计算任务块,以使所述计算进程根据所述计算任务块计算得到每一条边的两个端点的共同邻居的个数;
计算每一条边的两个端点的结构相似形,其中,以γ(v)表示v的邻居结点的个数,以γ(u)表示u的邻居结点的个数,以σ(u,v)表示以u和v为端点的边,则:
判断计算得出的结构相似性的值是否满足预置的结构相似性阈值,若满足,则获取结点v中结构相似性大于预置的结构相似性阈值的邻居个数;
若结点v大于预置的结构相似性阈值的邻居个数大于等于预置邻居个数值时,则判断v为核心结点。
进一步地,分别以u和v表示所述无向无权简单图中的任意一条边的两个端点,则如图7所示,结点判断单元602包括:
切片分配模块6021,用于获取所述无向无权简单图的所有的边,得到边集合,按照预置切片大小将所述边集合分成等份的若干切片,将切片分配给所有计算进程,以使所述计算进程计算所述切片内所有边的结构相似性;
结点判断模块6022,用于判断计算得出的结构相似性的值是否满足预置的结构相似性阈值,若满足,则获取结点v中结构相似性大于预置的结构相似性阈值的邻居个数,若结点v大于预置的结构相似性阈值的邻居个数大于等于预置邻居个数值时,则判断v为核心结点。
进一步地,如图8所示,切片分配模块6021具体包括:
切片分配子模块60211,用于获取所有计算进程的运行状态,将切片随机分配给运行状态为空闲的计算进程,以使所述计算进程计算所述切片内所有边的结构相似性;
进程判断子模块60212,用于当接收到计算进程发送的任务申请指令时,发送新的切片给对应的计算进程,判断是否存在未计算的切片,若存在,则执行所述将切片随机分配给运行状态为空闲的计算进程的步骤,若不存在,则结束计算。
进一步地,切片分配子模块60211具体用于:
将切片和上锁指令发送给运行状态为空闲的计算进程,以使所述计算进程计算所述切片内所有边的结构相似性并进行上锁;
则进程判断子模块具体用于:
当接收到计算进程发送的任务申请指令时,发送解锁指令给发送任务申请指令的计算进程,以使所述发送任务申请指令的计算进程进行解锁;
接收所述发送任务申请指令的计算进程发送的解锁完毕信息,将新的切片和上锁指令发送给所述发送任务申请指令的计算进程,以使计算进程计算所述新的切片内所有边的结构相似性并重新上锁。
本发明提供的上述基于openmp的多核并行计算相似性算法弥补了原始scan算法在处理现实动态网络图数据的不足之处。使用本发明实施例提供的并行算法后,随着核数的递增,时间效率几乎是线性增长。由于在现实生活中数据量巨大,如果只采用单核去计算每条边的结构相似性,则不仅是对时间资源的巨大浪费,也没用充分利用现有的硬件资源。
本发明提供的实施例,可以应用于以下领域:图数据中的社区搜索应用领域十分广泛,而现实中的图数据总是在不停的更新,由于在现实生活中数据量巨大,如果每次都需要重新计算,则是对时间和空间资源的巨大浪费。在现实世界中对数据的高效性和实时性要求较高,尤其在在电话通信网络中,要查询一个用户与其紧密联系的一个社群,进而了解其的社会关系网络,这一应用有助于帮助公安刑侦,打击团伙犯罪,恐怖组织等更需要高效地进行。另外发现图数据中的社区结构在生物学中也有重要的应用,能够找出具有相同性质的物质。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!