一种XML流数据的快速查询方法与流程
本发明属于信息交换和查询领域,尤其涉及一种xml流数据的快速查询方法,具体为在xml流数据中进行由多个具有复杂结构关系的标签路径组成的快速层次融合式查询,并返回二维结果值集合。
背景技术:
xml(extensiblemarkuplanguage),即可扩展的标记语言,是一套定义语义标记的规范。xml提供统一的方法来描述和交换独立于应用程序的结构化数据。随着网络应用的快速发展,使得xml类型的数据成为基于互联网数据交换的主流数据形式。xml流数据是以流的形式在线传输、实时到达,需要即时解析和处理,因此针对大规模xml流数据的快速查询处理是流查询模型的研究热点。
xml格式数据具有天然的层次结构关系即树形结构关系,因此在很多应用场合下针对xml数据的查询也具有层次关系特性。在传统关系数据库中一种常见的层次数据查询应用:有条件地从不同层级的数据表中检索多个字段的数据。假定以下关系:部门(部门编号,部门名称);员工(员工编号,部门编号,员工姓名,职位,性别,年龄),部门和员工之间是一对多的关系(树状结构),对应的简写:dept(dep_id,dep_name)和emp(emp_id,dep_id,name,title,gender,age)。显然部门表和员工表是不同层次关系的表,后者是前者的子表,现在要检索出“年龄大于40岁的所有的员工姓名、职位和所属部门名称”,那么对应的sql脚本语句如下:
总结这种层次表联接(融合性)查询具有以下特点:
1)数据的循环层次,结果集是以员工层次为中心的循环数据集而不是部门,在sql中缺省以最低层次为循环中心;
2)员工表中必须要有部门编号,标注自己所属部门,需占用员工表空间;
3)连接操作体现出层次之间的关联关系同时又具有隔离性,即具有相同部门编号的员工(在员工表中)的所属部门信息(在部门表中)也相同,同时不同的部门拥有不同的员工,即使有跨部门员工,此员工信息也会出现多次(部门编号不同,一对多关系);
4)要查询的字段也具有层次融合性,每个员工除了自己的专有信息外还包括所属部门的名字(部门名字在部门表中,不在员工表中)。
作为数据交换的主体,xml又具有很强的层级结构自描述特性,上面的两张具有“父子关系”的数据表(部门表和员工表)可以很容易转换成二级循环(部门和员工)的xml格式数据,下层xml分支嵌套在上层的某个循环分支中,即多个员工信息(同一部门的员工)的下层分支嵌入到所属部门的上层分支中,具有天然或缺省的层次联接条件,不需要在员工层标明部门编号(部门编号作为嵌入的员工层分支的祖先节点形式存在),避免了上述特点2)节省了存储空间。基于此,针对此类xml数据提出上述的层次融合式查询需求也是很自然的事情。那么目前的针对xml的查询处理技术是不是能够很好的解决上述问题呢?
xpath是一种在xml文档中查找信息的语言,是w3c推荐标准,迄今为止,学术界集中讨论的基于xml的处理都是围绕着xpath展开的。xpath借助于路径表达式来选取xml文档中的节点、节点集合、原子值、以及节点和原子值的混合。通过沿着位置路径表达式(path)或者步(steps)来选取相关节点。
但是由于语法上的限制,一般情况下xpath返回的都是一维的结果集,结果集的元素之间都是兄弟关系,即使使用联合操作"|"强行合并两个表达式返回的值集合也不能得到正确的层次融合式结果集。因此单独使用xpath不能直接返回具有不同层次结构关系的多个字段(或者标签路径)的值集合。
xquery建立在xpath表达式基础之上用于xml的数据查询语言,xquery在xpath之后成为w3c推荐标准。xquery天生支持xpath并将其作为xquery语法的一部分,xquery显然能完成xpath所能完成的任何任务。
由于xquery是图灵完备的(turing-complete),可以被看作是一种通用语言,因而很容易克服xpath的诸多局限,xquery提供了一批重要的内置函数和运算符,而且还提供了表达对结果集进行任意转换的功能。但xquery使用的复杂性明显增加,使用xquery返回具有不同层次结构关系的结果集往往需要编写非常复杂多层嵌套的xquery脚本,甚至需要编程语言的帮助下才能完成融合式的查询,而且脚本的执行在时空效率上要依赖于所选择的xquery查询引擎。
技术实现要素:
为了解决上述问题,本发明提供一种xml流数据的快速查询方法,采用基于xml流数据的快速层次融合式查询模型qxmtq(quickxmlmultipletagsquery),能够满足查询自适应性和较高时空效率的要求。
为实现上述目的,本发明采用如下的技术方案:
一种xml流数据的快速查询方法,包括以下步骤:
步骤1、xmlschema定义预处理:构建查询导航pat树
步骤101、搜索根元素并根据其元素信息创建查询树的根节点;
步骤102、判断是否为schema定义文档中的最末元素,如果是结束此预处理,否则跳转到步骤103;
步骤103、通过当前元素寻找所有子元素,构建相对应的子标签节点并放入查询树中,在该子标签节点中放入此子元素标签特定的详细信息,同时在父-子标签节点中放入导航信息;
步骤104、根据节点及其所有直属孩子节点构建patriciatries辅助快速搜索结构,中间pat节点记录“共同”部分的长度,叶子pat节点指向对应的直属孩子标签节点;
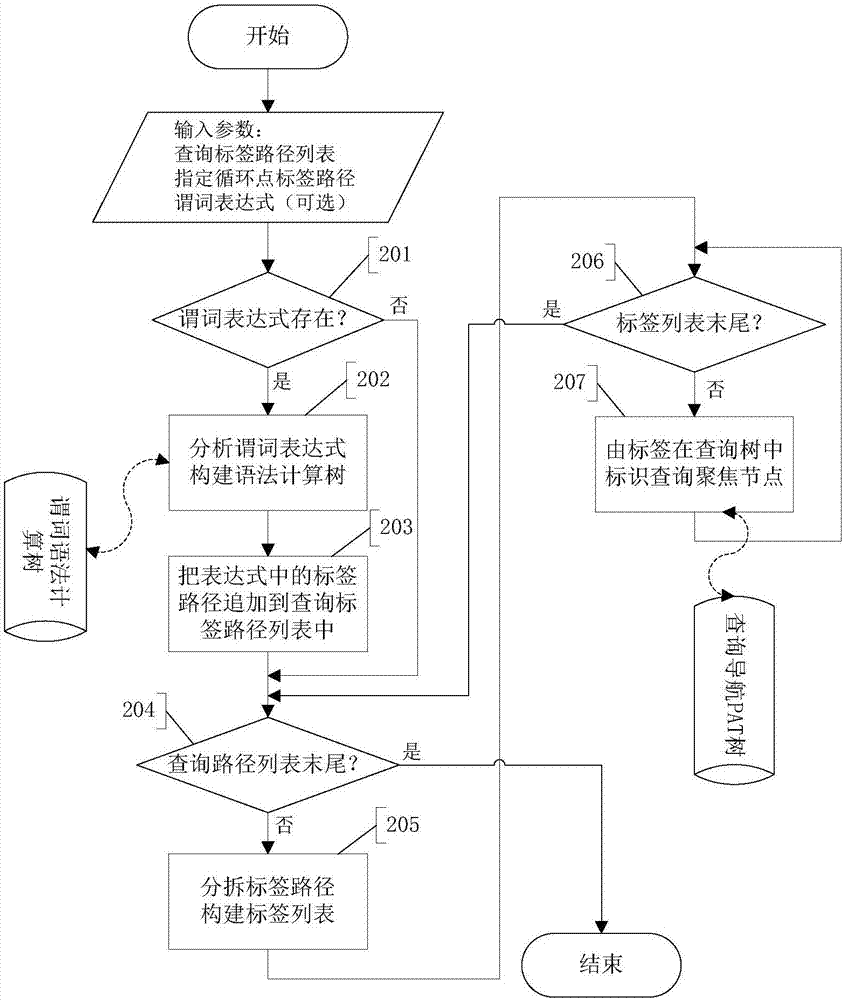
步骤2、查询参数预处理:构建谓词表达式语法计算树、查询导航pat树
步骤201、如果谓词表达式不存在的话,跳转到步骤204,如果存在,顺序执行下一步骤202;
步骤202、按照表达式ebnf范式,语法分析谓词条件表达式,并把操作数作为叶子节点,相关的操作符作为其父节点,依次类推构造谓词语法计算树;
步骤203、把每个条件表达式子项中的标签路径追加到查询标签路径表中;
步骤204、判断是否查询标签路径列表末尾,如果不是执行步骤205,否则结束查询参数预处理;
步骤205、针对每一查询标签路径,首先分拆成一个标签序列,按照顺序处理每一个标签,在查询导航pat树结构中的对应标签节点标注为需要查询聚焦:此标签节点状态为“通过”,同时把父标签节点通向该标签节点的每一个pat节点标注状态为“通过”,其它的pat节点的状态为“拒绝”;然后顺序检查下一个标签,直到此标签序列结束,跳转执行步骤204;
步骤3、查询处理并提供二维结果集
步骤301、解析目标xml流数据文档,解析过程中根据产生的事件回调不同方法,其中事件“startelement”执行步骤302、事件“characters”执行步骤303、事件“endelement”执行步骤304;
步骤302、输入标签匹配搜索查询导航pat树中从当前标签节点也就是父标签节点开始通过pat辅助结构和其对应的快速搜索算法,能够快速检查确定是否定位到正确的孩子节点标签上,根据匹配结果更新上下文状态,包括:“接受”和“拒绝”状态;
步骤303、收集本次事件对应的标签值并放入缓存中;
步骤304、如果到达标注谓词计算位置的标签节点,则提取表达式中的各标签路径对应值,然后开始按照谓词表达式语法计算树结构来计算表达式,结果为真则执行步骤305,结果为假则拒绝收集以此标签节点为根节点的分支的所有标签值集;
步骤305、如果计算结果为真并且本标签节点为“接受”状态,则收集本次标签对应值并放入缓存中;
步骤306、收集所有缓存中的标签对应结果集,合并组成二维标签结果集,结束查询处理,并返回二维结果集。
作为优选,步骤3中查询处理过程以xml流数据为主导,查询导航pat树为辅助指导作用,同时记录系统的状态变化或者上下文变化;假定当前流数据节点元素nd下的某个孩子节点ndc,其标签为tdc,需要搜索匹配的对象是查询树中对应节点nq下的所有孩子标签节点标签列表tlqc,找到标签tdc对应查询树中孩子标签节点后同时检测其是否为查询聚焦的标签节点。因为该标签列表是当前节点下所有孩子节点的全集,对应需要的查询聚焦的孩子节点标签列表为tlqfc,二者的关系为tlqc包含tlqfc;采用patriciatrie匹配搜索算法进行匹配,分为如下几种情况:
a)查询聚焦标签列表tlqfc为空,意味着以ndc为根节点的数据分支无须继续查询处理,可以剪掉此数据分支;
b)tlqc等于tlqfc,意味着ndc数据节点无需匹配必然是是用户查询聚焦的标签,可以继续后续查询处理;
c)tlqfc不为空同时tlqc真包含tlqfc,采用patricia搜索算法,其中pat节点记录标签跳过的共同部分长度,分支对应不同的目标匹配标签,搜索从pat根节点依次向下,直到到达“接受”或“拒绝”pat节点;如果是“拒绝”pat节点,意味着以ndc为根节点的数据分支无须继续查询处理,可以剪掉此数据分支;如果是“接受”pat节点,意味着此ndc为查询聚焦的标签。
本发明的xml流数据的查询方法,在xml流数据中进行由多个具有复杂层次结构关系的标签路径组成的层次融合式查询,并构建了解决此问题的快速查询模型——快速xml多标签路径查询(qxmtq)。qxmtq模型基于简洁的查询接口(qi)、查询导航pat树数据结构模型(qgpatt)和快速查询处理引擎(qqe),其中在qi中提供要查询的标签路径,由模型自适应标签路径之间的复杂层次结构关系,支持谓词表达式参数接口(可选);qgpatt共享标签导航结构和辅助快速搜索结构pat可以使qqe更快速、更精准地匹配目标标签、过滤无关分支、查询并获取相关的标签值。通过测试表明qxmtq模型针对大规模xml流数据查询多个层次复杂的标签路径具有非常突出的查询时空效率。
附图说明
图1:xmlschema定义预处理流程图;
图2:查询参数预处理流程图;
图3:查询处理流程图。
具体实施方式
本发明提供一种xml流数据的快速查询方法,采用基于xml流数据的快速层次融合式查询模型qxmtq(quickxmlmultipletagsquery),该模型接收多个查询标签路径,这些路径之间的关系比较复杂,包括:“父子关系”、“兄弟关系”、“叔侄关系”、“祖先-子孙关系”、“叔公-侄孙关系”等。经过解析查询提取之后的结果集是一个二维的集合,第一维是按照xml数据中存放顺序的每个指定“家族”/分支对应的结果子集,第二维的结果子集是一个映射表,其中“键”对应的是标签路径,“值”是标签路径所指定的融合后的结果值。采用具体技术方案如下:
1、提供简单的查询接口
用户只需要简单地提供查询标签路径列表、指定的循环点标签路径和谓词表达式(可选)即可,不需要额外关注多个查询标签路径之间复杂的结构关系,不需要对查询过程进行干预,不需要做“二次编程”或者“再查找”收集结果的工作。系统会封装并自适应查询标签路径之间的复杂层次结构关系,查询并自动提取相应的结果值集合,使得用户能够更专注自己的业务需求,快速适应业务变化。
由于xml定义文件、查询请求参数同xml数据变化频度不一致,一般地,xml定义文件几乎不会变化;查询请求参数的预处理具有相对的独立性,不需每次处理xml数据之前处理xml定义文件或者查询参数,所以整个查询过程分为以下三大部分:
2、对xml定义文件的预处理
1)构建xml定义全集树,xmlschema描述了xml文档的整个结构,包括:文档中的元素定义、属性定义、子元素定义及子元素循环次数等信息。所有输入的xml流数据都遵循此描述定义,充分利用这些信息对xml的解析和查询过程进行指导同时过滤无关分支,能够加快处理速度。基于xmlschema定义的元素及其结构关系(元素和属性作为节点,结构关系作为导向指针)构建xml定义全集树(查询导航pat全集树的前身,只具有标签节点),此树中的节点称为标签节点;
2)构建“父-子”节点的patriciatrie索引,为了加快由父亲节点搜索寻找对应指定标签名字的孩子节点的过程,构建具有“父-子”节点的patriciatrie索引,作为匹配搜索的静态辅助索引结构。在所有的孩子标签字符串中寻找“共享”部分(pat结构节点),“不同”部分作为pat分支,依次类推最终构造具有patriciatries结构的查询导航pat全集树,该索引结构中的节点称为pat节点。
3、查询请求参数的预处理
3.1、构建谓词语法计算树
对输入的谓词表达式进行语法分析,分解谓词条件表达式之后构造谓词语法计算树,操作数作为叶子节点,把相关的操作符作为其父节点,依次类推。这里的操作数包括:数字、字符串、true、false以及标签路径(可以看作脚本语言变量,计算之前把其对应的标签值代入其中)。然后按照条件表达式语义分析谓词语法计算树,并整理成由条件分项组成的由条件分项组成的可计算序列。最后把每个条件表达式子项中涉及到的标签路径追加到查询标签路径列表中。
3.2、在查询导航pat全集树中聚焦查询标签路径
1)输入的查询标签路径列表中的每一条路径都是用户关注的,系统需要根据此路径到xml流数据中查询提取相关的标签值。因此,需要在xml定义导航pat全集树结构中针对符合查询标签路径的各中间标签节点标注:“拒绝”或“通过”;各叶子标签节点标注“拒绝”或“接受”;其它标签节点都为“拒绝”。同时在符合查询标签路径的每一“父子”标签节点的patriciatrie结构索引中也需要增加相关标注:查询标签的pat链中的各pat节点标注“通过”,最后一个pat节点标注“接受”,其它pat节点都为“拒绝”。最后经过针对查询标签路径聚焦后的树结构称为查询导航pat树。
2)每个构成查询树的节点除了要有标签的信息之外,还要有详尽的导航信息,方便对此查询树的遍历,同时还要标注可以对谓词表达式计算的位置。
4、查询处理并收集结果集
1)读入xml数据流文档,采用sax(simpleapiforxml)技术。sax是轻量级的xml解析方法,其大致工作过程为:阅读器(reader)首先读入部分xml流数据,后续的解析工作由事件驱动,包括:startdocument、enddocument、startelement、endelement及characters,依此类推重复上述过程直至xml流数据结束。对比dom解析,sax边读边解析,无需读入整个文档到内存,特别适合解析大型xml文档。本发明把只针对查询标签路径的查询过滤处理也加入到事件回调方法中,进一步缩小需匹配处理的xml数据量,有利于节省存储空间,减少解析时间,提高时空效率。
2)查询处理过程以xml流数据为主导,查询导航pat树为辅助指导作用,同时记录系统的状态变化或者上下文变化。
假定当前流数据节点元素nd下的某个孩子节点ndc,其标签为tdc,需要搜索匹配的对象是查询树中对应节点nq下的所有孩子标签节点标签列表tlqc,找到标签tdc对应查询树中孩子标签节点后同时检测其是否为查询聚焦的标签节点。因为该标签列表是当前节点下所有孩子节点的全集,对应需要的查询聚焦的孩子节点标签列表为tlqfc,二者的关系为tlqc包含tlqfc。为了加快匹配过程,本发明采用高效、快速的patriciatrie匹配搜索算法,分为如下几种情况:
a)查询聚焦标签列表tlqfc为空,意味着以ndc为根节点的数据分支无须继续查询处理,可以剪掉此数据分支;
b)tlqc等于tlqfc,意味着ndc数据节点无需匹配必然是是用户查询聚焦的标签,可以继续后续查询处理;
c)tlqfc不为空同时tlqc真包含tlqfc,采用patricia搜索算法,其中pat节点记录标签跳过的共同部分长度,分支对应不同的目标匹配标签,搜索从pat根节点依次向下,直到到达“接受”或“拒绝”pat节点。如果是“拒绝”pat节点,意味着以ndc为根节点的数据分支无须继续查询处理,可以剪掉此数据分支。如果是“接受”pat节点,意味着此ndc为查询聚焦的标签。
3)在已标注的计算点位置开始计算谓词表达式,结果为真则继续该分支的查询处理,否则要跳过对此分支的处理,跳转到下一个循环分支。
如图1、2、3所示,本发明xml流数据的快速查询方法,具体处理流程包括以下步骤:
步骤1、xmlschema定义预处理:构建查询导航pat树
步骤101搜索根元素并根据其元素信息创建查询树的根节点。
步骤102判断是否为schema定义文档中的最末元素,如果是结束此预处理,否则跳转到步骤103。
步骤103通过当前元素寻找所有子元素,构建相对应的子标签节点并放入查询树中,在该子标签节点中放入此子元素标签特定的详细信息,同时在父-子标签节点中放入导航信息,包括:“父子”指针、“子父”指针等。
步骤104根据节点及其所有直属孩子节点构建patriciatries辅助快速搜索结构,中间pat节点记录“共同”部分的长度,叶子pat节点指向对应的直属孩子标签节点。
步骤2、查询参数预处理:构建谓词表达式语法计算树、查询导航pat树
步骤201如果谓词表达式不存在的话,跳转到步骤204,如果存在,顺序执行下一步骤202。
步骤202按照表达式ebnf范式,语法分析谓词条件表达式,并把操作数作为叶子节点,相关的操作符作为其父节点,依次类推构造谓词语法计算树。
步骤203把每个条件表达式子项中的标签路径追加到查询标签路径表中。
步骤204判断是否查询标签路径列表末尾,如果不是执行步骤205,否则结束查询参数预处理。
步骤205至207针对每一查询标签路径,首先分拆成一个标签序列,按照顺序处理每一个标签,在查询导航pat树结构中的对应标签节点标注为需要查询聚焦:此标签节点状态为“通过”,同时把父标签节点通向该标签节点的每一个pat节点标注状态为“通过”,其它的pat节点的状态为“拒绝”。然后顺序检查下一个标签,重复执行步骤207,直到此标签序列结束,跳转执行步骤204。
步骤3、查询处理并提供二维结果集
步骤301解析目标xml流数据文档,解析过程中根据产生的事件回调不同方法,其中事件“startelement”执行步骤302、事件“characters”执行步骤303、事件“endelement”执行步骤304。在解析过程中直接开始查询过滤处理,减小需匹配处理的目标xml流数据规模,有利于节省存储空间,减少解析时间,提高时空效率。
步骤302输入标签匹配搜索查询导航pat树中从当前标签节点也就是父标签节点开始通过pat辅助结构和其对应的快速搜索算法,能够快速检查确定是否定位到正确的孩子节点标签上,根据匹配结果更新上下文状态,包括:“接受”和“拒绝”状态。
步骤303收集本次事件对应的标签值并放入缓存中。
步骤304如果到达标注谓词计算位置的标签节点,则提取表达式中的各标签路径对应值,然后开始按照谓词表达式语法计算树结构来计算表达式,结果为真则执行步骤305,结果为假则拒绝收集以此标签节点为根节点的分支的所有标签值集。
步骤305如果计算结果为真并且本标签节点为“接受”状态,则收集本次标签对应值并放入缓存中。
步骤306收集所有缓存中的标签对应结果集,合并组成二维标签结果集,结束查询处理,并返回二维结果集。
- 还没有人留言评论。精彩留言会获得点赞!