基于维度区分的团队进步算法改进方案的制作方法
本发明基于维度区分的团队进步算法改进方案,属于启发式优化算法技术领域,可用于飞行器、电磁场、热场、声场、应力场等问题的工程仿真分析中。
背景技术:
智能优化算法作为一类求解最优化问题的高效优化算法,其原理简单,鲁棒性强,成为科学研究和工程领域解决多极值优化问题的有效工具,受到广大科研工作者的青睐。目前经典高效的智能优化算法有模拟生物在自然环境中的遗传和进化过程的遗传算法、模仿鸟群或鱼群觅食规律的粒子群算法、模仿个体间竞争合作关系的差分进化算法等。这些算法都属于单群体的仿生优化算法,属于在全局范围内寻优的随机初始化种群的群智能搜索算法,因此都有相应的缺点,如单群体优化方法易早熟收敛,不能兼顾全局寻优和收敛速度之间的矛盾等。
为解决该问题,近期提出了团队进步算法,该算法是一种兼顾全局搜索和局部搜索,同时又兼顾收敛速度的双群体智能优化算法,参数设置简单,全局寻优成功率高,计算量小,稳定性好等优点。团队进步算法基于团队分工、合作,首先随机初始化团队成员,按评价值大小把该团队成员分成精英组和普通组两组成员,精英组确保收敛速度,普通组确保全局收敛,然后在学习、探索和成员更新规则的机制下,整个团队快速进步,以尽可能少的计算量产生全局最优评价值的成员的过程。而且现阶段也出现了很多对原始tpa算法的改进,比如将原始算法中的学习步长改为高斯分布,并且探索步长也改为高斯分布。尽管该改进tpa算法已经比原始tpa算法以及其他几个经典算法计算时间缩短了不少,但是计算时间仍然具备可缩短的空间,因此需要对该算法进一步改进来提高处理效率和计算时间。为此,本发明在该改进算法的基础上提出将工程问题分为高低维度分别讨论,并制定出针对这两种维度的最佳改进团队进步算法。
技术实现要素:
:
技术问题:为解决现阶段团队进步算法计算量仍较大的问题,本发明提出按照实际工程中问题的难易程度,将其分为低维度和高维度两大类,在现阶段先进tpa算法的前提下,按照维度将学习步长根据维度制定合理的分布机制,并且对探索步长的高斯分布系数进行深度探索研究,从而得出针对所有工程问题的更加完善的团队进步算法,避免不必要的资源浪费,提高计算效率。解决上述问题的具体技术方案如下:
步骤一:确定属于低维或者高维问题:
参数相对较少的问题定义为低维问题,参数较多的问题定义为高维问题。本发明中将参数低于10个的工程问题都归为低维问题,参数大于10个或者大于20个的工程问题归为高维问题。
步骤二:确定基本模型并分组精英组和普通组:
多变量无约束最小化问题可表示为:
式中,x为成员,f(x)为成员x的评价值,min{f(x)}为取f(x)的最小值,xi为x的第i个能力因素,n个确定的能力因素能够确定一个成员x,ai和bi分别表示xi的上下边界。现以使评价值最小为优化目标。首先,利用随机方法产生n+m个初始成员,并计算所有成员的评价值,由评价值较高的前n个成员构成精英组,剩余的m个成员构成普通组。
步骤三:从精英组或者普通组中生成新生成员:
新生成员从精英组或者普通组中择一生成,新生成员的每一个能力因素都是从当前所有精英组成员能力因素的对应位置随机继承,从普通组中生成与之方法类似。新生成员记做xr,用公式(2)表示:
其中,xr的第i个变量xri是继承的精英组的第r个成员的第i个变量的值。与之类似,将式(2)中的下标e全部换成p即可得到普通组生成的新生成员。
步骤四:判断新生成员参与何种行为机制,根据不同维度进行相应的学习或者探索行为:
新生成员要成为候选成员必须在继承能力因素的前提下进行一次能力因素的学习或探索机制行为:
进行学习行为则需要有学习的参考目标才可以向更优值靠拢。参考目标分别产生于两组,分别设置为精英组样板ee和普通组样板ep,取所在组成员的能力因素的平均值为样板的能力因素,如下式:
新生成员的学习或者探索行为由学习概率l来决定,经验计算得,学习概率l一般取为0.2~0.5。r为区间(0,1)上的均匀分布随机数,若学习概率l大于随机数r则进行一次学习行为,若小于则进行一次探索行为。进一步的,所述步骤五又分为两个部分:
步骤五-1:确定学习样板并进行学习行为:
学习的目的就是让新生成员定向搜索,从而增强算法自身的局部搜索能力,使之快速收敛。学习样板分为精英组学习样板和普通组学习样板,各自按照学习样板进行学习。原始tpa采用算术平均生成学习样板,而现阶段先进tpa算法中学习样板采用的是几何平均。几何学习样板,即利用最大、最小方式确定各组能力因素的外接超立方体或长方体,并用该超立方体或长方体的几何中心作为学习样板。几何平均算法可以克服算术平均算法易受到计算值影响的弊端,几何平均值更加稳定且更具代表性,故本发明沿用之。公式(3-1)和(3-2)显示了精英组几何样板ee和普通组几何样板ep的计算公式:
其中,n为成员能力因素的个数,xemax和xemin分别为精英组外接超长方体的边界值点。xpmax和xpmin分别为普通组的外接超长方体的边界值点。
在获得学习样板之后,便可进行学习行为。原始tpa的学习步长采用均匀随机分布产生,这容易导致学习的定向性和集中度的不足,为解决这一问题,本发明按照低维度和高维度分别进行设计:
(1)针对低维度,本发明沿用现阶段先进tpa中的高斯分布来产生学习步长,具体如下:
如果新生成员是由精英组xr产生,则应向普通组学习样板ep的反方向学习,首先将普通组样板映射新生成员的镜像位置,均值μe即为镜像,方差σe为收缩向量k以及新生成员与镜像差的乘积,公式如(4-1):
其中,r1通过均匀随机分布产生,区间取[0,1),收缩向量k取经验值0.01。
相应的,如果新生成员xr由普通组产生,则应向精英组样板学习ee,均值μp即为精英组样板,方差σp为收缩向量以及新生成员与精英组样板之间的差做乘积,公式如(4-2):
在采用高斯分布生成学习步长时,要进行越界检查,如果发生越界,则取对应的上下界即可。
(2)针对高维度问题,对学习步长进行重新分配,本发明中采用beta分布来代替高斯分布。学习步长r的公式如下:
其中,u为区间[0,1)的均匀随机数,n是当前的迭代次数,n是算法设定的最大迭代次数,α为指数参数。由公式(6)可知,r随着n的增加而增大,使得样板对新生成员的引导作用越来越明显。
步骤五-2:进行探索行为:
原始tpa算法中的探索步长采用的是beta分布,这种方式的弊端就是无法再边界区域进行探索,缩小了求解区域,是不合理的。为解决上述问题,现阶段先进tpa算法则采用高斯分布来代替beta分布,公式如下:
其中,μ为均值,σ2为方差,n是当前的迭代次数,n是算法设定的最大迭代次数,α为指数参数。由于高斯函数的最佳逼近由二项式展开的系数决定的,曲线的形状很大程度上由系数k决定,所以本发明对收缩向量k进行深入探索,经过大量的数据采集和测试后,得出规律,在此取最优值0.001。由高斯分布产生的随机数能够覆盖整个搜索区域,并且具有随着迭代次数的增加渐趋集中于出发点的特征,使得该算法在初期可以进行大范围的全局搜索,而后期则在新生成员附近进行越来越精细的搜索,这样既保证了全局寻优的能力,又保证了快速收敛的能力,大大改善算法性能。
步骤六:成员更新:
由新生成员经过学习或者探索行为之后成为候选成员,若候选成员xc的评价值优于精英末位的评价值,则xc进入精英组,精英末位直接丢弃出整个组群。若候选成员劣于精英组末位但优于全队末位,则分两种情况进行讨论:当xc是经探索得到,则xc进入普通组,丢弃全队末位成员;当xc经学习得到,则直接丢弃出群。
有益效果
一是按照问题的难易程度分为低维度和高维度问题,并且针对两种维度的问题分别制定相应的算法方案,避免了将所有问题混为一谈,进而达到因地制宜、量体裁衣的效果,最大程度的利用较少的资源和成本解决相应问题;二是根据维度不同,分别设计出合理的学习步长的分配机制,从而能够减少计算时间;三是对高斯分布的系数做了深入探索,找出最合适的系数,较大程度的增加了运算效率。
附图说明
图1为团队进步算法流程图。
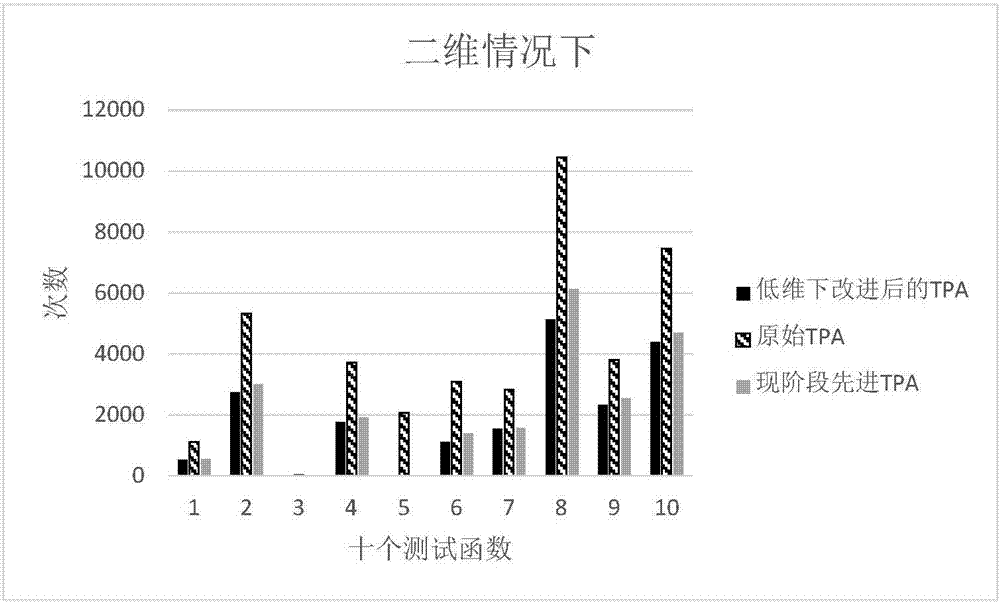
图2、图3为低维度(二维和三维情况下)本发明改进算法、原始算法以及现阶段先进算法针对10个测试函数的测试结果对比图(其中,f5只在二维情况下可讨论)。
图4、图5为高维度(十维和二十维情况下)本发明改进算法、原始算法以及现阶段先进算法针对10个测试函数的测试结果对比图(其中,f5只在二维情况下可讨论)。
具体实施方式
以下结合附图对本发明的优选实施例进行详细说明。
为了解决现阶段团队进步算法计算量仍较大的问题,本发明提出按照实际工程中问题的难易程度,将其分为低维度和高维度两大类,在现阶段先进tpa算法的前提下,按照维度将学习步长根据维度制定合理的分布机制,并且对探索步长的高斯分布系数进行深度探索研究,从而得出针对所有工程问题的更加完善的团队进步算法,从而避免不必要的资源浪费,提高计算效率。包括如下步骤:
步骤一:确定属于低维或者高维问题:
参数相对较少的问题定义为低维问题,参数较多的问题定义为高维问题。本发明中将参数低于10个的工程问题都归为低维问题,参数大于10个或者大于20个的工程问题归为高维问题。
步骤二:确定基本模型并分组精英组和普通组:
多变量无约束最小化问题可表示为:
式中,x为成员,f(x)为成员x的评价值,min{f(x)}为取f(x)的最小值,xi为x的第i个能力因素,n个确定的能力因素能够确定一个成员x,ai和bi分别表示xi的上下边界。现以使评价值最小为优化目标。首先,利用随机方法产生n+m个初始成员,并计算所有成员的评价值,由评价值较高的前n个成员构成精英组,剩余的m个成员构成普通组。
步骤三:从精英组或者普通组中生成新生成员:
新生成员从精英组或者普通组中择一生成,新生成员的每一个能力因素都是从当前所有精英组成员能力因素的对应位置随机继承,从普通组中生成与之方法类似。新生成员记做xr,用公式(2)表示:
其中,xr的第i个变量xri是继承的精英组的第r个成员的第i个变量的值。与之类似,将式(2)中的下标e全部换成p即可得到普通组生成的新生成员。
步骤四:判断新生成员参与何种行为机制,根据不同维度进行相应的学习或者探索行为:
新生成员要成为候选成员必须在继承能力因素的前提下进行一次能力因素的学习或探索机制行为:
进行学习行为则需要有学习的参考目标才可以向更优值靠拢。参考目标分别产生于两组,分别设置为精英组样板ee和普通组样板ep,取所在组成员的能力因素的平均值为样板的能力因素,如下式:
新生成员的学习或者探索行为由学习概率l来决定,经验计算得,学习概率l一般取为0.2~0.5。r为区间(0,1)上的均匀分布随机数,若学习概率l大于随机数r则进行一次学习行为,若小于则进行一次探索行为。进一步的,所述步骤五又分为两个部分:
步骤五-1:确定学习样板并进行学习行为:
学习的目的就是让新生成员定向搜索,从而增强算法自身的局部搜索能力,使之快速收敛。学习样板分为精英组学习样板和普通组学习样板,各自按照学习样板进行学习。原始tpa采用算术平均生成学习样板,而现阶段先进tpa算法中学习样板采用的是几何平均。几何学习样板,即利用最大、最小方式确定各组能力因素的外接超立方体或长方体,并用该超立方体或长方体的几何中心作为学习样板。几何平均算法可以克服算术平均算法易受到计算值影响的弊端,几何平均值更加稳定且更具代表性,故本发明沿用之。公式(3-1)和(3-2)显示了精英组几何样板ee和普通组几何样板ep的计算公式:
其中,n为成员能力因素的个数,xemax和xemin分别为精英组外接超长方体的边界值点。xpmax和xpmin分别为普通组的外接超长方体的边界值点。
在获得学习样板之后,便可进行学习行为。原始tpa的学习步长采用均匀随机分布产生,这容易导致学习的定向性和集中度的不足,为解决这一问题,本发明按照低维度和高维度分别进行设计:
(1)针对低维度,本发明沿用现阶段先进tpa中的高斯分布来产生学习步长,具体如下:
如果新生成员是由精英组xr产生,则应向普通组学习样板ep的反方向学习,首先将普通组样板映射新生成员的镜像位置,均值μe即为镜像,方差σe为收缩向量k以及新生成员与镜像差的乘积,公式如(4-1):
其中,r1通过均匀随机分布产生,区间取[0,1),收缩向量k取经验值0.01。
相应的,如果新生成员xr由普通组产生,则应向精英组样板学习ee,均值μp即为精英组样板,方差σp为收缩向量以及新生成员与精英组样板之间的差做乘积,公式如(4-2):
在采用高斯分布生成学习步长时,要进行越界检查,如果发生越界,则取对应的上下界即可。在此算法基础上,对10个测试函数进行测试,得出如图2~3所示的比较图,可以看出,本发明改进的算法结果较现阶段先进算法有较好的改善,较明显的是二维下:f6改善19.67%、f8改善16.16%;三维下:f3改善30.77%,f10改善12.45%,其余改善基本都在5%~10%之间。
(2)针对高维度问题,对学习步长进行重新分配,本发明中采用beta分布来代替高斯分布。学习步长r的公式如下:
其中,u为区间[0,1)的均匀随机数,n是当前的迭代次数,n是算法设定的最大迭代次数,α为指数参数。由公式(6)可知,r随着n的增加而增大,使得样板对新生成员的引导作用越来越明显。在此算法基础上,对10个测试函数进行测试,得出如图4~5所示的比较图,可以看出,本发明改进的算法结果较现阶段先进算法有较好的改善,较明显的是十维下:f6改善29.60%、f10改善51.01%,;二十维下f1改善94.13%、f10改善72.27%,其余基本在7%~13%之间。
步骤五-2:进行探索行为:
原始tpa算法中的探索步长采用的是beta分布,这种方式无法再边界区域进行探索,缩小了求解区域,是不合理的。为解决上述问题,本发明借鉴现阶段先进tpa算法,采用高斯分布来代替beta分布,公式如下:
其中,μ为均值,σ2为方差,n是当前的迭代次数,n是算法设定的最大迭代次数,α为指数参数。由于高斯函数的最佳逼近由二项式展开的系数决定的,曲线的形状很大程度上由系数k决定,所以本发明对收缩向量k进行深入探索,经过大量的数据采集和测试后,得出规律,在此取最优值0.001。由高斯分布产生的随机数能够覆盖整个搜索区域,并且具有随着迭代次数的增加渐趋集中于出发点的特征,使得该算法在初期可以进行大范围的全局搜索,而后期则在新生成员附近进行越来越精细的搜索,这样既保证了全局寻优的能力,又保证了快速收敛的能力,大大改善算法性能。
步骤六:成员更新:
由新生成员经过学习或者探索行为之后成为候选成员,若候选成员xc的评价值优于精英末位的评价值,则xc进入精英组,精英末位直接丢弃出整个组群。若候选成员劣于精英组末位但优于全队末位,则分两种情况进行讨论:当xc是经探索得到,则xc进入普通组,丢弃全队末位成员;当xc经学习得到,则直接丢弃出群。
在上述步骤五中,原始算法以及现阶段先进算法将工程中的所有问题都混为一谈,是针对低维度以及高维度所有问题的解决方案,这就造成了在解决简单问题时的资源浪费以及时间浪费,为解决上述问题,本发明将日常工程问题按照复杂程度分为低维度和高维度,并且针对两种维度的问题分别制定相应的算法方案,进而达到因地制宜、量体裁衣的效果,最大程度的利用较少的资源和成本解决相应问题。
在上述步骤五中,现阶段先进的算法将学习步长和探索步长均按照系数为0.01的高斯分布得到。这种做法优于原始tpa中学习步长采用均匀随机分布、探索步长采用beta分布的算法,既解决了学习行为中定向性和集中度不足的问题,也对边界区域进行了探索。但是该算法仍然需要较大的计算量和较长的计算时间,而且对于低维度问题的运算效果不佳。
为解决上述问题,本发明首先对高低维中探索行为的高斯分布系数k进行深入探索研究,找到最合适的系数从而提高算法的运算效率。由于高斯函数的最佳逼近由二项式展开的系数决定,所以本发明对该系数k做了详尽的参数遍历,找出其规律,从而得出最优参数为k=0.001。然后针对10个低维的函数进行测试,测试结果比现阶段较先进的tpa的结果更加优秀,具体可见附图2~3。
之后针对高维度问题,对学习步长进行重新分配,本发明中采用beta分布来代替高斯分布。学习步长r的公式如下:
其中,u为区间[0,1)的均匀随机数,n是当前的迭代次数,n是算法设定的最大迭代次数,α为指数参数。由公式(6)可知,r随着n的增加而增大,使得样板对新生成员的引导作用越来越明显。针对10个10维和20维的函数进行测试,测试结果比现阶段较先进的tpa的结果更优,具体可见附图4~5。
由此可得结论,当遇到低维度问题时,学习步长采用系数为0.01的高斯分布,探索步长采用系数为0.001的高斯分布;当遇到低维度问题时,学习步长采用beta分布,探索步长采用系数为0.001的高斯分布。
- 还没有人留言评论。精彩留言会获得点赞!