基于Kinect深度相机的人体分割方法与流程
本发明属于计算机视觉领域,具体而言,主要涉及数字图像处理以及计算机视觉领域,是基于kinect深度相机的人体分割方法。
背景技术:
人体分割是3d人体重建,3d运动捕捉和人体参数估计等应用的重要步骤,获取准确的人体分割结果变的尤为重要。但是由于许多不同因素的影响,例如图像噪声干扰、空间遮挡、颜色信息的相似性和复杂背景的出现,会使分割结果变的不理想。人体分割的主要挑战是处理那些与头发、皮肤、衣服具有相同颜色的物体。2011年微软发布了kinectv2深度相机,不同于利用散斑结构光成像原理的第一代kinect相机,kinectv2利用tof(时间飞行)技术,能够获取比第一代kinect准确性更高的深度图像,其包含一个彩色相机和一个深度相机,为科研和工业应用提供了便利。除了提供rgb-d(彩色深度)数据,kinectv2也提供了采集场景中人的骨架信息。
目前,已经有大量基于不同信息的人体分割方法被提出,可以分为以下几类:1)基于彩色图的方法:gulshan等人(gulshanv,lempitskyv,zissermana.humanisinggrabcut:learningtosegmenthumansusingthekinect[c]//ieeecomputervisionworkshops.2011:1127–1133.)提出训练kinect深度相机采集的数据的自下而上学习算法获得人体分割结果。rother等人(rotherc,kolmogorovv,andblakea.grabcut:interactiveforegroundextractionusingiteratedgraphcuts[j].acmtransactionsongraphics(tog),2004:309–314.)用交替迭代的高斯混合模型分别对前背景建模进行分割,li等人(lis,luh,shaox.humanbodysegmentationviadata-drivengraphcut[j].ieeetransactionsoncybernetics,2014:2099–2108.)提出了在图割框架中结合从上而下和从下而上线索的数据驱动的方法,但是这些方法由于只利用彩色信息而不能很好的区分那些颜色相近的物体。2)基于深度图的方法:shotton等人(shottonj,sharpt,kipmana,etal.real-timehumanposerecognitioninpartsfromsingledepthimages[j].communicationsoftheacm,2013:116–124.)提出用深度图来提取人体动作的方法,hern′andez-vela(hern′andez-velaa,zlatevan,marinova,etal.graphcutsoptimizationformulti-limbhumansegmentationindepthmaps[c]//ieeecomputervisionandpatternrecognition.2012:726–732.)提出建立在随机森林和图割理论基础上用深度图进行人体分割的方法,但这种只利用深度信息的方法往往需要训练大量数据。3)基于rgb-d的方法:palmero等人(palmeroc,clap′esa,bahnsenc,etal.multi-modalrgb–depth–thermalhumanbodysegmentation[j].internationaljournalofcomputervision.2016:1–23.)提出了结合新颖的数据集和多模式分割基线的多模式分割方法。vineet等人(vineetv,sheasbyg,warrellj,etal.posefield:anefficientmean-fieldbasedmethodforjointestimationofhumanpose,segmentation,anddepth[c]//ieeecomputervisionandpatternrecognition(cvpr).2013:180–194.)提出了针对联合估计人体分割、姿态、人体部分和深度的有效的滤波均值场交互方法。yang等人(yangj,ganz,lik,etal.graph-basedsegmentationforrgb-ddatausing3-dgeometryenhancedsuperpixels[j].ieeetransactionsoncybernetics.2015:927–940.)采用分两步的分割方法,先用超像素聚合算法产生超像素,而后在融合阶段对产生的超像素进行融合来产生语意连贯的分割结果。4)基于骨架的方法:junior(juniorj,jungc,musses.skeleton-basedhumansegmentationinstillimages[c]//icip.2012:141–144.)等人提出了在骨架模型上寻找基于图的最大值路径的方法来产生人体分割轮廓。由于缺乏颜色信息,造成了不平滑的人体轮廓分割结果。
技术实现要素:
本发明旨在克服现有技术的不足,实现采集信息的充分利用,与只基于单纯彩色信息、深度信息、rgb-d信息或骨架信息的方法不同,本发明在图优化框架下联合利用rgb-d信息和骨架信息来产生更好的分割结果。本发明采取的技术方案是,基于kinect深度相机的人体分割方法,步骤是:在过分割阶段首先对原始深度图进行扭转修复得到与彩色图相同分辨率的高质量深度图;利用超像素聚集算法对rgb-d数据进行聚集得到超像素;然后在融合阶段构建能量函数模型,设计能量函数的数据项和光滑项,最小化能量函数来实现基于rgb-d和骨架信息的图模型的超像素融合。
其中:
1)基于rgb-d数据的图像过分割
11)对原始深度图进行扭转填充:运行kinect深度相机软件开发程序sdk将深度图扭转到彩色图的坐标系下,引入彩色边缘图来控制深度扩散顺序,保证深度图在空洞区域由外向内扩散填充,针对边缘像素x的深度dx,滤波方程为:
其中,w为标准化系数,i为同一坐标系下的高质量彩色图像;
12)基于图像的rgb-d数据,通过一种类似k均值即k-means的超像素迭代算法,即把k-means算法的全局搜索范围限定为2s*2s的扫描区域,s为种子点间的步长,迭代划分离该种子距离最近的像素归集到超像素块中,最后检查每个超像素的有效性,去除无效的超像素;
2)基于rgb-d和骨架信息的图模型的超像素融合:
21)构建图模型的能量函数的构建:用s表示一个超像素,s={sp|p=1,…m}表示经过过分割算法的所有超像素集合,这当中m=|s|是集合中超像素的个数,用l:={body,background}表示所有的标签,其中body和background分别表示人体和背景,接下来的融合问题为每一个超像素s∈s分配一个标签记为fs∈f,定义最小化能量函数:
e(f)=edata(f)+esmooth(f)(2)
公式中edata(f)表示数据项,反映超像素s被标记body和background的可能性,esmooth(f)表示平滑项,反映相邻超像素对的空间平滑性,利用α-expansion算法来最小化整个能量函数;
22)能量函数的数据项的构建:数据项表示超像素与标签的接近程度,对于一个超像素连接到某个标签之间的数据项:
数据项分为两个部分,参数λ1表示骨架项的影响程度,公式(4)第一个部分是基于rgb-d数据的
其中
其中,α,β是控制sigmoid函数坡度和相位的参数,d(s,k)表示超像素到骨架的距离:
其中
23)能量函数的平滑项的构建:平滑项度量所有超像素对之间的平滑程度,它是所有超像素对的平滑项之和:
其中n表示超像素对的集合,
其中对应代价为:
gij=λ2cij+λ3hij(11)
λ2,λ3为控制参数,在上式中,cij表示连通项分量,在基于像素层次的分割设计中,相邻节点之间的平滑项可以度量彩色信息的差异,由于超像素是一群像素的集合,不能直接考虑相邻超像素之间的差异程度,在边界上找到一个梯度变化最小的方向,作为超像素之间连接的方向,通过度量这个方向上的彩色差异程度,来计算连通性分量,用ωij表示超像素对si与sj相邻边界上的像素,那么连通性分量的计算方法如下式所示:
其中ip像素p的彩色信息,iq是像素p的8联通临域中的像素q的彩色信息,|ωij|表示在边界ωij上的所有像素点个数,σ1是控制指数衰减的参数,
其中σ2是用来控制衰减率的参数,ρ(hi,hj)为直方图矢量间相关系数,用mi和mj分别表示直方图矢量hi和hj的均值,那么相关系数ρ(hi,hj)的计算方法如下:
其中控制衰减率参数σi和σj是用类似的方法计算的,计算过程如下:
其中j是直方图中总的柱状条数。
本发明的技术特点及效果:
本发明针对人体分割问题,通过将rgb-d和骨架信息进行融合来实现复杂场景的人体分割问题,基于图论的超像素融合算法,比基于像素的图论分割算法维度低很多,从而大大降低了运算复杂度。通过寻求能量函数的最优解,得到全局最佳的超像素融合方法,从而在图像分割出人。
具体地,本发明具有以下特点:
1)运用深度修复算法,修复原始深度图的空洞,得到高质量的深度图。
2)骨架提供更好的轮廓信息,选取人体骨架的节点,提出超像素到人体骨架的度量方法。
3)提出彩色深度信息和人体骨架信息联合使用的算法框架,结合每种信息的特点,设计每一项的组成,得到更为准确的人体分割结果。
附图说明
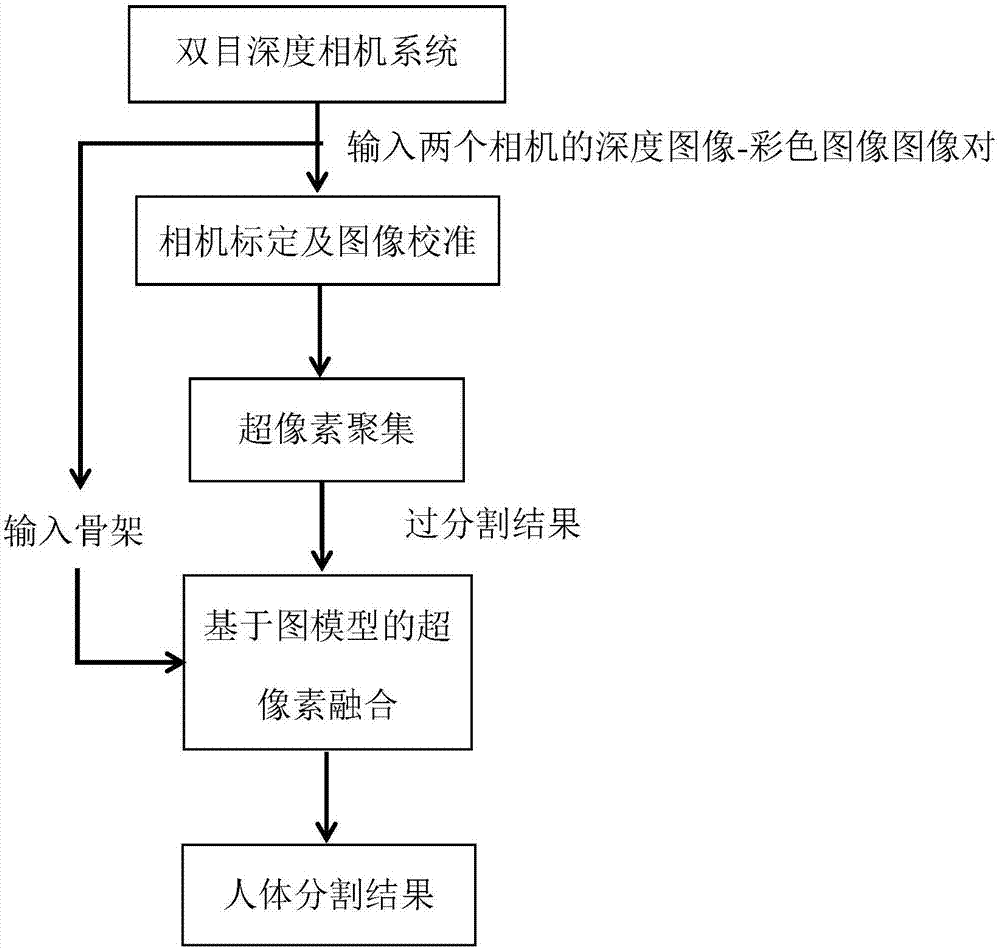
图1是本发明方法的流程图;
图2是本发明中采集的彩色图(左)和原始深度图(中)和修复得到的归一化深度图(右);
图3是度量超像素种子点到人体骨架距离的示意图;
图4是不同场景下人体分割的结果图:a)原始彩色图;b)分割后的结果图(左上方标注的是theoverlappingvalue);c)groungtruth(真值图);
图5是局部残差图及其放大图。
具体实施方式
在传统基于彩色图或深度图人体分割的基础上引入骨架信息,将多种信息结合起来,提出算法框架来得到更加准确的人体分割结果。下面结合附图和实施例对本发明作详细说明。
1)基于rgb-d数据的图像过分割
11)对原始深度图进行扭转填充:运行kinect深度相机的sdk(软件开发程序)将深度图扭转到彩色图的坐标系下,引入彩色边缘图来控制深度扩散顺序,保证深度图在空洞区域由外向内扩散填充,针对边缘像素x的深度dx,滤波方程为:
其中,w为标准化系数,i为同一坐标系下的高质量彩色图像;
12)超像素聚集根据图像的rgb-d数据,通过一种类似k-means的超像素迭代算法来迭代划分每一个像素属于哪个超像素块。将图像的超像素个数设置为m,每个超像素块都初始化有一个种子点,相邻的种子之间间隔是s。本发明初始化的间距设置为等间距,使用一个较大的m值,以便在物体之间得到更为准确的边界。将深度图映射到三维空间,结合彩色信息和二维平面坐标信息;来推动一种类似k-means的超像素迭代算法得到超像素。最后检查每个超像素的有效性,去除无效的超像素,比如说超像素过小,并将其归并到相邻超像素中。
2)基于rgb-d和骨架信息的图模型的超像素融合:
21)构建图模型的能量函数的构建:用s表示一个超像素,s={sp|p=1,…m}表示经过过分割算法的所有超像素集合,这当中m=|s|是集合中超像素的个数,用l:={body,background}表示所有的标签,其中body和background分别表示人体和背景。接下来的融合问题可以理解成为每一个超像素s∈s分配一个标签记为fs∈f,定义最小化能量函数:
e(f)=edata(f)+esmooth(f)(2)
公式中edata(f)表示数据项,反映超像素s被标记body和background的可能性,esmooth(f)表示平滑项,反映相邻超像素对的空间平滑性,利用α-expansion算法来最小化整个能量函数;
22)能量函数的数据项的构建:数据项表示超像素与标签的接近程度,对于一个超像素连接到某个标签之间的数据项:
数据项分为两个部分,参数λ1表示骨架项的影响程度,公式(4)第一个部分是基于rgb-d数据的
其中
其中,α,β是控制sigmoid函数坡度和相位的参数。d(s,k)表示超像素到骨架的距离
其中
23)能量函数的数据项的构建:平滑项度量所有超像素对之间的平滑程度,它是所有超像素对的平滑项之和:
其中n表示超像素对的集合,
其中对应代价为:
gij=λ2cij+λ3hij(11)
λ2,λ3为控制参数,在上式中,cij表示连通项分量,在基于像素层次的分割设计中,相邻节点之间的平滑项可以度量彩色信息的差异。由于超像素是一群像素的集合,不能直接考虑相邻超像素之间的差异程度,我们可以在边界上找到一个梯度变化做小的方向,作为超像素之间连接的方向,通过度量这个方向上的彩色差异程度,来计算连通性分量。用ωij表示超像素si与sj相邻边界上的像素,那么,连通性分量的计算方法可以如下式所示:
其中ip为像素p的彩色信息,iq是像素p的8联通临域中的像素q的彩色信息,|ωij|表示在边界ωij上的所有像素点个数,σ1是控制指数衰减的参数,
其中σ2是用来控制衰减率的参数,ρ(hi,hj)为直方图矢量间相关系数,用mi和mj分别表示直方图矢量hi和hj的均值,那么相关系数ρ(hi,hj)的计算方法如下:
其中控制衰减率参数σi和σj是用类似的方法计算的,计算过程如下:
其中j是直方图中总的柱状条数。
基于图论的超像素融合算法,比基于像素的图论分割算法维度低很多,从而大大降低了运算复杂度。通过寻求能量函数的最优解,得到全局最佳的超像素融合方法,从而在图像分割出人。
本发明方法将rgb-d信息与骨架信息相结合,提出基于多种信息的算法框架,从而得到更好的分割结果,即实现对场景中人的准确分割。(实验流程图如图1所示)。结合附图和实施例的详细说明如下:
1)试验中kinectv2采集的彩色图分辨率时1920*1080,深度图是512*424,利用kinectv2的sdk(软件开发程序)将深度图扭转到彩色图坐标系下,得到相同分辨率的彩色图和深度图(如图2所示)。引入彩色边缘图像控制深度扩散顺序,保证在空洞区域由外向内扩散填充。针对边缘像素x的深度dx,滤波方程为:
其中,w为标准化系数,i为同一坐标系下的高质量彩色图像;
12)超像素聚集根据图像的rgb-d数据,通过一种类似k-means的算法来迭代划分每一个像素属于哪个超像素块。将图像的超像素个数设置为m,每个超像素块都初始化有一个种子点。本发明初始化的间距设置为等间距,使用一个较大的m值,以便在物体之间得到更为准确的边界,对应值分别取一系列值观察,发现取800较为合适。将深度图映射到三维空间,结合彩色信息和二维坐标信息;来推动一种类似k-means的超像素迭代算法得到超像素。最后检查每个超像素的有效性,去除无效的超像素,比如说超像素过小,并将其归并到相邻超像素中。
2)基于rgb-d和骨架信息的图模型的超像素融合:
21)构建图模型的能量函数的构建:用s表示一个超像素,s={sp|p=1,…m}表示经过过分割算法的所有超像素集合,这当中m=|s|是集合中超像素的个数,用l:={body,background}表示所有的标签,其中body和background分别表示人体和背景。接下来的融合问题可以理解成为每一个超像素s∈s分配一个标签记为fs∈f,定义最小化能量函数:
e(f)=edata(f)+esmooth(f)(2)
公式中edata(f)表示数据项,反映超像素s被标记body和background的可能性,esmooth(f)表示平滑项,反映相邻超像素对的空间平滑性,利用α-expansion算法来最小化整个能量函数;
22)能量函数的数据项的构建:数据项表示超像素与标签的接近程度,对于一个超像素连接到某个标签之间的数据项:
数据项分为两个部分,参数λ1表示骨架项的影响程度,公式(4)第一个部分是基于rgb-d数据的
其中
其中,α,β是控制sigmoid函数坡度和相位的参数。d(s,k)表示超像素到骨架的距离
其中
23)能量函数的数据项的构建:平滑项度量所有超像素对之间的平滑程度,它是所有超像素对的平滑项之和:
其中n表示超像素对的集合
其中对应代价为:
gij=λ2cij+λ3hij(11)
λ2,λ3控制参数,在上式中,cij表示连通项分量,在基于像素层次的分割设计中,相邻节点之间的平滑项可以度量彩色信息的差异。由于超像素是一群像素的集合,不能直接考虑相邻超像素之间的差异程度,我们可以在边界上找到一个梯度变化做小的方向,作为超像素之间连接的方向,通过度量这个方向上的彩色差异程度,来计算连通性分量。用ωij表示超像素si与sj相邻边界上的像素,那么,连通性分量的计算方法可以如下式所示:
其中ip为像素p的彩色信息,iq是像素p的8联通临域中的像素q的彩色信息,|ωij|表示在边界ωij上的所有像素点个数,σ1是控制指数衰减的参数,
其中σ2是用来控制衰减率的参数,ρ(hi,hj)为直方图矢量间相关系数,用mi和mj分别表示直方图矢量hi和hj的均值,那么相关系数ρ(hi,hj)的计算方法如下:
其中控制衰减率参数σi和σj是用类似的方法计算的,计算过程如下:
其中j是直方图中总的柱状条数。
基于图论的超像素融合算法,比基于像素的图论分割算法维度低很多,从而大大降低了运算复杂度。通过寻求能量函数的最优解,得到全局最佳的超像素融合方法,从而在图像分割出人。实验结果:本发明采用theoverlappingvalue(重叠值)作为图像填充结果的度量测度,其计算表达式为:
evl=(∑i(y1(i)∩y2(i))/(y1(i)∪y2(i)))(17)
y1(i)和y2(i)分别表示实验分割的结果和groundtruth(真值图),∩和∪分别表示像素间的与和或。最终实验结果和残差图如图4、5所示,本发明提出的方法得到了很好的人体分割结果。
- 还没有人留言评论。精彩留言会获得点赞!