一种基于向量空间模型的英汉语料提取方法与流程
本发明涉及英语语料库领域。更具体地说,本发明涉及一种基于向量空间模型的英汉语料提取方法。
背景技术:
基于英汉双语语料库的前后文建模方法是利用语料库提供的词语和词语间彼此的关联性来对词语进行向量化建模,向量空间模型也称为单向向量空间模型,是基于统计词语相似度计算策略中使用广泛的一种模型,其理论基础是计算出源语言中每一个词wi的特征词向量ri,再计算出目标语言中每一个词wi的特征词向量ri则计算词wi和wj的相似度就转换成计算特征词向量ri与rj的相似度。而单向向量空间模型存在精确度不够的问题,常常发生翻译不准备或词不达意。
技术实现要素:
本发明目的是提供一种基于向量空间模型的英汉语料提取方法,通过构建双向前后文词语向量空间模型,提高英汉语料翻译的精确度。
本发明还有一个目的是提供一种构建双向前后文词语向量空间模型的方法,从汉至应进行正向传输,再从英至汉反向传输,正、反向传输通过计权等效分析最终确定传输效果,提高翻译的精确度。
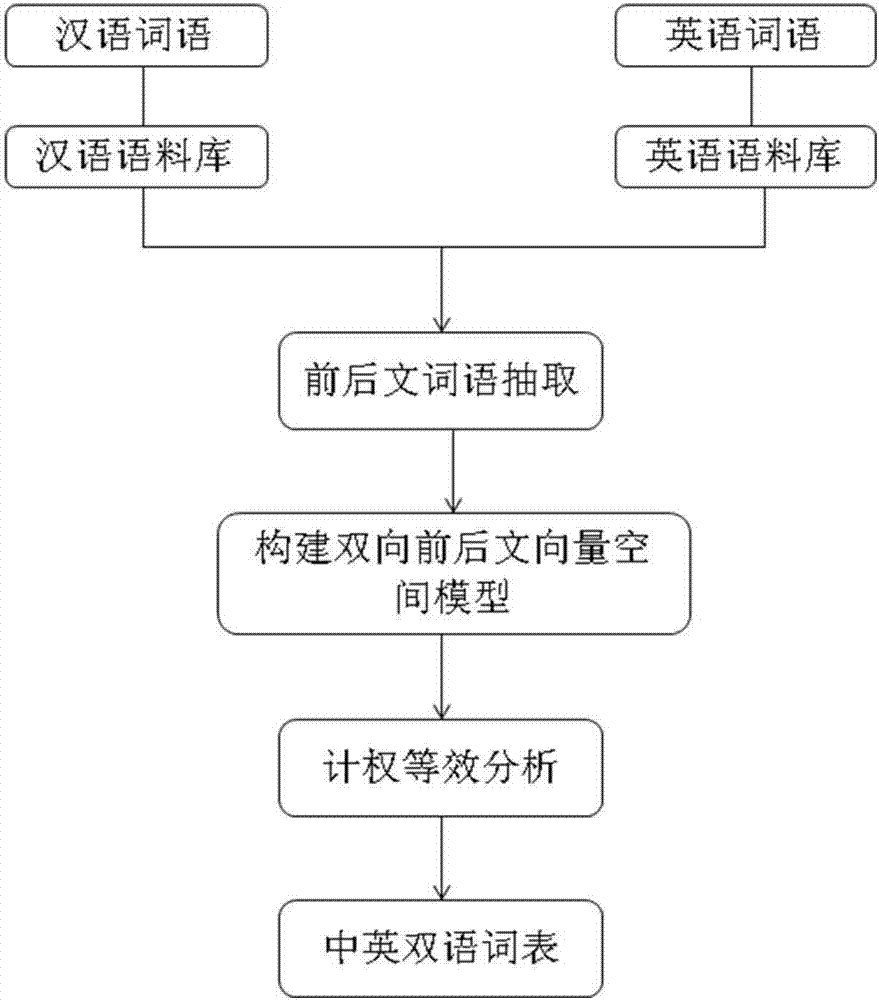
为了实现根据本发明的这些目的和其它优点,提供了一种基于向量空间模型的英汉语料提取方法,包括:
步骤1、分别对汉语和英语语料库进行预处理;
步骤2、构建双向前后文词语向量空间模型;
步骤3、进行计权等效分析,将第一升序集合{km,k2,k1,k3··ki··k4}中的英语单词依次进行计权等效相似度sim(ki)|计权计算,所述计权等效相似度sim(ki)|计权为:
其中,ωai为第一计权因子,ωbi为第二计权因子;
步骤4、将sim(k1)|计权、sim(k2)|计权、…sim(ki)|计权、…、sim(km)|计权中最大数值对应的英语单词确定为汉语语料中心词语的词对,建立中英双语词表。
优选的是,所述双向前后文词语向量空间模型构建过程包括:步骤2.1、选取汉语语料的中心词语并构建前后文词语向量s;步骤2.2、进行汉至英正向模型构建,在进行英至汉反向模型构建。
优选的是,所述正向模型构建包括:列举出全部与中心词语的具有相同词义的英语单词;对任意一个英语单词ki构建其前后文词语向量t,对前后文词语向量s和t进行相似度计算;设定相似度阈值,剔除小于相似度值阈值的英语单词,其他单词按照相似度值进行升序排列,组成第一升序集合。
优选的是,所述反向模型构建包括:将第一升序集合中每个英语单词作为中心词语,并建立其前后文词语向量t′;
列举出全部与作为中心词语的英语单词具有相同词义的汉语词,并构件每一个汉语词的前后文词语向量s′;
前后文词语向量s′与t′进行相似度计算,剔除掉小于设定相似度阈值的汉语词;
剩余汉语词按照相似度进行升序排列,依次计算平均相似度
优选的是,所述平均相似度为:
其中,sim(s′,t′)i为步骤4中剩余汉语词中第i个汉语词的相似度。
优选的是,所述相似度计算采用余弦相似度计算方法。
优选的是,所述第一计权因子ωai为:
其中,li为翻译单词ki在集合第一升序中从左至右方向的位次。
本发明至少包括以下有益效果:基于向量空间模型的英汉语料提取方法基于双向向量空间模型,大大提高语言在翻译过程中传输的准确度。
本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
图1是本发明的基于向量空间模型的英汉语料提取方法的流程图。
图2是本发明的基于向量空间模型的英汉语料提取方法中的构建双向前后文词语向量空间模型的流程图。
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
应当理解,本文所使用的诸如“具有”、“包含”以及“包括”术语并不配出一个或多个其它元件或其组合的存在或添加。
图1示出了根据本发明的一种实现形式,一种基于向量空间模型的英汉语料提取方法,包括以下步骤:
步骤1、分别对汉语和英语语料库进行预处理,所述预处理包括分词、去除停用词和词根还原;所述分词为将连续语言序列切分成单个词语。所述去除停用词为删除掉语言系列中的虚词、冠词或无实际信息的词。所述词根还原为:将各种形态的词语恢复至原始的词性。
步骤2、如图2所示构建双向前后文词语向量空间模型;
步骤2.1将汉语语料进行预处理,所述预处理步骤同步骤1。
步骤2.2选取汉语语料的中心词语,通过中心词语的前后文环境来选取前后文词语,并构建前后文词语向量;
例如:语料“a科研机构和与之相关的工作人员应该遵守相关规定”,进行预处理后变成“科研机构和工作人员遵守规定”;那么选取“工作人员”为中心词语,根据前后文环境来选取的前后文词语为“机构和”、“遵守规定”,构成的前后文词语向量为{机构、和、遵守、规定}。
步骤2.3进行相似度度量计算,选取高于相似度阈值的翻译单词集合。
将与中心词语的具有相同词义的全部英语单词k1,k2,k3··ki··kα罗列出来,任意一个英语单词ki的前后文词语向量t,计算其与汉语词语的前后文词语向量s的相似度,本发明的相似度计算均采用余弦相似度方法,因余弦相似度方法为通用的计算词语的相似度的方法,具体的计算过程不再进行赘述,本文只列出其计算公式:
中心词语的前后文词语向量s为:s=(s1,s2,s3····sn),其翻译成英文的英语单词ki的前后文词语向量t为:t=(t1,t2,t3····tn)。
余弦相似度为:
步骤2.4比较上述步骤计算的每个英语单词的相似度计算结果,将相似度阈值设定为0.75,将高于相似度阈值的英语单词重新罗列出来组成集合{k1,k2,ki····km},其中,m≤α;
集合中的每个元素对应的相似度为sim(s,t)1、sim(s,t)2、…sim(s,t)i…sim(s,t)m,进一步将集合按照相似度的大小进行升序排列,即为第一升序集合{km,k2,k1,k3··ki··k4},英文翻译单词k4与中心词语的相似度最高。
步骤2.3和2.4为正向模型构建,下面为反向模型构建:
步骤2.5反向前后文词语向量构建过程如下:
步骤2.5.1将集合{k1,k2,ki····km}中的每一英文单词进行预处理后作为中心词语,并抽取英语语料中词语的前后文词语建立前后文词语向量,具体过程可参考步骤2.2。
任一翻译单词ki进行预处理后作为中心词语,并抽取英语语料中词语的前后文词语建立前后文词语向量,具体过程可参考步骤2.2。
步骤2.5.2进一步将单词ki翻译成的全部汉语词语一一罗列出来,基于每一个汉语词语的前后文词语向量s′,前后文词语向量s′与英语词语ki的前后文词语向量t′进行相似度计算,均采用余弦相似度方法,将相似度阈值设定为0.75,选取高于相似度阈值的翻译单词集合{λ1,λ2,λ3····λn},并按照相似度进行升序排列,将集合中的相似度值进行相加后取平均,得到平均相似度
步骤3、进行计权等效分析
将英语单词第一升序集合{km,k2,k1,k3··ki··k4}中的元素依次进行计权等效相似度sim(ki)|计权计算,其计算过程为:
其中,ωbi为第二计权因子,通常取值为0.5。ωai为第一计权因子,其计算方法如下:如翻译单词ki在第一升序集合{km,k2,k1,k3··ki··k4}的位次为5,那么ωai为:
其中,li为翻译单词ki在集合第一升序中从左至右方向的位次,翻译单词km的位次为1。
将sim(k1)|计权、sim(k2)|计权、…sim(ki)|计权、…、sim(km)|计权中最大数值对应的英语单词确定为汉语词的翻译,最终将汉语词和英语单词组成双语词对;
步骤4、按照步骤1-3循环,将所有汉词语分别组合能够双语词对,从而组成中英双语词表。
通过中心词语的前后文环境关联词语来构建中心词的前后文词语向量,然后比较并选取目标语言中相似度最高的一个或多个向量,将向量对应的词语作为源语言的候选翻译词语,
步骤3、进行计权等效分析,建立中英双语词表。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用。它完全可以被适用于各种适合本发明的领域。对于熟悉本领域的人员而言,可容易地实现另外的修改。因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 还没有人留言评论。精彩留言会获得点赞!