一种并行化的文本聚类方法与流程
本发明属于计算机技术领域,更为具体地讲,涉及一种并行化的文本聚类方法。
背景技术:
随着信息网络技术的迅速发展和互联网的进一步普及,网络上的数据呈现几何式的增长,数据“爆炸”已成为当前网络时代的特征之一。面对如此庞大而且增长迅速的数据,高效地挖掘有用信息无论在商业、医疗还是科学研究方面,都有着非常巨大的价值。其中,大量信息都以文本形式存储,如新闻稿件、科技论文、书籍、数字图书馆、邮件、博客和网页等等。文本聚类技术可以将大量文本聚合为少数有意义的簇,从而在大量文本中导出高质量的信息,使得人们从数据中获取信息、知识和决策支持更加容易。
但是,传统串行式的文本聚类方法在处理海量或者高维数据时,聚类的速度不够快,在面对大规模数据时,受制于内存容量,往往不能有效地运行,因而传统串行式文本聚类方法已经难以满足当前实际应用的需求。
并行计算(Parallel Computing)是指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段。它的基本思想是用多个处理器来协同求解同一问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理机来并行计算。并行计算系统既可以是专门设计的、含有多个处理器的超级计算机,也可以是以某种方式互连的若干台的独立计算机构成的集群。通过并行计算集群完成数据的处理,再将处理的结果返回给用户。
并行计算可以将大规模数据分发到多个分布式节点上并行地进行计算,最后将所有节点的计算结果归并为最终的结果,可以大大地提高计算速度。然而实际上,可能存在许多障碍使得特定类型的计算任务难以执行给定的并行化处理。通常来说,对于一项将进行并行处理的计算任务来说,需要将与该计算任务相关的数据复制到其使用的每一个处理器中,这里将产生一定的计算开销;若某项任务需要计算资源整合其它子任务的并行处理结果,以便得到一个统一的计算结果时,可能产生一定的整合资源计算开销,考虑到这些开销,许多类型的计算任务进行并行化是不现实的。为了将传统串行式的文本聚类方法并行化,需要对其进行方法上的改进,使其适合并行化计算的基本体系结构,这样才能高效地利用计算资源,在处理海量或者高维数据时,大大提高文本聚类的速度。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种并行化的文本聚类方法,采用并行化的计算方式提取特征向量和聚类,充分利用了并行计算的优点,提高文本聚类的速度。
为实现上述发明目的,本发明一种并行化的文本聚类方法,其特征在于,包括以下步骤:
(1)、文本预处理
将非结构化文本平均分发到各分布式节点上,对各节点上的文本进行预处理、分词、过滤停用词操作;
(2)、提取文本特征向量
采用并行化的计算方式对预处理后的文本进行特征提取,获取处理后的文本特征向量;
(3)、对文本特征向量进行聚类
采用改进后的并行化聚类方法对上述文本特征向量进行聚类,增量式地获取多个文本簇。
其中所述步骤(1)中文本预处理的具体步骤为:
(2.1)、采用“key=文本编号,value=文本内容”的格式,将已有非结构化文本平均分发到各分布式节点上;
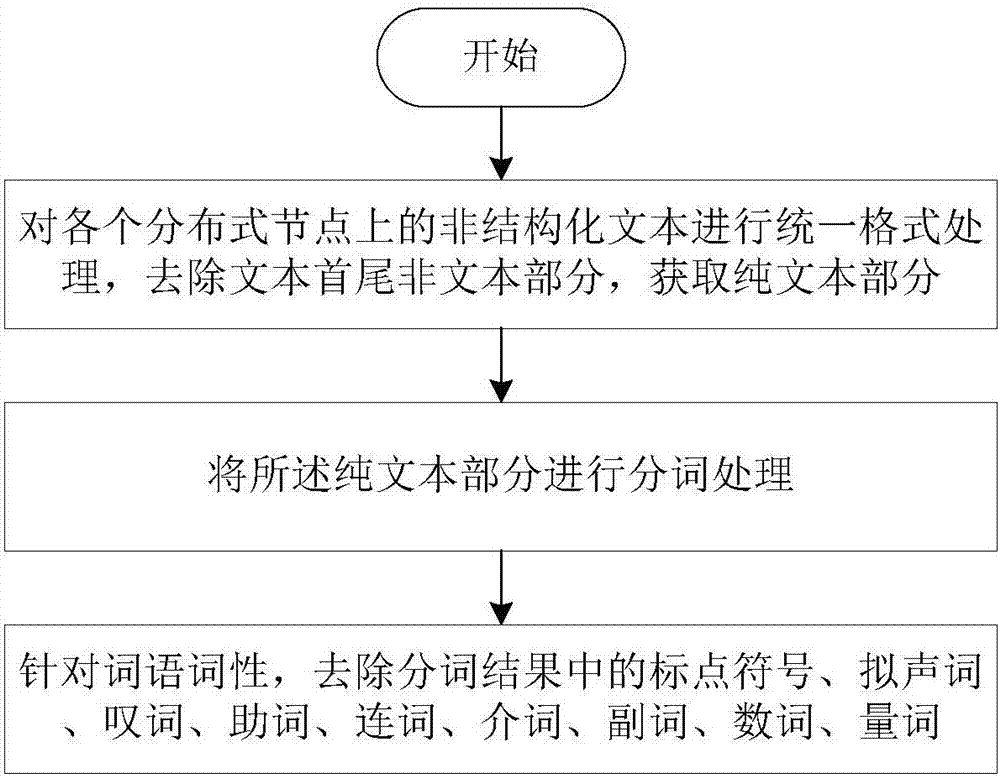
(2.2)、对各分布式节点上的非结构化文本进行统一格式处理:去除非结构化文本的首尾非文本部分,获取纯文本部分,若为空文本则跳过;
(2.3)、将纯文本部分进行词语词性的分词处理,针对词语词性,去除分词结果中的标点符号、拟声词、叹词、助词、连词、介词、副词、数词、量词;
其中,提取文本特征向量的具体方法为:
(3.1)、采用并行化计算方式对各分布式节点上各纯文本的分词结果进行词频向量统计:统计每个分布式节点上的纯文本数量,再按照如下方法统计该分布式节点上每个纯文本的分词结果的词频向量;
(3.1.1)、为每个纯文本构建一个维数足够大的词频向量tfi,tfi的维数为length,tfi初始化为零向量,i表示第i个纯文本;
(3.1.2)、对分词结果中的每个词语作哈希计算,得到整数型的哈希值,再将该哈希值对length取余得到该词语对应的向量索引,然后在tfi上词语对应的索引位置处加1,以此统计出该词语在该纯文本中出现的次数,最后将tfi转换为稀疏向量形式;
(3.2)、采用并行化计算方式对各分布式节点上各纯文本的词频向量进行逆文本频率向量统计:先统计每个分布式节点上的词频向量数量,再按照如下方法统计该分布式节点的逆文本频率向量;
(3.2.1)为每个分布式节点构建文本频率向量dfq,维数与tfi一致,q表示第q个分布式节点;
(3.2.2)、遍历每个分布式节点中所有的词频向量,得到词频向量中非零元素的向量索引,在dfq的对应索引位置进行加1,以此统计该词语在该分布式节点上多少个纯文本中出现的次数;
(3.2.3)、将各分布式节点的dfq向量求和,得到总文本频率向量DF;通过公式计算得到所有纯文本的逆文本频率向量IDF,DFk表示向量DF中第k个元素,n表示所有纯文本的总个数;
(3.3)、将逆文本频率向量IDF广播到各分布式节点上,将各纯文本的词频向量tfi和逆文本频率向量IDF对应相乘,得到各纯文本的TF-IDFi向量,按照“key=文本编号,value=TF-IDFi向量”的格式聚合所有节点上的TF-IDFi向量,得到所有纯文本的文本特征向量TF-IDF。
其中,对文本特征向量进行聚类的具体方法为:
(4.1)、将文本特征向量TF-IDF广播到各分布式节点上,遍历每个纯文本,通过公式计算第i个纯文本与前i-1个纯文本的余弦相似度,di表示第i个文本的TF-IDF向量,其中i∈[1,n],j∈[1,i-1],从这i-1个余弦相似度中取出最大值maxi,j,maxi,j表示第i个文本与第j个文本的余弦相似度;
(4.2)、创建共享向量Data,维数为n,以存放聚类结果;
(4.3)、根据上述余弦相似度,按照如下方法对所述文本特征向量进行改进后的并行化聚类;
(4.3.1)、设定一个聚类阈值,当i=1或maxi,j小于设定的阈值时,为第i个文本新建一个文本簇,以“key=文本编号,group=i”的格式在Data索引为i的位置存放数据;
(4.3.2)、当maxi,j大于设定的阈值时,将第i个文本与第j个文本归为同一文本簇,在向量Data获取文本j的group值G,以“key=文本编号,group=G”的格式在Data索引为i的位置存放数据;
(4.3.3)、最后得到的向量Data即为聚类结果。
本发明的发明目的是这样实现的:
本发明一种并行化的文本聚类方法,将非结构化文本平均分发到各分布式节点上,再对各节点上的文本进行预处理,采用并行化的计算方式对预处理结果进行特征提取,获取处理后的文本特征向量;然后采用改进后的并行化聚类方法对上述文本特征向量进行聚类处理,增量式地获取多个文本簇;通过将聚类过程中的各个步骤并行化,在面对海量或高维数据时,提升了文本聚类的速度。
同时,本发明一种并行化的文本聚类方法还具有以下有益效果:
(1)、采用特征哈希(Feature Hashing)法来统计词频向量,相较于传统方法,无需维护一个特征值及其下标的向量,提高了计算效率;
(2)、将词频向量转换为稀疏向量形式,大大降低了计算开销;
(3)、相较于K-means等非增量式的聚类方法,本发明一种并行化的文本聚类方法是一种增量式的聚类方法,不需要提前指定类簇的个数,可以排除孤立点对聚类效果的影响。
附图说明
图1是本发明一种并行化的文本聚类方法流程图;
图2是文本预处理流程示意图;
图3是提取文本特征向量的流程示意图;
图4是对文本特征向量进行聚类的流程示意图。。
具体实施方式
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
实施例
图1是本发明一种并行化的文本聚类方法流程图。
在本实施例中,如图1所示,本发明一种并行化的文本聚类方法,包括以下步骤:
S1、文本预处理
将非结构化文本平均分发到各分布式节点上,对各节点上的文本进行预处理、分词、过滤停用词操作;
采用“key=文本编号,value=文本内容”的格式,预先将非结构化文本平均分发到各节点,之后的大部分操作都将在各节点完成,以提升操作完成速度;数据库中文本可能存在首尾部分有冗余内容或者文本自身为空的情况,需要先进行一步预处理,再对纯文本进行分词操作,获取分词结果。针对不同的语言可以采取不同的分词方法,本实施例中,针对汉语采用NLPIR汉语分词系统进行分词操作。
下面结合图2对文本预处理的具体流程进行详细说明,具体如下:
S1.1、采用“key=文本编号,value=文本内容”的格式,将已有非结构化文本平均分发到各分布式节点上;
S1.2、对各分布式节点上的非结构化文本进行统一格式处理:去除非结构化文本的首尾非文本部分,获取纯文本部分,若为空文本则跳过;
S1.3、将纯文本部分进行词语词性的分词处理,针对词语词性,去除分词结果中的标点符号、拟声词、叹词、助词、连词、介词、副词、数词、量词;
S2、提取文本特征向量
采用并行化的计算方式对预处理后的文本进行特征提取,获取处理后的文本特征向量;
下面结合图3对提取文本特征向量的具体流程进行详细说明,具体如下:
S2.1、采用并行化计算方式对各分布式节点上各纯文本的分词结果进行词频向量统计:统计每个分布式节点上的纯文本数量,再按照如下方法统计该分布式节点上每个纯文本的分词结果的词频向量;
S2.1.1、为每个纯文本构建一个维数足够大的词频向量tfi,tfi的维数为length,tfi初始化为零向量,i表示第i个纯文本;
词频向量的维数应设置的足够大,来保证步骤S2.1.2中词语的索引不会频繁出现冲突,本实施例中,维数length=218,该值可根据文本数量进行设置;
S2.1.2、对分词结果中的每个词语作哈希计算,得到整数型的哈希值,再将该哈希值对length取余得到该词语对应的向量索引,然后在tfi上词语对应的索引位置处加1,以此统计出该词语在该纯文本中出现的次数,最后将tfi转换为稀疏向量形式,以减少计算开销;
S2.2、采用并行化计算方式对各分布式节点上各纯文本的词频向量进行逆文本频率向量统计:先统计每个分布式节点上的词频向量数量,再按照如下方法统计该分布式节点的逆文本频率向量;
S2.2.1、为每个分布式节点构建文本频率向量dfq,维数与tfi一致,q表示第q个分布式节点;
S2.2.2、遍历每个分布式节点中所有的词频向量,得到词频向量中非零元素的向量索引,在dfq的对应索引位置进行加1,以此统计该词语在该分布式节点上多少个纯文本中出现的次数;
S2.2.3、将各分布式节点的dfq向量求和,得到总文本频率向量DF;通过公式计算得到所有纯文本的逆文本频率向量IDF,DFk表示向量DF中第k个元素,n表示所有纯文本的总个数;
S2.3、将逆文本频率向量IDF广播到各分布式节点上,将各纯文本的词频向量tfi和逆文本频率向量IDF对应相乘,得到各纯文本的TF-IDFi向量,按照“key=文本编号,value=TF-IDFi向量”的格式聚合所有节点上的TF-IDFi向量,得到所有纯文本的文本特征向量TF-IDF。
S3、对文本特征向量进行聚类
采用改进后的并行化聚类方法对上述文本特征向量进行聚类,增量式地获取多个文本簇;
下面结合图4对提取文本特征向量的具体流程进行详细说明,具体如下:
S3.1、将文本特征向量TF-IDF广播到各分布式节点上,遍历每个纯文本,通过公式计算第i个纯文本与前i-1个纯文本的余弦相似度,di表示第i个文本的TF-IDF向量,其中i∈[1,n],j∈[1,i-1],从这i-1个余弦相似度中取出最大值maxi,j,maxi,j表示第i个文本与第j个文本的余弦相似度;
S3.2、创建共享向量Data,维数为n,以存放聚类结果;
S3.3、根据上述余弦相似度,按照如下方法对所述文本特征向量进行改进后的并行化聚类;
S3.3.1、设定一个聚类阈值,本实施例中设置聚类阈值为0.3,当i=1或maxi,j小于设定的阈值时,为第i个文本新建一个文本簇,以“key=文本编号,group=i”的格式在Data索引为i的位置存放数据;
S3.3.2、当maxi,j大于设定的阈值时,将第i个文本与第j个文本归为同一文本簇,在向量Data获取文本j的group值G,以“key=文本编号,group=G”的格式在Data索引为i的位置存放数据;
S3.3.3、最后得到的向量Data即为聚类结果。
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
- 还没有人留言评论。精彩留言会获得点赞!