一种网络资源搜索训练系统的制作方法
本发明主要涉及网络数据检索与抓取系统。
背景技术:
随着互联网的快速发展,互联网上的数据资源呈几何数字上升,对于特定信息的目标资源的检索,效率越来越低,而且检索得到的资源与目标资源的相近度无法确定,另外不同数据平台下的检索结果出现不一致情况,检索机制的不同造成实际结果与真实结果的差值无法缩小,进而造成搜索引擎的效率降低,成本高,而且无法匹配实时在变动的互联网海量资源。
技术实现要素:
针对上述现有存在的问题和不足,本发明提供了一种网络资源搜索训练系统,网络资源中的目标资源检索效率更高,且具有自我更新特征关键信息权重值,从而提高了搜索精准度和效率。
发明内容:为解决上述技术问题,本发明所采用的技术手段为:一种网络资源搜索训练系统,包括信息采集模块,信息内容解析与分类模块,检索抓取模块和训练模块,其中:
所述信息采集模块,收集并提取用户待检索资源关键信息,并根据关键信息生成关联信息,并将该关联信息与用户进行交互并记录修改信息,同时对关键信息和关联信息进行权重排序和确定,确定后的特定检索信息发送至检索抓取模块;
所述检索抓取模块,从网络上抓取包含关键信息或关联系信息的网页信息,并将数据发送至信息内容解析模块;
所述信息内容解析模块,首先对信息内容进行分类,然后计算抓取后的网页信息中关键信息的相近度和出现频率,并根据相近度和出现频率计算各关键信息的在关键信息类别集合中的贡献比值;
所述训练模块,提取信息内容解析模块计算的各关键信息的权重,并按照权重大小的顺序选取部分关键信息作为特征关键信息,并对其进行归一化处理;继续使用特征关键信息作为检索依据进行再次检索得到目标资源;
所述信息内容解析模块中关键信息的权重通过公式(1)计算得到:
w(t,i)为特征关键信息t在关键信息类别i中的权值,tf(t,i)表示特征关键信息在关键信息类别i中的频次,cs为所有关键信息类别集合,t为信息类别的序号,i为当前信息类别下的关键信息的序号,f(i)表示特征关键信息t在该关键信息类别i中出现的频次,f(cs)表示特征关键信息t在所有标记块中出现的总次数,n表示信息类别的总个数。
本发明对关键信息进行集合化和分类处理,并对各关键信息的近似度和在各自集合下的贡献比值进行优化模拟,得到关键信息的权重值从而以此为依据进行归一化处理进行训练生成得到特征关键信息,并作为训练后的搜索依据进行检索得到精确度更高的目标资源。本发明考虑了关键信息相近度和权重比值,经过数学公式进行模拟得到更精准的目标资源。
附图说明
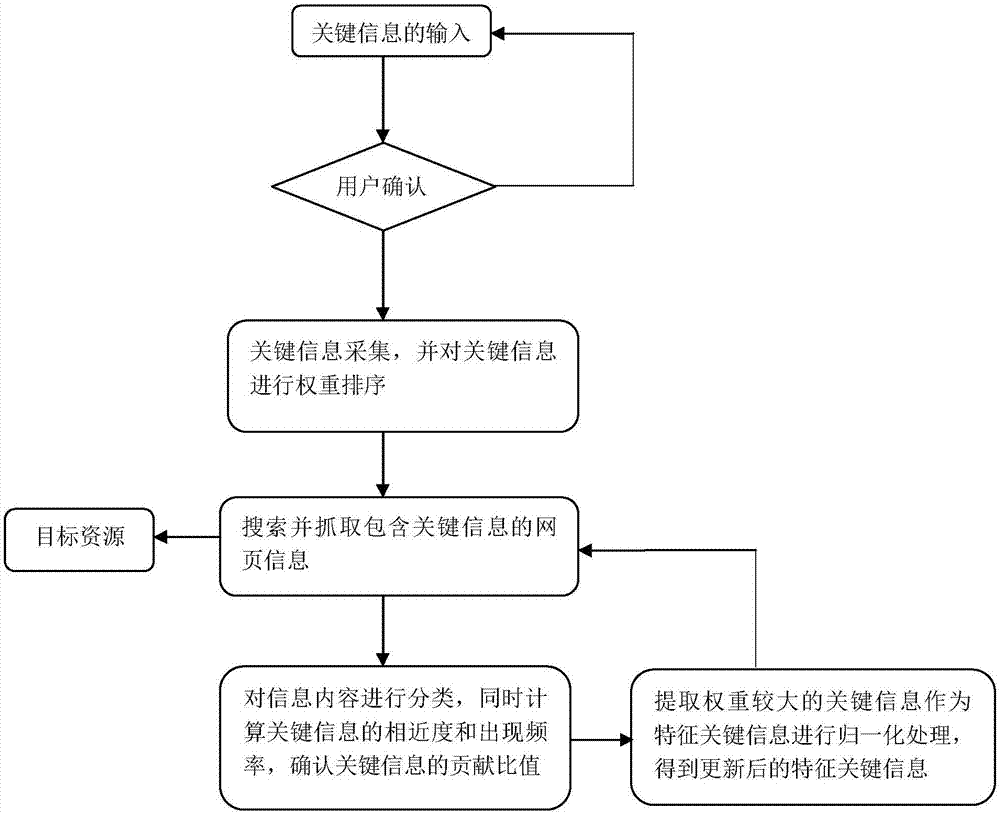
图1为本发明所述系统的逻辑流程图。
具体实施方式
下面结合附图和具体实施例对本发明内容作进一步说明。
如图1所示,本发明的网络资源搜索训练系统,主要包括信息采集模块,信息内容解析与分类模块,检索抓取模块和训练模块。对于互联网上海量的数据资源内容,本系统对资源内容的类型进行了划分,可以以文字、视频、音频、图像、字段字符,或以内容生成格式为依据进行划分。使用者在确定需要搜索的目标关键信息后,本系统提取该关键信息内容并与系统的资源内容的比对形成一定规则下的关键信息集合,同时对相关联的信息进行修正并与使用者进行交互确认,确定后的关键信息,由本系统抓取模块在网络上进行网页信息的检索和抓取,抓取得到的数据送至信息内容解析模块进行处理。
信息内容解析模块,首先对信息内容进行分类,然后计算抓取后的网页信息中关键信息的相近度和出现频率,并根据相近度和出现频率计算各关键信息的在关键信息类别集合中的贡献比值;
所述训练模块,提取信息内容解析模块计算的各关键信息的权重,并按照权重大小的顺序选取部分关键信息作为特征关键信息,并对其进行归一化处理;继续使用特征关键信息作为检索依据进行再次检索得到目标资源;
所述信息内容解析模块中关键信息的权重通过公式(1)计算得到:
w(t,i)为特征关键信息t在关键信息类别i中的权值,tf(t,i)表示特征关键信息在关键信息类别i中的频次,cs为所有关键信息类别集合,t为信息类别的序号,i为当前信息类别下的关键信息的序号,f(i)表示特征关键信息t在该关键信息类别i中出现的频次,f(cs)表示特征关键信息t在所有标记块中出现的总次数,n表示信息类别的总个数。
技术特征:
技术总结
本发明公开了种网络资源搜索训练系统,本系统对关键信息进行集合化和分类处理,并对各关键信息的近似度和在各自集合下的贡献比值进行优化模拟,得到关键信息的权重值从而以此为依据进行归一化处理进行训练生成得到特征关键信息,并作为训练后的搜索依据进行检索得到精确度更高的目标资源。本发明考虑了关键信息相近度和权重比值,经过数学公式进行模拟得到更精准的目标资源。
技术研发人员:李文华
受保护的技术使用者:江苏德胜智业信息技术有限公司
技术研发日:2017.05.22
技术公布日:2017.10.10
- 还没有人留言评论。精彩留言会获得点赞!