一种基于改进ELM算法的毛管质量预报方法与流程
本发明属于回归技术领域的质量预报技术,具体涉及一种基于改进elm算法的毛管质量预报方法。
背景技术:
穿孔作为无缝钢管生产的第一道工序,对钢管的质量有着十分重要的影响;穿孔过程产生的质量问题在后续过程中不但得不到缓解,而且会使钢管产生更严重的质量问题;所以,建立利用采集的穿孔过程数据建立毛管质量预报模型对轧钢工艺有着很重要的指导意义;常见的预测方法主要是基于时间序列法、卡尔曼滤波法、神经网络、支持向量机(svm)等;时间序列方法预报的结果不稳定,其模型参数难以确定;神经网络收敛速度慢,已陷入局部最优等缺陷;卡尔曼滤波法的状态方程的建立需要对机理知识有一定的理解,对一般的建模者来说是一个挑战;支持向量机的预报结果虽然精度能达到要求,但是耗时长。
elm算法2006年由huangg.b.第一次提出,是在单隐含层神经网络(slfns)基础上的延伸。与slfns不同的是,其隐含层节点数、隐含层参数与训练数据无关,大大加快了elm的训练速度,且泛化能力较优良。elm算法随机生成隐含层参数,避免了梯度下降法调整参数,大大加快了运行速度;不会产生过拟合,避免陷入局部最优;理论证明elm算法具有训练误差越小,权重范数越小的性质,根据巴特利特理论知极限学习算法具有很好的泛化能力。对elm算法的研究和应用掀起了热潮,增量式极限学习机、误差最小极限学习机、l1/2正则化方法修剪极限学习机、op-elm等实现对elm算法的不断改进和发展,elm算法成功的应用到分类、回归、模式识别等领域;
通过查阅文献对比知道,elm算法学习速度、泛化能力和可扩展性方面均有优势;但是,当样本数据存在噪声干扰时,elm模型的预报结果不稳定。
技术实现要素:
针对现有技术中毛管质量预报方法在样本数据存在噪声干扰elm模型的预报结果不稳定等不足,本发明提出一种基于改进elm算法的毛管质量预报方法,以达到提高毛管预测准确性的目的。
为解决上述技术问题,本发明采用的技术方案是:
一种基于改进elm算法的毛管质量预报方法,包括以下步骤:
步骤1、采集毛管穿孔过程的多组历史现场数据,构建训练集;
步骤2、根据所采集的现场数据,确定集成elm网络的输入层、输出层和隐含层;
步骤3、结合多个常用激励函数,通过设置权重的方式,确定集成elm网络的激励函数;
步骤4、采用遗传算法对集成elm网络的激励函数中每个权值进行优化,获得最优激励函数;
步骤5、采用训练集对集成elm网络进行训练,完成集成elm网络的构建,具体如下:
步骤5-1、利用交叉检验的方法确定集成elm网络的子网络个数;
步骤5-2、对训练集中所有组数据进行训练,每组数据分别在每个子网络中进行训练,完成集成elm网络搭建;
步骤6、将实际生产中的数据输入至集成elm网络的每个子网络中,获得每个子网络的输出结果,进而获得集成elm网络的输出预报结果,即获得毛管质量的预报结果。
步骤1所述的现场数据,包括:上辊转速实际值、下辊转速实际值、上辊电流、下辊电流、上辊磁场、下辊磁场、上辊电机感应电动势、下辊电机感应电动势、止推小车的实际位置、上辊压下实际值、下辊压上实际值、上辊倾角实际值、下辊倾角实际值、右导盘位置实际值、左导盘位置实际值、推钢机位置、上辊转速实际值、下辊转速实际值、上辊入口侧温度、上辊出口侧温度、下辊入口侧温度、下辊出口侧温度、右导盘电流和左导盘电流和纵向壁厚。
步骤2所述的根据所采集的现场数据,确定集成elm网络的输入层、输出层和隐含层;具体为:将所采集的前24个数据作为集成elm网络的输入,将纵向壁厚作为集成elm网络输出,采用交叉检验的方法确定隐含层的个数。
步骤3所述的结合多个常用激励函数,通过设置权重的方式,确定集成elm网络的激励函数;具体公式如下:
激励函数具体公式如下:
g(x)=λ1·log(x)+λ2·hardlim(x)+λ3·satlin(x)(1)
其中,g(x)表示激励函数,λ1表示log(x)函数的权值,λ2表示hardlim(x)函数的权值,λ3表示satlin(x)函数的权值,0≤λi≤1,i=1,2,3。
步骤4所述的采用遗传算法对集成elm网络的激励函数中每个权值进行优化,获得最优激励函数;
步骤4-1、确定目标函数;
目标函数如下:
其中,f为目标函数,yi为采集的质量指标,
步骤4-2、确定待优化参数为激励函数中权重值;
步骤4-3、确定染色体的个数为变量个数;
步骤4-4、根据目标函数确定适应度函数;
步骤4-5、确定遗传算法的参数,包括:种群大小,迭代次数,染色体个数;
步骤4-6、运行遗传算法,求取最优权值。
本发明优点:
本发明提出一种基于改进elm算法的毛管质量预报方法,主要以改进elm算法为核心,建立毛管穿孔过程质量预报模型,为提高elm预报模型的鲁棒性及精度,进一步利用集成学习的elm模型算法搭建预报模型;主要利用取平均值、随机优化取均值、ga优化权值的方法建立集成的elm算法;通过比较发现,单个elm模型的预报效果远没有集成网络的效果准确;即集成的elm预报模型继承了elm模型的快速的性能和集成方法的鲁棒性,使得预报更加可靠准确;对于集成网络,相对于均值集成,选择后优化的效果很好,优化权值产生新的激励函数的预报效果更佳,能更准确的预报毛管的质量。
附图说明
图1为本发明基于改进elm算法的毛管质量预报方法流程图;
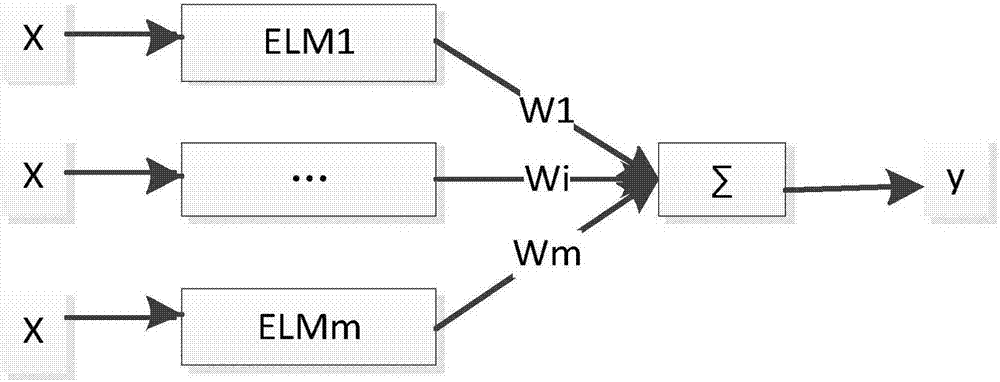
图2为本发明中毛管质量的集成elm预报模型示意图;
图3(a)为本发明中多个elm网络集成测试结果示意图;
图3(b)为多个elm网络集成测试误差示意图;
图4(a)为本发明中选择集成的elm网络集成测试结果示意图;
图4(b)为选择集成的elm网络集成测试结果示意图;
图5(a)为本发明中基于优化激活函数的穿孔过程集成elm网络的预报结果示意图
图5(b)为集成的elm网络预报误差示意图。
具体实施方式
下面结合附图对本发明一种实施例做进一步说明。
本发明实施例中,基于改进elm算法的毛管质量预报方法,方法流程图如图1所示,包括以下步骤:
步骤1、采集毛管穿孔过程的40组历史现场数据,构建训练集;
本发明实施例中,采用宝钢钢管分公司sww斜轧穿孔机的实际测量历史数据为样本,共40组数据作为训练数据,所述的现场数据,包括:上辊转速实际值、下辊转速实际值、上辊电流、下辊电流、上辊磁场、下辊磁场、上辊电机感应电动势、下辊电机感应电动势、止推小车的实际位置、上辊压下实际值、下辊压上实际值、上辊倾角实际值、下辊倾角实际值、右导盘位置实际值、左导盘位置实际值、推钢机位置、上辊转速实际值、下辊转速实际值、上辊入口侧温度、上辊出口侧温度、下辊入口侧温度、下辊出口侧温度、右导盘电流和左导盘电流和纵向壁厚;
步骤2、根据所采集的现场数据,确定集成elm网络的输入层、输出层和隐含层;
本发明实施例中,如图2所示,将所采集的前24个数据作为集成elm网络的输入,将纵向壁厚作为集成elm网络输出,采用交叉检验的方法确定隐含层的个数,具体如下:
步骤2-1、初始化神经网络结构:输入变量24,输出变量为1,采用交叉检验的方法确定隐含层为35个;确定神经网络结构为24-35-1的连接方式,即输入层神经元为24个,在网络开始训练的时刻,隐含层的神经元为35个,输出层神经元1个;
步骤2-2、对神经网络的权值进行随机赋值;
本发明实施例中,对神经网络的权值进行随机赋值,其值为0到1的随机数;
步骤3-3、定义误差函数为:
其中,m为训练集中数据的组数,
附图2中,x为elm网络的输入、wi为集成的m个elm网络每一个网络所占有的权重。
步骤3、结合多个常用激励函数,通过设置权重的方式,确定集成elm网络的激励函数;具体公式如下:
激励函数具体公式如下:
g(x)=λ1·log(x)+λ2·hardlim(x)+λ3·satlin(x)(1)
其中,g(x)表示激励函数,λ1表示log(x)函数的权值,λ2表示hardlim(x)函数的权值,λ3表示satlin(x)函数的权值,0≤λi≤1,i=1,2,3。
步骤4、采用遗传算法对集成elm网络的激励函数中每个权值进行优化,获得最优激励函数;
步骤4-1、确定目标函数;
目标函数如下:
其中,f为目标函数,yi为采集的质量指标,
步骤4-2、确定待优化参数为激励函数中权重值,选择编码类型为十进制;
步骤4-3、确定染色体的个数为变量个数,本发明实施例中,取值为3;
步骤4-4、根据目标函数确定适应度函数,本发明实施例中,适应度函数为fitness=-f;
步骤4-5、确定遗传算法的参数,包括:种群大小30,迭代100次,染色体为3;
步骤4-6、运行遗传算法,求取最优权值;
步骤5、采用训练集对集成elm网络进行训练,完成集成elm网络的构建,具体如下:
步骤5-1、利用交叉检验的方法确定集成elm网络的子网络个数,本发明实施例中,子网络个数为11;
步骤5-2、对训练集中40组数据进行训练,每组数据分别在每个子网络中进行训练,完成集成elm网络搭建;
步骤6、将实际生产中的数据输入至集成elm网络的每个子网络中,获得每个子网络的输出结果,进而获得集成elm网络的输出预报结果,即获得毛管质量的预报结果;
11个elm子网络的输出f1,f2,...f11,则集成的结果为:
最终,将
本发明实施例中,图3(a)~3(b)、图4(a)~4(b)、图5(a)~5(b)所示,其测试误差分别为0.0115,0.0078,0.0036,由数据分析知:对于集成网络,相对于均值集成,选择后优化的效果很好,优化权值产生新的激励函数的预报效果更佳,能更准确的预报毛管的质量。
- 还没有人留言评论。精彩留言会获得点赞!