一种基于词对齐的历史典籍分词方法与流程
本发明涉及自然语言处理技术领域,具体是一种基于词对齐的历史典籍分词方法。
背景技术:
中文分词,指将连续的汉字序列按照一定的规范重新合成词序列的过程。分词是自然语言处理中由字到词的重要部分,是对文字进行文本分类,信息检索等处理的保证。现有的主要分词方法有基于规则的分词方法和基于统计的分词方法。很多分词方法在现代汉语中取得了较为理想的分词效果,大部分算法及其商业实现均已达到很高的水平。古文较现代汉语来说,更简洁紧凑,除了历史典籍和人名以外,通常词就指单字,而且古文句法结构比现代汉语更加灵活。目前,对于古汉语分词的尝试并不多:南通大学的钱志勇等学者用hmm方法对先秦时期的部分语料进行了分词以及标注;南京师范大学的石民等学者用crf对《左传》进行了分词。以上两种方法都需要大规模语料库的支持。如果在目前这种缺乏面向古汉语的分词词典和大规模的分词训练语料的情况下,将现代汉语的分词方法直接套用到古汉语中,必然得不到较为满意的效果。
技术实现要素:
在古汉语翻译过程中,名词、术语一般保留不变,每个单字翻译对应该词本身;而其他词性的字,一般情况下,每个字对应一个或多个词。本发明基于古汉语翻译的特点以及缺乏古汉语分词语料的现状,提出了一种基于词对齐的历史典籍分词方法,通过词对齐这个桥梁,利用现代汉语中丰富的语料资源和方法,实现了在缺少古汉语标注语料的前提下对古汉语进行分词,提高了分词的准确率。
为实现上述目的,本发明采用的技术方案如下:
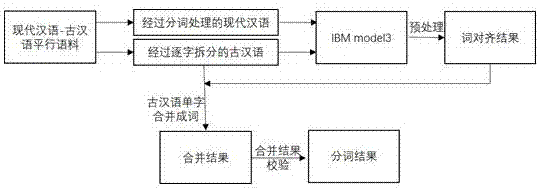
一种基于词对齐的历史典籍分词方法,包括以下步骤:
步骤1:对平行语料中的现代汉语进行分词,对古文进行逐字拆分。将古文和现代汉语使用ibmmodel3模型进行词对齐。
步骤2:对步骤1中得到的对齐结果进行预处理,消除标点符号及副词的干扰。
步骤3:根据步骤2中经预处理得到的词对齐结果对古文单字进行合并。
步骤4:对合并结果中由三个或者三个以上的字构成的词进行校验。
进一步地,步骤2所述的对齐结果的预处理的具体步骤如下:
(1)对步骤1中得到的对齐结果进行逐条校验,删除对齐概率小于或等于零、古文单字或对应现代汉语为非汉字的对齐结果;
(2)步骤2中对每条对齐结果中两个词或字的词性进行检验,若副词在对齐文件中对齐名词,则保留;反之,则删除。由于一般情况下,副词在古文中只表达虚意,在对齐中会形成较大的干扰,但有些副词同时还对应着名词、动词等其他词性,若直接删除,势必会对某些人名、地名的分词产生影响,因此只留下对齐名词的副词对齐结果。
进一步地,步骤3中古文单字合并的具体步骤如下:
(1)对已经拆分成单字的古汉语,逐字查询其对应的现代汉语,若相邻两个字均对应同一个现代汉语翻译,则合并这两个字;
(2)继续观察后面的单字,若依然对应同一个现代汉语,则继续合并。直到下一个字不再和前面的词指向同一个汉语翻译为止;
(3)若单字是零到九的用于表示年代的数词,则对它们进行合并。
进一步地,步骤4中对合并结果中由三个或者三个以上的字构成的词进行校验的具体步骤如下:
(1)对每一个由三个及三个以上的字构成的词,在现代汉语翻译中对该词进行查找,若成功找到,则视为分词结果正确;
(2)若未找到,说明该候选词合并有误,应当对其进行分割:从候选词的第一个字后开始分割,将产生的两个词段分别在现代汉语中进行查找比对。若成功找到,则保留分割结果,此时视为分割成功;若未找到,则继续从第二个词后分割,并以此类推,直到找到相匹配的词段。
本发明的有益效果:本发明通过词对齐这个桥梁,利用现代汉语中丰富的语料资源和方法,结合古汉语翻译过程中的一些特点,解决了在缺乏面向古汉语的分词词典和大规模的分词训练语料的情况下对古汉语进行分词的问题,提高了分词的准确率。
附图说明
图1本发明方法的流程示意图。
具体实施方式
以下结合附图对本发明做进一步说明。
参见附图1,一种基于词对齐的历史典籍分词方法:首先对平行语料中的现代汉语进行分词,对古文进行逐字拆分,并将古文和现代汉语使用ibmmodel3模型进行词对齐;其次,对上一步中得到的对齐结果进行处理,消除标点符号及副词的干扰;再次,根据经预处理得到的对齐结果对古文单字进行合并;最后,对合并结果中由三个或者三个以上的字构成的词进行校验。
实施例1
本实施例以eclipse为开发平台,java为开发语言。在《史记》中的《秦始皇本纪》、《秦本纪》、《项羽本纪》、《高祖本纪》和《吕后本纪》的古文与白话文的4145句对语料上进行。以下为具体过程:
步骤1:对平行语料中的现代汉语进行分词,对古文进行逐字拆分。将古文和现代汉语使用ibmmodel3模型进行词对齐。
步骤2:对步骤1中得到的对齐结果进行预处理,消除标点符号及副词的干扰:
(1)对步骤1中得到的对齐结果进行逐条校验,删除对齐概率小于或等于零、古文单字或对应现代汉语为非汉字的对齐结果;
(2)对每条对齐结果中两个词或字的词性进行检验,若副词在对齐结果中对齐名词,则保留;反之,则删除。因为一般情况下,副词在古文中只表达虚意,在对齐中会形成较大的干扰,但有些副词同时还对应着名词、动词等其他词性,若直接删除,势必会对某些人名、地名的分词产生影响,因此只留下对齐名词的副词对齐结果。
例如古文中的“耳”:“耳”在古文中普遍用作虚词,不翻译,但重耳、张耳等历史典籍人物是名词,为消除虚词干扰,需要对“耳”在对齐文件里对齐的现代汉语翻译进行词性判断,若是名词,例如:“重耳”,则保留;若不是名词,则直接删除。
步骤3:根据步骤2中处理好的对齐结果对古文单字进行合并:
(1)对已经拆分成单字的古汉语,逐字查询其对应的现代汉语,若相邻两个字均对应同一个现代汉语翻译,则合并这两个字;
(2)继续观察后面的单字,若依然对应同一个现代汉语,则继续合并。直到下一个字不再和前面的词指向同一个汉语翻译为止;例如:古汉语“周武王伐纣,并杀恶来”对应现代汉语“周武王讨伐纣王,连同恶来一起杀死”。在词对齐结果中,“周”、“武”、“王”三字均对齐同一词“周武王”,所以就将这三个字合并作为一个词。而“伐”对齐“讨伐”,因此,将“伐”同前面的“王”分离开。
(3)若单字为零到九,用于表示年代的数词,则对它们进行合并。
步骤4:对合并结果中由三个或者三个以上的字构成的词进行校验:
(1)对每一个由三个及三个以上的字构成的词,在现代汉语翻译中对该词进行查找,若成功找到,则视为分词结果正确;
(2)若未找到,说明该候选词合并有误,应当对其进行分割:从候选词的第一个字后开始分割,将产生的两个词段分别在现代汉语中进行查找比对。若成功找到,则保留分割结果,此时视为分割成功;若未找到,则继续从第二个词后分割,并以此类推,直到找到相匹配的词段。例如:“张良悦”是一个由三个字构成的词。在现代汉语翻译中进行查找后未发现该词,说明分词有误,须对该词进行分割。从第一个字后分割得到“张”和“良悦”,进行查找比对后均无匹配词段。再次对该词分割,得到“张良”和“悦”,查找后发现“张良”成功匹配,则视为分割正确,遂将分词结果替换为“张良/悦”。
根据以上步骤,本发明将分词效果与结巴分词、斯坦福分词以及nlpir分词方法做了对比,见表1,结巴分词和nlpir是目前国内广泛使用的分词方法,斯坦福分词是国外具有代表性的一种中文分词方法。
表1不同分词方法结果对比
从表1中可以看出,本发明提出的方法在分词准确率、召回率以及f1度量方面明显优于其他方法。f1度量是准确率和召回率的调和平均。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!