基于局部敏感哈希的中文多关键词模糊排序密文搜索方法与流程
本发明涉及一种基于局部敏感哈希的中文多关键词模糊排序密文搜索方法
背景技术:
随着云计算技术的飞速发展,敏感数据越来越多的存储到云中,如电子邮件、个人健康记录、私人视频和照片、公司财务数据和政府文件等。云服务器提供了高质量的数据存储服务,将数据存储到云中,可以减少用户的数据存储和维护开销。但是数据拥有者和云服务器不在同一个信任域中会使外包数据处于危险之中,为了保护用户的隐私安全,将数据加密后再存储到云服务器是一种常见的解决方法。然而数据经过加密后不再具有原有的特性,当用户需要某些数据时,无法直接在密文中分辨出所需要的数据,在数据量很小的情况下,可以将所有的密文数据下载至本地,解密后在明文中搜索自己想要的数据。然而随着云端数据规模的急剧增长,这种浪费了大量时间开销与带宽功耗的做法显然已经不能满足用户的实际需求,因此,如何在大量密文中搜索到需要的文档成为了一个难题。
song等率先开始进行可搜索加密技术的研究,为解决密文检索的问题提供了思路。chang等为每篇文档创建索引,搜索时只需对加密的文档索引进行搜索,提高了搜索效率。wang等提出了单关键词排序的搜索方案,主要通过计算文档的tf-idf(词频-逆文档频率)值并经过保序加密后,对保序加密后的相关度分数进行排序,返回top-k篇文档给用户。cao等提出了多关键词排序可搜索加密方案,引入了向量空间模型和安全knn(securek-nearestneighbor)方法,通过矩阵对索引向量进行加密,计算索引向量和搜索向量的内积相似度来实现多关键词的排序搜索。但是这些方案只支持精确关键词搜索,用户输入的关键词必须与预定义的关键词完全匹配,才能返回搜索结果,这使得搜索方案具有较大局限性。因此,li等提出模糊关键词可搜索加密方案,用通配符的方法构造关键词模糊集合,用户在输入的搜索关键词出现拼写错误或格式不匹配的情况时,也能以较大的概率找到相关文档,极大改善了用户的搜索体验。li等提出了节省存储空间的模糊搜索方案,通过克(gram)来构造模糊集。wang等利用通配符和索引树,实现了高效的模糊搜索方案。chuah等为了提高搜索效率,实现了基于bedtree的多关键词模糊搜索方案。
但是以上的方案都是针对英文关键词实现模糊搜索,由于汉字是典型的非字母语言,词语的搭配灵活多样,因此以上的方案并不适用于中文关键词的模糊搜索。cao等提出了一种基于汉语拼音的明文模糊搜索方案,但是并不能实现密文上的搜索。chen等使用基于拼音的汉字串相似度衡量方案,实现了中文关键词的密文模糊搜索方案。
然而以上的模糊搜索方案都要预先构建模糊集,这些模糊集合将占用云服务器大量的存储空间。例如,在基于通配符的模糊集构造方法中,随着编辑距离的增加,模糊集合的大小会呈指数增长,因此构造模糊集合会耗费大量的计算和存储开销。yang等基于simhash的降维思想,将关键词做n-gram处理得到simhash指纹来实现模糊搜索。wang等和fu等将局部敏感哈希(locality-sensitivehashing,lsh)和安全knn方法(securek-nearestneighbor)结合,实现了一种新的多关键词模糊搜索方案。以上方案虽然无需构建关键词模糊集合,但是同样是针对英文的模糊搜索,并不能实现中文模糊搜索。
针对目前的中文密文关键词搜索方案中,要预先构造模糊集合,浪费大量的存储空间和时间开销等问题,本发明提出了一种新型的中文多关键词模糊排序搜索方法,可以实现高效的模糊关键词存储、支持文档动态更新,并返回精确的排序结果。
技术实现要素:
本发明的目的在于提供一种基于局部敏感哈希的中文多关键词模糊排序密文搜索方法,以克服现有技术中存在的缺陷。
为实现上述目的,本发明的技术方案是:一种基于局部敏感哈希的中文多关键词模糊排序密文搜索方法,提供一数据拥有单元、一授权用户单元以及一云服务器,按照如下步骤实现:
步骤s1:初始化,所述数据拥有单元从明文文档集合f=(f1,f2,…,fm)中抽取关键词,得到关键词集合w=(w1,w2,…,wn);
步骤s2:生成密钥,所述数据拥有单元输入一预设安全参数λ,产生一个向量s,s∈{0,1}λ,以及两个λ×λ维的可逆矩阵{m1,m2},密钥sk由三元组{s,m1,m2}组成,所述数据拥有单元生成一加密文档的密钥sk;
步骤s3:建立索引,所述数据拥有单元从一lsh哈希族中选取l个独立的lsh函数,为每篇文档fi构建一个λ比特的布隆过滤器,作为文档fi的索引ii;
步骤s4:索引加密,采用安全knn算法加密索引ii,得到加密后的索引
步骤s5:文档加密,所述数据拥有单元通过对称加密算法对所述文档集合f=(f1,f2,…,fm)进行加密,得到密文集合c=(c1,c2,…,cm),并上传给所述云服务器;
步骤s6:生成陷门,当授权用户搜索时,通过所述授权用户单元输入η个搜索关键词q=(q1,q2,…,qη),并为查询关键词集合q构建一个λ比特的布隆过滤器作为陷门tq;
步骤s7:陷门加密,采用安全knn算法对陷门tq加密,得到加密后的陷门
步骤s8:所述云服务器根据加密的索引encsk(ii)和加密的陷门encsk(tq),计算文档的相似度分数,将所有分数排序后,返回前k篇文档给用户;
步骤s9:所述授权用户单元通过使用所述数据拥有单元分发的密钥sk,对返回的top-k篇密文进行解密,获得所需的明文文档集。
相较于现有技术,本发明具有以下有益效果:
(1)新型中文模糊搜索方法:本发明首次提出了无需预先构造关键词模糊集合的新型中文多关键词模糊排序密文搜索方法。首先将中文关键词转换成对应的拼音串,接着设计了基于拼音串的中文关键词向量生成算法基于unigram的中文关键词向量生成算法1和算法2三种向量生成算法将关键词拼音串转化成对应的向量,然后为每篇文档构建一个布隆过滤器作为索引,利用lsh函数将文档中关键词对应的向量插入到布隆过滤器中。由于lsh函数的特性(原数据相似,经过lsh后的哈希值以很高的概率相等),授权用户在拼写错误的情况下也能匹配到正确的关键词,从而实现中文关键词的密文搜索。
(2)高效的模糊关键词存储:本发明设计了三种算法将每个关键词转化为对应的向量,即一个关键词对应一个向量,使得特定的向量在经过lsh函数哈希后能够匹配上拼写错误的查询词向量,从而实现模糊搜索。不同于以往的中文关键词模糊搜索方法,本发明无需构造庞大的关键词模糊集合,而只需要将一个关键词处理为一个对应的向量,再构造成索引存储在云服务器即可,因此极大减少了计算和存储开销。
(3)精确返回排序结果:本发明引入了域加权评分,对处于文档不同域中的关键词赋予不同的权重,将域加权评分、关键词向量间的欧氏距离和词频权重结合,实现了更加精确的三因子排序方法,满足用户的需求。
(4)支持文档动态更新:本发明引入了关键词的权重信息和域加权评分来提高排序结果的精确性,但发明采用了关键词的词频权重wft,f来代替传统方案大多采用的tf-idf相关度分数作为关键词的权重,使得关键词的权重信息不会随着文档的增加或减少发生变化,并且本发明采用一篇文档对应一个布隆过滤器作为加密索引。加入新文档(或删除旧文档)时,只需在计算当前文档中关键词的权重信息和域加权评分后构建新文档的索引并加密(或删除旧文档的加密索引,接着将文档加密后上传到云端(或删除加密的旧文档)即可,实现了文档的动态更新。
附图说明
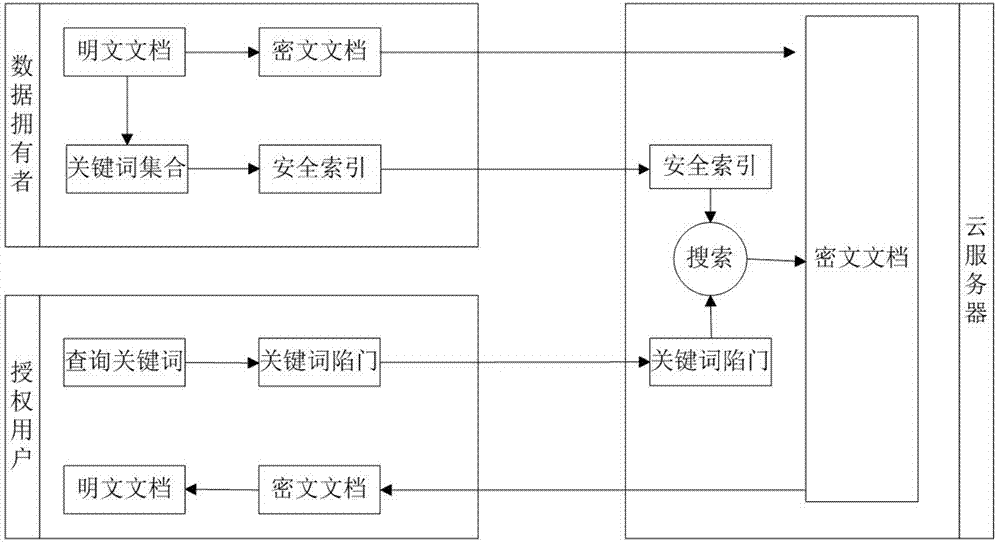
图1为本发明中基于局部敏感哈希的中文多关键词模糊排序密文搜索方法的系统框架图。
图2为本发明中基于局部敏感哈希的中文多关键词模糊排序密文搜索方法的流程图。
图3为本发明中基于局部敏感哈希的中文多关键词模糊排序密文搜索方法中基于拼音串的中文关键词向量生成算法的过程。
图4为本发明中基于局部敏感哈希的中文多关键词模糊排序密文搜索方法中基于unigram的中文关键词向量生成算法1。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
本发明提供一种基于局部敏感哈希的中文多关键词模糊排序密文搜索方法,图1为本发明的系统框架,包含三个实体:数据拥有者,授权用户和云服务器。本发明的索引和陷门加密采用安全knn算法加密,可以参考:wongwk,cheungwl,kaob,etal.secureknncomputationonencrypteddatabases//proceedingsoftheacmsigmodinternationalconferenceonmanagementofdata.newyork,usa,2009:139-152.
进一步的,如图2为本发明的基本流程,具体步骤如下:
(1)setup:数据拥有者从明文文档集合f=(f1,f2,…,fm)中抽取关键词,得到关键词集合w=(w1,w2,…,wn)。
(2)keygen(λ):数据拥有者输入一个安全参数λ,产生一个向量s,s∈{0,1}λ和两个λ×λ维的可逆矩阵{m1,m2},密钥sk由三元组{s,m1,m2}组成。接着,数据拥有者生成一个加密文档的密钥sk。
(3)buildindex(f,sk,l):从lsh哈希族中选取l个独立的lsh函数。为每篇文档fi构建一个λ比特的布隆过滤器作为fi的索引ii,具体操作如下:
31)采用基于拼音串的中文关键词向量生成算法或基于unigram的中文关键词向量生成算法1或基于unigram的中文关键词向量生成算法2,为文档fi中的每个关键词wj生成对应的关键词向量
32)利用hσ∈h将每一个关键词向量
(4)
最后,数据拥有者将加密的索引集合
(5)encfile(f,sk):数据拥有者使用对称加密算法对文档集合f=(f1,f2,…,fm)进行加密,得到密文集合c=(c1,c2,…,cm)并上传给云服务器。
(6)trapdoor(q,sk,l):当授权用户搜索时,首先输入η个搜索关键词q=(q1,q2,…,qη)。接着为查询关键词集合q构建一个λ比特的布隆过滤器作为陷门tq,具体操作如下:
61)采用基于拼音串的中文关键词向量生成算法或基于unigram的中文关键词向量生成算法1或基于unigram的中文关键词向量生成算法2为每个查询词qj生成对应的查询词向量
62)利用hσ∈h将每一个查询词向量
(7)enctrapdoor(tq,sk):采用安全knn算法陷门tq,得到加密后的陷门
(8)
(9)decrypt(c,sk):授权用户使用数据拥有者分发的密钥sk,对返回的top-k篇密文进行解密,获得所需的明文文档集。
进一步的,结合具体实施例说明基于拼音串的中文关键词向量生成算法。
在本实施例中,如果将中文关键词的拼音串看做英文字母串,那么插入、删除和替换掉一个或若干个字母后得到的很可能不是合法的拼音串。因此需要基于拼音的结构来定义编辑操作,具体定义如下:
1.只有同一个音节的声母或韵母发生变化。
2.同一个音节的声母和韵母同时发生变化。
3.音调发生变化。
由于lsh函数的输入是向量,因此应当用向量来表示中文关键词。此算法采用63比特的关键词向量
(a11)将中文关键词转化成对应的拼音字符串;
(a12)将每一个关键词按声母、韵母分割,分别用1、2、3、4表示音节的四个音调;
(a13)在音调后加入1、2、3、4来表示关键词的第1、2、3、4个字。
例如,关键词“实验”的音节的分割集为{sh,i,21,y,an,42},声母集为{sh,y},韵母集为{i,an},音调集为{21,42},其中“21”表示关键词“实验”中的第一个字“实”的音调为二声,“42”表示关键词“实验”中的第二个字“验”的音调为四声;
(a14)将关键词声母集、韵母集和音调集中的元素映射到关键词向量
进一步的,在本实施例中,当采用基于拼音串的中文关键词向量生成算法时,采用哈希族h={hσ:{0,1}63→{0,1}λ}。
进一步的,假设用户需要查询的关键词为“实验”,但是由于用户的拼写错误等原因,他实际输入的查询词为“实样”,即把an拼成ang(在中文关键词中前鼻音韵母和后鼻音韵母发音出错是常见的拼写错误)。根据上文的操作可得到查询词“实样”的音节分割集为{sh,i,21,y,ang,42},声母集为{sh,y},韵母集为{i,ang},音调集为{21,42}。经过映射可得到查询词向量
进一步的,结合具体实例说明基于unigram的中文关键词向量生成算法1。
在本实施例中,unigram即为一元语法,例如,英文单词“cloud”经过unigram处理后得到的集合为{c,l,o,u,d};中文单词“可搜索加密”经过unigram处理后得到的集合为{可,搜,索,加,密}。
此算法采用42比特的关键词向量
(a21)将中文关键词转化成对应的拼音字符串;
(a22)将每一个关键词的拼音串按unigram方法分割。分别用1、2、3、4表示音节的四个音调;
(a23)在音调后加入1、2、3、4来表示关键词的第1、2、3、4个字。例如,关键词“实验”的音节的分割集为{s,h,i,21,y,a,n,42}。
(a24)将关键词音节分割集中的元素映射到关键词向量
进一步的,在本实施例中,当采用基于unigram的中文关键词向量生成算法1时,采用哈希族h={hσ:{0,1}42→{0,1}λ}。
进一步的,假设用户需要查询的关键词为“实验”,但是由于用户的拼写错误等原因,他实际输入的查询词为“实样”,即把an拼成ang。根据上文相同的操作可得到查询词“实样”的音节分割集yi为{s,h,i,21,y,a,n,g,42}。经过映射可得到查询词向量
进一步的,结合具体实例基于unigram的中文关键词向量生成算法2。在基于unigram的中文关键词向量生成算法1(简称算法1)中,当查询关键词出现前后字调换时,可能会返回无关文档。例如:“故事”,“事故”为两个意义完全不同的关键词,但是它们的音节的分割集都为{g,u,41,s,h,i,42}。由于算法1未考虑到音节的有序性,因此,在算法1中,用户若想查询关键词“事故”的相关文档,会返回有关“故事”的文档,并且由于音节分割集完全相同,包含“故事”的文档的欧氏距离与包含“事故”文档的欧氏距离相同,使得包含“故事”的文档也返回给用户,浪费了大量的带宽。针对这种缺陷,对算法1提出进一步改进。
此算法采用120比特的关键词向量
基于unigram的中文关键词向量生成算法2(简称算法2)与基于unigram的中文关键词向量生成算法1(简称算法1)不同之处在于:
(a31)首先将中文关键词转化成对应的拼音字符串;
(a32)将每一个关键词的拼音串按unigram方法分割,由于一般情况下最多只有四字成语调换前后字后还能是一个词,因此,在关键词的音节分割集后加入1、2、3、4来表示关键词的第1、2、3、4个字;
(a33)分别用1、2、3、4表示音节的四个音调,并在音调后加入1、2、3、4来表示关键词的第1、2、3、4个字。例如,例如,关键词“故事”的音节的分割集为{g1,u1,41,s2,h2,i2,42}。
(a34)将关键词音节分割集中的元素映射到关键词向量
进一步的,在本实施例中,当采用基于unigram的中文关键词向量生成算法2时,采用哈希族h={hσ:{0,1}120→{0,1}λ}。
进一步的,由上文分析可知,“故事”和“事故”两个意义完全不同的关键词的音节的分割集都为{g,u,41,s,h,i,42}。而两关键词经过算法2处理后的音节分割集完全不同,关键词“故事”的音节的分割集为{g1,u1,41,s2,h2,i2,42},“事故”的音节的分割集为{s1,h1,i1,41,g2,u2,42}。显然,这两个意义完全不同的关键词的向量
进一步的,在本实施例中,将域加权评分的概念引入文档的评分当中,对处于文档不同域中的关键词赋予不同的权重,将词频权重、域加权评分和关键词向量间的欧式距离三者结合,提出了一种三因子排序方法,使得排序结果更加精确。
进一步的,域加权评分过程如下:
将域加权评分的概念引入文档的评分当中,可以参考manningcd,raghavanp,schützeh.introductiontoinformationretrieval.cambridge:cambridgeuniversitypress,2008.
给定一系列文档,假定每篇文档有
令υi为查询和文档的第i个域的匹配得分(1和0分别表示是否匹配),于是,域加权评分方法可以定义为:
进一步的,词频权重过程如下:
采用tf的亚线性尺度变换方法计算词频权重wft,f:
可以参考jinli,chenx.efficientmulti-userkeywordsearchoverencrypteddataincloudcomputing.computing&informatics,2013,32(4):723-738。
进一步的,对步骤(3)以及步骤(8)进行细化说明。
buildindex(f,sk,l):
(b1)计算词频权重wft,f;
(b2)计算域加权得分zij:在本发明中,设定每篇文档fi有3个域,分别为标题、摘要和正文。其对应的权重系数分别为g1,g2,g3,满足公式(1)且g1>g2>g3。令υi为查询关键词在某篇文档的第i个域的匹配得分,υi=1表示匹配,υi=0表示未匹配。根据公式(2)计算关键词wj的域加权得分。例如,在文档fi中,关键词wj出现在标题和正文中,未在摘要中出现,则3个域的得分为υ1=1,υ2=0,υ3=1,那么,关键词wj在文档fi中的域加权得分为zij=g1×υ1+g2×υ2+g3×υ3=g1+g3。
(b3)构建索引:从lsh哈希族中选取l个独立的lsh函数。为每篇文档fi构建一个λ比特的布隆过滤器作为fi的索引ii,具体操作如下:
(b31)采用基于拼音串的中文关键词向量生成算法或基于unigram的中文关键词向量生成算法1或基于unigram的中文关键词向量生成算法2为文档fi中的每个关键词wj生成对应的关键词向量
(b32)利用hσ∈h将每一个关键词向量
进一步的,在本实施例中,当采用基于拼音串的中文关键词向量生成算法时,采用哈希族h={hσ:{0,1}63→{0,1}λ}。当采用基于unigram的中文关键词向量生成算法1时,采用哈希族h={hσ:{0,1}42→{0,1}λ}。当采用基于unigram的中文关键词向量生成算法2时,采用哈希族h={hσ:{0,1}120→{0,1}λ}。
进一步的,则对于
最后,授权用户使用数据拥有者分发的密钥sk,对返回的top-k篇密文进行解密,获得所需的明文文档。
进一步的,在本实施例中,由于云服务器不是完全可信的第三方,因此为了保障数据安全和个人隐私,用户会将部分敏感数据,例如私密邮件、个人电子医疗记录、公司财务报表等,加密后再存储到云服务器。当需要使用这些数据时,用户可以使用本发明提供的方法对云端数据进行中文多关键词模糊排序密文关键词检索。当授权用户由于各种原因无法输入准确的关键词时,也可以匹配到相关的文档,精确的返回给授权用户,满足用户的搜索需求。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!