一种XML数据的快速查询方法与流程
本发明属于信息交换和查询领域,尤其涉及一种xml数据的快速查询方法,具体为在xml数据中进行由多个具有复杂结构关系的标签路径组成的层次融合式查询,并返回二维结果值集合。
背景技术:
xml(extensiblemarkuplanguage),即可扩展的标记语言,是一套定义语义标记的规范。xml提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。是internet环境中跨平台的、依赖于内容的技术,也是当今处理分布式结构信息的有效工具。随着网络应用的快速发展,使得xml类型的数据成为基于互联网数据交换的主流数据形式。
xml格式数据具有天然的层次结构关系即树形结构关系,因此在很多应用场合下针对xml数据的查询也具有层次关系特性。在传统关系数据库中一种常见的层次数据查询应用:有条件地从不同层级的数据表中检索多个字段的数据。假定以下关系:部门(部门编号,部门名称);员工(员工编号,部门编号,员工姓名,职位,性别,年龄),部门和员工之间是一对多的关系(树状结构),对应的简写:dept(dep_id,dep_name)和emp(emp_id,dep_id,name,title,gender,age)。显然部门表和员工表是不同层次关系的表,后者是前者的子表,现在要检索出“年龄大于40岁的所有的员工姓名、职位和所属部门名称”,那么对应的sql脚本语句如下:
selectemp.name,emp.title,dept.dept_name
fromdept,emp
wheredept.dept_id=emp.dep_id
andage>40;
总结这种层次表联接(融合性)查询具有以下特点:
1)数据的循环层次,结果集是以员工层次为中心的循环数据集而不是部门,在sql中缺省以最低层次为循环中心;
2)员工表中必须要有部门编号,标注自己所属部门;
3)连接操作体现出层次之间的关联关系同时又具有隔离性,即具有相同部门编号的员工(在员工表中)的所属部门信息(在部门表中)也相同,同时不同的部门拥有不同的员工,即使有跨部门员工,此员工信息也会出现多次(部门编号不同,一对多关系);
4)要查询的字段也具有层次融合性,每个员工除了自己的专有信息外还包括所属部门的名字。
作为数据交换的主体,xml又具有很强的层级结构自描述特性,上面的两张具有“父子关系”的数据表(部门表和员工表)可以很容易转换成二级循环(部门和员工)的xml格式数据,下层xml分支嵌套在上层的某个循环分支中,即多个员工信息(同一部门的员工)的下层分支嵌入到所属部门的上层分支中,具有天然或缺省的层次联接条件,不需要在员工层标明部门编号(部门编号作为嵌入的员工层分支的祖先节点形式存在),避免了上述特点2)节省了存储空间。基于此,针对此类xml数据提出上述的层次融合式查询需求也是很自然的事情。那么目前的针对xml的查询处理技术是不是能够很好的解决上述问题呢?
xpath是一种在xml文档中查找信息的语言,是w3c推荐标准,迄今为止,学术界集中讨论的基于xml的处理都是围绕着xpath展开的。xpath借助于路径表达式来选取xml文档中的节点、节点集合、原子值、以及节点和原子值的混合。通过沿着位置路径表达式(path)或者步(steps)来选取相关节点。
但是由于语法上的限制,一般情况下xpath返回的都是一维的结果集,结果集的元素之间都是兄弟关系,即使使用联合操作"|"强行合并两个表达式返回的值集合也不能得到正确的层次融合式结果集。因此单独使用xpath不能直接返回具有不同层次结构关系的多个字段(或者标签路径)的值集合。
xquery建立在xpath表达式基础之上用于xml的数据查询语言,xquery在xpath之后成为w3c推荐标准。xquery天生支持xpath并将其作为xquery语法的一部分,xquery显然能完成xpath所能完成的任何任务。
但是xquery是图灵完备的(turing-complete),可以被看作是一种通用语言,因而很容易克服xpath的诸多局限,xquery提供了一批重要的内置函数和运算符,而且还提供了表达对结果集进行任意转换的功能。但xquery使用的复杂性明显增加,使用xquery返回具有不同层次结构关系的结果集往往需要编写非常复杂多层嵌套的xquery脚本,甚至需要编程语言的帮助下才能完成融合式的查询,而且脚本的执行在时空效率上要依赖于所选择的xquery查询引擎。
技术实现要素:
本发明要解决的技术问题是,提供一种xml数据的快速查询方法,能够满足查询自适应性和较高时空效率的要求。
为实现上述目的,本发明采用如下的技术方案:
一种xml数据的快速查询方法,包括以下步骤:
步骤1、查询参数预处理:构建谓词表达式语法计算树、查询导航树
步骤、101如果谓词表达式不存在的话,跳转到步骤104,如果存在,顺序执行下一步骤;
步骤102、按照表达式ebnf范式,语法分析谓词条件表达式,并把操作数作为叶子节点,把相关的操作符作为其父节点,依次类推构造谓词语法计算树;
步骤103、把每个条件表达式子项中的标签路径追加到查询标签路径表中;
步骤104、针对查询标签列表中的每一个标签路径,分拆成一组标签序列;
步骤105至107针对此标签路径的标签序列,按照顺序处理每一个标签:如果此标签没在查询树结构中,则创建新的节点结构编入查询树中,在节点中放入此标签的详细信息,同时把导航信息放入此节点中,包括:“父子”指针、“子父”指针,按照顺序检查下一个标签、重复执行步骤105;如果在查询树结构中已经存在,顺序查找下一个标签,重复执行步骤105;直到标签序列结束执行步骤108。
步骤108遍历查询导航树,继续丰富节点的导航信息。
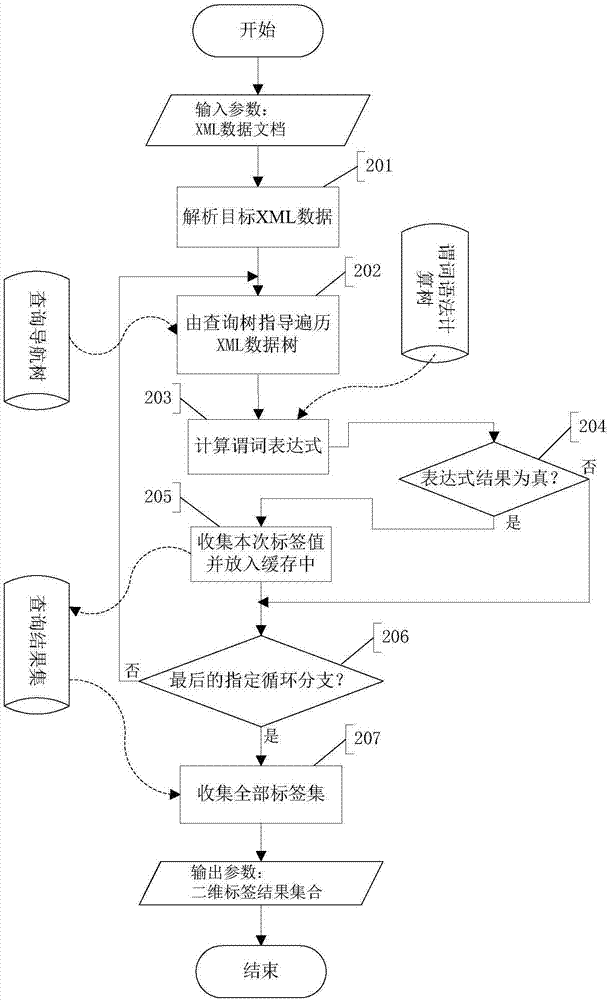
步骤2、查询处理并提供二维结果集
步骤201、解析目标xml数据读入内存中,构造数据对象树,此对象树节点中只存在“父子关系”的向下单向指针,无“子父关系”的向上指针;
步骤202、遍历查询导航树同时遍历xml数据树,对于查询树中的查询节点和数据树中的相关数据节点采用“双树剪枝”算法作遍历检查处理:查询标签节点存在但无数据标签节点与之对应,则以此查询节点为根节点的查询分支不再遍历;查询节点和数据节点的标签名相同,则通过此标签节点或者收集其标签路径的结果值放入缓存;数据标签节点存在但无查询标签节点与之对应,则遍历跳过以此数据节点为根节点的数据分支;
步骤203和204、如果遍历到已标注谓词计算位置的标签节点上,则提取表达式中的各标签路径对应值,然后开始按照谓词表达式语法计算树结构要求计算表达式,结果为真则执行步骤205,结果为假则执行步骤206;
步骤205、收集本次的标签对应值并放入缓存中;
步骤206、越过此指定循环点路径的分支,继续下一个分支,如果是最后的数据分支,则执行步骤207,如果不是则执行步骤202;
步骤207、收集所有缓存中的标签对应结果集,合并组成二维标签结果集,并返回。
作为优选,采用双树剪枝算法作遍历检查处理过程为:遍历的过程中,当前标签节点要选定下一个孩子标签节点时:假定nq为当前查询树节点,nlqc为nq的所有孩子节点集合,其标签列表为tlqc,nqc为nq的目标孩子节点,tqc为其标签;nd为当前数据树节点,其标签和nq节点的标签相同,nldc为nd的所有孩子节点集合,其标签列表为tldc,ndc为nd的孩子节点,tdc为其标签;对于nlqc的所有查询子节点对应的标签,依次要到数据树的nldc中查找和检查:
a)当数据子节点标签tdc不属于tlqc时,意味着以ndc为根节点的数据分支无须继续查询,数据树遍历时可以剪掉此分支,即对数据树剪枝;
b)当tdc等于tqc时,意味着以nqc和ndc为根节点的分支都需要继续深入遍历查询,如果nqc为叶子节点,则收集此标签对应的结果,否则要对其孩子节点重复上述过程;
c)当tqc不属于tldc时,意味着要查询的标签在nldc中不存在,那么以nqc为根节点的查询分支无须继续查询,查询树遍历时可以剪掉此分支,即对查询树剪枝。
本发明的种xml数据的快速查询方法,在xml数据中进行由多个具有复杂层次结构关系的标签路径组成的层次融合式查询,构建了解决此问题的查询模型——xml多标签路径查询(xmtq)。xmtq模型基于简洁的查询接口(qi)、查询导航树数据结构模型(qgt)和查询处理引擎(qe),其中在qi中只提供要查询的标签路径即可,不需关注其复杂的结构关系,可由模型自适应标签路径之间的结构关系,也支持谓词表达式参数接口;qgt具有“树干”标签节点遍历结果共享和快捷的遍历导航路线特征,可以指导qe更快速、更精准地遍历、跳过无关分支、查询并获取相关的标签值。通过测试表明xmtq模型针对大规模xml数据查询多个层次复杂的标签路径具有突出的查询时空效率。
附图说明
图1:查询参数预处理流程图;
图2:查询处理流程图。
具体实施方式
本发明提供一种xml数据的快速查询方法,采用新的层次融合式查询模型xmtq(xmlmultipletagsquery),该模型接收多个查询标签路径,这些路径之间的关系比较复杂,包括:“父子关系”、“兄弟关系”、“叔侄关系”、“祖先-子孙关系”、“叔公-侄孙关系”等。经过查询提取之后的结果集是一个二维的集合,第一维是按照xml数据中存放顺序的每个指定“家族”/分支对应的结果子集,第二维的结果子集是一个映射表,其中“键”对应的是标签路径,“值”是标签路径所指定的融合后的结果值,具体技术方案如下:
1、提供简单的查询接口
用户只需要简单地提供查询标签路径列表、指定的循环点标签路径和谓词表达式(可选)即可,不需要额外关注多个查询标签路径之间复杂的结构关系,不需要对查询过程进行干预,不需要做“二次编程”或者“再查找”收集结果的工作。系统会封装并自适应查询标签路径的复杂层次结构关系,查询并自动提取相应的结果值集合,使得用户能够更专注自己的业务需求,快速适应业务变化。
由于查询请求参数同xml数据变化频度不一致,一般地,查询参数发生变化时系统必须要重新对查询参数进行预处理,而不是每次处理xml数据之前处理查询参数,所以整个查询过程分为以下两大部分:
2、查询请求参数的预处理
2.1、构建谓词语法计算树
按照如下条件表达式的ebnf范式对输入的谓词表达式进行语法分析:
<条件>→<条件分项1>{or<条件分项1>}
<条件分项1>→<条件分项2>{and<条件分项2>}
<条件分项2>→not(<条件分项3>)|<条件分项3>
<条件分项3>→<表达式><关系运算符><表达式>|(<条件>)
<表达式>→<项>{+<项>}|<项>{-<项>}
<项>→<因子>{*<因子>}|<因子>{/<因子>}
<因子>→tag_path|num|string|false|true|(<表达式>)
<关系运算符>→<|<=|>|>=|==|!=
分解谓词条件表达式之后构造谓词语法计算树,操作数作为叶子节点,把相关的操作符作为其父节点,依次类推。同时把每个条件表达式子项中涉及到的标签路径追加到查询标签路径列表中。
2.2、构建查询导航树
1)输入的查询标签路径是绝对路径,每个标签路径都是从根节点开始逐次向下,这些路径之间存在着大量的可以共享的标签,那么可以把这些查询路径进行某种程度上的合并,即构建查询树,同时能够反映出各个路径之间的结构层次关系。
2)每个构成查询树的节点除了要有标签的信息之外,还要有详尽的导航信息,方便对此查询树的遍历,同时还要标注可以对谓词表达式计算的位置。
3、查询处理并收集结果集
1)解析目标xml数据读入内存中,构造数据对象树,此对象树节点中只存在“父子关系”的向下单向指针,无“子父关系”的向上指针,有利于节省存储空间,减少解析时间,提高时空效率。
2)查询导航树和xml数据树的遍历过程中,采用双树剪枝算法(查询树和数据树)。
遍历的过程中,当前标签节点要选定下一个孩子标签节点时:假定nq为当前查询树节点,nlqc为nq的所有孩子节点集合,其标签列表为tlqc,nqc为nq的目标孩子节点,tqc为其标签;nd为当前数据树节点,其标签和nq节点的标签相同,nldc为nd的所有孩子节点集合,其标签列表为tldc,ndc为nd的孩子节点,tdc为其标签。对于nlqc的所有查询子节点对应的标签,依次要到数据树的nldc中查找和检查:
a)当数据子节点标签tdc不属于tlqc时,意味着以ndc为根节点的数据分支无须继续查询,数据树遍历时可以剪掉此分支,即对数据树剪枝;
b)当tdc等于tqc时,意味着以nqc和ndc为根节点的分支都需要继续深入遍历查询,如果nqc为叶子节点,则收集此标签对应的结果,否则要对其孩子节点重复上述过程;
c)当tqc不属于tldc时,意味着要查询的标签在nldc中不存在,那么以nqc为根节点的查询分支无须继续查询,查询树遍历时可以剪掉此分支,即对查询树剪枝。
3)在已标注的计算点开始计算谓词表达式,结果为真则继续遍历查询,否则要跳过对此分支的遍历查询,跳转到下一个循环分支。
如图1和2所示,本发明实施例提供一种xml数据的快速查询方法,具体流程包括以下步骤:
步骤1、查询参数预处理:构建谓词表达式语法计算树、查询导航树
步骤101如果谓词表达式不存在的话,跳转到步骤104,如果存在,顺序执行下一步骤。
步骤102按照表达式ebnf范式,语法分析谓词条件表达式,并把操作数作为叶子节点,把相关的操作符作为其父节点,依次类推构造谓词语法计算树。
步骤103把每个条件表达式子项中的标签路径追加到查询标签路径表中。
步骤104针对查询标签列表中的每一个标签路径,分拆成一组标签序列。
步骤105至107针对此标签路径的标签序列,按照顺序处理每一个标签:如果此标签没在查询树结构中,则创建新的节点结构编入查询树中,在节点中放入此标签的详细信息,同时把导航信息放入此节点中,包括:“父子”指针、“子父”指针,按照顺序检查下一个标签、重复执行步骤105;如果在查询树结构中已经存在,顺序查找下一个标签,重复执行步骤105;直到标签序列结束执行步骤108。
步骤108遍历查询导航树,继续丰富节点的导航信息。
步骤2、查询处理并提供二维结果集
步骤201解析目标xml数据读入内存中,构造数据对象树,此对象树节点中只存在“父子关系”的向下单向指针,无“子父关系”的向上指针,有利于节省存储空间,减少解析时间,提高时空效率。
步骤202遍历查询导航树同时遍历xml数据树,对于查询树中的查询节点和数据树中的相关数据节点采用“双树剪枝”算法作遍历检查处理:查询标签节点存在但无数据标签节点与之对应,则以此查询节点为根节点的查询分支不再遍历;查询节点和数据节点的标签名相同,则通过此标签节点或者收集其标签路径的结果值放入缓存;数据标签节点存在但无查询标签节点与之对应,则遍历跳过以此数据节点为根节点的数据分支。
步骤203和204如果遍历到已标注谓词计算位置的标签节点上,则提取表达式中的各标签路径对应值,然后开始按照谓词表达式语法计算树结构要求计算表达式,结果为真则执行步骤205,结果为假则执行步骤206。
步骤205收集本次的标签对应值并放入缓存中。
步骤206越过此指定循环点路径的分支,继续下一个分支,如果是最后的数据分支,则执行步骤207,如果不是则执行步骤202。
步骤207收集所有缓存中的标签对应结果集,合并组成二维标签结果集,并返回。
- 还没有人留言评论。精彩留言会获得点赞!