一种基于系统辨识的STAP训练样本选择方法与流程
本发明属于雷达技术领域,具体涉及到基于系统辨识的stap训练样本选择方法。
背景技术:
空时自适应处理(stap)是雷达和通信信号处理中的一项关键技术,被广泛用于雷达及通信信号处理之中。stap要求设计最优权向量
(1)应满足rts=rcut。
(2)训练样本要足够多,因为用于估计协方差矩阵的训练样本数至少大于系统自由度的2倍,才能使stap的输出信噪比损失小于3db。
目前训练样本选择方法主要分为三类。第一类是功率选择训练算法,其基本原理是挑选杂波功率大的样本,从而加深杂波凹口深度。第二类是广义内积(gip)算法,其基本原理是通过广义内积统计量来剔除掉训练样本中与待检测单元杂波背景统计特性不同的样本。第三类是基于波形相似的方法。
其中,基于波形相似的方法尤其受到关注。该类方法通常是在时域或频域上选取与cut(待检测距离单元)杂波波形相似性较高的样本。文献《zhangx,yangq,dengw.weaktargetdetectionwithinthenonhomogeneousionosphericclutterbackgroundofhfswrbasedonstap[j].internationaljournalofantennasandpropagation,2013,2013》中提出根据时域波形相似性选取样本,计算待选样本与cut杂波的时域波形相关系数,选择相关系数大于所设阈值的样本作为训练样本。但该方法直接舍弃了相似性较低的样本,导致样本的利用率较低。针对该问题,文献《xinz,yanhuas,qiangy,etal.space-timeadaptiveprocessing-basedalgorithmformeteortrailsuppressioninhigh-frequencysurfacewaveradar[j].ietradar,sonar&navigation,2015,9(4):429-436》进一步提出基于相关系数加权的方法估计协方差矩阵。相关系数小的样本被赋予小的权值,从而使得相似性较低的样本也能被用来估计rcut,从而提高了样本利用率。文献《yifengw,tongw,jianxinw,etal.robusttrainingsamplesselectionalgorithmbasedonspectralsimilarityforspace–timeadaptiveprocessinginheterogeneousinterferenceenvironments[j].ietradar,sonar&navigation,2015,9(7):778-782》和《wuy,wangt,wuj,etal.trainingsampleselectionforspace-timeadaptiveprocessinginheterogeneousenvironments[j].ieeegeoscienceandremotesensingletters,2015,12(4):691-695》则研究了根据频域波形相似性选择样本,该方法选择与cut杂波频谱相似的样本作为训练样本,这些方法有效提高了cut杂波协方差矩阵估计的准确度。
训练样本选择问题的本质是寻找与待检测距离单元杂波具有相同协方差矩阵的样本。而在两个信号的协方差矩阵相同时,这两个信号的波形可能完全不相似,因此选取的训练样本中可能存在波形完全不相似的样本,传统基于波形相似性的样本选择方法容易遗漏大量相似性低的可用样本。
技术实现要素:
本发明针对stap中基于传统训练样本选择方法的样本漏选问题,提出了一种新型的基于系统辨识的训练样本选择方法。
对于包括n个阵元的雷达天线,用m表示一个相干处理间隔(cpi)内的脉冲数,则第k个距离单元的回波信号xk可以如下表示:
xk=ξks+ck+nk(1)
其中ck是杂波信号,nk是接收的噪声,s是目标信号空时导向向量,ξk是目标的增益系数,xk,ck,nk,s均为mn维的复向量。用xcut表示待检测距离单元的回波信号。
stap的最优权向量w可以通过求解如下优化问题得到:
其中rcut为待检测距离单元的杂波协方差矩阵,符号“(·)h”表示共轭转置。计算可求得最优权向量为:
上式中rcut一般是未知的,需要通过训练样本
为准确估计协方差矩阵以保障stap性能,理想的训练样本与cut的杂波协方差矩阵应相同,即
然而在实际情况中,由于地形、地貌的空间变化,强散射点以及阵列等原因,导致训练样本的统计特性偏离待检测单元的统计特性,即
现有stap训练样本的选择方式是挑选时域或频域波形与cut相似的样本。然而协方差矩阵相同不等价于波形相似,即,
具有相同杂波协方差矩阵的两个距离单元,其波形不一定相似。
对上述的结论证明如下:
设时间序列分别为x=(x1,x2,…,xl,…,xn)t,y=(y1,y2,…,yl,…,yn)t的2个波形满足xxh=yyh,其中,
由于xxh=yyh,x与y的模与辐角应分别满足式(6)与(7):
|y1|2=|x1|2,|y2|2=|x2|2,…|yn|2=|xn|2(6)
β1-β2=θ1-θ2,β1-β3=θ1-θ3,…,β1-βn=θ1-θn(7)
记α=β1-θ1=β2-θ2=…=βn-θn,则x与y的相关系数γx,y为:
显然只有当α=0时,x与y才线性相关;当α=π/2时,则x与y完全不相关。因此,具有相同杂波协方差矩阵的两个距离单元,其波形不一定相似。
因此,在现有stap训练样本的选择方式会漏选波形不相似、杂波协方差矩阵却相似的样本。其训练样本选择的范围变小了,一些性能更好的样本可能被遗漏了。在地貌、地形变化很快的环境下,此类方法可获得的训练样本将更少,协方差矩阵估计的误差将更大,导致stap的性能严重下降。
如果直接选取杂波协方差矩阵与cut相同的训练样本,将可以避免上述基于波形相似性产生的问题。
本发明中,通过滤波输出方差来判断判断两个向量的协方差矩阵是否相同。其原理分析如下:
设有两时间序列{x(n)}与{y(n)},记作向量x=(x(1),x(2),…,x(n))t,y=(y(1),y(2),…,y(n))t,rxx与ryy分别是各自的协方差矩阵。设时间序列{x(n)}的白化滤波器为h,这里的h可以看作是{x(n)}的模型。滤波输出为白噪声{ex(n)},其方差为
若
因上述模型h可能是线性,也可能是非线性系统,因此下面分两种情况论证。
(a)当模型h是线性系统时。
一个线性时间序列通常可用自回归滑动平均模型(arma)建模,{x(n)}的arma模型为:
上式中,{ex(n)}是方差为
则上述向量x的自相关函数rx(m)为:
式(11)表明,对于一个确定的模型h,信号x的自相关函数rx(m)取值只与
(b)当模型h是非线性系统时。
在实际处理中,信号可能是一个复杂的非线性时间序列。双线性模型是一种一般性的非线性时间序列模型,理论上可以证明,任何连续的因果泛函都可以用一个双线性系统来逼近。此时非线性时间序列{x(n)}可采用双线性模型对其建模。grander和anderson定义的阶数为p,q,r,s的双线性时间序列模型满足式(12)所示差分方程:
上式中,ai,bj,ck,l为系统的参数,{ex(n)}是方差为σx2的白噪声序列。显然双线性模型是线性arma模型的直接推广。
上述向量x的自相关函数rx(m)典型表达式为:
其中d为积分域[-π,π],α(ω)、β(ω)、γ0(ω)及z的表达式如式(14)(15)所示,
多项式α(ω)、β(ω)、γ0(ω)只与该双线性系统的模型参数有关,对于确定的模型,z只与
在选择stap训练样本时,如果把cut杂波视作上述时间序列{x(n)},待选样本xk视作上述时间序列{y(n)},h为cut杂波模型。当其对应的滤波输出方差相等时,则可以认为其协方差矩阵相同,则样本可以选作训练样本。于是,样本选择问题转变成了cut杂波的系统模型h的辨识问题。
因h既可能是线性系统,也可能是复杂的非线性系统。而神经网络不仅能对线性系统进行建模,而且还具有很强的非线性映射能力。基于该考虑,本发明采用神经网络对cut杂波进行建模,辨识出其模型h。此外,考虑到回声状态网络(esn)是一种新型递归网络,相较于传统的神经网络具有更好的稳定性及精度,因此优选回声状态神经网络(如雷达科学与技术2015年8月第4期公开的“基于回声状态网络的othr海杂波抑制方法”中所提及的回声状态神经网络)辨识cut的杂波模型h,即基于cut进行多次杂波预测模型(如回声状态神经网络、或者其他神经网络(如径向基神经网络)、volterra模型等)训练,通过训练不断调整自身的参数,以近似逼近杂波模型h,取滤波输出方差
步骤1:基于待检测距离单元cut进行多次杂波预测模型训练,从中选择滤波输出方差
步骤2:通过cut杂波模型h对待选样本xk进行滤波,得到滤波输出的方差
步骤3:若方差
由于杂波具有混沌特性,理论上cut单元的杂波经模型h后的滤波输出为0。因此,如果待选样本xk与cut的杂波协方差矩阵相同,其滤波后的输出方差
进一步,步骤3中,也可以直接将
本发明适用于stap中估计协方差矩阵的训练样本选择问题,即基于本发明的训练样本的选择结果,估计cut杂波的协方差矩阵rcut,计算stap的最优权向量w,得出滤波器的输出scnrout。从而有效提升现有stap的性能。
与传统基于波形相似选择训练样本的方法相比,本发明的有益效果为:
(1)能获得更多的有效样本,可有效解决样本的短缺问题;
(2)估计的杂波协方差矩阵更准确,杂波的抑制性能更好。
附图说明
图1为本发明具体实施方式的流程图。
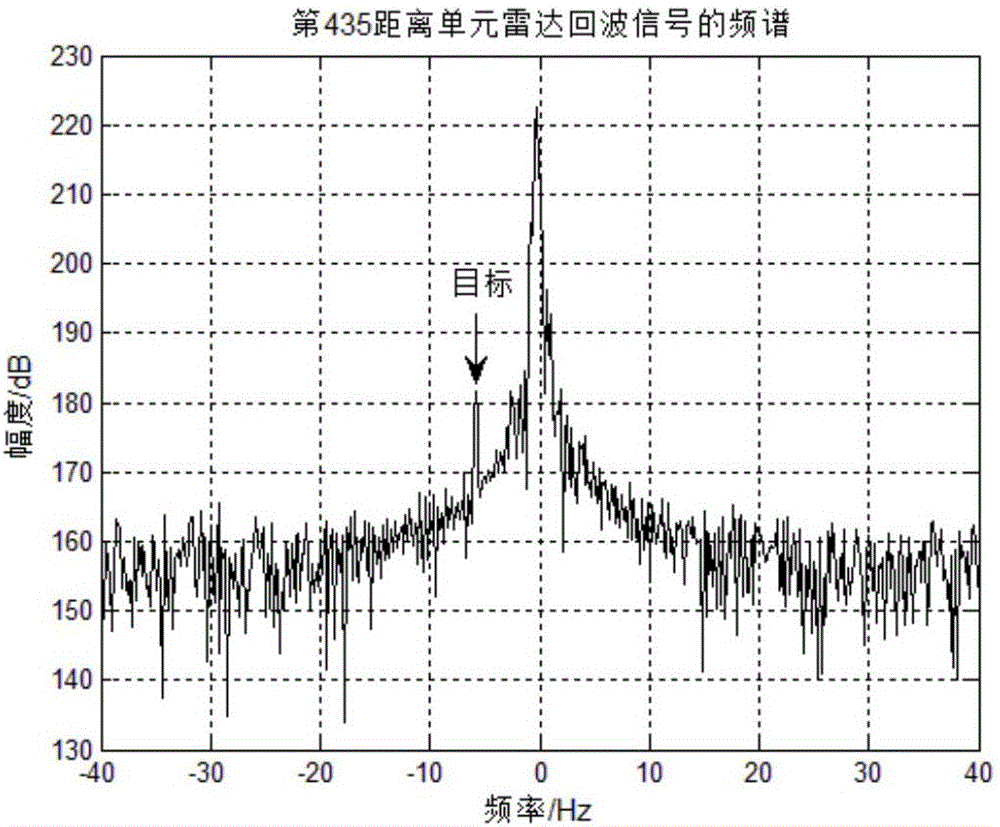
图2为第435距离单元雷达回波信号的频谱。
图3为各距离单元与cut的相关系数。
图4为各距离单元滤波后的归一化输出方差。
图5为两种方法的杂波抑制结果,其中5(a)为基于相似性的方法,5(b)为本发明所提方法。
图6为不同输入scnr条件下的杂波抑制性能。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。
将本发明用于stap中的估计协方差矩阵,具体实现步骤如图1所示:
步骤s1:使用待检测距离单元cut的回波信号xcut多次训练回声状态神经网络,辨识出cut的杂波模型h,选择多次训练滤波输出方差
步骤s2:使用训练好的回声状态神经网络对待选样本xk(k=1,2,…)进行滤波,得到滤波输出的方差
步骤s3:设置合适的阈值(取值接近0的正数),如果
步骤s4:利用步骤3中选取的训练样本
实施例
以天波雷达工作频率f0=18.3mhz,脉冲重复周期t=12ms,脉冲积累个数m=512,相干积累时间cit=6.144s。回波数据中,已知待检测的第435距离单元有一个多普勒频率为-5.859的目标,其频谱如图2所示。图3是各距离单元数据与待检测单元之间的相似性,图4表示各距离单元经训练好的神经网络滤波后的归一化输出方差。
如果基于相似性来选择训练样本,理论上应尽可能选取相关系数接近1的样本。然而受制于可选样本数量的限制,此处根据参考文献《zhangx,yangq,dengw.weaktargetdetectionwithinthenonhomogeneousionosphericclutterbackgroundofhfswrbasedonstap[j].internationaljournalofantennasandpropagation,2013,2013》,选取相关系数大于0.7的样本作为参考样本,总共可获得25个参考样本。
若采用本发明所提参考样本选取办法,选取归一化预测误差方差小于0.165的样本作为参考样本,最终能获得的56个有效的训练样本。表1统计了这56个训练样本在各个相关系数区间的数量。从表1可以看出,与cut相关系数小于0.1的训练样本数量为16,它们与cut几乎完全不相关。然而,这些样本与cut杂波却具有相似的协方差矩阵,因此可以选做训练样本。
表1所选训练样本在各相关系数区间的数量
传统的基于相似性的样本选择方法漏选了与cut波形不相似、杂波协方差矩阵却相似的样本。本发明所提方法的选择目标是与cut具有相似杂波协方差矩阵的单元,因此能获得更多的训练样本。
分别采用两种方法对第435距离单元进行杂波抑制,仿真结果如图5所示。图5(a)是利用相似性选择样本的方法进行海杂波抑制后的各频率归一化输出scnr结果。目标-5.859hz多普勒频率处的输出scnr最高,比第二高峰高出11.202db。图5b)是本发明所提方法的仿真结果。目标信号的多普勒频率处有一个更高的突起,杂波的输出归一化scnr全被抑制在-13.34db以下。相比于图5(a)中基于相似性选择样本的方法,本发明所提方法对杂波的抑制效果更好,更容易检测出目标信号。
为了比较本文所提方法与基于相似性选择样本的方法在不同输入scnr条件下的杂波抑制性能,本次仿真实验使用另一雷达回波数据,在第144距离单元模拟添加多普勒频率为fd=1hz的目标,输入scnr的取值从-30db到-10db取值。图6为两种方法在不同输入scnr条件下的杂波抑制性能。纵坐标为目标频率处输出scnr与其余频率范围内最大输出scnr的差值。该差值表征了目标多普勒频率处的输出scnr的凸起程度,差值越大,说明杂波抑制效果越好,目标更容易被检测到。经计算,本文所提的方法其输出scnr差值比使用基于相似性的方法平均高出2.71db,杂波的抑制性能更好。
通过以上仿真,验证了本发明的两点优势:(1)能获得更多的有效样本,可有效解决样本的短缺问题;(2)估计的杂波协方差矩阵更准确,杂波的抑制性能更好。
- 还没有人留言评论。精彩留言会获得点赞!