一种表格数据导入方法及系统与流程
本发明涉及数据处理领域,尤其涉及一种表格数据导入方法及系统。
背景技术:
一个成熟的企业管理系统中必然包含许多小型的信息管理系统,而每一个信息管理系统的核心必然是实现对数据的管理功能。
通常系统中需要实现excel批量导入数据到数据库的功能,而传统的基于orm框架的excel批量导入数据的做法是,首先读取excel文件中的数据,然后对读取的数据按excel行进行遍历,在遍历每一行时,需要对这一行的部分关键字段(列数据)进行验证,判断数据是否合法,如果不合法则停止执行并给出错误提示信息,如果合法则按行插入数据到数据库中。传统的基于orm框架的excel批量导入数据的大致流程如图5所示,
该方法为:
s51:读取表格数据;
s52:遍历数据;
s53:判断是否遍历到末尾,若是,结束执行;否则,验证每一行数据;
s54:判断数据是否合法,若不是,结束执行;
s55:若数据合法,新建orm对象;并填充orm对象属性并按行插入数据到数据库中。
传统的excel批量导入方法存在以下问题:
1.在遍历时需要对excel表格中每一行的数据进行验证,通常excel表格中不同的行之间存在许多重复的数据,没有必要对这些重复数据进行多次验证,只需要进行一次验证即可。
2.基于orm框架保存对象时,需要将每一行excel记录对应的一个orm对象,然后填充对象的属性并保存对象。传统方法中每一行记录对应一个orm对象,需要新建许多orm对象,这对内存资源将造成很大的消耗。
公开号为cn103744982a的专利提供了一种将表格数据导入数据库的方法,包括以下步骤:数据库系统建立excel报表模板配置文件,该配置文件用于定义excel报表模板的名称、至少一个标题以及各标题的数据类型;数据库系统根据下载请求由配置文件生成excel模板并提供下载;向下载的excel模板导入数据,导入结束后将excel报表上传至数据库系统;数据库系统自动将excel报表的数据保存到数据库。该方法遍历每一个数据,会造成重复验证等问题。
技术实现要素:
本发明要解决的技术问题目的在于提供一种表格数据导入方法及系统,用以解决表格数据批量导入时重复验证问题及orm对象共用及重用的问题。
为了实现上述目的,本发明采用的技术方案为:
一种表格数据导入方法,包括步骤:
s1、按照预设规则对导入的表格数据分组;所述分组后的每组数据有共同点或相似点;
s2、判断所述表格数据是否通过验证,若否,结束执行;若是,将每组表格数据对应一个新建的orm对象。
进一步地,还包括步骤:
根据分组对所述表格数据进行去重操作并批量验证所述分组后的表格数据是否合法。
进一步地,步骤s1具体包括:
判断表格数据的验证字段长度是否大于预设字段长度,若是,采用综合权重分组的方法;具体包括步骤:
为各个验证字段分配权重;
利用散列算法综合字段长度和字段的值得出散列值;
将各个字段散列值分别与对应的权重相乘并取和以得到综合散列值;
步骤s1具体还包括:若所述表格数据的字段长度不大于预设字段长度,则采用散列归并分组的方法,具体包括步骤:
将核心字段散列到预设范围;
根据分组数量进行归并分组。
进一步地,步骤s2具体包括:
判断每组内的表格数据是否有重复数据,若有,排除所述重复数据;
判断每组间的表格数据是否有重复数据,若有,排除所述重复数据。
进一步地,步骤s3中所述将每组表格数据对应一个新建的orm对象的步骤具体包括:
按照分组创建orm对象;
遍历所述分组后的表格数据;
判断是否遍历到分组末尾,若是,结束执行,否则,填充所述orm对象属性并保存所述orm对象。
一种表格数据导入系统,包括:
分组模块,用于按照预设规则对导入的表格数据分组;所述分组后的每组数据有共同点或相似点;
判断模块,用于判断所述表格数据是否通过验证,若否,结束执行;若是,将每组表格数据对应一个新建的orm对象。
进一步地,还包括:
验证模块,用于根据分组对所述表格数据进行去重操作并批量验证所述分组后的表格数据是否合法。
进一步地,所述分组模块还用于判断表格数据的验证字段长度是否大于预设字段长度,若是,采用综合权重分组的方法;具体包括:
分配权重单元,用于为各个验证字段分配权重;
计算散列值单元,用于利用散列算法综合字段长度和字段的值得出散列值;
综合权重单元,用于将各个字段散列值分别与对应的权重相乘并取和以得到综合散列值;
所述分组模块还用于若所述表格数据的字段长度不大于预设字段长度,则采用散列归并分组的方法,具体包括:
散列单元,用于将核心字段散列到预设范围;
归并单元,用于根据分组数量进行归并分组。
进一步地,所述验证模块包括:
组内去重单元,用于判断每组内的表格数据是否有重复数据,若有,排除所述重复数据;
组间去重单元,用于判断每组间的表格数据是否有重复数据,若有,排除所述重复数据。
进一步地,所述判断模块包括:
创建单元,用于按照分组创建orm对象;
遍历单元,用于遍历所述分组后的表格数据;
填充单元,用于判断是否遍历到分组末尾,若是,结束执行,否则,填充所述orm对象属性并保存所述orm对象。
本发明与传统的技术相比,有如下优点:
1.传统技术使用单线程方式,本发明采用多线程方式,提高了导入效率;
2.传统技术对每一行数据进行验证,会对许多重复的数据进行重复验证,本发明将有共同点的数据进行分组,然后使用批量验证的方式,对重复数据只进行一次验证,提高了验证效率,节约了计算机资源;
3.传统技术需要对每一行数据新建一个orm对象,本发明采用一个分组共用一个orm对象,实现orm对象的复用,提高了内存使用效率,减少了内存消耗。
附图说明
图1是实施例一提供的一种表格数据导入方法流程图;
图2是实施例二提供的一种表格数据导入方法流程图;
图3是实施例三提供的一种表格数据导入方法流程图;
图4是本发明实施例提供的一种表格数据导入系统结构图;
图5是传统的基于orm框架的表格数据批量导入的方法流程图。
具体实施方式
以下是本发明的具体实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
实施例一
本实施例提供了一种表格数据导入方法,如图1所示,包括步骤:
s11:按照预设规则对导入的表格数据分组;
s12:根据分组对所述表格数据进行去重操作并批量验证所述分组后的表格数据是否合法;
s13:判断所述表格数据是否通过验证,若否,结束执行;若是,将每组表格数据对应一个新建的orm对象。
orm即对象关系映射,是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。从效果上说,它其实是创建了一个可在编程语言里使用的--“虚拟对象数据库”。
orm框架采用元数据来描述对象一关系映射细节,元数据一般采用xml格式,并且存放在专门的对象一映射文件中。
其中,元数据是描述其它数据的数据,或者说是用于提供某种资源的有关信息的结构数据。元数据是描述信息资源或数据等对象的数据。
本实施例核心是按照一定的规则对需要导入的表格数据进行分组,然后对各个分组的数据进行批量验证,验证通过后则将分组数据插入数据库中,在将数据插入数据库时也做了部分优化。
本实施例中,步骤s11为按照预设规则对导入的表格数据分组。
其中,所述分组后的每组数据有共同点或相似点。
按照一定规则进行分组。此处分组的规则可以灵活地设置,比如可以将某一列数据相同的所有行分为一组,也可以将某几列数据相似的所有行分为一组,也可以设置更为复杂的分组规则,只要保证分组合理且分组内数据有共同点或相似点即可。
具体的,表1为一张用户信息的excel表格,其示例数据如表1所示。
用户信息包含用户名、电话号码、地址、邮箱、vip等级以及用户状态信息,在进行批量导入时,为了保证数据合法性和安全性,需要对用户名、电话号码、邮箱、vip等级和用户状态字段进行验证。
具体验证包括用户名长度验证、用户名合法性验证、电话号码长度验证和合法性验证、邮箱合法性验证、vip等级范围验证、用户状态范围验证。
表1用户信息的excel表格
对数据分组有很多种方式,例如可以把某字段相似的数据分为一组,把所有邮箱后缀相同的数据划分为一组,又或者把用户名长度一致的数据分为+组。
具体的,按照邮箱后缀进行分组,分组结果如表2所示。
表2按照邮箱后缀分组的excel表格
本实施例中,步骤s12为批量验证分组后的表格数据。
由于分组内许多数据都相同或相似,所以此处验证时对重复数据只需要验证一次,不需要再重复验证,通过分组批量可以解决重复验证的问题,提高了验证效率。
为了避免重复验证,首先需要进行去重操作,把重复的数据排除掉。此处去重包括两个部分,一是分组内部去重,二是分组之间去重。
本实施例中,步骤s12具体包括:
判断每组内的表格数据是否有重复数据,若有,排除所述重复数据;
判断每组间的表格数据是否有重复数据,若有,排除所述重复数据。
先进行组内的去重操作再进行组间的去重操作,可以将相同或相似的数据排除掉,节省验证次数,避免了重复验证,提高工作效率。
本实施例中,步骤s13为判断表格数据是否通过验证,若否,结束执行;若是,将每组表格数据对应一个新建的orm对象。
步骤s12分组验证完成后,为每一个分组创建一个orm对象,由于分组内数据有很多共同点或相似点,所以它们将共用一个orm对象,然后遍历分组内数据,填充orm对象属性以及保存对象,通过一个orm对象对应一组相似数据的方法,可实现orm对象的共用和重用。提高了内存使用效率,减少了内存消耗。
具体的,以表1示例数据为例,在进行用户状态字段的校验时,组内去重后的结果是:分组1(1、2)、分组2(1、3)、分组3(1)、分组4(1),组间去重后的结果是(1、2、3)。最开始由于重复数据的存在需要校验10次,去重后只需要校验3次即可。提高了验证效率,节约了计算机资源。
本实施例还提供了一种表格数据导入系统,如图4所示,包括:
分组模块41,用于按照预设规则对导入的表格数据分组;
验证模块42,用于批量验证所述分组后的表格数据;
判断模块43,用于判断所述表格数据是否通过验证,若否,结束执行;若是,将每组表格数据对应一个新建的orm对象。
本实施例中,分组模块41用于按照预设规则对导入的表格数据分组。
可以将某一列数据相同的所有行分为一组,也可以将某几列数据相似的所有行分为一组,也可以设置更为复杂的分组规则,只要保证分组合理且分组内数据有共同点或相似点即可。
本实施例中,验证模块42用于批量验证分组后的表格数据。
为了避免重复验证,首先需要进行去重操作,把重复的数据排除掉。此处去重包括两个部分,一是分组内部去重,二是分组之间去重。
本实施例中,验证模块42包括:
组内去重单元,用于判断每组内的表格数据是否有重复数据,若有,排除所述重复数据;
组间去重单元判断每组间的表格数据是否有重复数据,若有,排除所述重复数据。
先进行组内的去重操作再进行组间的去重操作,可以将相同或相似的数据排除掉,节省验证次数,避免了重复验证,提高工作效率。
本实施例中,判断模块42用于判断表格数据是否通过验证,若否,结束执行;若是,将每组表格数据对应一个新建的orm对象。
分组验证完成后,为每一个分组创建一个orm对象,可实现orm对象的共用和重用。提高了内存使用效率,减少了内存消耗。
实施例二
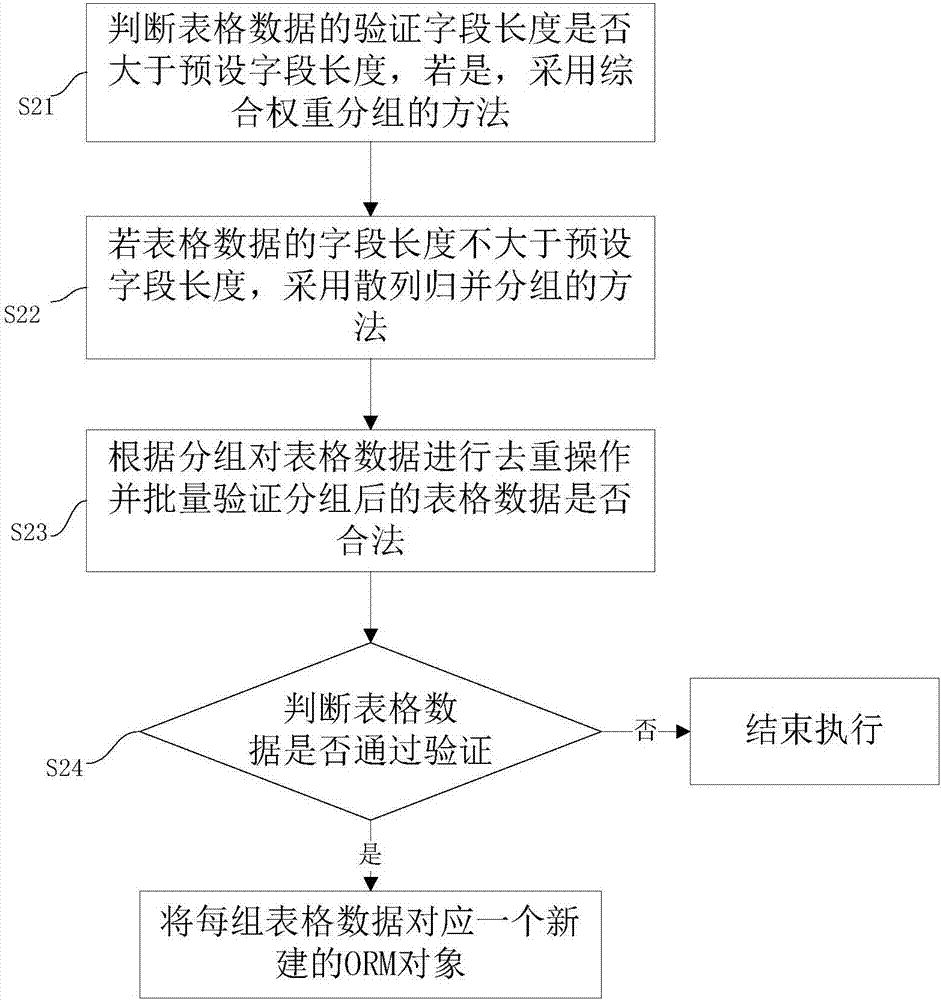
本实施例提供了一种表格数据导入方法,如图2所示,包括步骤:
s21:判断表格数据的验证字段长度是否大于预设字段长度,若是,采用综合权重的分组方法;
s22:若表格数据的验证再短长度不大于预设字段长度,采用散列归并分组的方法;
s23:根据分组对所述表格数据进行去重操作并批量验证所述分组后的表格数据是否合法;
s24:判断所述表格数据是否通过验证,若否,结束执行;若是,将每组表格数据对应一个新建的orm对象。
与实施例一不同之处在于,步骤s11包括步骤s21及步骤s22。
对数据的分组方式有很多种,且很灵活,例如可以把某字段相似的数据分为一组,把所有邮箱后缀相同的数据划分为一组,又或者把用户名长度一致的数据分为一组。
对于较为复杂的分组规则,分组方式具体包括:
s21:判断表格数据的验证字段长度是否大于预设字段长度,若是,采用综合权重的分组方法;
s22:若表格数据的验证再短长度不大于预设字段长度,采用散列归并分组的方法;
本实施例中,步骤s21具体包括:
为各个验证字段分配权重;
利用散列算法综合字段长度和字段的值得出散列值;
将各个字段散列值分别与对应的权重相乘并取和以得到综合散列值。
具体的,若表格数据的字段长度大于预设字段长度,判定为验证字段较多,通常各个字段的重要性和安全性要求存在一定的差别,所以采用综合权重分组的方法。
首先按照一定的规则为各个字段分配权重,之后利用一定的hash算法综合字段长度和字段的值得出某个范围的hash值,再将各个字段hash值分别与对应的权重相乘并取和,得到该列数据综合hash值。之后根据综合hash值进行分段并划分成不同的分组。
hash,一般翻译做“散列”,就是把任意长度的输入(又叫做预映射),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
本实施例中,步骤s22具体包括:
将核心字段散列到预设范围;
根据分组数量进行归并分组。
具体的,若表格数据的字段长度不大于预设字段长度,判定各位验证字段较少,采用将核心字段hash散列到一定的范围,再将hash结果根据分组数量进行归并分组的方法。
具体的,以表1的示例数据为例,假设需要对用户名、电话号码、邮箱、vip等级以及用户状态字段进行验证,且要求对电话号码和邮箱进行严格的验证,则首先按照一定的规则为各个验证字段分配权重,例如(用户名:电话号码:邮箱:vip等级:用户状态=2:3:3:1:1),之后利用一定的hash算法综合字段长度和字段的值得出某个范围的hash值,再将各个字段hash值分别与对应的权重相乘并取和,得到该列数据综合hash值。之后根据综合hash值进行分段并划分成不同的分组。
若表格数据的字段不大于预设字段,判定各位验证字段较少,采用将核心字段hash散列到一定的范围,再将hash结果根据分组数量进行归并分组的方法。以表1的实力数据为例,假设只要验证用户名和电话号码字段,那么采用一定的hash算法综合核心字段的内容以及长度等信息,最终将hash结果转换成0到1之间的浮点数,然后根据表格数据量大小确定分组数量为5,那么hash结果的值将被划分出0-0.2、0.2-0.4、0.4-0.6、0.6-0.8、0.8-1.0五个区间,hash结果的值再同一区间的为一组数据。
本实施例还提供了一种表格数据导入系统,如图4所示,包括:
分组模块41,用于按照预设规则对导入的表格数据分组;
验证模块42,用于批量验证所述分组后的表格数据;
判断模块43,用于判断所述表格数据是否通过验证,若否,结束执行;若是,将每组表格数据对应一个新建的orm对象。
与实施例一不同之处在于,所述分组模块41还用于判断表格数据的验证字段长度是否大于预设字段长度,若是,采用综合权重的分组方法;具体包括:
分配权重单元,用于为各个验证字段分配权重;
计算散列值单元,用于利用散列算法综合字段长度和字段的值得出散列值;
综合权重单元,用于将各个字段散列值分别与对应的权重相乘并取和以得到综合散列值。
具体的,若表格数据的字段长度大于预设字段长度,判定为验证字段较多,通常各个字段的重要性和安全性要求存在一定的差别,所以采用综合权重分组的方法。
首先按照一定的规则为各个字段分配权重,之后利用一定的hash算法综合字段长度和字段的值得出某个范围的hash值,再将各个字段hash值分别与对应的权重相乘并取和,得到该列数据综合hash值。之后根据综合hash值进行分段并划分成不同的分组。
hash,一般翻译做“散列”,就是把任意长度的输入(又叫做预映射),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
本实施例中,分组模块41还用于若所述表格数据的字段长度不大于预设字段长度,则采用散列归并分组的方法,具体包括:
散列单元,用于将核心字段散列到预设范围;
归并单元,用于根据分组数量进行归并分组。
若表格数据的验证再短长度不大于预设字段长度,采用散列归并分组的方法。
具体的,若表格数据的字段长度不大于预设字段长度,判定各位验证字段较少,采用将核心字段hash散列到一定的范围,再将hash结果根据分组数量进行归并分组的方法。
实施例三
本实施例提供了一种表格数据导入方法,如图3所示,包括步骤:
s31:按照预设规则对导入的表格数据分组;
s32:根据分组对表格数据进行去重操作并批量验证所述分组后的表格数据是否合法;
s33:判断所述表格数据是否通过验证,若否,结束执行;:
s34:若所述表格数据通过验证,按照分组创建orm对象;
s35:遍历所述分组后的表格数据;
s36:判断是否遍历到分组末尾,若是,结束执行;否则,填充所述orm对象属性并保存orm对象。
与实施例一、二不同之处在于,所述将每组表格数据对应一个新建的orm对象的步骤具体包括步骤s33、s34、s35、s36。
分组验证完成后,为每一个分组创建一个orm对象,由于分组内数据有很多共同点或相似点,所以它们将共用一个orm对象,然后遍历分组内数据,填充orm对象属性以及保存对象。
传统方法使用单线程方式,本实施例使用多线程方式。每个分组对应一个子线程。
其中,多线程是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。
首先在子线程新建一个orm对象,分组内所有数据都对应这个orm对象,然后遍历分组内的数据,每次遍历都执行填充orm对象属性和保存对象的操作,以此实现对该orm对象的共用及重用,减少内存消耗并提高导入效率。
具体的,以表1的为例,新建一个orm对象,然后填充对象属性,包括用户名和电话号码等字段,然后保存该对象到数据库中,以类似的操作继续存储剩余的3条数据,知道遍历完分组内所有数据。
本实施例还提供了一种表格数据导入系统,如图4所示,包括:
分组模块41,用于按照预设规则对导入的表格数据分组;
验证模块42,用于批量验证所述分组后的表格数据;
判断模块43,用于判断所述表格数据是否通过验证,若否,结束执行;若是,将每组表格数据对应一个新建的orm对象。
与实施例二不同之处在于,所述判断模块43包括:
创建单元,用于按照分组创建orm对象;
遍历单元,用于遍历分组后的表格数据;
填充单元,用于判断是否遍历到分组末尾,若是,结束执行,否则,填充orm对象属性并保存orm对象。
具体的,以表1的为例,新建一个orm对象,然后填充对象属性,包括用户名和电话号码等字段,然后保存该对象到数据库中,以类似的操作继续存储剩余的3条数据,知道遍历完分组内所有数据。
本实施例可实现对该orm对象的共用及重用,减少内存消耗并提高导入效率。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!