一种基于大数据的社保指标仓库的构建系统及其方法与流程
本发明具体涉及一种基于大数据的社保指标仓库的构建系统及其方法,属于大数据应用技术领域。
背景技术:
目前,在大数据时代背景下,社保家底数据如征缴企业养老保险基金金额、社保覆盖人口比例等的统计分析面临挑战。社保的大量数据处于分散存储状态,存在信息孤岛现象,社保统计信息服务决策、服务管理、服务社会的巨大潜力尚未开发;基于数据库的统计查询、人工多口径信息提取等手段落后,导致统计数据客观性、真实性、便捷性存在问题
随着信息化技术的不断发展,社会保险系统已经积累了大量的业务数据。通过收集、整理、挖掘、利用社保业务数据,构建社保统计指标,实现从多个角度或者从不同的考察范围来观察某一指标或多个指标,进行分析对比,找出这些指标间隐藏的内在关系,并预测这些指标的发展趋势,为社会保险改革决策提供科学的依据。是深化大数据在社会保险服务应用的有效手段。
联机分析处理(olap)是一种将原始数据转化为可从多视角观察数据的软件技术。olap的主要工作就是将数据仓库中的数据转换到多维数据结构中,并且对上述多维数据结构执行有效且非常复杂的多维查询。
传统的数据仓库一般采用集中式结构化存储方式,单节点运行计算,配置起来比较简单。然而社保统计指标的重要数据来源就是社保业务数据,社保业务数据普遍分散在各个社保领域(养老、医疗)的业务数据库中,加之社保业务数据具有地域分布广、涉及系统多、数据规模大、结构较松散等问题。往往要对多张数据表中成千上万条数据进行综合查询,传统数据仓库的性能越来越难以满足这类复杂的查询需求,且随着数据量的积累,数据仓库扩容将是一个巨大的问题。
对海量社保数据的多维查询分析,查询速度是评价系统性能的关键因素。当前国内外关于大数据联机分析处理的研究成果多种多样,但是针对社保应用海量数据实现的分布式多维分析系统不多见。普遍是通过优化计算策略、查询操作方法来实现多维分析效率的提升。
技术实现要素:
本发明为了解决上述问题,提供一种社保大数据指标仓库的构建方法及系统。系统以社保业务数据为数据源,利用大数据处理技术和分布式存储技术构建一种准确的、定时更新的以立方体结构存储组织的多维统计指标库,并提供指标快速查询和展示功能。
本方法和系统将指标构建分为数据采集阶段和指标仓库构建阶段。
数据采集阶段,分为批量导入和变更同步两个部分。批量导入是将分散于各地市的社保业务数据按照设计的组织原则,一次性经过抽取、转换,整合到统一的过程库(基于hbase数据库),完成从业务数据库到业务过程数据库的初始批量导入;变更同步阶段,在各个业务数据库中配置oraclestreams,分析redo日志,将包含业务数据库变更操作的消息分发到oracle高级队列,然后将变更消息转换成消息流,利用apachestorm将变更数据同步到业务过程数据库hbase中。保证整合后的业务过程数据库的实时性和准确性。
指标仓库构建阶段。基于开源大数据引擎kylin,借助hive工具加载数据,按照多维分析模型定义的事实表、维表、事实表和维表的连接关系,进行多维指标立方的预计算,并以立方体组织形式将数据保存到指标库中(基于hbase数据库)。设置指标计算周期,定时自动执行增量数据的指标立方体构建。
本方法及系统提供的查询展示功能包括,根据多维查询请求,解析多维数据模型信息及kylin引擎识别的查询语句,实现快速从指标仓库中获取数据,并按需求的方式将结果展示。
为了实现上述目的,本发明采用如下的技术方案:
基于大数据的社保指标仓库的构建系统,包括:
社保业务数据库,为社保指标仓库的计算提供原始数据来源,为数据的变更同步提供增量变更消息流;
业务数据采集模块,用于完成从业务数据到社保业务过程数据的批量导入和变更同步;
数据预处理模块,用于对数据格式、类型、表结构等进行转换处理,将数据转为apachekylin(一种大数据分布式计算引擎)计算所支持的数据模式;
指标计算模块,用于定义、调度、执行指标计算任务,根据设置的计算周期,自动定时执行指标计算;
指标元数据存储模块,用于存储社保指标数据模型相关信息,指标立方体构建信息;
社保数据存储模块,为社保业务过程数据和社保指标仓库数据提供分布式存储支持,构建社保业务过程库和社保指标仓库;
数据查询展示模块,用于定义查询需求及执行查询,并将结果展示。
所述社保业务数据库,包括redo日志分析模块,aq模块(advancedqueue,即高级队列);
所述redo日志分析模块,基于oraclestreams技术,用于分析业务数据库中的redo日志,产生变更消息发送到aq模块存储;
所述aq模块,是一种oracle数据库提供的消息队列,接受和临时存储redo日志分析模块发送的变更消息流;
所述业务数据采集模块,包括批量导入模块、变更同步模块;
所述批量导入模块,用于加载各地市的业务数据库中的数据,将数据批量导入到分布式存储的业务过程数据库中,并创建数据表索引,提高数据查询等操作效率;
所述变更同步模块,用于将业务数据库中自批量导入以后变更的数据实时同步到过程库中。storm增量拓扑接收高级队列(aq)中的变更消息流,对其进行解析,将变更数据同步到过程库中。并进行相应的数据表索引更新。实现从业务数据库到业务过程库的变更同步;
所述数据预处理模块,包括hive与过程库hbase整合模块,数据转换模块。
所述hive与过程库hbase整合模块,用于创建hive外表,与过程库hbase数据库中的表相关联,实现hive从hbase中实时读取数据,且hive对外表的操作会同时更新到hbase对应的表中。指标数据计算基于kylin实现的,kylin支持从hive中查询数据,需要搭建kylin查询hbase数据的桥梁;
所述数据转换模块,用于进行数据类型、数据格式、数据取值的转换、抽取、表连接等。根据社保统计指标需求,实现对其所需业务数据的预处理转换。社保业务数据存在结构松散,数据噪声多等问题,kylin进行指标预计算对数据格式、表结构等有一定的要求,通过该模块实现相应的数据预处理工作;
所述指标计算模块,包括多维数据模型定义模块,指标计算任务调度模块,指标计算任务池;
所述多维数据模型定义模块,根据社保统计指标的不同分析主题模块,定义相应的多维数据模型,包括数据源(事实表、维表、事实表与维表连接关系)的定义,以及统计指标、指标维度、聚合函数的定义,每一个数据模型对应一个指标计算任务;
社保指标仓库不同的主题模块包括:
参保人员情况(具体包括新增参保人数、减少的参保人数、参保总人数等)、
享受待遇情况(具体包括领取待遇人次,领取待遇减少人次等)、
社保基金收入情况(具体又包括收入总额、单位缴费额、个人缴付额、财政缴费额、划入医疗个人账户金额、划入养老个人账户金额等)、
社保基金支出情况(总支出,统筹支出、个人账户支出等)等。
分析的角度包括:时间(年度、季度、月度等);地区(省级、市级、区级等)、人员属性(年龄、人群、人员类别、人员状态等)、单位属性(单位性质、经济类型、所属产业等)、业务属性(险种、发放类别、医疗支出[医疗统筹类别、疾病类别]、工伤[伤残等级、工伤类别]等)。
结合分析的主题模型和业务数据特点,各个主题模块分别包括以下数据模型:
参保人员情况(参保人数数据模型、参保变动数据模型)、
享受待遇情况(参保待遇数据模型)、
社保基金收入情况(职工基金收入数据模型、居民基金收入数据模型、医疗个人账户收入数据模型、养老个人账户收入数据模型)、
社保基金支出情况(医疗支出立方体、生育支出立方体、失业支出立方体、养老支出立方体、医疗个人账户支出立方体、养老个人账户支出立方体等)
所述计算任务调度模块,根据数据模型定义模块中关于立方体模型的定义,添加指标数据计算任务,配置各个任务计算周期。定时执行指标计算任务,启动kylin大数据计算引擎,进行相应的各维度组合下的指标值的计算,以数据立方的组织方式存储到hbase数据库中;
所述指标计算任务池,包含大量数据模型立方体计算任务,每一个计算任务对应社保不同的统计主题模块,并且每一个计算任务包括主题模块下的所有立方体数据模型作业,被配置为一个定时的调度作业。以实现变更数据的计算;
所述指标元数据信息存储模块,存储社保指标数据模型相关信息,指标立方体构建信息;
所述社保数据存储模块,包括社保业务过程数据库和社保指标数据仓库;
所述社保过程数据库,是一种分布式存储的hbase数据库,用于将大规模业务数据库中的数据分布式存储,为分布式计算提供基础,为社保指标数据仓库的构建提供实时数据支持;
所述社保指标立方体仓库,是一种分布式存储的hbase数据库,也是本方法及系统构建的目标数据库;社保指标仓库是一种涵盖所有社保统计指标的各个维度的数据直观展现;
所述数据查询展示模块,包括查询定义模块,查询模块,结果展示模块;
所述查询定义模块,从指标元数据模块获取数据仓库信息,定义要查询的指标、维度、过滤条件及查询结果展示形式。结果展示形式包括表格、饼图、柱状图、折线图几类;
所述数据查询模块,将查询需求解析为相应的查询语句。通过kylin接口,执行数据查询任务,返回查询结果;
所述结果展示模块,将查询结果通过相应的展示组件呈现。
本发明提供的基于大数据的社保指标仓库的构建方法,包括以下步骤:
步骤201,配置业务数据采集模块,抽取分散在各个社保业务数据库中的数据,整合集中到基于分布式存储的业务过程数据库中,为进行社保指标仓库的构建提供数据支持;
步骤202,完成业务过程数据库的初始批量导入后,在业务数据库配置oraclestreams实现redo日志分析,捕获增量变更消息到aq高级队列中存储;
步骤203,配置业务数据采集模块,构建运行storm增量拓扑。storm拓扑接受来自高级队列中的变更消息,将变更数据同步到业务历程数据库,并更新索引表,保证业务过程库的一致性和实时性;
步骤204,配置数据预处理模块,添加数据转换任务。数据预处理模块中的hive与hbase整合模块建立过程库hbase到hive的外表,实现从hive实时读取过程库hbase表数据。数据预处理模块中的数据转换模块根据配置信息建立hive视图,实现数据类型、格式转换及多表连接等数据预处理;
步骤205,配置指标计算模块,完成指标数据模型定义,并通过作业调度模块执行和作业定义相匹配的指标计算任务池中的任务,完成从社保业务过程库到社保指标仓库的计算。元数据存储模块保存相应的数据模型、指标计算信息;指标立方体的预计算是基于kylin大数据引擎实现的,kylin支持大规模数据立方的快速计算;
步骤206,完成指标仓库的构建后,可以进行快速的olap查询分析。从指标元数据存储模块中获取已构建指标立方体相关信息,定义多维分析需求。解析查询需求,从指标仓库中预计算好的数据中执行查询,将查询结果返回给展示模块,展示模块根据需求配置进行结果展示。
本发明实现的有益效果
本发明提供了基于社会保障业务数据的社保统计指标立方体的仓库的构建方法及系统。具体是将地区分布广、涉及系统多、数据规模大、数据噪声多、结构较松散的社保业务数据,进行清洗、转换、整合等处理,集中到基于分布式存储的社保指标仓库中。实现了数据的有效汇聚整合,提高了数据之间的关联性,保证了社保统计信息的质量和时效。为社保数据服务决策、服务管理、服务社会提供支持。能够实现快速多角度分析问题,为制作报表、分析报告等提供有价值的数据信息。
附图说明
图1为本发明的一种社保大数据指标仓库的快速构建方法及系统的架构图;
图2为本发明的一种社保大数据指标仓库构建方法及系统的初始化流程图。
具体实施方式
下面结合附图对本发明的具体实施方式进行说明:
本发明提供了一种基于大数据的社保指标仓库的构建系统及构建方法。
一种社保大数据指标仓库的构建系统,如图1所示,由数据源模块101(包括redo日志分析模块,aq模块)、业务数据采集模块102(包括批量导入模块,变更同步模块)、数据预处理模块103(hive与hbase整合模块,数据转换模块)、指标计算模块104(包括数据模型定义模块、任务调度模块、指标计算任务池)、指标元数据存储模块105、数据存储模块106(包括社保业务过程数据库,社保指标立方体数据仓库)、数据查询展示模块107(包括查询定义模块,数据查询模块,结果展示模块)六部分组成;
数据源模块101,即社保业务数据库,主要为业务数据采集模块提供数据抽取来源,同时为数据的增量计算提供变更消息;数据源模块101的功能通过业务数据库数据、redo日志分析模块1011以及aq模块1012共同完成;redo日志分析模块1011主要负责分析redo日志,捕获业务数据库数据更新操作,生成相应的变更消息发送至aq模块;aq模块1012主要负责临时存储来自redo日志分析模块产生的变更消息,为业务变更同步模块提供变更消息流。
业务数据采集模块102,主要负责从各地市的业务数据库中抽取数据并导入到分布式存储的业务过程数据库中,为构建社保指标仓库提供分布式化存储的数据来源;业务数据采集模块102的功能通过批量导入模块1021、变更同步模块1022共同完成;批量导入模块1021主要负责将社保业务数据库中的数据一次性初始导入社保业务过程数据库;变更同步模块主要负责接收aq模块1012中的变更消息,并进行解析转化应用到社保业务过程数据库中,实现从社保业务数据库到社保业务过程数据库的数据变更同步。
数据预处理模块103,主要负责实现hive查询过程库hbase中的数据,并对数据类型、格式、内容、表结构等进行转换。数据预处理模块103的功能通过hive与hbase整合模块1031、数据转换模块1032共同完成;hive与hbase整合模块1031,主要负责创建hive外表,与过程库hbase数据库中的表相关联,实现hive从hbase中实时读取数据,且hive对外表的操作会同时更新到hbase对应的表中。为kylin通过hive查询数据提供桥梁。数据转换模块1032,用于进行数据类型、数据格式、数据取值的转换、抽取、表连接等,以满足kylin计算需求。
指标计算模块104,主要负责指标计算任务的定义和调度,进行指标仓库的构建。指标计算模块104通过数据模型定义模块1041、任务调度模块1042、指标计算任务池1043共同完成;数据模型定义模块1041对应各个社保主题,定义相应的数据模型,包括事实表、维表的定义、维度、度量、聚合函数的设置。任务调度模块1042根据数据模型定义模块中关于立方体模型的定义,添加指标数据计算任务,配置各个任务计算周期。定时执行指标计算任务。指标计算任务池1043,主要负责整合所有的计算任务,供任务调度模块调度运行。
指标元数据存储模块105,主要负责存储数据模型、指标构建模型等元数据信息,为指标仓库管理、数据查询展示模块提供信息目录。
社保数据存储模块106,主要负责将社保业务过程数据库1061和社保指标立方体数据库1062进行分布式存储,为海量社保大数据提供了良好的数据存储安全保障机制,同时提高了数据仓库数据存储的横向扩展能力。
数据查询展示模块107,包括查询定义模块1071、查询模块1072、结果展示模块1073,主要提供查询界面,列出可查询数据,进行查询需求的定义和结果展示形式定义,并按要求执行查询,以需求的形式展示查询结果。
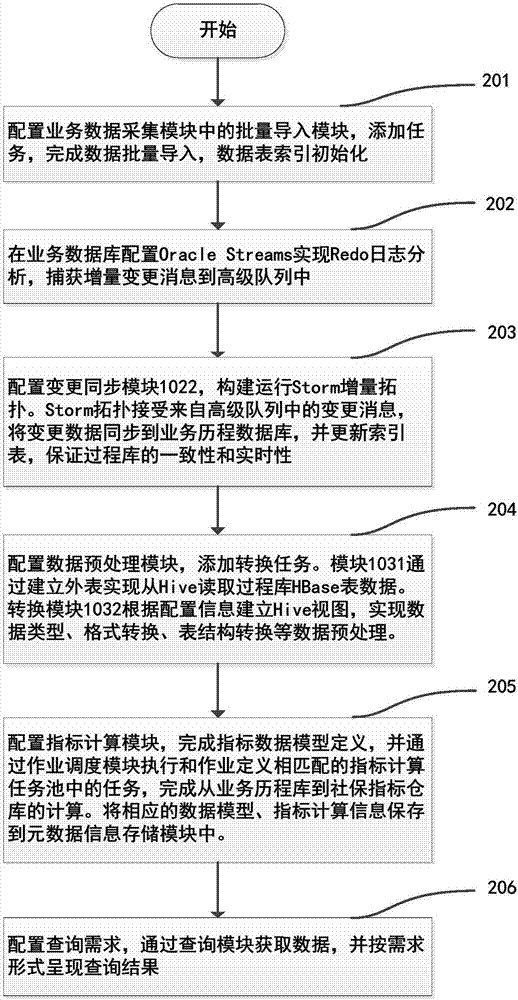
一种社保大数据指标仓库的构建方法与系统,如图2所示,它包括以下步骤:
步骤201,配置业务数据采集模块102中的批量导入模块1021,抽取分散在各个社保业务数据库中的数据,整合集中到基于分布式存储的业务过程数据库中,为进行社保指标仓库的构建提供数据支持;
步骤202,完成业务过程数据库的批量导入后,在业务数据库配置oraclestreams实现redo日志分析,捕获增量变更消息到aq高级队列中存储;
步骤203,配置业务数据采集模块102中的变更同步模块1022,构建运行storm增量拓扑。storm拓扑接受来自高级队列中的变更消息,将变更数据同步到业务历程数据库,并更新索引表,保证过程库的一致性和实时性;
步骤204,配置数据预处理模块,添加数据转换任务。hive与hbase整合模块1031建立过程库hbase到hive的外表,实现从hive实时读取过程库hbase表数据。转换模块1032根据配置信息建立hive视图,实现数据类型、格式转换及多表连接等数据预处理;
步骤205,配置指标计算模块,完成指标数据模型定义,并通过作业调度模块执行和作业定义相匹配的指标计算任务池中的任务,完成从业务历程库到社保指标仓库的计算。元数据存储模块保存相应的数据模型、指标计算信息;指标立方体的预计算是基于kylin大数据引擎实现的,kylin支持大规模数据立方的快速计算;
步骤206,完成指标仓库的构建后,可以进行快速的olap查询分析。数据查询定义模块1061从指标元数据中获取已构建指标立方体相关信息,定义多维分析需求提交给数据查询模块1062,数据查询模块解析需求,从指标仓库预计算好的数据中获取查询结果返回给展示模块,展示模块根据需求配置进行结果展示。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!