一种基于深度学习的雾霾能见度检测方法与流程
本发明涉及图像处理技术领域,特别是一种基于深度学习的雾霾能见度检测方法。
背景技术:
近年来,雾霾天气频发,气象专家对雾霾天气的众多原因做了分析。据悉,持续的雾霾天气给各行各业带来了比较严重的影响,首先就是对于交通运输的影响,受雾霾影响的地方航班延误甚至被取消,高速公备被封闭,海上交通也遭到了不同程度的影响。包括铁路,雾霾引起的“雾闪”导致京广铁路断电,临时停车或者延误事件时有发生,而准确的能见度检测是缓解该问题的必要环节之一。
传统的雾霾能见度检测方法分为人眼目测法和仪器测量法,人眼目测法是指:在人眼没有任何帮助的条件下,所能识别物体的最大距离。这往往会带来很多的人为误差,而仪器测量法是指:通过一些光学元器件进行能见度值的检测,这种设备通常比较昂贵,且使用起来不是特别方便,于是,近些年来开始有更多的人关注于基于图像的雾霾能见度检测,主要是通过对大气消光系数的估计进行能见度值的计算,这是一个复杂计算的过程。基于上述的种种,开始有人考虑用机器学习的方法进行能见度的识别,但都只是设想,暂时没有什么具体的模型。
技术实现要素:
本发明所要解决的技术问题是克服现有技术的不足而提供一种基于深度学习的雾霾能见度检测方法,构建雾霾图像检测模型,以达到雾霾图像能见度有效的识别效果。
本发明为解决上述技术问题采用以下技术方案:
根据本发明提出的一种基于深度学习的雾霾能见度检测方法,包括以下步骤:
步骤1、创建道路交通雾霾图像库,该数据库包括训练样本集和交叉验证样本集;
步骤2、对步骤1中交通雾霾图像库中训练样本集和交叉验证样本集里所有的雾霾图像进行预处理;
步骤3、采用卷积神经网络提取训练样本集里预处理后的雾霾图像的最远能见度边缘特征,得到多个特征图;将特征图通过前向传播至配置好的卷积神经网络进行训练,并通过反向传播算法进行卷积神经网络中各层间权重的调整,反复迭代求取得用于雾霾图像分类的卷积神经网络模型,再通过预处理后的交叉验证样本集对卷积神经网络模型进行优化,最终得到一个用于对雾霾图像分类的能见度检测模型;
步骤4、利用步骤3中得到的能见度检测模型对于路面摄像机拍摄的图片进行分类判断,从而实现对雾霾状况的实时检测。
作为本发明所述的一种基于深度学习的雾霾能见度检测方法进一步优化方案,卷积神经网络为一个包含输入层、隐层和输出层的多层网络。
作为本发明所述的一种基于深度学习的雾霾能见度检测方法进一步优化方案,卷积神经网络是具有权值共享的网络结构。
作为本发明所述的一种基于深度学习的雾霾能见度检测方法进一步优化方案,卷积神经网络是在caffenet网络的基础上通过参数的设置进行训练和验证的。
作为本发明所述的一种基于深度学习的雾霾能见度检测方法进一步优化方案,caffenet网络包括2个数据层和5个卷积层,2个数据层分别为用于训练的数据的输入和用于验证的数据的输入。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
(1)首次将深度学习的相关算法与雾霾能见度检测进行结合,并取得了相当可观的实验效果;
(2)不需要光学测量仪器的帮助,只需要监控路面的拍摄图片,就可对雾霾能见度进行快速分类和识别。
附图说明
图1是本发明的流程图。
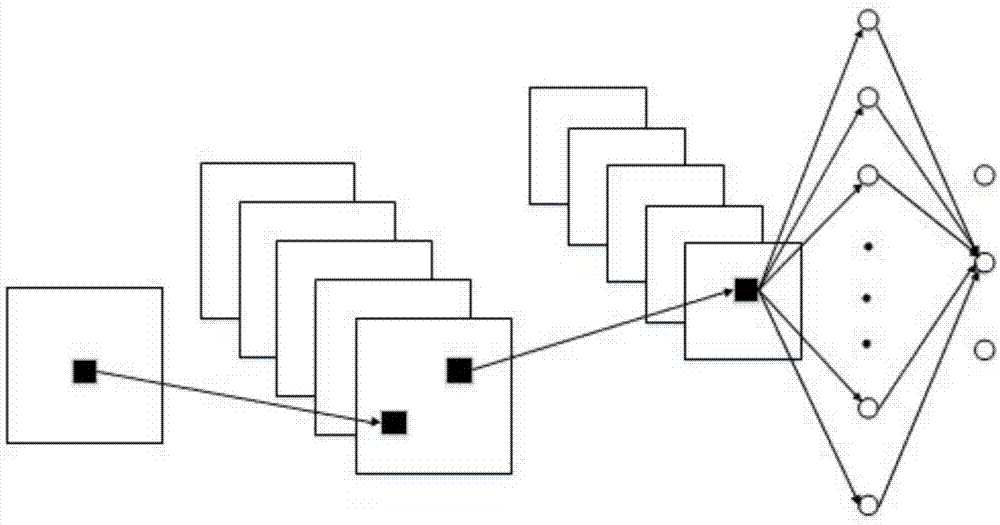
图2是卷积神经网络结构示意图。
图3是神经元结构图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
本发明具体是一种使用自建的交通图像数据库,并将卷积神经网络作为算法的训练和验证网络来实现的雾霾能见度检测算法,接下来将详细介绍具体的实现过程。
如图1所示是本发明的流程图,本发明的基于深度学习的雾霾能见度检测方法的实现主要包含以下步骤:
步骤1:创建道路交通雾霾图像库
数据集方面将采用两个数据集,第一个数据集是用来训练的,第二个数据集用来验证的,根据经验采用8:2的比例进行数据的分配。根据《中华人民共和国道路交通安全法实施条例》第81条机动车在高速公路上行驶,遇有雾、雨、雪、沙尘、冰雹等低能见度气象条件时,应当遵守下列规定:
(一)能见度小于200米时,开启雾灯、近光灯、示廓灯和前后位灯,车速不得超过每小时60公里,与同车道前车保持100米以上的距离;
(二)能见度小于100米时,开启雾灯、近光灯、示廓灯、前后位灯和危险报警闪光灯,车速不得超过每小时40公里,与同车道前车保持50米以上的距离;
(三)能见度小于50米时,开启雾灯、近光灯、示廓灯、前后位灯和危险报警闪光灯,车速不得超过每小时20公里,并从最近的出口尽快驶离高速公路。
因此将训练和验证数据分为三类,训练数据集的图像根据能见度在200米、100米、和50米范围内。分别在南通市临海公路如东段和南京g205滁河大桥架设监控摄像机,实时监控道路天气状况并录像。调取监控视频,选择三类天气状况的视频,按照能见度的不同分为,高能见度(200米范围),中等能见度(100米)和低能见度(50米范围),按帧截取视频图片,将图片像素全部设置为256*256,分别标记为high、mid和low,其中各有1000张图片。验证部分的图像也按上述方法分类,标记为high、mid和low,这个数据集较小,分别有125张图片。
步骤2:预处理雾霾图像
进行图像的预处理也就是对输入数据进行的准备工作,本发明的实验部分是在caffe平台上部署实施的。caffe是一个比较高效的深度学习框架,采用纯粹的c++/cuda架构,支持命令行、matlab及python接口,可以实现gpu和cpu的无缝切换。对图像进行预处理,也就是预处理图像的lmdb构建。具体实现步骤如下:
首先,将步骤1中的三类数据进行加标签处理,分别将high、mid和low标记为0、1、2,并生成可以被网络识别的标签文件;
其次,通过自写脚本程序生成卷积网络训练过程中所必需的数据库文件和均值文件;
步骤3:卷积神经网络的训练
雾霾检测模型的卷积神经网络可视为一个包含输入层、隐层和输出层的多层网络,其结构示意图如附图2所示。
卷积层
一个卷积层包含很多个特征图,特征图中的每个神经元都与前一层的局部感受野相连,其中神经元的结构图如附图3所示。特征图中的每个神经元与具有自主学习能力的卷积核进行卷积来获取好的局部能见度边缘特征,再经过与之相连的非线性激活函数输出得到该层的雾霾图像边缘信息的特征图。
非线性层也称作激活函数(activationfunction)或挤压函数(squashingfunction),一般地,最常用的激活函数有三种,分别是sigmoid函数、tanh函数和relu函数。深度神经网络最大的问题就是梯度消失问题,实验表明这在使用sigmoid函数、tanh函数等饱和函数时情况更为严重。这是因为神经网络进行误差反向传播时,各层都要乘以激活函数的一阶导数,梯度每传递一层就会有一次的衰减,所以当网络的层数较多时,梯度就会不停地衰减至消失。这样便会使得这类函数的训练网络收敛速度极慢,故本发明采用relu函数。relu函数,即规整化线性单元(rectifiedlinearunit),它是一种非饱和的激活函数。本发明里卷积层采用的计算公式和激活函数分别为:
yl=xk*hkl(1)
yl:代表第l个输出通道的能见度特征图
xk:代表输入的雾霾图像的第k个输入通道的特征图
hkl:第k行l列的卷积核
下采样层(pooling层)
下采样层也称为次抽样层或者池化层,是对输入进行采样操作,它把输入图像分割成不重叠的矩形,对于每个矩形取最大值(maxpooling),或者对每个矩形取平均值(meanpooling)。池化操作使得特征图个数不发生变化,但是降低了特征的维度。
全连接层
在卷积层和下采样层之后,会连接一个或多个全连接层。使得每个节点与相邻层的所有节点都有连接关系。主要的计算类型:矩阵-向量乘(gemv)
假设输入节点组成的向量为x,维度为d;输出节点组成的向量为y,维度为v;权值矩阵为w,维数是d*v,则全连接层计算可以表示为:
y=w·x(3)
本发明所采用的卷积神经网络是在caffenet网络的基础上通过参数的设置进行训练和验证的,所使用的网络包括以下部分:
首先是2个数据层,分别为用于训练的数据的输入和用于验证的数据的输入;
然后共有5个卷积层:第一层卷积层包含有一个96个11*11的卷积核,卷积输出的跳跃间隔设置为4,使用gaussian(高斯)权值进行加权,输出96个雾霾图像的featuremap(特征图)。卷积层后接rule激活函数,对激活函数后输出的雾霾图像边缘信息特征图使用最大值采样法进行采样,kernel_size(核大小)设置为2,stride(步数)也设置为2。为了达到“侧抑制”的效果,可以采用对一个输入的局部区域进行归一化处理,这里用的是lrn(局部归一化)层,将求和的正方形local_size(区域长度)设置为5,归一化公式中的alpha设置为0.0001,beta设置为0.75,归一化时,在各自通道内部的图像平面上延伸,每个输入值除以如下的公式:
xi:输入值
α、β:上诉的alpha和beta值
n:local_size值
第二层卷积层:采用256个5*5的卷积核,设置pad值为2,stride值为1;使用rule激活函数;继续使用最大值采样,kernel_size为3,stride为2;然后进行归一化。
第三层卷积层:采用384个3*3的卷积核,设置pad值为1,stride值为1;使用rule激活函数,没有经过下采样层和归一化操作。
第四层卷积层:采用384个3*3的卷积核,设置pad值为1,stride值为1;使用rule激活函数,没有经过下采样层和归一化操作。
第五层卷积层:采用256个3*3的卷积核,设置pad值为1,stride值为1,加偏置bias为1;使用rule激活函数;继续使用最大值采样,kernel_size为3,stride为2;然后进行归一化。
雾霾图像经过卷积层后接入全连接层,并设置num_output(输出向量维数)为4096,也就是该层输出元素的个数为4096个,通过rule激活函数输入dropout层,dropout层是为了防止训练过程中cnn网络中的过拟合现象。再经过上述过程的全连接,进入最后的输出num_output为3的全连接,并通过1个accuracy层用于显示训练过程中的准确率和1个softmaxwithloss层用于显示训练过程中数据的丢失率。
步骤4:训练并优化网络模型
为了验证网络的性能,实验采用caffe平台进行网络的训练和优化。将预处理好的雾霾图像放进设置好的网络中进行训练,输入的交通雾霾图像首先通过前向传播至输出层,然后得到输出,并计算输出值能见度值与真实值之间的误差。将计算得到的误差按照误差最小原则通过反向传播的方式逐层向后传播,在反向传播的过程中自动更新各网络之间的权重。反复迭代,最终得到了一个可以进行快速雾霾图像分类的识别器,通过计算所用雾霾测试图像的丢失率和准确率,来决定模型训练的步数,最终得到一个准确率较高又不至于过拟合的雾霾图像能见度检测模型。训练过程中的丢失率和测试结果的准确率如下表1所示:表1是丢失率与准确率。
表1
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替代,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!