一种高效的粮食舆情监控系统的制作方法
本发明创造涉及舆情监控领域,具体涉及一种高效的粮食舆情监控系统。
背景技术:
粮食是一个国家巩固、稳定的基本,随着社会的发展,粮食现代市场在不断的改革和调整,粮食的流通体制越来越丰富,然后这在一定程度上增加了粮食危机的系数,因此,对粮食市场以及粮食危机的实时监控,有利于预防粮食危机的产生和加剧,对于稳定粮食市场有着极其重要的意义。
随着科技的进步、互联网的发展,社会舆论的网络已成为可以表达民众观点、立场和情感的重要载体,网络舆论中反应了当今社会中人们较为关注的问题,随着网络的普及,参与者的增加,致使产生网络舆情的速率急速增长,网络舆情对社会带来的影响也迅速增大,研究发现,随着粮食相关网站的兴起,粮食网络已经逐步发展起来,粮食网络舆情的分析研究有利于实时了解粮食市场的舆论走向,从而及时进行应对和改进,对于营造一个安稳的粮食网络环境有着积极的作用。
技术实现要素:
针对上述问题,本发明旨在提供一种高效的粮食舆情监控系统。
本发明创造的目的通过以下技术方案实现:
一种高效的粮食舆情监控系统,包括舆情采集模块、舆情处理模块和客户端模块,所述舆情采集模块用于设定粮食相关网站的链接为种子链接,并采用主题爬虫策略从此种子链接出发,搜集与粮食主题相关的网页,所述舆情处理模块用于对采集得到的网页进行正文部分的提取并对正文部分进行中文分词,从所述中文分词结果中提取具有代表性的特征项并计算相应特征项的权重,从而通过计算网页的主题相似性系数,对采集得到的网页进行筛选,所述客户端模块用于存储粮食主题相关的网页信息,用户可以通过访问客户端模块实时了解粮食的舆情信息。
本发明创造的有益效果:提出一种高效的粮食舆情监控系统,通过互联网上有关粮食信息的有效抓取、处理和分析,对网络上有关粮食信息的舆情实现了有效监控。
附图说明
利用附图对发明创造作进一步说明,但附图中的实施例不构成对本发明创造的任何限制,对于本领域的普通技术人员,在不付出创造性劳动的前提下,还可以根据以下附图获得其它的附图。
图1是本发明结构示意图;
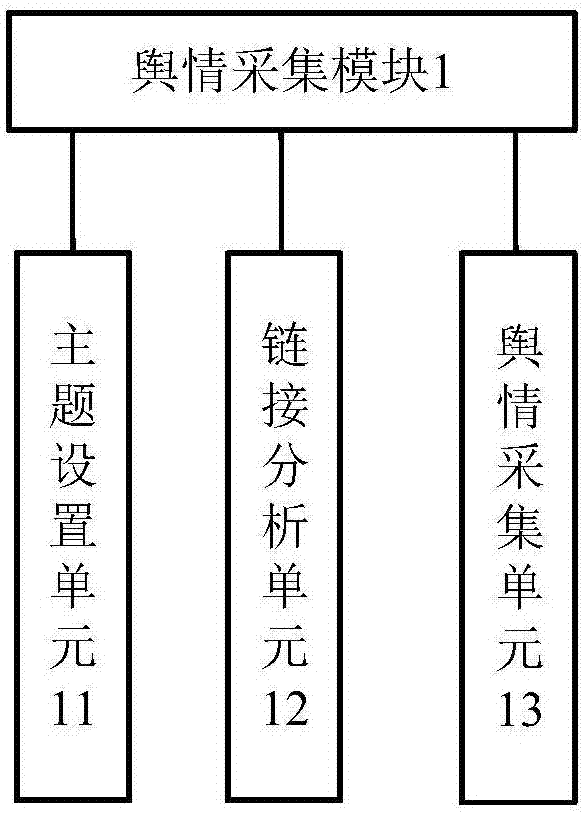
图2是本发明舆情信息采集模块结构示意图
图3是本发明舆情信息处理模块结构示意图。
附图标记:
舆情采集模块1;舆情处理模块2;客户端模块3;主题设置单元11;链接分析单元12;舆情采集单元13;特征项提取单元21;权重计算单元22;网页筛选单元23。
具体实施方式
结合以下实施例对本发明作进一步描述。
参见图1、图2和图3,本实施例的一种高效的粮食舆情监控系统,包括舆情采集模块1、舆情处理模块2和客户端模块3,所述舆情采集模块1用于设定粮食相关网站的链接为种子链接,并采用主题爬虫策略从此种子链接出发,搜集与粮食主题相关的网页,所述舆情处理模块2用于对采集得到的网页进行正文部分的提取并对正文部分进行中文分词,从所述中文分词结果中提取具有代表性的特征项并计算相应特征项的权重,从而通过计算网页的主题相似性系数,对采集得到的网页进行筛选,所述客户端模块3用于存储粮食主题相关的网页信息,用户可以通过访问客户端模块3实时了解粮食的舆情信息。
优选地,所述客户端模块3为安装有相关应用的智能手机或平板电脑。
本优选实施例提出一种高效的粮食舆情监控系统,通过互联网上有关粮食信息的有效抓取、处理和分析,对网络上有关粮食信息的舆情实现了有效监控。
优选地,所述舆情采集模块1包括主题设置单元11、链接分析单元12和舆情采集单元13,所述主题设置单元11用于根据本系统的主题设置粮食相关网站的网页链接为种子链接,所述链接分析单元12用于分析url队列中链接的主题相关度,去除主题相关度较小的链接,所述舆情采集单元13用于根据设置的初始链接,采用主题爬虫策略进行主题相关网页的爬取。
本优选实施例构成了本系统的舆情信息采集模块,通过分析url队列中链接的主题相关度,去除主题相关度较小的链接,只对主题相关度较高的网页进行爬虫,提高了爬虫的可靠性和效率。
优选地,所述链接分析单元12用于分析url队列中链接的主题相关度,确定与本系统主题相关的网页链接,具体包括:
(1)分析主题相关网页的ip链接中url字符串的特点,定义url字符串中代表粮食主题的关键词组d,则网页的url字符串的网页系数x1为:
式中,dr为采集得到的网页的url中包含的词组d中的关键词的个数,d为网页链接的url中代表粮食主题相关的关键词组;
(2)分析主题相关的网页的锚文本的特点,则网页的锚文本的网页系数x2为:
式中,mr为网页中锚文本中包含的关键词组g中的关键词的个数,g为代表粮食主题的关键词组;
(3)根据上述所得的网页系数x1和网页系数x2,计算网页的主题相关度系数ε,则ε的表达式为:
式中,x1为url字符串的网页系数,x2为锚文本的网页系数,σ1和σ2分别为url字符串的网页系数x1和锚文本的网页系数x2的权重;
(4)定义网页主题相关阈值γ,则当ε大于阈值γ时即确定为主题相关链接,予以保留,当ε小于阈值γ时,即确定为主题不相关链接,则删除此网页链接。
针对本实施例,根据采集得到的网页链接进行了一系列的测试,测试结果如下:
从上述测试结果可以看出,本优选实施例通过对网页的url字符串和锚文本的关键词进行分析,计算链接的主题相关度,有效的去除了主题相关度较小的链接,提高了系统的工作效率。
所述舆情处理模块2包括特征项提取单元21、权重计算单元22和网页筛选单元23,所述特征项提取单元21用于从正文部分的分词结果中选取具有代表性的特征项,所述权重计算单元22用于计算所述特征项在文本中的权重,所述网页筛选单元23用于通过计算网页的主题相似性系数,从而筛选出主题相关的网页进行保存。
优选地,所述特征项提取单元21用于从正文部分的分词结果中提取特征项,其采用一种改进的信息增益计算方法进行特征项的选择,具体包括:
定义采集得到的文档中类别为ci(1≤i≤m)的文本有{ci1,ci2,……ciy},则改进的信息增益ig(ci,tj)的计算方法为:
式中,p(tj)为特征词tj出现的概率,则
选取信息增益值较大的前t个特征词作为本文档的特征项。
本优选实施例在信息增益的计算过程中结合对特征项在各类文本和出现的频度以及分散度的计算,增加了特征项的分类能力,有助于选出较有效的特征项。
优选地,所述权重计算单元22用于计算所述特征项在文本中的权重,则特征项tj对应的权重的计算公式为:
式中,lij表示特征项tj在文本bi中出现的频数,
本优选实施例采用一种改进的权重计算方法,引进了特征项在文本集中出现的平均频数,综合考虑了特征项在文本集中的总体价值,充分体现了特征项权重的重要性。
优选地,所述网页筛选单元23用于通过计算网页相似度系数,筛选出主题相关的网页进行保存,具体包括:
a.选取主题相关网页作为样本网页进行处理,则处理后的样本文档为nd=(td1,td2,td3,……tdr);
b.对于采集得到的文档ny=(ty1,ty2,ty3,……tyt),其与样本文档的主题相似性系数计算公式如下:
f(tyk)=max{sim(tyk,td1),sim(tyk,td2),……sim(tyk,tdr)}(k=1,2……t)
式中,syd为文档ny和样本文档nd之间的主题相似性系数,f(tyk)表示文档ny中的特征项tyk和样本文档nd中的各个特征项之间的概念词语相似度的最大值,uyk为文档ny中的特征项tyk的权重,udl为特征项uyk和样本文档nd中概念词语最大相似度的特征项tdl的权重;
c.定义主题阈值为ρ,根据主题相似性系数和主题阈值之间的关系对采集得到的网页进行筛选,具体为:
式中,syg为文档ny和样本文档nd之间的主题相似性系数;
d.当判断为主题相关网页时,即将网页送入客户端模块3进行存储,并将主题相关网页中包含的链接加入主题爬虫的等待队列,当判断为非主题相关网页时即舍弃。
本优选实施例在计算文档相似性系数的过程中,引进了相应的特征项的权重进行综合计算,解决了不同特征项对文档相似性系数影响程度不同的问题,提高了文档相似性系数计算的准确性,此外,通过文档相似性系数和主题阈值之间的比较进行网页筛选,能够较为有效的进行主题相关网页的判别。
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
- 还没有人留言评论。精彩留言会获得点赞!