基于混合向量量化的最近邻搜索方法与流程
本发明涉及信息检索与多媒体检索,尤其是涉及基于混合向量量化的最近邻搜索方法。
背景技术:
最近邻检索在计算机很多领域都是被重点研究的问题。它在很多领域都起到基础性作用,比如数据库、机器学习、计算机视觉和信息检索。最近邻搜索问题可以被简单定义如下:给定维度相同的查询向量q和n个候选向量。目标是返回某种距离度量方式(通常是l1-距离或者l2-距离)下,在空间中距离查询向量最近的那些候选向量。
可以通过线性搜索整个候选集来找到最近邻。然而,线性搜索的时间复杂度是o(n·d)。尽管线性搜索的时间复杂度对维度和数据规模都是线性增长的,但是当维度和数据规模都增长的时候,其时间复杂度实际上是二次增长的。因此,在大规模地高维且稠密的向量空间里进行实时搜索几乎是不可能的。在这种情况下,大部分的传统方法,比如k-d树、r-树和局部敏感哈希(lsh)无法得到满意的结果。
近几年,基于向量量化的方法因其在高维数据上简单的计算,显著更低的空间消耗和不错的结果,变得越来越受欢迎。代表性的方法有乘积量化子(pq)、加法量化子(aq)和组合量化子(cq)。pq把高维向量分解成几段,每一段被一个量化子所量化,该量化子是从对应的子空间里的子向量训练得到。最后,原始向量被几段连接起来的单词所近似,其中每一个单词都是对应子空间码本中距离原始子向量最近的单词。查询向量和候选集向量的距离被近似为查询向量在对应子空间里的最近邻的距离之和。不同于pq、aq和cq不把向量分解成段。它们用几个与原向量同维度的单词加和来表示原向量。这些单词选自预先训练的码本,每一个码本至多选择一个向量。与pq相似,查询向量与候选集向量之间的距离被近似为查询向量与这些被选择的基本向量的距离的加和,并且借助查询表来达到有效的距离计算。
量化方法的优点包括两个方面。一方面,候选集向量已经被压缩(通常内存消耗会降低一个数量级),这使得将整个参照数据集可以被载入内存。另一方面,通过查表来计算查询向量与候选集向量之间的距离,速度非常快。然而,这些基于量化的方法里,都对被检索的数据有一个隐含的假设。考虑到计算消耗,在量化的时候,只采用数目有限的单词;因此,量化不能很好近似能量跨度很大的数据集。比如,给定向量[0.1,0.03,…]1*128和[55,122,…]1*128,它们的能量差异非常大。因为大的能量差,当前的方法可能只能很好近似表示其中一个向量,而不能有效近似另一个向量。当采用它们之中的任何一个做最近邻搜索的时候,都不得不进行线性搜索,这使得这些方法难以应用到大规模的搜索任务中。
技术实现要素:
针对以上问题,本发明的目的在于提供基于混合向量量化的最近邻搜索方法。
本发明包括以下步骤:
1)混合向量量化的编码方法:
给定一个向量v∈rd,对其前i阶的余向量(第一阶为向量本身)进行余向量量化,后面j阶的每阶余向量对其方向向量(归一化后的向量)和能量分别编码;假设i=2,j=2,则其编码形式如下:
在公式(1)中,
在编码中,设总的编码阶数为n,即n=i+j,则其中i由具体的问题确定,若待检索的数据集很大,则i的值大;因为前面i阶将用作生成倒排索引结构的索引,i值越大所能生成的索引值越多,可以索引的数据量也越大;目的是把数据集尽量打散,保证每次最近邻查询都只访问少量的候选向量;
2)基于低阶余向量量化编码的倒排索引结构:
(1)设采用四阶编码,即n=4,经过步骤1),输入向量q将编码为c1c2c3h0c4h1;其中,c1c2为余向量量化后的编码,这两个编码将合并作为倒排表的索引键值,即i=c1c2,而余下的编码将存放在倒排表该索引键值所对应的链表中;
(2)链表的每一项存放了候选向量的标记和余下的高阶编码,例如n=4情形下链表中每个候选项为<id,c3h0c4h1>。
3)基于层级剪枝的在线搜索策略:
(1)给定查询点q,搜索过程首先计算查询点q到每一个倒排索引键值的距离,这时需要把键值i拆分为c1和c2,c1和c2分别对应第一阶码本中的向量
在公式(2)的计算中,为了加快计算速度,可以先算q到
(2)经步骤(1)之后,查询计算q到候选链表中每一个候选项的距离,计算的公式如下,注意到公式(2)的计算结果可以加入到公式(3)的计算中以加快计算速度:
(3)步骤(2)之后,查询将获得q到经过混合编码的候选向量的距离,查询对距离排序,然后输出。
本发明提出一种基于剩余向量量化(rvq)的方法,从编码和索引结构两方面做出了改进。rvq是一种递归地量化上一步向量量化得到的残差向量来逼近原始向量的方法。实验观察到,训练简单的rvq与需要复杂训练的aq,cq和sq可以取得近似的结果。本发明将rvq进行了改进,使其适用于能量跨度很大的数据集。本发明中,向量和其残差向量在量化之前,都会先被标准化得到向量的能量和单位方向向量,然后对单位方向向量和能量分别进行量化,本发明被命名为递归标准化向量量化(rnq)。
在本发明的倒排搜索结构采用了一种混合rvq和rnq的编码方式。也就是,低阶的剩余向量采用rvq编码,而高阶的剩余向量采用rnq编码。这种设计充分利用了rvq的低阶编码效率和rnq的低编码误差。在搜索时,低阶的rvq码被当作倒排索引键值。为了构造有区分度的索引键值来加速搜索,做了一个关于rvq码本设置的综合性研究,发现在每一阶上合理设置码本的单词数量可以降低编码误差;采用多阶的单词数目少的码本得到的倒排表键值比用一阶的单词数目多的码本构造出来的编码误差更低;并且,多阶倒排键值能很灵活的扩展到十亿级别的数据集上。
附图说明
图1为mxq在低2阶作倒排索引键值,高2阶作rnq编码。
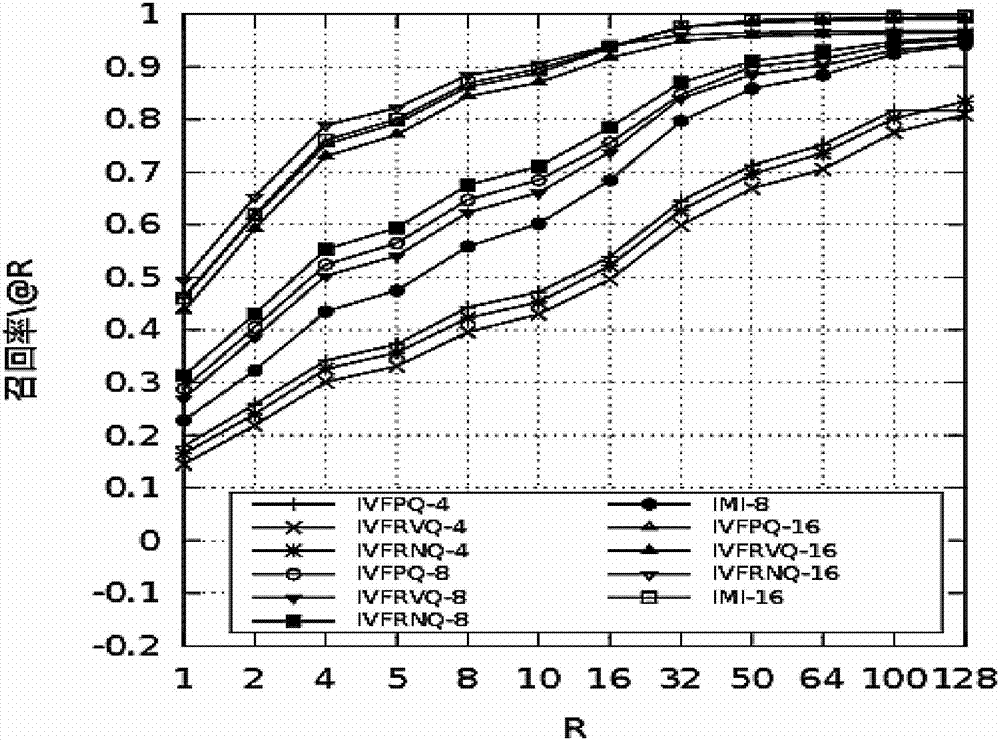
图2为mxq在sift1m数据集上与ivfpq,ivfrvq,imi的对比。
图3为mxq在gist1m数据集上与ivfpq,ivfrvq,imi的对比。
具体实施方式
1)混合向量量化的编码方法
给定一个向量v∈rd,对其前i阶的余向量(第一阶为向量本身)进行余向量量化,后面j阶的每阶余向量对其方向向量(归一化后的向量)和能量分别编码。假设i=2,j=2,则其编码形式如下:
在公式(1)中,
在编码中,设总的编码阶数为n,即n=i+j。则其中i由具体的问题确定。若待检索的数据集很大,则i的值大。因为前面i阶将用作生成倒排索引结构的索引,i值越大所能生成的索引值越多,可以索引的数据量也越大,目的是把数据集尽量打散,保证每次最近邻查询都只访问少量的候选向量。
2)基于低阶余向量量化编码的倒排索引结构
(1)设采用四阶编码,即n=4,经过1所述步骤,输入向量q将编码为c1c2c3h0c4h1。其中c1c2为余向量量化后的编码。这两个编码将合并作为倒排表的索引键值,即i=c1c2。而余下的编码将存放在倒排表该索引键值所对应的链表中。
(2)链表的每一项存放了候选向量的标记和余下的高阶编码。例如n=4情形下链表中每个候选项为<id,c3h0c4h1>。
3)基于层级剪枝的在线搜索策略
(1)给定查询点q,搜索过程首先计算查询点q到每一个倒排索引键值的距离。这时需要把键值i拆分为c1和c2。c1和c2分别对应第一阶码本中的向量
在公式(2)的计算中,为了加快计算速度,可以先算q到
(2)步骤(1)之后,查询计算q到候选链表中每一个候选项的距离。计算的公式如下,注意到公式(2)的计算结果可以加入到公式(3)的计算中以加快计算速度。
(3)步骤(2)之后,查询将获得q到经过混合编码的候选向量的距离,查询对距离排序,然后输出。
图1为本发明所提出的方法混合向量量化在低2阶rvq编码作倒排索引键值,高2阶方向和能量分别编码的图示。
mxq在sift1m数据集上与ivfpq,ivfrvq,imi的对比参见图2,mxq在gist1m数据集上与ivfpq,ivfrvq,imi的对比参见图3,在mxq中,每一个数据的最低的2阶用rvq编码作为索引键值,高阶余向量的能量和方向分开编码。测试采用了国际通用的sift1m和gist1m数据集。检索评价标准采用检索结果的召回率。具体定义为,各个数据的最近邻在返回结果中排的位置的平均值。
实验过程中,ivfrvq和mxq作为倒排键值的第一阶码本大小设置为8192,第二阶码本大小设置为256;ivfpq只有一阶码本作为索引键值,该码本的大小设置为8192;imi的两个码本的大小都设置为4096。ivfpq,ivfrvq和mxq减去倒排键值的余向量的码本数目分别选取了4,8,16;而imi分别选取了8,16。
从图2可以看到,mxq在大部分配置情况下召回率都是最高,特别是在gist1m数据集上,优于其他所有方法。ivfrvq与mxq的编码相似,但是mxq的结果优于ivfrvq,说明将余向量的方向和能量分开编码比rvq更有效。
ivfpq对应的方法为h.jegou等人提出的方法(productquantizationfornearestneighborsearch,in:ieeetransactionsonpatternanalysisandmachineintelligence,2011,33(1):117-128.)
ivfrvq对应的方法为y.chen等人提出的方法(approximatenearestneighborsearchbyresidualvectorquantization,in:sensors,vol.10,pp.11259-11273,2010.)
imi对应的方法为a.babenko等人提出的方法(theinvertedmulti-index,in:computervisionandpatternrecognition(cvpr),2012ieee,2012:3069-3076.)
本发明公开一种基于混合向量量化的最近邻检索方法。该类方法与现有向量量化方法不同的是,它对低阶余向量(一阶为原向量)采用传统余向量量化方式,而对高阶余向量,将它的方向向量和能量分别量化。一方面,向量量化后的低阶码将用来生成倒排索引结构的索引键值;另一方面,对每一高阶余向量进行分解。把一个向量分解为方向向量和能量。对方向向量和能量分别量化。与其他已有的量化方法相比,该方法训练码本以及量化过程都比目前的方法简单,同时取得较好的编码准确率。
- 还没有人留言评论。精彩留言会获得点赞!