一种英语识别方法和翻译方法与流程
本发明涉及英语教学领域,更具体的是,本发明涉及一种英语识别方法和翻译方法。
背景技术:
英语学习已经成为很多国家的教育的基础部分。根据以英语作为母语的人数计算,英语可能是世界上第三大语言,但它是世界上最广泛的第二语言。世界上60%以上的信件是用英语书写的,上两个世纪英国和美国在文化、经济、军事、政治和科学上的领先地位使得英语成为一种准国际语言。
英语学习中其实对学习者困扰最大的就是听力、单词记忆、写作、口语四个专项。这四个专项紧密联系,缺一不可。具体地说,例如,听力不好,口语就很差,英语语感就好不到哪去,单词也就很难记住。
常用的英语翻译装置需要对英语进行识别,而传统的英语识别方法识别英语过程慢,且正确率较低。
技术实现要素:
为解决英语识别过程慢,正确率低这一技术问题,本发明提供一种英语识别方法,能够有效快速的识别英文单词。
本发明的另一目的是提供一种翻译方法,能够快速、正确识别英语并翻译。
本发明的另一目的是提供一种用于英文识别的神经网络的权值和阈值的训练方法。
本发明提供的技术方案为:
一种英语识别方法,包括以下步骤:
步骤1:给定训练集n={(xi,ti)|xi∈rn,ti∈rn,i=1,2,3,…n},激励函数
如果当前为全连接层,输出特征值为:
yil=f(wlyil-1+bl)
如果当前为卷积层,输出特征值为:
yil=f(wl*yil-1+bl)
如果当前为池化层,输出特征值为:
yil=pool(yil-1)
其中,xi为待识别英语训练样本,ti为实际英语标签,yil第i个样本在第l层的输出特征值,yil-1为第i个样本在第l-1层的输出特征值,wl为第l层的输出权值,bl为第l层的偏置,yi0=xi,pool为按照池化区域大小和池化标准将输入缩小的过程;
步骤2:利用网络输出值和实际标签之间的误差和误差梯度进行反向传播,调整权值和偏置,直至误差梯度小于停止迭代阈值,否则重复对所述卷积神经网络进行模型训练,
如果当前为全连接层,误差梯度为:
δil-1=(wl)tδil⊙f'(yil-1)
如果当前为卷积层层,误差梯度为:
δil-1=δil*rot180(wl)⊙f'(yil-1)
如果当前为池化层,误差梯度为:
δil-1=upsampleδil⊙f'(yil-1)
其中,δil为误差梯度,rot180()表示上下翻转一次后再左右翻转一次。
优选的是,所述步骤2中的误差为:
其中,en为每个样本集的误差的和,c为卷积神经网络所分层数,n为训练样本数。
优选的是,所述步骤2中调整权值和偏置包括:
如果当前为全连接层:
如果当前为卷积层:
其中,α为梯度迭代参数,(δil)u,v为误差梯度δil各个子矩阵的项。
优选的是,所述步骤1中还包括:对所述文字训练样本进行归一化处理,归一域为[-1,1]。
优选的是,所述训练样本为英语单词和短语。
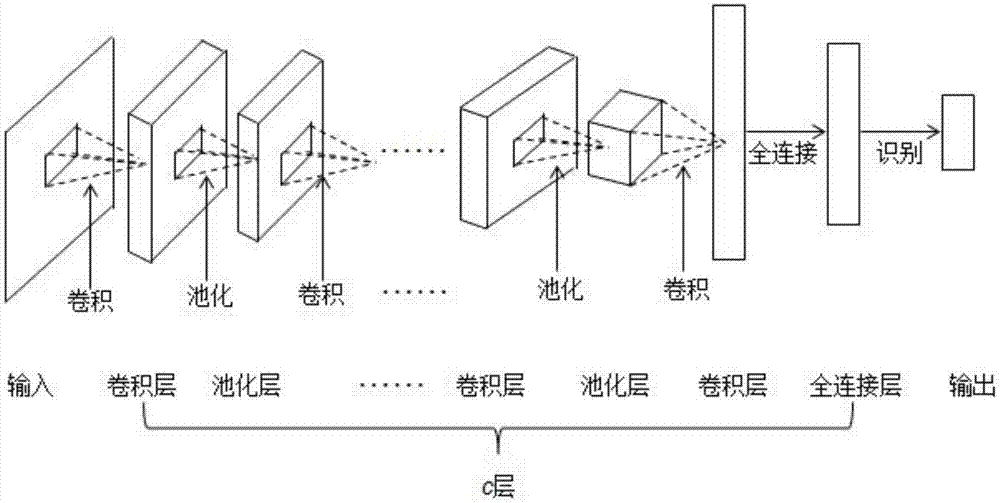
优选的是,所述卷积神经网络包括:
多个卷积层;
池化层,设置在每两个卷积层之间;以及
全连接层,设置在最后一个卷积层之后。
相应地,本发明还提供一种英语翻译方法,包括以下步骤:
步骤1:采用上述的英语识别方法对英语图像进行特征识别,得到英语图像特征值;
步骤2:按照预设的英语编码表,得到所述英语图像特征值对应的英语;
步骤3:将得到的所述英语翻译成对应的汉语。
优选的是,所述步骤3的翻译方法为逐词翻译,整句对应。
本发明所述的英语识别方法和翻译方法,能够快速、正确识别英语并翻译成对应的汉语,有助于人们在日常生活中对英文进行正确的记忆和学习。
附图说明
图1为本发明所述卷积神经网络的结构示意图。
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
本发明可以有许多不同的形式实施,而不应该理解为限于再次阐述的实施例,相反,提供这些实施例,使得本公开将是彻底和完整的。
本发明提供一种英语识别方法,包括以下步骤:
步骤1:给定训练集n={(xi,ti)xi∈rn,ti∈rn,i=1,2,3,…n},激励函数
如果当前为全连接层,输出特征值为:
yil=f(wlyil-1+bl)
如果当前为卷积层,输出特征值为:
yil=f(wl*yil-1+bl)
如果当前为池化层,输出特征值为:
yil=pool(yil-1)
其中,xi为待识别英语训练样本,ti为实际英语标签,yil第i个样本在第l层的输出特征值,yil-1为第i个样本在第l-1层的输出特征值,wl为第l层的输出权值,bl为第l层的偏置,yi0=xi,pool为按照池化区域大小和池化标准将输入缩小的过程;
步骤2:利用网络输出值和实际标签之间的误差和误差梯度进行反向传播,调整权值和偏置,直至误差梯度小于停止迭代阈值,否则重复对所述卷积神经网络进行模型训练,
如果当前为全连接层,误差梯度为:
δil-1=(wl)tδil⊙f'(yil-1)
如果当前为卷积层层,误差梯度为:
δil-1=δil*rot180(wl)⊙f'(yil-1)
如果当前为池化层,误差梯度为:
δil-1=upsampleδil⊙f'(yil-1)
其中,δil为误差梯度,rot180()表示上下翻转一次后再左右翻转一次。
所述步骤2中的误差为:
其中,en为每个样本集的误差的和,c为卷积神经网络所分层数,n为训练样本数。
所述步骤2中调整权值和偏置包括:
如果当前为全连接层:
如果当前为卷积层:
其中,α为梯度迭代参数,(δil)u,v为误差梯度δil各个子矩阵的项。
所述步骤1中还包括:对所述文字训练样本进行归一化处理,归一域为[-1,1]。
本实施例中所使用的训练样本为英语单词和短语。
如图1所示,本发明所述英语识别方法采用的卷积神经网络包括:多个卷积层;池化层,设置在每两个卷积层之间;以及全连接层,设置在最后一个卷积层之后。
实验数据和设计
实验将在英语数据库上进行测试:
英语数据库:该库包含50000个英语单词和50000个英语短语,该库内的英文图像已进行过归一化处理。实验时,分别选择60000、80000和90000个单词、短语为训练样本,则剩余的40000、20000和10000个单词、短语为测试样本。
识别结果及分析
由于卷积神经网络模型中初始的权值和偏置是随机赋值的,因此会对实验效果具有一定的影响。为了更好的说明卷积神经网络的效果,在该数据库进行150次实验,识别率取其平均值,并记录下这150组数据的标准差以说明算法的稳定性,结果如表1所示。
表1
上述结果表明,本发明所述的英语识别方法能够更加快速的识别英语,并且正确率较高。
本发明还提供一种英语翻译方法,包括以下步骤:
步骤1:采用上述的英语识别方法对英语图像进行特征识别,得到英语图像特征值;
步骤2:按照预设的英语编码表,得到所述英语图像特征值对应的英语;
步骤3:将得到的所述英语翻译成对应的汉语。
本实施例中,采用上述英语识别方法对英语进行识别,由于该识别方法中采用的训练样本为英语单词和短语,所在在步骤3中使用的翻译方法为逐词翻译,整句对应。
应当理解的是,本发明采用的英语识别方法和翻译方法并不限于英语,也可以是汉语,法语,德语等具有一定图像的语言,仅需在模型训练时修改训练样本即可。
本发明提供的英语识别方法和翻译方法,采用卷积神经网络进行英语图像识别,能够快速、正确的识别英语,并将其翻译成对应的汉语。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 还没有人留言评论。精彩留言会获得点赞!