一种入库量和出库量的联合预测方法与流程
本发明涉及库存管理,尤其是涉及基于数据挖掘技术的一种入库量和出库量的联合预测方法。
背景技术:
库存管理是有效地监控现有库存的流入和流出货物波动的一般过程[1]。这一过程一般包含了两种类型操作:(1)把货物搬进仓库以保证销售的顺畅(又名入库);(2)从仓库中交出货物用于销售(又名出库)。这两种类型操作会产生两种类型的时间序列数据,每一个代表随时间而变化的相应的操作量。实现良好的库存管理,即力图在控制每一种操作的消耗和维持库存状态。
在现有的库存管理系统[2]中,通常是单独预测入库量和出库量。它被视为一个单一的时间序列预测,忽略了入库量和出库量之间的关系。在实践中,在一个库存中的入库和出库量均相互依赖。在同一件货物或者一段时间内,出库的数量往往受到入库数量的限制,也就是说,为了预防货物无现货,出库往往少于入库。另外,为了避免供过于求的情况,入库计划依赖于历史出库情况[3]。因此,针对于库存管理的特性,入库和出库两个时间序列承担着一定的相互依赖关系。
在数据挖掘的研究中,时间序列预测问题得到了很好的探索[4,5,6]。然而,很少有研究聚焦于这一方面——预测相关的时间序列数据集合的运动。
参考文献:
[1]zipkinph.foundationsofinventorymanagement[m].newyork:mcgraw-hill,2000.
[2]lil,shenc,wangl,etal.iminer:mininginventorydataforintelligentmanagement[c]//proceedingsofthe23rdacm,internationalconferenceonconferenceoninformationandknowledgemanagement.acm,2014:2057-2059.
[3]scarfh.theoptimalityof(5,5)policiesinthedynamicinventoryproblem[j].1959.
[4]weigendas.timeseriesprediction:forescastingthefutureandunderstandingthepast[m].1994.
[5]vangestelt,suykensjak,baestaensde,etal.financialtimeseriespredictionusingleastsquaressupportvector,machineswithintheevidenceframework[j].neuralnetworks,ieeetransactionson,2001,12(4):809-821.
[6]taylorsj.modellingfinancialtimeseries[j].2007.
技术实现要素:
本发明的目的在于提供基于数据挖掘技术的一种入库量和出库量的联合预测方法。
本发明通过建立一个基于多时间序列数据预测的预测模型,并将其应用到库存管理领域,可以在满足出库与出库两类型时间序列的依赖关系情况下,同时实现高精度的预测结果。
本发明包括以下步骤:
1)获取预定时间段内的入库量和出库量时间序列数据,并对这两类型时间序列数据进行数据清洗;
2)利用数据挖掘技术建立时间序列预测模型;
3)考虑到库存中的入库量和出库量均相互依赖的背景知识,将入库量和出库量时间序列数据的相互依赖关系建立模型;
4)将步骤3)相互依赖关系建立模型应用于库存预测中,即把库存预测的要求建立到约束下,获得最终预测结果。
在步骤1)中,所述获取预定时间段内的入库量和出库量时间序列数据,并对这两类型时间序列数据进行数据清洗的具体方法可为:以特定周期(如周,月,季度等)为时间粒度来获取特定商品的入库量和出库量时间序列数据,n个周期的时间序列数据分别表示为{xi1,yi1}stockin和{xi2,yi2}stockout(i=1,2,...,n)。
在步骤2)中,所述利用数据挖掘技术建立时间序列预测模型的具体方法可为:利用数据挖掘技术建立时间序列预测模型,入库量和出库量预测模型分别为f1(·)和f2(·)。
在步骤3)中,所述考虑到库存中的入库量和出库量均相互依赖的背景知识,将入库量和出库量时间序列数据的相互依赖关系建立模型的具体方法可为:考虑到库存中的入库量和出库量均相互依赖的背景知识,如(1)入库总额往往大于出库总额,以避免供不应求;(2)入库\出库总额又尽可能接近,以避免供过于求;(3)入库和出库总额受到客观条件的限制等;将相互依赖关系建立数学模型,如ηi≤f1(xi1)-f2(xi2)≤ζi,ηi,ζi≥0,其中f1(xi1)和f2(xi2)分别表示入库量和出库量的预测值,ηi和ζi为约束常量。
在步骤4)中,所述将步骤3)相互依赖关系建立模型应用于库存预测中的具体方法可为:把库存预测的要求建立到约束下,在这些约束的条件下获得最终预测结果;建立预测的目标函数如下:
其中,l(·)为惩罚函数,常用的有平均绝对误差(mae),平均平方误差(mse),平均绝对值误差百分比(mape),γ为正则化参数,其作用是权衡训练误差和模型复杂度,||f1||2,||f2||2为入库和出库预测模型的2范数,作用是衡量模型的复杂度。
本发明提出了一个多时间序列数据预测的预测模型,并将其应用到库存管理领域。多时间序列之间的关系被建模为一类约束,在这些约束的条件下获得最终预测结果。
本发明的有益效果是:充分考虑库存管理的应用背景,将入库量和出库量时间序列数据间的相互依赖关系结合到预测模型中,可以获得更符合实际,同时达到高精度的预测结果。
附图说明
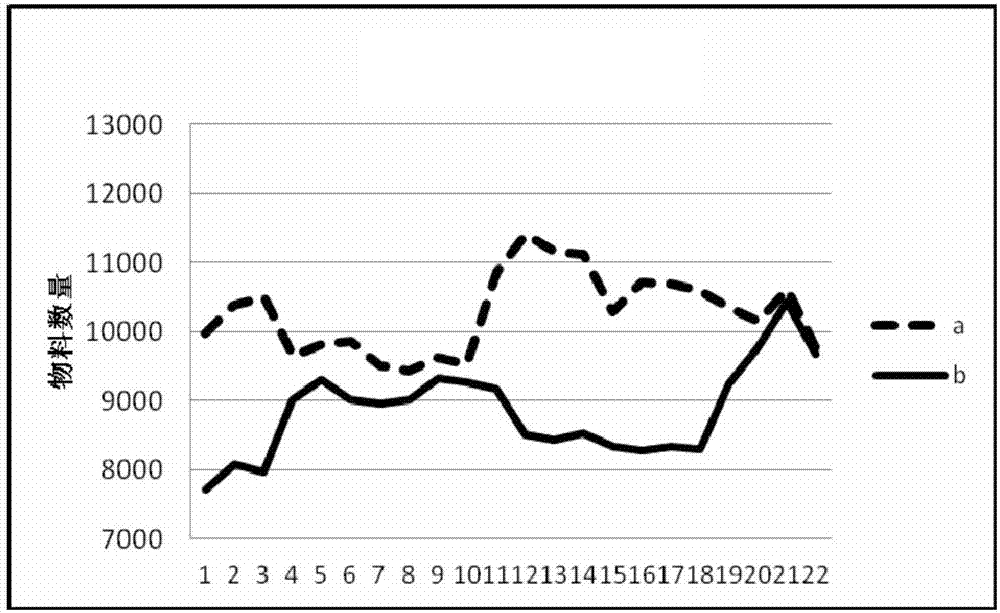
图1是本发明实施例1中的一种产品入库量和出库量的联合预测方法采用非线性预测模型下,原始数据图(曲线a为入库量;曲线b为出库量)。
图2是本发明实施例1中的一种产品入库量和出库量的联合预测方法采用非线性预测模型下,预测结果图(曲线a为入库量;曲线b为出库量)。
图3是不考虑背景知识约束下采用非线性预测模型svr的预测结果1(曲线a为入库量;曲线b为出库量)。
图4是不考虑背景知识约束下采用非线性预测模型svr的预测结果2(曲线a为入库量;曲线b为出库量)。
具体实施方式
下面对本发明的实施例进行详细说明。
本发明提供的一种基于数据挖掘技术的入库量和出库量的联合预测方法的流程图,该方法包括;
步骤一:获取预定时间段内的入库量和出库量时间序列数据,并对这两类型时间序列数据进行数据清洗;
步骤二:利用数据挖掘技术建立时间序列预测模型;
步骤三:考虑到库存中的入库和出库量均相互依赖的背景知识,将入库量和出库量时间序列数据的相互依赖关系建立模型;
步骤四:把上述建立的关系依赖模型应用于库存预测中,即把库存预测的要求建立到约束下,在这些约束的条件下获得最终预测结果。
下面结合一个具体实施例对本发明进行具体描述。
步骤一:获取预定时间段内的入库量和出库量时间序列数据,并对这两类型时间序列数据进行数据清洗;
给定一个时间序列t,可以提取从t中提取连续的样本。假设有m个样本
以一周为时间粒度来获取特定商品的入库量和出库量时间序列数据,n个周期的时间序列数据分别表示为{xi1,yi1}stockin和{xi2,yi2}stockout(i=1,2,...,n)。
步骤二:利用数据挖掘技术建立时间序列预测模型,入库量和出库量预测模型分别为f1(·)和f2(·)。
若采用线性预测模型,则数学模型为:
其中ωl为时间序列数据的权向量,fl(xil)为预测值。
若采用非线性预测模型,以支持向量机回归模型为例,则数学模型为:
其中,||ωl||为权向量的模,即ωl=(ωl·ωl)1/2。γil为松弛变量,希望其值尽可能小。cl为常数,来权衡分类误差和泛化误差。φ(xil)表示将数据映射到高维空间,从而解决原始空间中先行不可分的问题,通常采用核函数来实现。
步骤三:考虑到库存中的入库和出库量均相互依赖的背景知识,将入库量和出库量时间序列数据的相互依赖关系建立模型;
入库和出库量均相互依赖的背景知识,如1)入库总额往往大于出库总额,以避免供不应求;2)入库\出库总额又尽可能接近,以避免供过于求;3)入库和出库总额受到客观条件的限制等。将上述相互依赖关系建立数学模型如下:
ηi≤f1(xi1)-f2(xi2)≤ζi,ηi,ζi≥0(3)
其中f1(xi1)和f2(xi2)分别表示入库量和出库量的预测值,ηi和ζi为约束常量。
步骤四:把入库和出库量两种类型时间序列数据的关系依赖模型应用于库存预测中,即把库存预测的要求建立到约束下,在这些约束的条件下获得最终预测结果。建立预测的目标函数如下:
其中,l(·)为惩罚函数,常用的有平均绝对误差(mae),平均平方误差(mse),平均绝对值误差百分比(mape)。γ为正则化参数,其作用是权衡训练误差和模型复杂度。||f1||2,||f2||2为入库和出库预测模型的2范数,作用是衡量模型的复杂度。
结合上述预测模型,结合公式(4),可将问题转化为二次规划问题来对模型参数寻优。
接下来以线性模型
转化为二次规划问题来对模型参数寻优,标准的二次规划形式如下:
其中ω是预测模型的n维列向量,h是hesse矩阵(n阶对称矩阵),c是n维列向量,a是m×n矩阵,b是m维列向量。
由此,确定各个对应参数如下:
如表1所示,本发明提供的一种基于数据挖掘技术的入库量和出库量的联合预测方法采用线性预测模型下,与传统方法的评价指标对比结果。其中joint表示本发明提供的方法,single表示不考虑背景知识约束下线性预测方法,moving表示不考虑背景知识约束下平均移动模型预测方法。表1中采用mae,mse,mape三个指标来评价预测效果。可以看出本发明提供的一种基于数据挖掘技术的入库量和出库量的联合预测方法得到了最好的预测结果。
表1入库量和出库量的联合预测方法与传统方法预测结果对比
如图1~4所示,本发明提供的一种基于数据挖掘技术的入库量和出库量的联合预测方法采用非线性预测模型svr下,与传统方法的对比效果图。其中图1表示原始数据,图2表示本专利提供的方法用非线性预测模型svr的预测结果可以看出,图3和图4表示不考虑背景知识约束下采用非线性预测模型svr的预测结果。可以看出本发明提供的一种基于数据挖掘技术的入库量和出库量的联合预测方法可以获得更符合实际,同时达到高精度的预测结果。
本发明的有益效果是:充分考虑库存管理的应用背景,将入库量和出库量时间序列数据间的相互依赖关系结合到预测模型中,可以获得更符合实际,同时达到高精度的预测结果。
- 还没有人留言评论。精彩留言会获得点赞!