一种网络信息语义倾向分析方法及系统与流程
本发明属计算机技术领域,具体涉及一种一种网络信息语义倾向分析方法及系统。
背景技术:
在通常情况下,公众或投资者需要通过不同的信息来源获取企业的经营信息和与企业经营相关的政策和行业信息,例如工商局、税务局、法院、各级行政单位和行业协会,再进行信息的汇总、处理和分析。公众投资者根据分析结论结合自身个性化的风险偏好做出投资决策。
在金融和证券业务领域内,有信息的推送方案可供用户使用,特别是在某些证券交易软件内,软件会将一些与该企业相关的信息经过分类和标注之后推送给用户查看。而该推送方案的信息来源是根据该企业拥有的固有信息发布渠道,比如公司网站、证券信息批露网站等。该技术方案信息来源单一,获取的信息面窄,并且没有运用技术的方法对信息的影响作出判断和评估,仍需要用户以自身经验和倾向对信息内容进行判断和评估。
技术实现要素:
针对以上问题的不足,本发明提供了一种一种网络信息语义倾向分析方法及系统,本发明以互联网海量信息作为信息来源,快速计算和判断企业信息的正面负面倾向,可让公众用户快速、全面的获取企业的经营和舆论信息,也可以为行业、机构、企业用户提供信息检索技术服务。
一种网络信息语义倾向分析方法,包括:
获取企业名称;
使用网络爬虫在互联网上搜索与该企业相关的信息,并将这些信息以文本的形式存储在数据库中;
使用分词器将上述文本分解为符合逻辑的词语序列,并将词语序列存储在分词库中;
从分词库中取出所述词语序列,输入语料分析器,得到带词性标注的词语序列;
将所述带词性标注的词语序列输入情感倾向分类器,得到文本的情感倾向值,进而得到文本的情感倾向。
优选地,所述语料分析器将词组序列里的每个词语与词语感情色彩索引库进行对比,得到情感词性标注的词语序列。
优选地,所述词语感情色彩索引库存储有大量词语、对每个词语的汉语词性标注和对每个词汇的情感词性标注。
优选地,所述情感词性包括四类:褒义、贬义、中性和否定。
优选地,所述词性标注的标注方式为:词语/汉语词性后缀/情感词性后缀,其中,所述情感词性后缀定义包括为:
褒义词性后缀:1;
贬义词性后缀:0;
中性词性后缀:na;
否定词性后缀:-1。
优选地,所述文本的情感倾向包括三类:积极倾向、消极倾向和中性。
优选地,所述情感倾向分类器的算法步骤如下:
s51:根据词组序列中的汉语词性标注,分句提取每一句的情感词性后缀,得到每一句的情感词性后缀序列,
sm={wm1,wm2……wmn},
其中,sm为文本中第m句的所有词的情感词性后缀序列,
wmn为文本中第m句第n个词的情感词性后缀;
s52:采用逻辑决策法计算每一句的情感倾向值,定义情感倾向值:积极倾向为1,消极倾向为0,中性为na,
其中,sem为文本中第m句的情感倾向值,
wmn为文本中第m句第n个词的情感词性后缀;
n为第m句的词总数;
s53:根据每一句的情感倾向值,得到文本中所有句子的情感倾向值序列,
t={se1,se2……sem},
其中,t为文本中所有句子的情感倾向值序列;
s54:采用逻辑决策法计算文本的情感倾向值,得到该文本信息的情感倾向,
其中,te为文本的情感倾向值,
sem为文本中第m句的情感倾向值;
m为文本的句子总数。
优选地,所述逻辑决策法包括以下计算方法:
第一种:pi=1,pi+1=1,则pipi+1=1;
第二种:pi=0,pi+1=0,则pipi+1=0;
第三种:pi=1,pi+1=0或pi=0,pi+1=1,则pipi+1=na;
第四种:pi=-1,pi+1=1,则pipi+1=0;
第五种:pi=-1,pi+1=0,则pipi+1=1;
其中pi为一句中第i个词语的情感词性后缀;
pi+1为一句中第i+1个词语的情感词性后缀;
第六种:rj=1,rj+1=1,则rjrj+1=1;
第七种:rj=0,rj+1=0,则rjrj+1=0;
第八种:rj=1,rj+1=0或rj=0,rj+1=1,则rjrj+1=na;
其中rj为第j句的情感倾向值;
rj+1为第j+1句的情感倾向值;
所述第四种和第五种为特殊逻辑算法,句子中出现否定词时,否定词的情感词性后缀与后一词的情感词性后缀优先计算,并得到与后一词的情感词性后缀相反的结论。
优选地,还包括获取用户的反馈信息,根据用户的反馈,情感倾向分类器进行自动学习,对自身规则进行更新或增加。
一种网络信息语义倾向分析系统,包括:
输入模块,用于获取企业名称;
信息收集模块,用于使用网络爬虫在互联网上搜索与该企业相关的信息,并将这些信息以文本的形式存储在数据库中;
文本分词模块,用于使用分词器将上述文本分解为符合逻辑的自然词组序列,并将词组序列存储在分词库中;
语义分析模块,用于从分词库中取出词组序列,输入语料分析器,得到带汉语词性标注和情感词性标注的词组序列;
倾向分类模块,用于将带词性标注的词组序列输入情感倾向分类器,对文本进行情感倾向判断,得到文本的情感倾向;
自动学习模块,用于获取用户的反馈信息,根据用户的反馈,情感倾向分类器进行自动学习,对自身规则进行更新或增加。
由上述方案可知,本发明以互联网海量公开信息为作为信息来源,以各个电子政务网站、公司网站、新闻门户网站、行业机构网站等渠道方式,收集全面的政策、新闻、公告等与企业相关的全面信息,解决信息来源单一、信息面窄的问题;通过对这些信息的分析,快速计算和判断企业信息的正面负面倾向,可让公众用户快速、全面的获取企业的经营和舆论信息,也可以为行业、机构、企业用户提供信息检索技术服务。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍。在所有附图中,类似的元件或部分一般由类似的附图标记标识。附图中,各元件或部分并不一定按照实际的比例绘制。
图1为本实施例中网络信息语义倾向分析方法的流程图;
图2为本实施例中情感分类器的算法流程图;
图3为本实施例中网络信息语义倾向分析系统的原理框图。
具体实施方式
下面将结合附图对本发明的实施例进行详细的描述。以下实施例仅用于更加清楚地说明本发明的产品,因此只是作为示例,而不能以此来限制本发明的保护范围。
实施例:
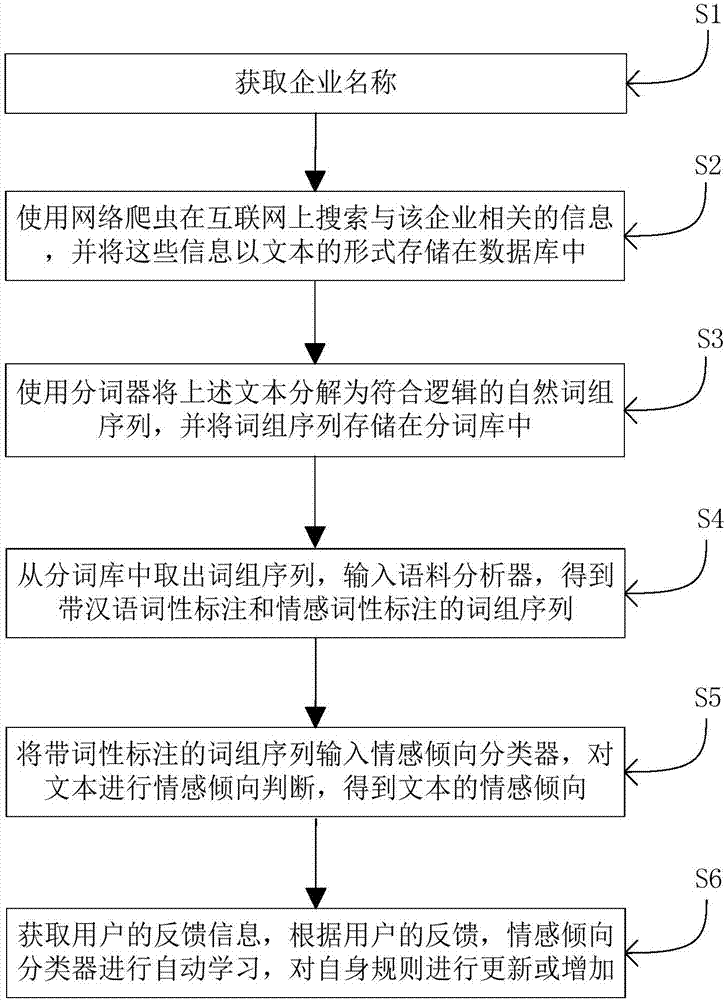
本发明实施例提供的一种网络信息语义倾向分析方法,如图1所示,包括:
s1,获取企业名称;
s2,使用网络爬虫在互联网上搜索与该企业相关的信息,并将这些信息以文本的形式存储在数据库中;
s3,使用分词器将上述文本分解为符合逻辑的词语序列,并将词语序列存储在分词库中;
s4,从分词库中取出所述词语序列,输入语料分析器,得到带词性标注的词语序列,所述情感词性包括四类:褒义、贬义、中性和否定;
s5,将所述带词性标注的词语序列输入情感倾向分类器,得到文本的情感倾向值,进而得到文本的情感倾向,所述文本的情感倾向包括三类:积极倾向、消极倾向和中性;
s6,获取用户的反馈信息,根据用户的反馈,情感倾向分类器进行自动学习,对自身规则进行更新或增加。
所述s6包括以下具体步骤:
s61,倾向分类器将计算结果输出给用户,结果分为三种情况(1,-1或者na),分析系统展示的结论为(积极,消极或中性)三种倾向;
s62,用户判断倾向分类器计算结果是否正确,在分析系统的人机交互界面上可以选择(正确或者错误)的选项,用户反馈器将【正确】定义为【1】,将【错误】定义为【-1】,结果定义值直接送入算法进化器运算;
s63,算法进化器接收用户反馈结果,将[倾向分类器计算结果]与用户反馈结果进行对比,将大量用户反馈的异常结果进行算法分析,更新或增加算法规则,通常是多感情色彩词语,或者词性变化引起的句子感情倾向变化;
s64,算法进化器将更新后算法规则送入倾向分类器,倾向分类器对自身规则进行更新或者增加,算法进化完成。
所述网络爬虫是一种按照一定的规则,自动地抓取互联网信息的程序或者脚本。
所述分词器是将一段文本分解为按逻辑顺序分解了若干个词的一种算法。
本实施例中通过有关企业的互联网信息可判断出企业的经营和舆论信息的积极倾向或消极倾向或无倾向。本实施例中情感倾向分类器的自动学习,使本算法得到的结果无限接近于人类对自然语言的理解和判断结论。
所述语料分析器将词组序列里的每个词语与词语感情色彩索引库进行对比,得到情感词性标注的词语序列。所述词语感情色彩索引库存储有大量词语、对每个词语的汉语词性标注和对每个词汇的情感词性标注。
所述词性标注的标注方式为:词语/汉语词性后缀/情感词性后缀,其中,所述情感词性后缀定义包括为:
褒义词性后缀:1;
贬义词性后缀:0;
中性词性后缀:na;
否定词性后缀:-1。
所述情感倾向分类器的算法步骤如下:
s51:根据词组序列中的汉语词性标注,分句提取每一句的情感词性后缀,得到每一句的情感词性后缀序列,
sm={wm1,wm2……wmn},
其中,sm为文本中第m句的所有词的情感词性后缀序列,
wmn为文本中第m句第n个词的情感词性后缀;
s52:采用逻辑决策法计算每一句的情感倾向值,定义情感倾向值:积极倾向为1,消极倾向为0,中性为na,
其中,sem为文本中第m句的情感倾向值,
wmn为文本中第m句第n个词的情感词性后缀;
n为第m句的词总数;
s53:根据每一句的情感倾向值,得到文本中所有句子的情感倾向值序列,
t={se1,se2……sem},
其中,t为文本中所有句子的情感倾向值序列;
s54:采用逻辑决策法计算文本的情感倾向值,得到该文本信息的情感倾向,
其中,te为文本的情感倾向值,
sem为文本中第m句的情感倾向值;
m为文本的句子总数。
优选地,所述逻辑决策法包括以下计算方法:
第一种:pi=1,pi+1=1,则pipi+1=1;
第二种:pi=0,pi+1=0,则pipi+1=0;
第三种:pi=1,pi+1=0或pi=0,pi+1=1,则pipi+1=na;
第四种:pi=-1,pi+1=1,则pipi+1=0;
第五种:pi=-1,pi+1=0,则pipi+1=1;
其中pi为一句中第i个词语的情感词性后缀;
pi+1为一句中第i+1个词语的情感词性后缀;
第六种:rj=1,rj+1=1,则rjrj+1=1;
第七种:rj=0,rj+1=0,则rjrj+1=0;
第八种:rj=1,rj+1=0或rj=0,rj+1=1,则rjrj+1=na;
其中rj为第j句的情感倾向值;
rj+1为第j+1句的情感倾向值;
所述第四种和第五种为特殊逻辑算法,句子中出现否定词时,否定词的情感词性后缀与后一词的情感词性后缀优先计算,并得到与后一词的情感词性后缀相反的结论。
一种网络信息语义倾向分析系统,包括:
输入模块,用于获取企业名称;
信息收集模块,用于使用网络爬虫在互联网上搜索与该企业相关的信息,并将这些信息以文本的形式存储在数据库中;
文本分词模块,用于使用分词器将上述文本分解为符合逻辑的自然词组序列,并将词组序列存储在分词库中;
语义分析模块,用于从分词库中取出词组序列,输入语料分析器,得到带汉语词性标注和情感词性标注的词组序列;
倾向分类模块,用于将带词性标注的词组序列输入情感倾向分类器,对文本进行情感倾向判断,得到文本的情感倾向;
自动学习模块,用于获取用户的反馈信息,根据用户的反馈,情感倾向分类器进行自动学习,对自身规则进行更新或增加。
举例方案一
步骤1,系统在互联网上获取到一则新闻如下:
“乐视网是今年以来a股市场上的焦点公司,先是乐视控股的“生态化反”遭遇种种质疑,后有拖欠供应商货款而被诉诸法庭,还面临着股价破位下跌后可能触发股票质押平仓的危机。”
步骤2,对文本进行汉语词性标注,结果如下:
乐视网/ns是/vl今年/nt以来/nta/ws股市/n场上/nl的/u焦点/n公司/n,/w先是/c乐视控股/n的/u“/w生态化反/n”/w遭遇/n种/v种/v质疑/v,/w后/nd有/v拖欠/v供应商/n货款/n而/c被/p诉诸/v法庭/n,/w还/d面临/v着/u股价/n破/a位/q下跌/v后/nd可能/vu触发/v股票/n质押/v平仓/v的/u危机/n。/w
步骤3:对上述文本进行情感词性标注,结果如下:
乐视网/ns/na是/vl/1今年/nt/na以来/nt/naa/ws/na股市/n/na场上/nl/na的/u/na焦点/n/1公司/n/na,/w/na先是/c/na乐视控股/n/na的/u/na“/w生态化反/n/na”/w/na遭遇/n/0种种/v/na质疑/v/0,/w/na后/nd/na有/v/1拖欠/v/0供应商/n/na货款/n/na而/c/na被/p/na诉诸/v/na法庭/n/na,/w/na还/d/na面临/v/0着/u/na股价/n/na破/a/0位/q/na下跌/v/0后/nd/na可能/vu/na触发/v/na股票/n/na质押/v/0平仓/v/0的/u/na危机/n/0。/w/na
步骤4:计算每一句的情感倾向值:
句子1:乐视网/ns/na是/vl/1今年/nt/na以来/nt/naa/ws/na股市/n/na场上/nl/na的/u/na焦点/n/1公司/n/na,/w/na
s1={na,1,na,na,na,na,na,na,1,na,na}
se1=1;计算结果为1,表示积极情感。
句子2:先是/c/na乐视控股/n/na的/u/na“/w/na生态化反/n/na”/w/na遭遇/n/0种种/v/na质疑/v/0,/w/na
s2={na,na,na,na,na,na,0,na,0,na}
se2=0;计算结果为0,表示消极情感。
句子3:后/nd/na有/v/1拖欠/v/0供应商/n/na货款/n/na而/c/na被/p/na诉诸/v/na法庭/n/na,
s3={na,1,0,na,na,na,na,na,na}
se3=0;计算结果为0,表示消极情感。
句子4:还/d/na面临/v/0着/u/na股价/n/na破/a/0位/q/na下跌/v/0后/nd/na可能/vu/na触发/v/na股票/n/na质押/v/0平仓/v/0的/u/na危机/n/0。/w/na
s4={na,0,na,na,0,na,0,na,na,na,na,0,o,na,0,na}
sem4=0;计算结果为0,表示消极情感。
步骤5:对整段文本进行赋值,以句子情感赋值序列:
t={se1,sem,se3,se4}={1,0,0,0}
te=0;计算结果为0,表示消极情感。
步骤6:分析系统根据整句计算结果为0(te=0),将整段新闻判定为消极倾向的新闻。
举例方案二(带否定句式)
例句:我不认为你不是一个好人。
步骤1,对文本进行词性标注:
我/r/na不/d/-1认为/v/na你/r/na不是/d/-1一个/r/na好人/n/1。/w/na
步骤2,获得词性后缀序列:
s={na,-1,na,na,-1,na,1,na}
步骤3,执行优先计算步骤:
优先计算w1={不是/d/-1一个/r/na好人/n/1}={-1,na,1}=0
优先计算w2={不/d/-1认为/v/na你/r/naw1}={-1,na,na,0}=1
步骤4,整句计算:
s={na,w2,na}=w2=1
结论:例句“我不认为你不是一个好人。”是一个积极情感倾向的句子。
本实施例以互联网海量公开信息为作为信息来源,以各个电子政务网站、公司网站、新闻门户网站、行业机构网站等渠道方式,收集全面的政策、新闻、公告等与企业相关的全面信息;在获得全量信息的基础之上,通过语义分析得到信息的情感倾向,或积极或消极或中性,积极为正面影响,消极则为负面影响。本实施例可让公众用户快速、全面的获取特定企业的经营和舆论信息,也可以为行业、机构、企业用户提供信息检索技术服务。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
- 还没有人留言评论。精彩留言会获得点赞!