一种快速的新闻事件聚类系统及方法与流程
本发明涉及新闻资讯领域,具体涉及一种快速的新闻事件聚类系统及方法。
背景技术:
随着互联网的快速发展,网络舆情对社会的影响力越来越大。不管是政府网络舆情监控的需要,还是企业在进行品牌传播及品牌公关的需要,如何在大量的舆情的条件下,快速地分析舆情的情感倾向,以及时地进行决策支持和舆情引导,响应快速变化的舆论环境,是舆情分析中迫切需要解决的问题。以往的情感分析,需要进行复杂的分析,在应对大量的舆情条件下,无法做到低延迟处理。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种快速的新闻事件聚类系统及方法,在面对大量舆情场景下,进行快速类聚新闻事件。
本发明的目的是通过以下技术方案来实现的:
一种快速的新闻事件聚类系统,包括:
新闻抓取模块:用于从新闻门户、论坛及微博上抓取新闻文档,其中包括对文本进行初步去重处理;
新闻文本初步处理模块:用于对文本进行初步文本特征处理,包括分词、去停用词、对否定式短语进行额外标注;
新闻文本事件类聚模块:包括对分词进行排列组合、将文档d映射到第一层聚类、计算文档d与子聚类的距离、判定文档d所属的聚类、创建新的子聚类;
数据存储模块:存储计算后的结果。
一种快速的新闻事件聚类方法,包括以下步骤:
s01:抓取文本d,文档去重;
s02:抽取文本标题,对标题分词,只保留名词/动词性词语;
s03:对标题分词做排列组合,得到n个组合,每个组合将作为第一层聚类的key
s04:在每个聚类的大类,拿文本的分词结果与每个子聚类的质心做余弦距离计算,假设有m个子聚类,则产生m个结果;
s05:对产生的m×n个结果进行排序,取值最大的结果,假设为r,同时设定经验阈值g该经验阈值是[0.75,1];
s06:如果r>=g,文本d归属于r所在的类
s07:如果r<g,创建新的子类,根据子聚类结果,计算每个大类的平均余弦距离,得到n个值,排序,取最大值,设最大值对应的大类为c,在c中创建以文档d为质心的子类。
进一步,所述的步骤s02中文本处理方式,具体包括抽取文本标题,进行分词,对分词进行词性过滤,只保留名词性和动词性分词。
进一步,所述的步骤s03所述的第一层聚类方法,具体包括将分词结果做排列组合,得到n个组合,每个组合按照单词排序,使用分隔符将单词拼接为字符串,所得字符串就是第一层聚类的key值,对于文本d而言,n个key对应的大类,都有可能是它所在的大类。
进一步,步骤s04所述的处理过程,具体包括:对于s3获得的n个key,检索得到n个聚类结果(第一层聚类结果),对于每个聚类结果,假设已有m个子聚类(第二层聚类),拿文档d的分词结果与每个子聚类的质心计算相似度,相似度的算法包括但不限于余弦距离算法,这一步将会输出m×n个结果值。
进一步,所述的步骤s05中,具体包括将m×n个结果输出,取最大的值作为候选结果,根据经验设定一个分类阈值,阈值的范围为[0.7,1]。
进一步,所述的步骤s06中聚类步骤,具体包括如果r>=g,则直接判断文档d归属于r所在的类,也就是说d属于r的类对应的事件。
进一步,所述的步骤s07中创建新的子类的过程,具体包括如果r>=g,使用s4产生的n×m个结果,计算n个聚类的平均余弦距离,得到n个平均值;针对这n个平均值进行排序,取最大值,对应的第一层聚类c就是文档所在的第一层聚类;在聚类c中,创建以文档d为质心的的子聚类。
本发明的有益效果是:通过本发明的方法可以对不同的新闻事件进行快速分类,使得新闻事件分布集中,方便阅读者有针对性的查找自己感兴趣的新闻。
附图说明
图1为本发明的系统结构示意图;
图2为本发明的方法流程图。
具体实施方式
下面结合附图进一步详细描述本发明的技术方案,但本发明的保护范围不局限于以下所述。
如图1所示,
一种快速的新闻事件聚类系统,包括:
新闻抓取模块:用于从新闻门户、论坛及微博上抓取新闻文档,其中包括对文本进行初步去重处理;
新闻文本初步处理模块:用于对文本进行初步文本特征处理,包括分词、去停用词、对否定式短语进行额外标注;
新闻文本事件类聚模块:新闻文本时间聚类模块,包括对分词进行排列组合、将文档d映射到第一层聚类、计算文档d与子聚类的距离、判定文档d所属的聚类、创建新的子聚类;
数据存储模块:存储计算后的结果。
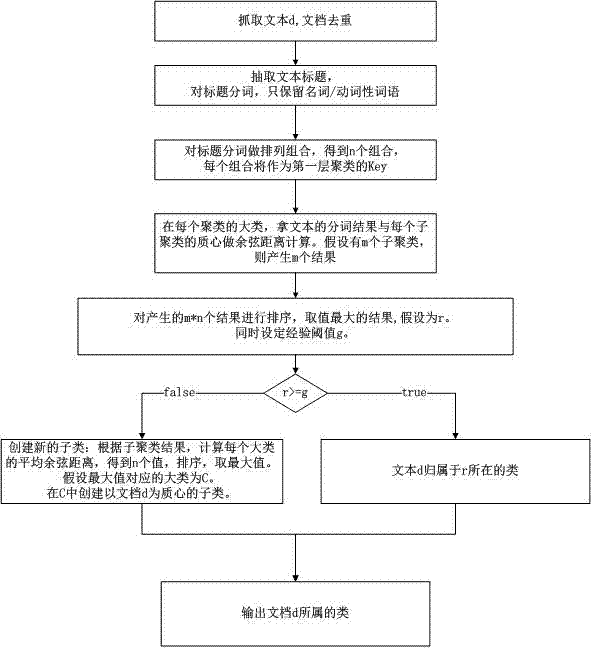
如图2所示:
一种快速的新闻事件聚类方法,包括以下步骤:
s01:抓取文本d,文档去重;
s02:抽取文本标题,对标题分词,只保留名词/动词性词语;
s03:对标题分词做排列组合,得到n个组合,每个组合将作为第一层聚类的key
s04:在每个聚类的大类,拿文本的分词结果与每个子聚类的质心做余弦距离计算,假设有m个子聚类,则产生m个结果;
s05:对产生的m×n个结果进行排序,取值最大的结果,假设为r,同时设定经验阈值g该经验阈值是[0.75,1];
s06:如果r>=g,文本d归属于r所在的类
s07:如果r<g,创建新的子类,根据子聚类结果,计算每个大类的平均余弦距离,得到n个值,排序,取最大值,设最大值对应的大类为c,在c中创建以文档d为质心的子类;
最后输出文档d所属的类。
进一步,所述的步骤s02中文本处理方式,具体包括抽取文本标题,进行分词,对分词进行词性过滤,只保留名词性和动词性分词。
进一步,所述的步骤s03所述的第一层聚类方法,具体包括将分词结果做排列组合,得到n个组合,每个组合按照单词排序,使用分隔符将单词拼接为字符串,所得字符串就是第一层聚类的key值,对于文本d而言,n个key对应的大类,都有可能是它所在的大类。
进一步,步骤s04所述的处理过程,具体包括:对于s3获得的n个key,检索得到n个聚类结果(第一层聚类结果),对于每个聚类结果,假设已有m个子聚类(第二层聚类),拿文档d的分词结果与每个子聚类的质心计算相似度,相似度的算法包括但不限于余弦距离算法,这一步将会输出m×n个结果值。
进一步,所述的步骤s05中,具体包括将m×n个结果输出,取最大的值作为候选结果,根据经验设定一个分类阈值,阈值的范围为[0.7,1]。
进一步,所述的步骤s06中聚类步骤,具体包括如果r>=g,则直接判断文档d归属于r所在的类,也就是说d属于r的类对应的事件。
进一步,所述的步骤s07中创建新的子类的过程,具体包括如果r>=g,使用s4产生的n×m个结果,计算n个聚类的平均余弦距离,得到n个平均值;针对这n个平均值进行排序,取最大值,对应的第一层聚类c就是文档所在的第一层聚类;在聚类c中,创建以文档d为质心的的子聚类。
以上所述仅是本发明的优选实施方式,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!