一种计算节点内存共享系统及读、写操作内存共享方法与流程
本发明涉及通用计算节点和异构计算节点间共享内存领域,尤其涉及一种基于pci-e实现不同类型计算节点内存共享的系统及方法。
背景技术:
出于功耗及空间方面的考虑,数据中心的一些应用中已经开始使用异构计算(gpu、fpga等)加速器,许多应用已经受益于可在不同系统架构中无缝移动数据的加速器引擎。目前的加速器大多数是基于pci-e总线,但pci-e总线在不同类型计算节点中通信存在带宽低、延时高的问题,如何基于pci-e接口和交换机实现不同类型计算节点之间高带宽、低延时互访是一个需要解决的技术难题。
技术实现要素:
为解决上述问题,本发明提供一种不同计算节点的内存可以共享使用的计算节点内存共享系统及读、写操作内存共享方法。
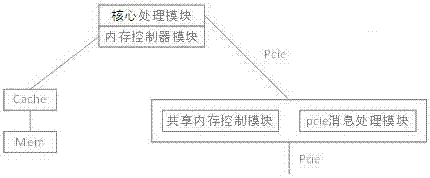
本发明的技术方案是:一种计算节点内存共享系统,所述计算节点有至少两个,每个计算节点均包括:
对读写操作进行计算处理的核心处理模块;
对cache和内存进行控制的内存控制器模块;
实现各个计算节点内存互访的共享内存控制模块;
对pcie消息进行封装和解析的pcie消息处理模块;
所述核心处理模块通过内存控制器模块与cache连接,cache与内存连接;
所述核心处理模块还通过pcie总线与共享内存控制模块连接;所述共享内存控制模块通过pcie消息处理模块与其他计算节点连接。
进一步地,各个计算节点通过pcieswitch互联。
进一步地,计算节点的类型包括各种架构的cpu、gpu和fpga。
一种实现计算节点读操作内存共享方法,计算节点包括本地计算节点和被访问计算节点,本地计算节点进行读操作处理包括以下操作:
s1:判断所读地址是否在本地cache中;
s2:如果所读地址在本地cache中,且本地cache状态表明数据有效,则从本地cache中读取数据;
s3:如果所读地址不在本地cache中或本地cache状态表明数据无效,则进入步骤s4:
s4:判断是否是读本地内存;
s5:如果是读本地内存,则通过内存控制器模块访问本地内存,然后刷新本地cache内容为本地内存中的内容;
s6:如果不是读本地内存,则调用本地共享内存控制模块;
s7:本地共享内存控制模块通过本地pcie消息处理模块把访问地址封装成pcie消息发送给被访问计算节点;
s8:被访问计算节点访问目标内存,并将访问结果发回本地计算节点进行处理。
进一步地,步骤s8具体包括以下步骤:
s8.1:被访问pcie消息处理模块接收并解析pcie消息,发给被访问共享内存控制模块;
s8.2:被访问共享内存控制模块访问目标内存;
s8.3:被访问共享内存控制模块调用pcie消息处理模块把访问结果封装成pcie消息发回本地计算节点;
s8.4:本地pcie消息处理模块解析pcie消息中的结果传给本地共享内存控制模块;
s8.5:本地共享内存控制模块把访问结果返回本地核心处理模块;
s8.6:本地内存控制器模块刷新本地cache内容为新的访问结果。
一种实现计算节点写操作内存共享方法,计算节点包括本地计算节点和被访问计算节点,本地计算节点进行写操作处理包括以下操作:
s1:判断是否是写本地内存;
s2:如果是写本地内存,则通过本地内存控制器模块访问本地cache和本地内存;如果不是写本地内存,则进入步骤s7;
s3:写内存操作完成后,通过本地共享内存控制模块调用本地pcie消息处理模块;
s4:pcie消息处理模块封装pcie消息发给其他所有计算节点;
s5:其他所有计算节点各自的pcie消息处理模块解析pcie消息;
s6:其他所有计算节点各自的共享内存控制模块更新本地cache状态;
s7:调用本地共享内存控制模块;
s8:调用本地pcie消息处理模块把访问地址封装成pcie消息发给被访问计算节点;
s9:被访问计算节点访问目标内存,并将被访问内存有变化消息发送给其他所有计算节点。
进一步地,步骤s9具体包括以下步骤:
s9.1:被访问pcie消息处理模块接收pcie消息解析后发给被访问共享内存控制模块;
s9.2:被访问共享内存控制模块访问目标内存;
s9.3:被访问共享内存控制模块调用被访问pcie消息处理模块;
s9.4:被访问pcie消息处理模块封装pcie消息发给其他所有计算节点,以通知给其他所有计算节点被访问内存内容有变化;
s9.5:其他所有计算节点各自的pcie消息处理模块解析pcie消息;
s9.6:其他所有计算节点的共享内存控制模块更新本地cache状态。
本发明提供的计算节点内存共享系统及读、写操作内存共享方法,实现不同计算节点的内存共享使用,不同类型的计算节点处理数据就不需要在各自内存中把数据搬来搬去,这样就能减少传输带宽的使用,降低处理数据的延时。
附图说明
图1是本发明系统连接部署示意图。
图2是本发明系统模块关系示意图。
图3是本发明具体实施例一读操作处理流程图。
图4是本发明具体实施例二写操作处理流程图。
具体实施方式
下面结合附图并通过具体实施例对本发明进行详细阐述,以下实施例是对本发明的解释,而本发明并不局限于以下实施方式。
如图1和2所示,本发明提供的计算节点内存共享系统,计算节点有多个,可设置至少两个。计算节点的类型有多种,可包括各种结构的cpu、gpu和fpga。各种类型的计算节点通pcie总线连接,连接的计算节点比较多时可采用pcieswitch互联。可以是相同类型的计算节点互联,也可以是不同类型的计算节点互联。
每个计算节点均包括:
对读写操作进行计算处理的核心处理模块;
对cache和内存进行控制的内存控制器模块;
实现各个计算节点内存互访的共享内存控制模块;
对pcie消息进行封装和解析的pcie消息处理模块。
核心处理模块通过内存控制器模块与cache连接,cache与内存连接;核心处理模块还通过pcie总线与共享内存控制模块连接;共享内存控制模块通过pcie消息处理模块与其他计算节点连接。
实施例一:
计算节点包括本地计算节点和被访问计算节点,如图3所示,本地计算节点进行读操作处理包括以下操作:
s1:判断所读地址是否在本地cache中;
s2:如果所读地址在本地cache中,且本地cache状态表明数据有效,则从本地cache中读取数据;
s3:如果所读地址不在本地cache中或本地cache状态表明数据无效,则进入步骤s4:
s4:判断是否是读本地内存;
s5:如果是读本地内存,则通过内存控制器模块访问本地内存,然后刷新本地cache内容为本地内存中的内容;
s6:如果不是读本地内存,则调用本地共享内存控制模块;
s7:本地共享内存控制模块通过本地pcie消息处理模块把访问地址封装成pcie消息发送给被访问计算节点;
s8:被访问计算节点访问目标内存,并将访问结果发回本地计算节点进行处理。
其中,步骤s8具体包括以下步骤:
s8.1:被访问pcie消息处理模块接收并解析pcie消息,发给被访问共享内存控制模块;
s8.2:被访问共享内存控制模块访问目标内存;
s8.3:被访问共享内存控制模块调用pcie消息处理模块把访问结果封装成pcie消息发回本地计算节点;
s8.4:本地pcie消息处理模块解析pcie消息中的结果传给本地共享内存控制模块;
s8.5:本地共享内存控制模块把访问结果返回本地核心处理模块;
s8.6:本地内存控制器模块刷新本地cache内容为新的访问结果。
实施例二:
计算节点包括本地计算节点和被访问计算节点,如图4所示,本地计算节点进行写操作处理包括以下操作:
s1:判断是否是写本地内存;
s2:如果是写本地内存,则通过本地内存控制器模块访问本地cache和本地内存;如果不是写本地内存,则进入步骤s7;
s3:写内存操作完成后,通过本地共享内存控制模块调用本地pcie消息处理模块;
s4:pcie消息处理模块封装pcie消息发给其他所有计算节点;
s5:其他所有计算节点各自的pcie消息处理模块解析pcie消息;
s6:其他所有计算节点各自的共享内存控制模块更新本地cache状态;
s7:调用本地共享内存控制模块;
s8:调用本地pcie消息处理模块把访问地址封装成pcie消息发给被访问计算节点;
s9:被访问计算节点访问目标内存,并将被访问内存有变化消息发送给其他所有计算节点。
其中,步骤s9具体包括以下步骤:
s9.1:被访问pcie消息处理模块接收pcie消息解析后发给被访问共享内存控制模块;
s9.2:被访问共享内存控制模块访问目标内存;
s9.3:被访问共享内存控制模块调用被访问pcie消息处理模块;
s9.4:被访问pcie消息处理模块封装pcie消息发给其他所有计算节点,以通知给其他所有计算节点被访问内存内容有变化;
s9.5:其他所有计算节点各自的pcie消息处理模块解析pcie消息;
s9.6:其他所有计算节点的共享内存控制模块更新本地cache状态。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!