一种基于四维索引的大规模图的可达查询方法和系统与流程
本发明属于大数据处理技术领域,更具体地,涉及一种基于四维索引的大规模图的可达查询方法和系统。
背景技术:
随着大数据时代的到来,图的规模也越来越大。图查询作为一种基础性操作被应用于很多领域,比如社交网络、运输网络、交通定位、基因的生物学功能分析和数据挖掘等。图的可达性代表了图上一个结点到另一个结点的能力,即是否存在一条以u为起始结点,以v为终止结点的路径。
图可达查询有两种极端的解决方法。第一种是基于预计算和存储图的完整传递闭包的方法,也就是预先记录图中任意两个结点之间的可达性,该方法最早的研究工作可以追溯到1989年。这种方法的优点是查询时间很快,时间复杂度是o(1),但是该方法的缺点也很明显,它需要o(|v|*|e|)的索引构建时间和o(|v|2)的索引存储空间。第二种方法是采用深度优先遍历或者广度优先遍历的方法来回答结点对的可达性,该方法虽然不需要构建索引,但是查询时间的复杂度却高达o(|v|+|e|)。因此,在大规模图中,上述两种方法都是不可行的。
目前,图可达查询的关键挑战是在保证高效查询时间的同时保证索引构建时间比较快和索引大小也比较有竞争力。到目前为止,很多研究者都研究了这个问题,但是随着图规模的增加,现有的方法都或多或少存在着问题,它们要么是索引构建时间太长,要么是索引太大,要么是查询时间太慢。因此,如何在索引构建时间、索引大小和查询时间三者之间找到一个平衡点是一个亟待解决的问题。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种基于四维索引的大规模图的可达查询方法和系统,其目的在于通过对给定图进行划分,为每个结点构建一个四维索引来回答结点对的可达性,由此确保高效的查询时间的同时保证索引构建时间和索引大小与现有方法相比都比较有竞争力。
为实现上述目的,按照本发明的一个方面,提供了一种基于四维索引的大规模图的可达查询方法,所述方法包括以下步骤:
(1)通过递归遍历从目标图中划分出互不相交的不共享子图和连接这些不共享子图的跨子图边;结点的不共享子图的编号为其所处不共享子图所含根结点的编号,其层次索引按递归次数增加;
(2)由不共享子图中所有结点的拓扑排序值求取该结点的间隔域,所述间隔域包括初始间隔域和目标间隔域;
(3)记录所有不共享子图中由于非树边的存在导致的不能使用间隔域判断结点对可达性的异常情况;记录所有不共享子图中由于跨子图边的存在导致的不能直接判断结点对可达性的异常情况;
(4)计算每个结点的向上等级索引
(5)通过结点对的层次索引、所在不共享子图编号、间隔域和等级索引的对比关系确定结点对的可达性。
进一步地,所述步骤(1)包括以下子步骤:
(11)找出目标图g=(v,e)中所有单根子图m(r)=(vm(r),em(r)),单根子图即目标图中一个根结点能到达的所有结点和该根结点的集合,其中,v表示目标图的结点;e表示目标图的边;r表示该单根子图的根结点;vm(r)表示单根子图的结点;em(r)表示单根子图的边;
(12)在目标图中找出所有位于两个或两个以上单根子图中的结点vu,由所有结点vu和结点间相连的边eu构成共享子图u=(vu,eu);
(13)构建不共享子图为n(r)=(vn(r),en(r)),其中,
(14)将共享子图u=(vu,eu)设为新的目标图g=(v,e),重复步骤(11)~(13),每次重复遍历得到的不共享子图的层次索引都累加1,直到找不到共享子图,最后得到一组有序的不共享子图n0,n1,…,nx和连接不共享子图的跨子图边k0,k1,…,ky,其中,x为不共享子图的个数;y为跨子图边个数。
进一步地,所述步骤(2)包括以下子步骤:
(21)依次求出每个不共享子图中结点的拓扑排序值,将拓扑排序值赋值给该结点的初始间隔域su,其中,u为结点;同时在拓扑排序的过程中,若边(u,v)是该不共享子图的边且边(u,v)未被访问,则称该边为非树边,v为u的非树边出点,u为v的非树边入点;
(22)若不共享子图中结点u为不共享子图的叶子结点,则其目标间隔域eu等于其初始间隔域su;否则eu等于其后续邻接点的e和su中的最大值;若结点u有后继邻接点v为结点u的非树边出点,则在计算eu时不考虑v的目标间隔域ev。
进一步地,所述步骤(3)包括以下子步骤:
(31)若不共享子图内结点u为非树边入点,则结点u的非树边集exception(u)初始化为其非树边出点;否则exception(u)初始化为空集;若结点v为结点u的后继邻接点,则exception(u)=exception(u)∪exception(v);若w∈exception(u),且满足su≤sw和eu≥ew,则将w从exception(u)中除去,其中,su和sw为结点u和w的初始间隔域;eu和ew为结点u和w的目标间隔域;
(32)若不共享子图内结点u为跨子图边入点,则结点u的跨子图边集cross(u)初始化为其跨子图边出点;否则cross(u)初始化为空集;若结点v和结点u属于同一不共享子图,且结点v为结点u的后继邻接点,则cross(u)=cross(u)∪cross(v);若x,y∈crossu(),且满足x,y属于同一不共享子图并且x可达y,则把y从cross(u)中除去。
进一步地,所述步骤(5)包括以下子步骤:
(51)对于结点对(u,v),判断
(52)判断若layeru>layerv则进入步骤(53);若layeru=layerv则进入步骤(54);若layeru<layerv则进入步骤(55);其中,layeru和layerv表示表示结点u和v的层次索引;
(53)结点u不可达结点v;
(54)判断:若rootu≠rootv,则结点u不可达结点v;若su>sv,则结点u不可达结点v;若eu≥ev,则结点u可达结点v;若w∈exception(u)且结点w可达结点v,则结点u可达结点v;否则结点u不可达结点v;其中,rootu和rootv表示结点u和v所在不共享子图的编号;eu和ev表示结点u和v的目标间隔域;su和sv表示结点u和v的初始间隔域;
(55)若w∈cross(u)且结点w可达结点v,则结点u可达结点v;否则结点u不可达结点v。
按照本发明的另一方面,提供了一种基于四维索引的大规模图的可达查询系统,所述系统包括:
不共享子图划分模块,用于通过递归遍历从目标图中划分出互不相交的不共享子图和连接这些不共享子图的跨子图边;结点的不共享子图的编号为其所处不共享子图所含根结点的编号,其层次索引按递归次数增加;
结点间隔域求取模块,用于由不共享子图中所有结点的拓扑排序值求取该结点的间隔域,所述间隔域包括初始间隔域和目标间隔域;
可达性异常记录模块,用于记录所有不共享子图中由于非树边的存在导致的不能使用间隔域判断结点对可达性的异常情况;记录所有不共享子图中由于跨子图边的存在导致的不能直接判断结点对可达性的异常情况;
等级索引计算模块,用于计算每个结点的向上等级索引
结点对可达性判断模块,用于通过结点对的层次索引、所在不共享子图编号、间隔域和等级索引的对比关系确定结点对的可达性。
进一步地,所述不共享子图划分模块包括:
单根子图划分单元,用于找出目标图g=(v,e)中所有单根子图m(r)=(vm(r),em(r)),单根子图即目标图中一个根结点能到达的所有结点和该根结点的集合,其中,v表示目标图的结点;e表示目标图的边;r表示该单根子图的根结点;vm(r)表示单根子图的结点;em(r)表示单根子图的边;
共享子图划分单元,用于在目标图中找出所有位于两个或两个以上单根子图中的结点vu,由所有结点vu和结点间相连的边eu构成共享子图u=(vu,eu);
不共享子图划分单元,用于构建不共享子图为n(r)=(vn(r),en(r)),其中,
递归遍历单元,用于将共享子图u=(vu,eu)设为新的目标图g=(v,e),重复单根子图划分单元、共享子图划分单元和不共享子图划分单元,每次重复遍历得到的不共享子图的层次索引都累加1,直到找不到共享子图,最后得到一组有序的不共享子图n0,n1,…,nx和连接不共享子图的跨子图边k0,k1,…,ky,其中,x为不共享子图的个数;y为跨子图边个数。
进一步地,所述结点间隔域求取模块包括:
初始间隔域单元,用于依次求出每个不共享子图中结点的拓扑排序值,将拓扑排序值赋值给该结点的初始间隔域su,其中,u为结点;同时在拓扑排序的过程中,若边(u,v)是该不共享子图的边且边(u,v)未被访问,则称该边为非树边,v为u的非树边出点,u为v的非树边入点;
目标间隔域单元,用于判断若不共享子图中结点u为不共享子图的叶子结点,则其目标间隔域eu等于其初始间隔域su;否则eu等于其后续邻接点的e和su中的最大值;若结点u有后继邻接点v为结点u的非树边出点,则在计算eu时不考虑v的目标间隔域ev。
进一步地,所述可达性异常记录模块包括:
非树边异常单元,用于判断若不共享子图内结点u为非树边入点,则结点u的非树边集exception(u)初始化为其非树边出点;否则exception(u)初始化为空集;若结点v为结点u的后继邻接点,则exception(u)=exception(u)∪exception(v);若w∈exception(u),且满足su≤sw和eu≥ew,则将w从exception(u)中除去,其中,su和sw为结点u和w的初始间隔域;eu和ew为结点u和w的目标间隔域;
跨子图边异常单元,用于判断若不共享子图内结点u为跨子图边入点,则结点u的跨子图边集cross(u)初始化为其跨子图边出点;否则cross(u)初始化为空集;若结点v和结点u属于同一不共享子图,且结点v为结点u的后继邻接点,则cross(u)=cross(u)∪cross(v);若x,y∈crossu(),且满足x,y属于同一不共享子图并且x可达y,则把y从cross(u)中除去。
进一步地,所述结点对可达性判断模块包括:
第一判断单元,用于对于结点对(u,v),判断
第二判断单元,用于判断若layeru>layerv则进入第三判断单元;若layeru=layerv则进入第四判断单元;若layeru<layerv则进入第五判断单元;其中,layeru和layerv表示表示结点u和v的层次索引;
第三判断单元,用于确定结点u不可达结点v;
第四判断单元,用于判断若rootu≠rootv,则结点u不可达结点v;若su>sv,则结点u不可达结点v;若eu≥ev,则结点u可达结点v;若w∈exception(u)且结点w可达结点v,则结点u可达结点v;否则结点u不可达结点v;其中,rootu和rootv表示结点u和v所在不共享子图的编号;eu和ev表示结点u和v的目标间隔域;su和sv表示结点u和v的初始间隔域;
第五判断单元,用于判断若w∈cross(u)且结点w可达结点v,则结点u可达结点v;否则结点u不可达结点v。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有以下技术特征及有益效果:
(1)由于采用了图划分方法,把图划分为若干个互不相交的不共享子图,利用不共享子图间的关系达到加速可达查询的效果;
(2)由于在不共享子图中采用了间隔域的方法来判断结点间的可达性,达到了加速可达查询的效果;
(3)由于图划分和间隔域的有效性,可以快速的构建规模合理的索引,更好地完成了查询时间、索引构建时间和索引大小三者之间的平衡。
附图说明
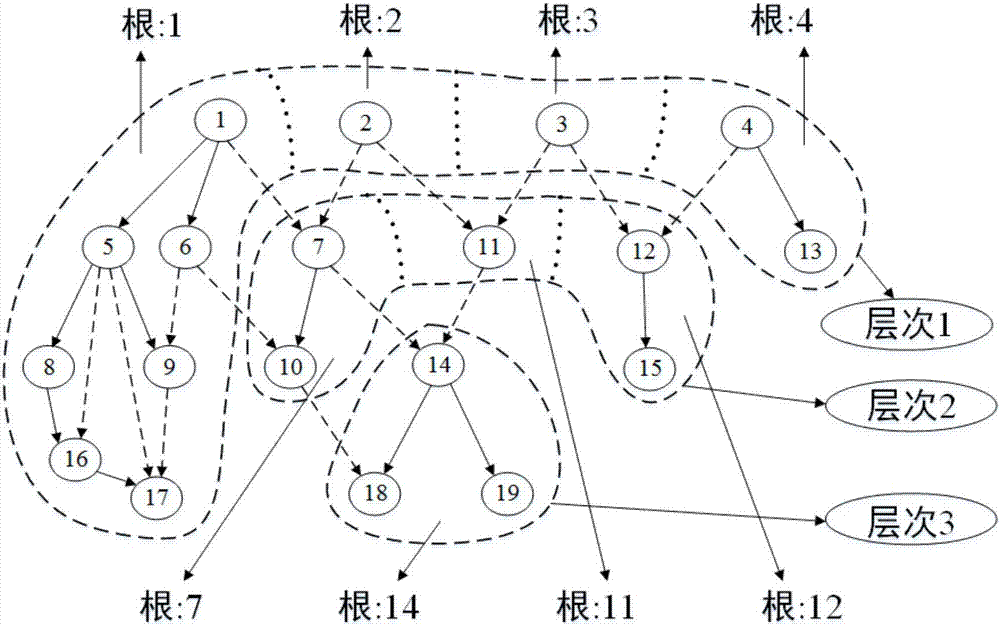
图1是本发明的目标图最后划分示意图;
图2为本发明单根子图示意图;
图3为本发明共享子图和不共享子图示意图;
图4为本发明不共享子图n(1)中结点的间隔域值和初始非树边集;
图5为本发明不共享子图n(1)中结点的最终非树边集。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
如图1所示,本发明通过对给定图进行划分,然后根据每个结点所处位置为其构建索引来回答结点对的可达性。具体包括以下步骤:
(1)通过递归遍历从目标图中划分出互不相交的不共享子图和连接这些不共享子图的跨子图边;结点的不共享子图的编号为其所处不共享子图所在根结点编号,其层次索引按递归次数增加;
(11)给定图g=(v,e),其中,v表示结点集;e表示边集,则从g中入度为0的结点(根r)开始遍历图,找出该结点可以到达的所有结点vm(r);结点vm(r)和结点间相连的边em(r)构成的子图称为单根子图m(r)=(vm(r),em(r)),其中,r表示该单根子图的根结点;
如图2所示,图g有4个根结点:1、2、3和4,则g有四个单根子图:m(1)、m(2)、m(3)和m(4);
(12)找出所有位于两个或两个以上单根子图的结点;这些结点vu和连接结点的边eu构成的子图称为共享子图u=(vu,eu),如图3所示;
(13)则不共享子图为n(r)=(vn(r),en(r)),其中,
第一次遍历结束得到的所有不共享子图中结点的层次索引为1,结点的不共享子图编号为该不共享子图的根结点id值;
(14)把共享子图u设为图g,再次从其根结点开始遍历,使接下来每次遍历结束得到的不共享子图的层次索引加1,重复(11)~(13)直到找不到共享子图,则图划分结束,得到一组有序的不共享子图n0,n1,…,nx,其中,x为不共享子图的个数,和连接不共享子图的跨子图边k0,k1,…,ky,其中,y为跨子图边个数;若边(u,v)为图g的跨子图边,则称v为u的跨子图边出点,u为v的跨子图边入点;
例如,在图1中,我们首先把图g划分为4个不共享子图n(1)、n(2)、n(3)和n(4),和相应的共享子图u;
然后,我们把u设为g,继续进行划分,得到3个不共享子图n(7),n(11)和n(12)以及相应的共享子图u';
接着,我们继续划分u',由于u'只有一个单根子图n(14),划分后该单根子图就是不共享子图,而没有共享子图产生;因此,划分结束;
最终,图g被划分为8个不共享子图和10条跨子图边,其中,不共享子图的顺序为:n(1)、n(2)、n(3)、n(4)、n(7)、n(11)、n(12)和n(14);跨子图边为:(1,7)、(2,7)、(2,11)、(3,11)、(3,12)、(4,12)、(6,10)、(7,14)、(11,14)和(10,18)。
(2)由不共享子图中所有结点的拓扑排序值求取该结点的间隔域,所述间隔域包括初始间隔域和目标间隔域;
这样处于同一不共享子图的结点对间的可达性可以用结点的间隔域的包含关系来判断;
(21)根据步骤1中得到的一组有序不共享子图n0,n1,…,nx,依次求出每个不共享子图中结点的拓扑排序值s,则s为该结点的初始间隔域;另外,在求不共享子图的拓扑排序过程中,若边(u,v)是该不共享子图的边且边(u,v)未被访问,则称该边为非树边,v为u的非树边出点,u为v的非树边入点;
(22)结点u的目标间隔域值e的计算方法如下:若u为不共享子图的叶子结点,则其目标间隔域值e为其初始间隔域值s;若u不是叶子结点,则其目标间隔域值e为其后继邻接点的e值和该点s值中的最大值,但是,若有后继邻接点v为u的非树边出点,则在计算u的e值时不考虑v的e值;这样做是为了保证当su≤sv并且eu≥ev时,结点u可以到达结点v;
例如,如图1所示,图g的不共享子图的顺序为n(1)、n(2)、n(3)、n(4)、n(7)、n(11)、n(12)和n(14),然后顺序遍历这些不共享子图,求出不共享子图中结点的拓扑排序,并赋值给结点的初始间隔域值;比如,首先,我们处理不共享子图n(1),如图4所示;n(1)中结点的拓扑顺序为1,6,5,9,8,16和17,也即s1=1,s6=2,s5=3,s9=4,s8=5,s16=6和s17=7;此外,n(1)中有4条非树边(5,16)、(5,17)、(6,9)和(9,17),这些非树边在图4中以虚线边表示;因此,对于叶子结点17来说,e17=s17=7;对于结点16,e16=max{s16,e17}=7;对于结点8,e8=max{s8,e16}=7;至于结点9,由于它仅有一条非树出边,所以e9=s9=4;同理,对于结点5,e5=max{s5,e8,e9}=7;对于结点6,e6=s6=2;对于结点1,e1=max{s1,e5,e6}=7;接下来,我们处理不共享子图n(2),由于n(2)中仅有一个结点,则e2=s2=8;随后,剩下的不共享子图中的结点均可以按照上述算法求出间隔域。
(3)记录所有不共享子图中由于非树边的存在导致的不能使用间隔域判断结点对可达性的异常情况;记录所有不共享子图中由于跨子图边的存在导致的不能直接判断结点对可达性的异常情况;
(31)不共享子图内结点对可达性判断的异常情况是由于非树边的存在导致间隔域不能完全判断不共享子图内结点对的可达性情况,该异常处理步骤包括:
初始化不共享子图内结点u的非树边集exception(u);若u为非树边入点,则exception(u)初始化为其非树边出点;否则exception(u)初始化为空集;
例如,如图4所示,n(1)中有4条非树边(5,16)、(5,17)、(6,9)和(9,17);那么,结点5、结点6和结点9的初始非树边集分别为exception(5)={16,17},exception(6)={9}和exception(9)={17};图4给出了不共享子图n(1)中每个结点的间隔域([s,e])和初始非树边集;
u为某一不共享子图中结点,若v为u的后继邻接点,则exception(u)=exception(u)∪exception(v);
若w∈exception(u),满足su≤sw和eu≥ew,则把w从exception(u)中除去;这样可以既保证了可达性判断的准确性,又减小了索引大小;
图5标示的是n(1)中结点的最终的非树边集;
(32)不共享子图间结点对可达性判断的异常情况是由于跨子图边的存在导致结点对的可达性无法用上述索引来直接判断;该异常处理步骤包括:
初始化不共享子图中结点u的跨子图边集cross(u);若u为跨子图边入点,则cross(u)初始化为其跨子图边出点;否则cross(u)初始化为空集;
u为某一不共享子图中结点,若v和u属于同一不共享子图,且v为u的后继邻接点,则cross(u)=cross(u)∪cross(v);
若x,y∈cross(u),且满足x,y属于同一不共享子图并且x可以到达y,则可以把y从cross(u)中除去;这样同样可以既保证可达性判断的准确性,又减小索引大小;
例如,这里以不共享子图n(1)为例,计算结点的跨子图边集,而其它不共享子图中结点的跨子图边集的计算方法与此类似;如图1所示,结点5、结点8、结点9、结点16和结点17都没有任何后继邻接点可以到达不在不共享子图n(1)中的点,所以,它们的跨子图边集为空集;对于结点6,它有一个跨子图边出点,所以,cross(6)={10};对于结点1,首先,它有一个跨子图边出点7;其次,它的后继邻接点6的跨子图边异常集中有一个结点10,但是由于结点7和结点10位于同一不共享子图且结点7可以到达结点10,所以,结点1的跨子图边异常集为cross(1)={7}。
(4)为每个结点创建向上等级索引
(5)通过结点对的层次索引、所在不共享子图编号、间隔域和等级索引的对比关系确定结点对的可达性;
(51)对于结点对(u,v),判断
(52)判断若layeru>layerv则进入步骤(53);若layeru=layerv则进入步骤(54);若layeru<layerv则进入步骤(55);其中,layeru和layerv表示表示结点u和v的层次索引;
(53)结点u不可达结点v;
(54)判断若rootu≠rootv,则结点u不可达结点v;若su>sv,则结点u不可达结点v;若eu≥ev,则结点u可达结点v;若w∈exception(u)且结点w可达结点v,则结点u可达结点v;否则结点u不可达结点v;其中,rootu和rootv表示结点u和v所在不共享子图的编号;eu和ev表示结点u和v的目标间隔域;su和sv表示结点u和v的初始间隔域;
(55)若w∈cross(u)且结点w可达结点v,则结点u可达结点v;否则结点u不可达结点v。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!