一种基于梯度提升树的停电投诉风险预测方法与流程
本发明涉及停电投诉风险预测技术领域,特别是一种基于梯度提升树(gradient-boostedtrees)的停电投诉风险预测方法。
背景技术:
当前,包括企业、个人等各类客户对于供电服务品质的期望值不断提高,对服务品质提出了更高的要求。而在现有技术中,供电企业大多无法对不同用户的停电敏感类型进行划分,以根据不同用户对停电的敏感程度采取不同的安抚和引导策略,从而带来大量的停电投诉,对企业形象造成负面影响,给企业的正常运营造成困扰,甚至衍生各类法律纠纷。
技术实现要素:
本发明的目的在于提供一种基于梯度提升树的停电投诉风险预测方法,该方法有利于准确判别不同用户对停电的敏感程度,以据此采取不同的安抚和引导策略,减少用户的停电投诉量。
为实现上述目的,本发明的技术方案是:一种基于梯度提升树的停电投诉风险预测方法,包括以下步骤:
步骤a:建立用户用电信息表,用户用电信息表中包括用户信息、停电信息以及用户停电投诉信息;
步骤b:对用户用电信息表中的用户用电信息数据集进行预处理;
步骤c:采用canopy算法、kmeans算法对用户用电信息数据集进行聚类,通过客户画像分析对用户用电信息数据集进行敏感类别标记,然后通过基于spark的smote过采样算法对不平衡分布的用户用电信息数据集进行数据处理,以提高分类准确性;
步骤d:对步骤c处理后的用户用电信息数据集进行梯度提升树的训练,得到停电投诉风险模型;
步骤e:运行步骤d得到的停电投诉风险模型,预测用户的停电敏感类别。
进一步的,步骤b中对用户用电信息表中的用户用电信息数据集进行预处理,具体包括以下步骤:
步骤b1:进行数据填充,在整个模型输入宽表中,对于枚举类型字段,采用默认值填充方式,即分别填充一个预先设定的默认类别;对于数值型字段,采用平均值填充法或零值填充法;
步骤b2:进行异常值处理,对于异常值所占比例小于设定值的字段,采用直接删除含异常值记录的方法;对于异常值所占比例大于设定值的字段,采用基于箱型图的异常值检测方法;
步骤b3:进行规范化处理,对于数值型字段,进行区间规范化,即根据公式(1)将数值归一化到[0,1]区间;对于取值全为0的特征项,不对该特征规范化,即保持原始值0;
其中vnorm为规范化处理结果,vinitial为特征原始值,vmin为该特征项的最小值,vmax为最大值;
步骤b4:进行连续属性离散化,采用等宽法将具有连续属性的字段进行离散化,分为多个类别,即将连续属性的值域根据数据特点或设定分成具有相同宽度的区间,以便于类别分析。
进一步的,步骤c中对用户用电信息数据集进行聚类和敏感类别标记,以及对不平衡分布的训练集数据进行处理,具体包括以下步骤:
步骤c1:采用canopy算法完成簇数k及初始簇中心的估计;
步骤c2:基于步骤c1确定的簇数k和初始簇中心,采用kmeans算法寻找簇中心直至其达至稳定实现对象的划分;
步骤c3:通过上述步骤的聚类得到k个客户群体,然后进行客户画像分析,根据用户的行业类别、客户类别、用电类型、行政区域、月均电量进行业务特征刻画,以反映不同客户群体的特征差别;根据客户画像分析的结果,对不同客户群体进行敏感类别的标记;
步骤c4:采用smote过采样算法按如下步骤对不平衡分布的训练集数据进行处理:
c41:对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集s_min中所有样本的距离,得到其k近邻;
c42:根据样本不平衡比例设置一个采样比例以确定采样倍率n,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为
c43:对于每一个随机选出的近邻
其中,rand(0,1)表示随机取0到1之间的一个值。
进一步的,步骤d中进行梯度提升树的训练以得到停电投诉风险模型,具体包括以下步骤:
步骤d1:初始化回归树,其为只有一个根节点的树,估计使损失函数极小化的常数值;
步骤d2:对回归树进行迭代更新;
步骤d21:计算损失函数的负梯度在当前模型的值,将其作为残差的估计;
步骤d22:估计回归树叶节点区域,以拟合残差的近似值;
步骤d23:利用线性搜索估计叶节点区域的值,使损失函数极小化;
步骤d24:更新回归树;
步骤d3:得到停电投诉风险模型f(x);
其中,对于给定的处理后的用电信息数据训练集s和其特征维数f,设定梯度提升树的相关参数:最大迭代次数maxiter,树的最大深度maxdepth,用于训练模型的子样本占整个样本集合的比例subsamplingrate;连续型特征离散化数量maxbins,节点上最少样本数mininstancespernode和节点上最少的信息增益mininfogain等;完成参数设置后,进行上述梯度提升树的训练,得到训练模型f(x)作为停电投诉风险模型。
本发明的有益效果是提供了一种基于梯度提升树的停电投诉风险预测方法,该方法结合聚类和客户画像分析,对用户用电信息数据集进行梯度提升树的训练,然后基于训练得到的停电投诉风险模型预测不同用户的停电敏感类型和停电投诉风险,从而可以根据不同用户的敏感程度采取不同的安抚和引导策略,提高对电力用户的服务质量,减少用户的停电投诉量,具有很强的实用性和广阔的应用前景。
附图说明
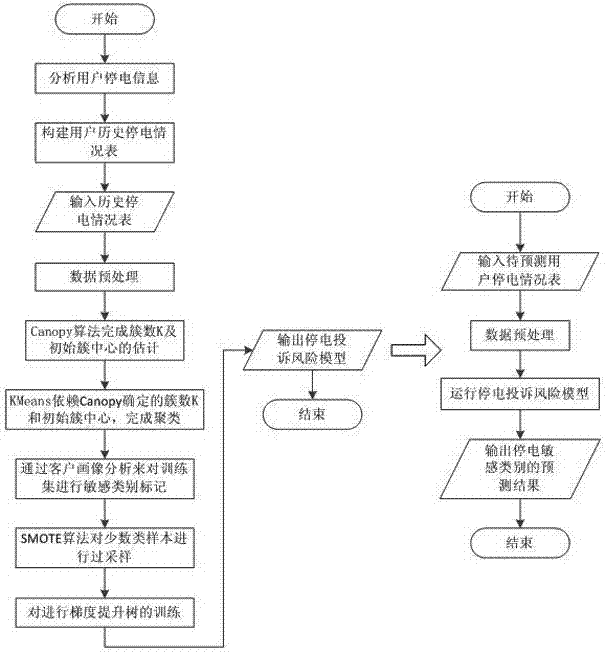
图1是本发明实施例的实现流程图。
图2是本发明实施例中基于箱型图的异常值检测的流程图。
图3是本发明实施例中canopy算法的实现流程图。
图4是本发明实施例中kmeans算法的实现流程图。
图5是本发明实施例中smote算法的实现流程图。
图6是本发明实施例中进行梯度提升树训练的实现流程图。
具体实施方式
下面结合附图及具体实施例对本发明作进一步的详细说明。
本发明基于梯度提升树的停电投诉风险预测方法,如图1所示,包括模型训练和模型预测两个过程,具体包括以下步骤:
步骤a:建立用户用电信息表,用户用电信息表中包括用户信息、停电信息以及用户停电投诉信息。
步骤b:对用户用电信息表中的用户用电信息数据集进行预处理,具体包括以下步骤:
步骤b1:进行数据填充,在整个模型输入宽表中,对于枚举类型字段,采用默认值填充方式,即分别填充一个预先设定的默认类别;对于数值型字段,采用平均值填充法或零值填充法。
步骤b2:进行异常值处理,对于异常值所占比例小于设定值的字段,采用直接删除含异常值记录的方法;对于异常值所占比例大于设定值的字段,采用基于箱型图的异常值检测方法。
数据收集的过程中难免会产生噪音数据,噪音数据中不可避免的存在一些异常数据需要处理。对于异常值所占比例小于设定值的字段,采用直接删除含异常值记录的方法;对于异常值所占比例大于设定值的字段,采用基于箱型图的异常值检测方法;如图2所示,箱型图判断异常值主要以四分位数和其间的位距为基础;异常值被定义为小于ql-1.5iqr或大于qu+1.5iqr的值,ql为下四分位数,qu为上四分位数,iqr为上下四分位数的间距,其区间包含了观测值的一半;四分位数具有一定的健壮性,不在四分位区间内的数可以变得任意远,不会对四分位数造成太大影响;因此,箱线图识别异常值的结果比较客观,具有一定优越性。
步骤b3:进行规范化处理,对于数值型字段,如停电次数、本月电量、投诉、报修、咨询、意见诉求量等数值,进行区间规范化,即根据公式(1)将数值归一化到[0,1]区间;对于取值全为0的特征项,不对该特征规范化,即保持原始值0。
其中vnorm为规范化处理结果,vinitial为特征原始值,vmin为该特征项的最小值,vmax为最大值;
如本月用电量字段等可能普遍是以百位数,千位数的数值居多,而停电或者投诉次数等字段以个位数、十位数的数值居多,对此进行特征规范化处理,将数据按比例进行缩放,使之落入一个特定的区域,便于综合分析。
步骤b4:进行连续属性离散化,采用等宽法将具有连续属性的字段(即用实数表示的字段,非离散值)进行离散化,分为多个类别,即将连续属性的值域根据数据特点或设定分成具有相同宽度的区间,以便于类别分析。
其中等宽法就是将连续属性的值域分成具有相同宽度的区间,区间的个数由数据本身的特点决定,或者由设计者设定。
步骤c:采用canopy算法、kmeans算法对用户用电信息数据集进行聚类,通过客户画像分析对用户用电信息数据集进行敏感类别标记,然后通过基于spark的smote过采样算法对不平衡分布的用户用电信息数据集进行数据处理,以提高分类准确性。具体包括以下步骤:
步骤c1:采用canopy算法完成簇数k及初始簇中心的估计。
其中canopy算法是一种聚类算法,依据参数t1和t2实现对象的粗略划分;图3显示本发明中canopy算法的运行过程:首先,将所有对象加入候选集;然后,每次从候选集中取出一个对象,计算它的所有canopy的距离(第一个对象自动成为canopy),若它与某个canopy的距离小于t1,则将其加入该canopy(图中实线圈);若它与某个canopy的距离还小于t2,则认为它们太接近了,不再考虑其作为canopy的可能性,从候选集中删除这个对象(图中虚线圈);算法迭代运行至所有对象都加入某个canopy;最后,计算canopy的数量即为簇数k的估计值,而每个canopy中对象的均值即为初始簇中心。
步骤c2:基于步骤c1确定的簇数k和初始簇中心,采用kmeans算法寻找簇中心直至其达至稳定实现对象的划分。图4显示本发明中kmeans算法的运行过程:首先选择k个簇中心,然后在每次迭代时将对象划分至最相似的簇中心,形成新的簇划分后再计算同簇对象的均值作为新的簇中心;这个过程反复进行,直至簇中心不再变动或达到最大迭代次数为止。
步骤c3:通过上述步骤的聚类得到k个客户群体,然后进行客户画像分析,根据用户的行业类别、客户类别、用电类型、行政区域、月均电量进行业务特征刻画,以反映不同客户群体的特征差别;根据客户画像分析的结果,对不同客户群体进行敏感类别的标记。
步骤c4:采用smote过采样算法按如下步骤对不平衡分布的训练集数据进行处理;由于数据类别是依靠聚类结果得到,存在数据不平衡分布的情况,造成了分类器在多数类的分类精度较高而在少数类的分类精度很低。因此,本发明实现了一个基于spark的并行smote合成少数过采样算法。如图5所示,smote算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中。采用smote过采样算法对不平衡分布的训练集数据进行处理的流程步骤如下:
c41:对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集s_min中所有样本的距离,得到其k近邻;
c42:根据样本不平衡比例设置一个采样比例以确定采样倍率n,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为
c43:对于每一个随机选出的近邻
其中,rand(0,1)表示随机取0到1之间的一个值。
步骤d:对步骤c处理后的用户用电信息数据集进行梯度提升树的训练。如图6所示,具体包括以下步骤:
步骤d1:初始化回归树,其为只有一个根节点的树,估计使损失函数极小化的常数值;
步骤d2:对回归树进行迭代更新;
步骤d21:计算损失函数的负梯度在当前模型的值,将其作为残差的估计;
步骤d22:估计回归树叶节点区域,以拟合残差的近似值;
步骤d23:利用线性搜索估计叶节点区域的值,使损失函数极小化;
步骤d24:更新回归树;
步骤d3:得到最终的停电投诉风险模型f(x)。
其中,对于给定的处理后的用电信息数据训练集s和其特征维数f,设定梯度提升树的相关参数:最大迭代次数maxiter,树的最大深度maxdepth,用于训练模型的子样本占整个样本集合的比例subsamplingrate;连续型特征离散化数量maxbins,节点上最少样本数mininstancespernode和节点上最少的信息增益mininfogain等;完成参数设置后,进行上述梯度提升树的训练,得到训练模型f(x)作为停电投诉风险模型。
梯度提升树是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案;该算法具有较强的泛化能力,可以发现多种有区分性的特征以及特征组合;业界中,facebook使用其来自动发现有效的特征、特征组合,来作为lr模型中的特征,以提高ctr预估(click-throughrateprediction)的准确性;在淘宝的搜索及预测业务上,梯度提升树也发挥了重要作用。
步骤e:利用运行步骤d得到的停电投诉风险模型,预测用户的停电敏感类别。
对于给定的需要预测的新的用户用电信息数据集t,将其作为步骤d所生成的停电投诉风险模型的输入,进行类别预测,输出预测结果的结构如表1所示。
预测得到的敏感类别标识用户所属于的客户群体,结合步骤c中的客户画像分析对不同客户群体特征差别的刻画,分析用户对停电的敏感类型和用户停电投诉的风险,有利于制定相应安抚和引导策略来提高电力客户服务质量,降低客户停电投诉量。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!