一种基于管道模式的端到端英文篇章结构自动分析方法与流程
本发明涉及一种基于管道模式的端到端英文篇章结构自动分析方法,特别涉及一种基于混合卷积树核和多项式核相结合的显式篇章关系分析方法和一种基于深度学习的非显式篇章关系分析方法,属于自然语言处理应用技术领域。
背景技术:
篇章分析一直是自然语言处理的核心任务,其所提供的篇章上下文信息以及篇章级语义信息对机器翻译、情感分析、自动问答等自然语言处理其它任务具有重要意义。篇章结构分析旨在研究篇章文本的构成方式,获取篇章内部的层次或逻辑语义关系,是篇章分析的重要途径之一。篇章关系是指在篇章内部,表示扩展、对比、转折等句子之间或子句之间的语义连接关系。有时这种语义关系会由表示连接作用的词语来表征,即连接词。因此,篇章关系分析通常包括篇章连接词识别、篇章关系单元划分以及篇章关系判别几个部分。在自然语言处理领域,早期的篇章结构分析研究多集中在上述的孤立子问题上。近几年,随着对篇章分析的研究逐渐深入,对系统地理解篇章的需求也愈加明显。再加上篇章标注理论的不断发展和大规模篇章标注语料库的构建,一些端到端篇章结构分析装置应运而生。但是,与其它词、句层面的自然语言处理任务相比,对计算机处理篇章问题的研究和实践只是刚起步,在有限的基础资源上进行的一些子问题的处理也只处于实验阶段,基于当前各个子问题的研究从整体上构建篇章理解的计算框架更是任重道远。
首先,对于显式篇章关系识别,传统方法采用词袋模型进行特征向量化,对于一些内部种类相对较多的特征,不仅会造成特征向量维度过大,特征更加稀疏,而且会带来某些相似特征在向量表示上却并不相似的问题。同时,该方法并不能合理地表示结构化特征,诸如句法路径。其次,对于非显式篇章关系识别,前人的工作已经证明了词对信息是一个很强的特征。然而,由于数据稀疏以及语义鸿沟问题,基于词对特征的分类效果并没有达到预期效果。同时,语言学特征往往只是停留在论元表面,并不能挖掘更深层次的语义。受到端到端装置中以上各子任务性能相对不高的约束,现有的端到端篇章自动分析方法整体性能都普遍较低。
基于此,目前迫切需要一种较为高效的端到端英文篇章结构自动分析方法,通过提升各子任务的性能来提升自动分析装置整体性能,为其它自然语言处理任务提供便利。
技术实现要素:
本发明目的是为解决以往端到端英文篇章结构分析装置中各子任务存在的问题,以优化端到端英文篇章结构分析装置整体性能为目标,提出了一种基于管道模式的端到端英文篇章结构自动分析方法。
本发明技术方案的思想是:首先,对于显式篇章关系识别模块,针对传统方法采用词袋模型进行特征向量化的不足,提出了基于混合卷积树核和多项式核相结合的特征表示和计算方法,对句法特征和扁平特征分而治之,不仅可以大大降低特征向量维度,而且可以充分表达特征中的细节信息。其次,在非显式篇章关系识别模块,随着wordembedding技术取得的巨大进展,并且在很多基于深度学习的模型上也表现出了强大的能力,可以很好的克服传统方法带来的数据稀疏以及语义鸿沟问题。同时,针对语言学特征不能挖掘更深层次的语义的问题,通过仔细分析非显式篇章关系识别的特点,运用词对特征的优势,提出了基于深度学习的非显式篇章关系识别模型。
为实现以上目的,本发明采用的技术方案如下:
一种基于管道模式的端到端英文篇章结构自动分析方法,包括训练步骤和实际分析方法,具体如下:
训练步骤,具体步骤如下:
步骤一、准备训练语料:
采用现有的包含有篇章原文、篇章关系所对应的连接词、论元范围、篇章关系类别的篇章库作为训练语料,采用工具生成篇章原文的词性标注和句法分析;
步骤二、wordembedding表示:
使用大规模语料库训练word2vec,将每个单词映射到向量空间的低维向量,从而表示每个单词的语义;
步骤三、对显式篇章关系训练语料进行特征提取:
分别就训练语料中显式篇章关系所包含的各部分:篇章连接词及其论元范围、显式篇章关系提取句法路径等句法特征以及词汇、词性等扁平特征,如果是单个词汇特征使用步骤二生成的wordembedding表示;
步骤四、核函数构建:
基于步骤三提取的特征,分别构建相应的混合卷积树核与多项式核相结合的核函数;
作为优选,所述混合卷积树核khybrid(t1,t2)通过下式构成:
khybrid(t1,t2)=λkpath(t1,t2)+(1-λ)kcs(t1,t2);
其中:0≤λ≤1,t1,t2是两棵句法树。
步骤五、svm分类模型训练:
基于步骤四构建的核函数采用svm分类算法生成步骤三所提到的显式篇章关系所包含的各部分相对应的分类模型;
步骤六、有用词对表构建:
将训练语料中的所有非显式篇章关系作为抽取对象,从其论元对中分别抽取一词作为词对,统计各词对在各篇章类别中的信息增益值大小,选取高于阈值m的词对构建有用词对表;
作为优选,非显式篇章关系包括隐式篇章关系和entrel篇章关系。
作为优选,m=1e-3。
步骤七、用于非显式篇章关系识别的深度学习模型构建:
利用双向lstm分别对输入模型中的两个相邻句子进行编码,抽取词对,选取出现在步骤六所构建的有用词对表中的词对作为后续卷积神经网络的输入;
上述的处理过程即构成了一个用于非显式篇章关系识别的深度学习模型;
作为优选,所述深度学习模型构建包括以下步骤:
(1)构建双向lstm层:对于每个论元,分别按从头到尾和从尾到头的顺序构建lstm模型;
(2)抽取词对:对经过(1)编码的的论元抽取词对,并经过有用词对表过滤,保留有用词对作为下一层的输入;
(3)构建卷积神经网络模型:将(2)所生成的词对信息以矩阵的形式输入到卷积神经网络中,矩阵的每一行都是相应词对的向量表示,分别通过卷积层、max-pooling层以及softmax层输出分类结果。
作为优选,所述max-pooling层使用了dropout,以此来控制过拟合,将其值设置为0.5;使用交叉熵损失函数作为卷积神经网络的训练目标,并且应用adagrad算法以0.01的学习率进行学习;同时将训练数据分为多批进行训练,每一批数据的最小大小为50;在卷积层设置3个卷积核,其高度分别为3,4,5;使用tanh作为激活函数。
步骤八、深度学习模型参数学习:
将步骤一所提取的训练语料中的所有非显式篇章关系所对应的论元以及篇章关系抽取出来作为步骤七构建的深度学习模型的训练语料,进行参数学习;选取最优效果所对应的模型作为非显式篇章关系的分类模型。
实际分析方法,具体步骤如下:
步骤一、语料预处理:对输入的待识别篇章结构的英文文本进行分句操作,然后对每一句进行词性标注、句法分析,保存以供后续提取特征;
作为优选,所述进行词性标注、句法分析采用斯坦福大学开发的句法分析器和词性标注工具进行。
步骤二、显式篇章关系识别:以篇章连接词为主线,分别提取显式篇章关系所包含的各部分所需特征,并使用训练步骤五生成的svm分类模型,获取正确的篇章连接词以及其对应的论元范围和显式篇章关系类别,并将以上三部分的最终结果组合成结构体保存;
步骤三、非显式篇章关系识别:基于训练步骤八最终确定的深度学习模型对步骤一所保存文本中不属于显式篇章关系的所有相邻句对进行非显式篇章关系识别,并确定其论元范围,以结构体形式保存;
步骤四、识别完成:将步骤二与步骤三所保存结构体组合输出至文本中,作为输出。
有益效果:
对比现有技术,本发明具有以下有益效果:
(1)针对传统方法采用词袋模型进行特征向量化的不足,提出了基于混合卷积树核和多项式核相结合的特征表示和计算方法,对句法特征和扁平特征分而治之,使得每个特征都得到了很好的表达,从而在显式篇章关系识别模块中的篇章连接词识别、显式关系判别,特别是论元划分子任务上得到了显著提升。
(2)针对传统基于语义学特征进行非显式篇章关系识别方法的不足,提出了基于深度学习的模型,充分利用词的上下文信息、词对特征及其上下文信息,提升了关系判别的精度。
附图说明
构成本申请的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明实施例显式篇章关系识别部分的训练流程图。
图2为本发明方法篇章关系识别流程示意图。
图3为本发明实施例中基于深度学习的非显式篇章关系识别模型。
具体实施方式
下面将参考附图并结合实施例来详细说明本发明。下述实施例中所使用的实验方法如无特殊说明,均为常规方法。
首先是训练步骤,如图1所示,其过程如下:
一、准备训练语料,实现步骤如下:
(1)以宾州篇章树库(pdtb)2.0版本中的section02-21作为训练语料,对于显式篇章关系,抽取其所对应的连接词、其论元(arg1、arg2)范围、篇章关系类别以及对应原文,并获得对应词性标注以及句法分析;对于非显式篇章关系,抽取其所对应的论元范围、篇章关系类别,以及篇章原文对应的词性标注以及句法分析结果,分别保存作为显式篇章关系和非显式篇章关系的训练语料;
二、wordembedding构建方法,实现步骤如下:
(1)获取训练语料,获取giga新闻语料2.21gb,在每一句最后加入句子结尾标记<end>,作为后续输入;
(2)基于步骤(1)获取的训练语料,使用word2vec工具训练词向量,选择skip-gram模型,输出维度为50,学习率设置为1e-3,窗口大小设置为5,训练之后得到词向量文件。
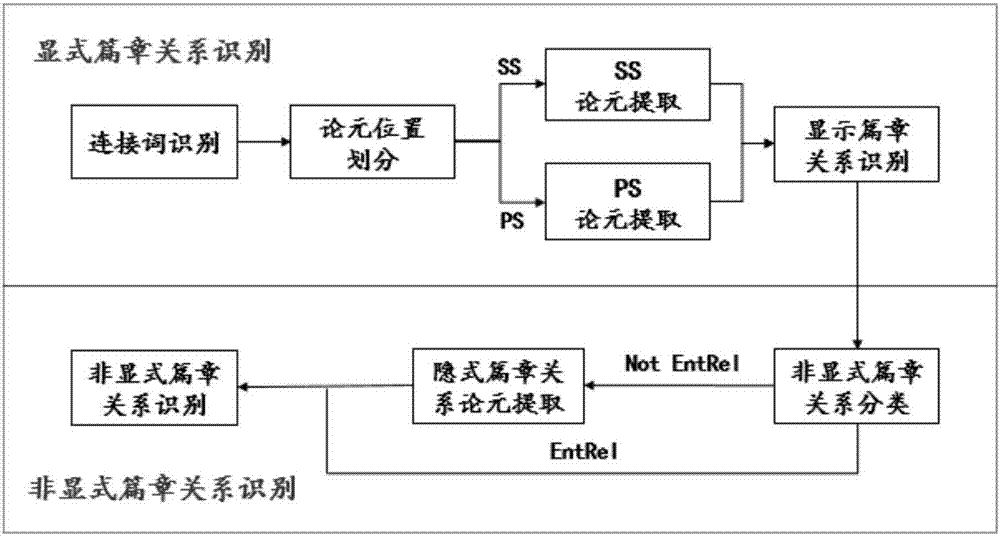
三、对显式篇章关系训练语料进行特征提取,如图2所示,显式篇章关系识别包括篇章连接词识别、论元范围确定、显式篇章关系识别三个部分,实现步骤如下:
(1)篇章关系连接词识别:在该部分,pdtb提供了一个大小为100的篇章连接词闭集,在一句话中,出现在该闭集中的词汇可能有很多,但是并不是全部都充当篇章连接词的角色,因此,需要对每个词汇进行消歧。如图1所示,本发明采用的基于分类的思想,对步骤一中提取的显式篇章关系训练语料中的每句原文进行扫描,选取出现在pdtb所给的100个篇章连接词闭集中的词汇作为篇章连接词候选,如果候选篇章关系连接词与正确的篇章连接词相同(包括在句中的位置),则赋予“1”的分类标签,反之,赋予“0”的分类标签,对每一个候选篇章连接词提取特征与对应的分类标签组成训练文本用于训练分类器使用。分类过程中提取的特征如下:
表1篇章连接词识别模块所用特征
表中的诸如连接词、连接词前一个词使用步骤二所训练的wordembedding表示;
(2)论元位置划分,如图2所示,在识别了一个文本内的所有篇章连接词之后,需要以篇章连接词为锚点来划分论元范围。arg2和篇章连接词是有直接语义联系的,其相对篇章连接词的位置是固定的。所以,这一部分主要的问题是判断arg1相对于篇章连接词的位置。基于pdtb,arg1相对于篇章连接词的位置可以分为以下几类:篇章连接词和arg1位于同一个句子中(ss)、arg1位于篇章连接词所在句中的前一个句子中(ps)。如图1所示,该部分同样采用分类思想处理,通过比较步骤一所提取的显式篇章关系识别的训练语料中,每个篇章连接词所在句与arg1所在句的大小,确定每个篇章连接词的位置信息:ss或ps,并为每一个篇章连接词提取相应特征,组合构成训练文本用于训练分类器使用。该部分所用特征如下:
表2论元位置识别所用特征
(3)论元范围确定,如图2所示,在确定了arg1相对于篇章连接词的位置之后,针对ss、ps的情况进行分类处理。就ps的情况,由于是发生在两个句子之间,因此直接将篇章连接词所在句作为arg2,其前一句作为arg1。就ss的情况,首先基于启发式规则在句法树中选取论元候选,如图1所示,通过构建分类模型来确定以上论元候选属于arg1、arg2、none中的哪一类,最后根据分类结果对各论元候选进行组合以形成最终论元。选取论元候选的启发式规则围绕篇章连接词制定,从篇章连接词节点(覆盖连接词的最低节点)开始递归运行,首先,搜集篇章连接词的所有兄弟节点作为论元候选,然后,移动到篇章连接词的父节点并搜集它的所有兄弟节点,直到到达根节点。此外,如果篇章连接词节点并不是完全严格地覆盖篇章连接词,那么,篇章连接词节点的其它孩子节点也需要搜集作为论元候选。对每一个论元候选与步骤一所提取的显式篇章关系训练语料中的正确论元比较,以确定其属于arg1、arg2、none中哪一类,并赋予分类标签,然后提取特征,组合构成训练文本用于训练分类器使用。对论元候选进行分类所用特征如下:
表3候选论元分类所用到的特征
(4)显式篇章关系识别,如图2所示,在确定了篇章连接词以及其统辖的论元范围之后,需要识别它们所表示的篇章关系,在该部分采用了conll-2016的篇章关系分类体系。如图1所示,该部分同样采用分类思想进行识别,通过为步骤一所提取的显式篇章关系训练语料中每一个篇章关系赋予分类标签并提取相应特征构成训练文本用于训练分类器使用,所用特征如下:
表4显式篇章关系识别所用特征
四、核函数构建:通过分析步骤三针对显式篇章关系识别各子部分所提取的特征可以发现,这些特征都是由句法特征和扁平特征构成,因此可以对其分别处理,以充分表达特征的细节信息。具体实现步骤如下:
(1)构建混合卷积树核:传统的paf树核是直接用一个核函数对句法树进行处理,这样会丢失句法信息所要表达的细节信息。通过仔细分析句法特征,可以发现其基本可以分为句法路径信息以及句法成分结构信息。因此,本发明对传统paf树核进行了改造,将其分为路径核(kpath)和句法成分结构核(kcs),其中,路径核指的是在所提取的句法特征中与路径相关的特征所构建的核函数,如:pathofc’sparent—>root;句法成分结构核指的是在所提取的句法特征中表示句法成分的特征所构建的核函数,如:self-category。对路径核和句法成分核详细说明并通过以下公式进行组合:
khybrid(t1,t2)=λkpath(t1,t2)+(1-λ)kcs(t1,t2)
其中:0≤λ≤1,t1,t2是两棵句法树。通过改变λ的大小来为路径核和句法成分结构核赋予不同的权重。
(3)构建混合卷积树核和多项式核相结合的核函数:步骤三中所提取的特征可以分为句法特征和扁平特征两种类型,在构建分类模型时,利用混合卷积树核(khybrid(t1,t2))和多项式核(kpoly(t1,t2))分别擅于处理句法特征和扁平特征的优势,对句法特征和扁平特征分而治之,最后通过以下公式进行线性组合构成分类模型:
kcomp(t1,t2)=γkhybrid(t1,t2)+(1-γ)kpoly(t1,t2)
其中,0≤γ≤1为组合系数。通过改变γ的大小来为混合卷积树核和多项式核赋予不同的权重。本实施例中,在篇章连接词识别部分,γ=0.5,在论元范围确定部分,γ=0.6,在显式篇章关系识别部分,γ=0.6。
五、svm分类模型训练,实现步骤如下:
(1)采用svm分类器,使用步骤四所构造的核函数,分别对步骤三所构造的训练文本进行计算,最终生成显式篇章关系所包含的各部分相对应的分类模型。
以上显式篇章关系训练过程如图1所示。
六、有用词对表构建,实现步骤如下:
(1)设置训练语料集合t的非显式篇章关系数为n,某个类别的数量用ni表示,其中i∈{1,2,…,13,14},分别为temporal.synchronous,temporal.asynchronous.precedence,temporal.asynchronous.succession,contingency.cause.reason,contingency.cause.result,contingency.condition,comparison.contrast,comparison.concession,expansion.conjunction,expansion.instantiation,expansion.restatement,expansion.alternative,expansion.alternative.chosenalternative,expansion.exception,entrel;
(2)遍历训练语料集合t的非显式篇章关系,针对每一个词对t,分别统计出现在对应类别的隐式篇章关系的频数ti,i∈{1,2,…,13,14},|t|表示词对t出现的总次数;
(3)计算对应词对的信息增益值,计算公式如下:
其中,h(n)表示所有类别的经验熵,h(n|t)表示词对t对所有类别的经验条件熵。
针对每一词对,均可计算出该词对对于隐式篇章关系分类的贡献程度,将所有词对按照信息增益值大小排序,选取ig(t)值不小于1e-5的词对构成有用词对集合t'。
七、用于非显式篇章关系识别的深度学习模型构建,如图3所示,实现步骤如下:
(1)构建双向lstm层:对于每个论元,分别按从头到尾和从尾到头的顺序构建lstm模型,生成向量维度都设置为50,将两个模型的隐层向量拼接后形成一个100维的向量用于表示每个单词,以待后用。模型中其它参数初始值在[-0.1,0.1]内随机生成。
(2)抽取词对:对经过(1)编码的的论元抽取词对,并经过有用词对表过滤,保留有用词对作为下一层的输入;
(3)构建卷积神经网络模型:将(2)所生成的词对信息以矩阵的形式输入到卷积神经网络中,矩阵的每一行都是相应词对的向量(按传统方法的方式,取两个词的向量平均值作为词对的向量)表示。分别通过卷积层、max-pooling层以及softmax层输出分类结果。模型中max-pooling层使用了dropout,以此来控制过拟合,并将其值设置为0.5;使用交叉熵损失函数作为卷积神经网络的训练目标,并且应用adagrad算法以0.01的学习率进行学习;同时将训练数据分为多批进行训练,每一批数据的最小大小为50;在卷积层设置3个卷积核,其高度分别为3,4,5;使用tanh作为激活函数。
前人工作已经证明,在非显式篇章关系识别,词对特征是一个很强的信息,而本发明充分利用了词对特征,并结合深度学习思想,充分挖掘了词对及其上下文所表达的深度语义信息,使其有益于非显式篇章关系识别。
八、深度学习模型参数学习,实现步骤如下:
(1)将步骤一所提取的非显式篇章关系训练语料中的所有篇章关系所对应的论元以及篇章关系抽取出来作为步骤七构建的深度学习模型的训练语料,进行参数学习;选取最优效果所对应的模型作为非显式篇章关系的分类模型。
其次是实际分析方法,即本发明的实际应用方法,具体步骤如下:
一、语料预处理方法,实现步骤如下:
(1)对于输入文本,首先按照表示句子结束的标点符号进行断句,此处可以采用stanfordparser进行,然后对于每一个句子,使用stanfordparser进行词性标注、句法分析,并将生成结果存入文本作为如图2所示方法的输入。
二、显式篇章关系识别,如图2所示,显式篇章关系识别部分包括篇章连接词识别、论元划分、显式篇章关系识别三个子部分,这三个部分都是以篇章连接词为主线进行串联。实现步骤如下:
(1)篇章连接词识别,扫描步骤一中的输入文本,获取所有篇章连接词候选,为每一个篇章连接词候选提取特征(与训练步骤三对应的篇章连接词识别部分相同),将提取的特征保存到文本中使用训练步骤五生成的相应分类模型进行分类,选取正确的篇章连接词并保存;
(2)论元位置划分,针对(1)中获取到的正确篇章连接词,提取所需特征(与训练步骤三对应的论元位置划分部分相同),将提取的特征保存到文本中使用训练步骤五生成的相应分类模型进行分类并保存分类结果;
(3)论元提取,针对(2)的分类结果,就ps的情况,由于是发生在两个句子之间,因此直接将篇章连接词所在句作为arg2,其前一句作为arg1,保存结果;就ss的情况,采用与训练步骤三相对应的相同的论元候选提取规则对步骤一生成的对应句法树提取论元候选,为每一个论元候选提取特征(与训练步骤三对应的论元候选分类部分相同),使用训练步骤五生成的相应分类模型进行分类获取论元候选类别(arg1、arg2、none),按照对应类别组合形成arg1、arg2,保存结果。
(4)显式篇章关系识别,针对(1)获取到的正确篇章连接词,提取所需特征(与训练步骤三对应的显式篇章关系识别部分相同),将提取的特征保存到文本中使用训练步骤五生成的相应分类模型进行分类以确定篇章连接词所表示的篇章关系并保存分类结果;
(5)以(1)中生成篇章连接词为主线,将其对应的论元范围、显式篇章关系类别组合成结构体保存。
三、非显式篇章关系识别,如图2所示,实现步骤如下:
(1)如图3所示,以步骤一中的生成文本中不属于显式篇章关系的相邻句对为输入,利用训练步骤八所保存的深度学习模型对其进行分类以确定其篇章关系;
(2)由于英语中非显式篇章关系只发生在句子之间,因此,以存在非显式篇章关系的句对中前一句为arg1、后一句为arg2;
(3)将(1)和(2)的生成结果以结构体形式组合保存。
四、识别完成。将步骤二与步骤三所保存结构体组合输出至文本中,作为输出。
实验结果如表1所示:
上表是本发明最终的实验结果,其中,“opt”是当前已存在的精度最好的英语篇章分析系统。本发明在显式篇章关系识别中,将句法特征和扁平特征分而治之,不仅可以大大降低特征向量维度,而且可以充分表达特征中的细节信息,因此提高了显式篇章关系识别各部分的精度;而在非显式篇章关系识别中,通过仔细分析非显式篇章关系识别的特点,运用词对特征的优势,结合深度学习思想,构建了一个深度学习模型,同样使得非显式篇章关系识别的精度得以提高。系统中各模块的精度的提高使本发明的最终精度得以优于opt。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!