一种基于大数据的智能推荐系统的制作方法
本发明涉及智能推荐
技术领域:
,具体涉及一种基于大数据的智能推荐系统。
背景技术:
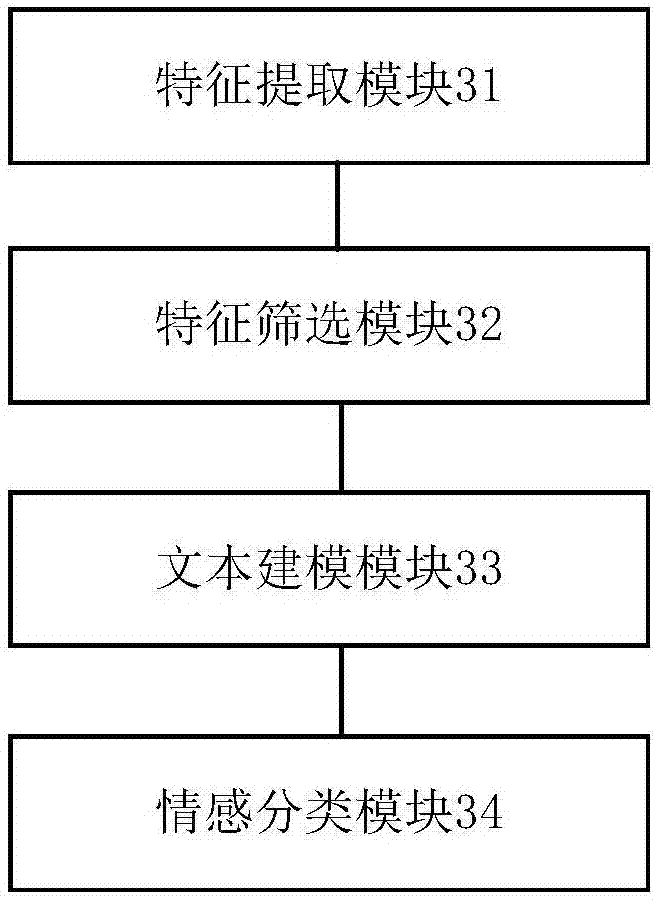
:现有的针对用户的智能推荐系统,基本都是根据用户的历史记录,推荐相似的条目给用户,若用户的历史记录空白,则无法向客户进行有效推荐。大数据库上的用户观点数据有着非常重要的研究价值以及商业价值,因此逐渐受到人们的重视。情感分类作为观点挖掘中的重要任务,对情感分类的研究显得尤为重要。情感分类的主要任务是将包含主观性文字的文本划分到不同类别中,现有的情感分类方法存在分类准确率差、分类速度慢等缺陷,无法满足日益提高的情感分类要求。技术实现要素:针对上述问题,本发明旨在提供一种基于大数据的智能推荐系统。本发明的目的采用以下技术方案来实现:提供了一种基于大数据的智能推荐系统,包括大数据库、用户消费数据库和推荐子系统;所述大数据库用于存储交通数据、酒店数据、餐饮数据及交通数据、酒店数据、餐饮数据的评价数据;所述用户消费数据库用于记录用户历史消费记录;所述推荐子系统用于向用户提供推荐项,对于任一领域消费,当用户有该领域的历史消费记录时,根据用户历史消费记录和所述大数据库向用户提供推荐项,当用户无该领域历史消费记录时,根据所述大数据库向用户提供推荐项。本发明的有益效果为:对于任一领域消费,能够向用户提供该领域推荐项。附图说明利用附图对本发明作进一步说明,但附图中的实施例不构成对本发明的任何限制,对于本领域的普通技术人员,在不付出创造性劳动的前提下,还可以根据以下附图获得其它的附图。图1是本发明的结构示意图;图2是本发明推荐子系统的结构示意图。附图标记:大数据库1、用户消费数据库2、推荐子系统3、特征提取模块31、特征筛选模块32、文本建模模块33、情感分类模块34。具体实施方式结合以下实施例对本发明作进一步描述。参见图1、图2,本实施例的一种基于大数据的智能推荐系统,包括大数据库1、用户消费数据库2和推荐子系统3;所述大数据库1用于存储交通数据、酒店数据、餐饮数据及交通数据、酒店数据、餐饮数据的评价数据;所述用户消费数据库2用于记录用户历史消费记录;所述推荐子系统3用于向用户提供推荐项,对于任一领域消费,当用户有该领域的历史消费记录时,根据用户历史消费记录和所述大数据库1向用户提供推荐项,当用户无该领域历史消费记录时,根据所述大数据库1向用户提供推荐项。本实施例对于任一领域消费,能够向用户提供该领域推荐项。优选的,所述交通数据是与航班时刻、航班类型、航空公司、铁路时刻、火车类型、火车座位有关的数据,所述酒店数据是与酒店名称、酒店位置、酒店级别、酒店入住率、酒店特色服务、酒店相关交通有关的数据,所述餐饮数据是与餐馆位置、餐馆类型、餐馆评价、餐馆菜系、餐馆特色有关的数据。本优选实施例大数据库提供了丰富的数据资源。优选的,所述大数据库1向用户提供推荐项根据评价数据的情感分类进行。本优选实施例根据情感分类向用户提供推荐项,能够提高用户满意度。优选的,所述推荐子系统3能够对大数据库中的评价数据进行情感分类,包括特征提取模块31、特征筛选模块32、文本建模模块33和情感分类模块34,所述特征提取模块31用于对评价数据中的文本包含的情感特征进行提取,所述征筛选模块32用于对提取的特征进行筛选,所述文本建模模块33用于根据筛选后的特征建立评价数据的文本模型,所述情感分类模块34用于根据文本模型对大数据库中的评价数据进行分类。所述特征筛选模块32包括第一筛选单元和第二筛选单元,所述第一筛选单元对提取的特征进行初步筛选,得到初步筛选的特征,所述第二筛选单元对初步筛选的特征进行进一步筛选,得到最终筛选的特征。所述对提取的特征进行初步筛选采用以下步骤进行:a、令w={w1,w2,…,wn}表示所有文本的集合,wi∈w表示集合中一个文本,n表示文本总数,c={c1,c2,…,ck}表示文本分类集合,ci∈c表示集合中一个分类,k表示分类的总数,f0={f1,f2,…,fm}表示任意文本wi包含的特征集合,fi∈f0表示集合中一个特征,m表示特征总数;b、建立初步筛选函数dy:式中,表示特征fi初步筛选函数值,wip(fi)表示特征fi在文本wi中出现的次数,设定阈值dy1,若则对特征予以保留,否则将特征过滤掉,得到初步筛选的特征。所述对初步筛选的特征进行进一步筛选采用以下步骤进行:a、对于任意ci∈c,建立最终筛选函数de:式中,de(ci,fi)表示特征fi最终筛选函数值,z(ci,fi)表示训练样本中的文本中包含特征fi且被划分为ci的文本数,表示训练样本中的文本中不包含特征fi且不被划分为ci的文本数,表示训练样本中的文本中包含特征fi且不被划分为ci的文本数,表示训练样本中的文本中不包含特征fi且被划分为ci的文本数;b、设定阈值de1,若de(ci,fi)>de1,则对特征予以保留,否则将特征过滤掉,得到最终筛选的特征。由于文本包含大量特征,将所有特征用于文本建模既耗时又易造成过度拟合,本优选实施例推荐子系统设置特征筛选模块对文本特征进行提取,抽取合适的特征集合来刻画文本,能够提高计算效率,减少工作时间,采用第一筛选单元和第二筛选单元对特征进行两次筛选,对多余的特征进行两次滤除,得到的特征更加符合实际应用的需求。优选的,所述文本模型采用以下方式建立:设文本集合为w,w={w1,w2,…,wn},其中,n表示文本数量,将集合中任意文本wi表示成一系列特征的集合f,计算每个特征对文本的重要程度,完成文本建模,其中,f={f1,f2,…,fm},f表示最终筛选的特征集合,m表示特征数量;计算每个特征对文本的重要程度,具体采用重要性程度指标zc衡量特征对文本的重要性程度:式中,表示特征fi对文本wi的重要性程度指标值,wip(fi)表示特征fi在文本wi中出现的次数,表示文本wi中包含的所有特征出现次数总和,wd(fi)表示特征fi在文本集合w中出现的次数。本优选实施例推荐子系统文本建模模块的文本模型简单、算法复杂度低,采用重要性程度指标来衡量特征对文本的重要性程度,有助于后续评价数据分类快速准确进行。优选的,所述根据文本模型对大数据库中的评价数据进行分类采用以下步骤进行:a、确定分类指标函数:式中,p(c|wi)表示文本wi被划分为c类的指标值,c表示分类的类标,ρ(fj,c)表示指示函数,当训练样本中文本的特征fj与类标同时出现时值为1,否则为0;b、选取指标值最大的类别作为评价数据的最终类别。本优选实施例推荐子系统情感分类模块通过分类指标函数实现了对文本的分类,分类过程中引入指示函数,获取的文本类结果更为准确,从而获取了更为准确的评价数据分类结果。采用本发明基于大数据的智能推荐系统向用户提供推荐项,当推荐项数目取不同值时,对推荐准确性和推荐时间进行统计,同未采用本发明相比,产生的有益效果如下表所示:推荐项数目推荐准确性提高推荐时间减少510%18%615%23%720%25%824%28%931%32%最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1