一种基于负载预测的DockerSwarm集群资源调度优化方法与流程
本发明属于计算机系统虚拟化技术领域,更具体地,涉及一种基于负载预测的dockerswarm集群资源调度优化方法。
背景技术:
docker自发布以来就立即在云计算领域引起了高度关注,社区异常活跃,成为目前最炙手可热开源软件之一。业界巨头如微软、谷歌、ibm等纷纷与docker建立合作,并在各自相应平台上支持docker。docker的发展势头相当迅猛。简单地讲,docker就是一个应用程序运行容器,可将应用及所有依赖打包进一个标准的单元中,如同集装箱一样。docker的功能类似虚拟机,但是要比虚拟机启停更快、更加节省计算机的资源。
docker集群管理工具swarm的出现进一步促进了docker在集群中的使用,为云计算平台及数据中心的虚拟化方法提供了一种新的思路。但是目前docker在下面两个方面还存在一些问题:
1、docker的资源限制:
docker通过cgroup(控制组)来控制容器使用的资源配额,包括cpu、内存、磁盘三大方面,基本覆盖了常见的资源配额和使用量控制。但目前docker只是用了cgroup的一部分子系统,实现对资源配额和使用的控制。通常用法是在启动一个容器时,通过设置权重或者上限等参数,来达到资源控制的作用。在集群中,多个容器运行在一个节点上,它们之间的资源分配策略分为两种:在资源利用不饱和时,各个容器尽最大努力使用资源,但受上限限制;而当资源利用饱和时,即容器开始竞争资源,则按分配的权重来进行资源分配,也受到上限的限制。
这样的资源调度方法在灵活性上有所欠缺,不能动态改变容器的资源权重和限制。这样可能会造成资源浪费和缺乏反馈的资源竞争:在资源利用不饱和的时候,部分容器运行时需要更多的资源,但受到了资源上限的限制,没有充分利用节点资源;在资源利用饱和时,有的容器对某些资源的需求比较大,但权重和上限都限制了它对资源的使用,而其他一些容器则对资源的需求不是很迫切,这时需要动态调整容器的资源权重和上限,达到总体提高容器运行性能的效果。
2、dockerswarm集群的调度策略:
目前swarm内置的调度策略有三种,分别是random(随机)、spread(扩散)和binpack(装箱):random调度策略是随机选择容器生成的位置,一般用于调试集群;而用spread和binpack调度策略时,主要的依据是swarm统计出的每个物理节点的内存和cpu的分配情况,其中,使用spread调度策略时,swarm会按照各个node节点的总的内存和cpu的比例来使容器分散在每一个节点上;使用binpack调度策略时,swarm会先把一个node节点的资源使用完后,再将容器生成在其他可用的节点上。
目前使用的最多的就是spread策略,但它也存在着不足之处:在分配新容器时,只关注节点上的内存和cpu占用比例,没有考虑节点的i/o性能,也没有考虑节点上容器的资源偏向特性,例如新容器是cpu密集型的,而正好有满足条件的节点上面也都是cpu密集型容器,这样就很可能在之后出现严重的cpu。理想的情况是节点上,有着各种资源偏向的容器,例如把cpu密集型和i/o密集型的容器放在一个节点上,这样可以大大减少竞争资源的可能,并能提高节点的资源利用率。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种基于负载预测的dockerswarm集群资源调度优化方法,其目的在于采取arima-rbf模型来对容器的资源历史使用量进行建模预测,获取资源未来使用量,集合资源目前使用情况对资源使用上限和资源使用权限进行调整;并根据容器的历史资源使用量来确定容器对资源的使用;并在集群启动一个新容器时根据该容器和满足容器资源需求的节点集上的资源使用偏向程度,选择一个加入该容器后资源使用偏向最均衡的节点来部署这个新容器,由此提高容器性能,提高了节点资源利用率和节点效益的作用。
为实现上述目的,按照本发明的一个方面,提供了一种基于负载预测的dockerswarm集群资源调度优化方法,所述方法包括:
(1)通过dockerdaemon的api接口函数,周期性地收集容器的资源历史使用量;
(2)对所述资源历史使用量按时间序列后利用arima模型进行建模预测,得到容器资源未来使用量,再用rbf神经网络对预测结果的误差进行建模预测,得到资源未来使用量的预测误差,再将容器资源未来使用量和预测误差结合,得到修正后容器资源未来使用量;
(3)将容器资源未来使用量、容器资源目前使用量和资源限制量进行对比后,进行动态调整容器对资源的限制量和容器对资源的权重;
(4)根据容器的资源历史使用量确定容器对资源的使用偏向程度;
(5)分配容器到节点上时,根据容器对资源的使用偏向程度筛选出部署该容器的节点。
进一步地,其特征在于,所述步骤(1)具体为在集群的每个节点上,实时获取每个容器的cpu、内存和带宽的历史使用量,按时间排序并生成相应的时间序列。
进一步地,其特征在于,所述步骤(2)具体包括:
(21)对所述资源历史使用量按时间序列,再对资源历史使用量的时间序列进行多次差分得到稳定的时间序列;
(22)对稳定的时间序列进行零均值化,再计算其自相关函数和偏自相关函数并识别出arima模型和估计参数,计算出arima模型的阶数和参数;
(23)对arima模型进行有效性检验,通过检验后,利用该模型进行预测,得到容器的资源未来使用量;
(24)对比预测后一段时间内容器的资源使用量和预测得到此段时间的资源未来使用量,得到预测误差,使用rbf神经网络对误差进行建模,得到误差预测;
(25)将容器资源未来使用量和误差预测结合,得到修正后容器资源未来使用量。
进一步地,其特征在于,所述步骤(3)具体包括:
(31)从容器s的r资源开始遍历,检查节点上r资源占用率是否饱和,若不饱和,进入步骤(32);否则进入步骤(33);
(32)比较容器s的rfuture和rnlimit,若rfuture大,则使rnlimit=rfuture;其中,rfuture表示容器的r资源未来使用量;rnlimit表示容器对r资源的限制量;进入步骤(34);
(33)检测r资源的调度策略中是否有权重这一属性,若没有,则等待下一轮调度;否则比较容器s的rfuture、rcur和rnlimit,若rfuture>rcur=rnlimit,则使rnlimit=rfuture;其中,rcur表示容器的r资源当前使用量;
(34)将rfuture与rnwgt/rallwgt·rall的比值记为
(35)将更新后的rnlimit和rnwgt,传递到dockerdaemon中。
进一步地,其特征在于,所述步骤(4)具体为:
容器对资源的使用偏向程度由偏向参数m确定,
其中,ε为资源阈值;ni为i时刻资源的使用率;p表示p个时刻;f()为指示函数,若x>0时,则f(x)=1,否则f(x)=0;偏向参数m越大,说明该容器对资源越偏向。
进一步地,其特征在于,所述步骤(5)具体包括:
(51)在集群部署一个新的容器时,先检测这个容器之前是否分析过资源偏向程度;若是则筛选出能够运行该容器的节点集,计算节点集中所有节点的balance;
其中,mi是所有容器对资源i的偏向参数之和;
(52)选出balance最小的节点,作为部署节点。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有以下技术特征及有益效果:
(1)本发明技术方案使用了arima-rbf模型,可以根据容器的资源使用历史,预测出未来的资源使用量,并及时调整各个容器的资源限制和权重,能够起到提高容器性能的作用;
(2)本发明技术方案在集群中各个节点中分析出该节点的资源使用偏向,并将其资源使用偏向纳入到容器调度策略中,尽量避免了容器在节点上的资源竞争,提高了节点资源利用率和节点效益的作用;
(3)本发明技术方案实时根据资源使用情况进行资源调度,具有容器资源调度实时性的优点。
附图说明
图1是本发明技术方案集群级的功能示意图;
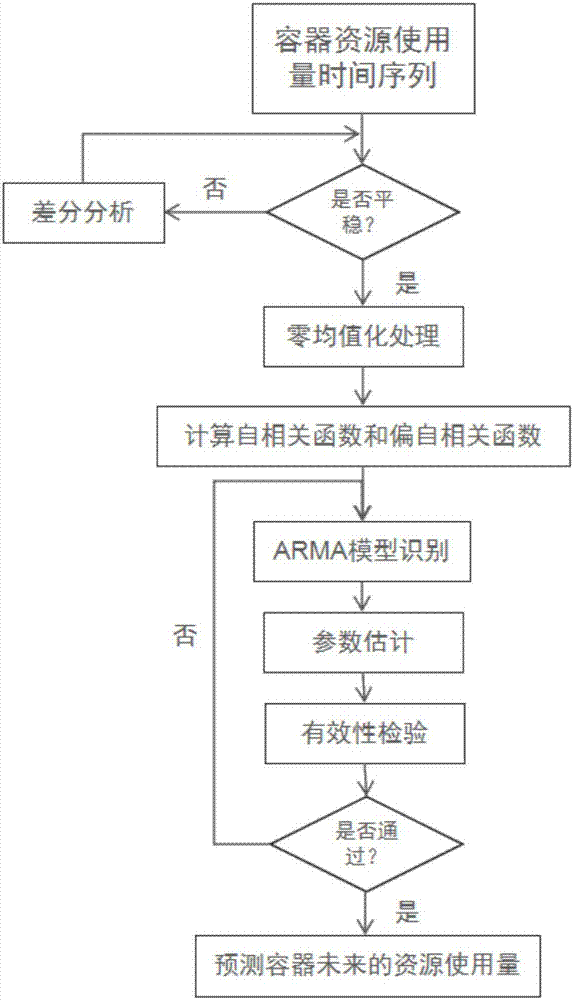
图2是本发明技术方案步骤(2)的流程图;
图3是本发明技术方案步骤(3)的流程图;
图4是本发明技术方案步骤(5)的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
如图1所示,本发明集群资源调度优化方法包括以下步骤:
(1)通过dockerdaemon的api接口函数,周期性地收集容器的资源历史使用量;具体为在集群的每个节点上,实时获取每个容器的cpu、内存和带宽的历史使用量,按时间排序并生成相应的时间序列。
(2)对所述资源历史使用量按时间序列后利用arima模型进行建模预测,得到容器资源未来使用量,再用rbf神经网络对预测结果的误差进行建模预测,得到资源未来使用量的预测误差,再将容器资源未来使用量和预测误差结合,得到修正后容器资源未来使用量;
如图2所示为步骤(2)具体工作流程,具体包括:
(21)对所述资源历史使用量按时间序列,再对资源历史使用量的时间序列进行多次差分得到稳定的时间序列;
(22)对稳定的时间序列进行零均值化,再计算其自相关函数和偏自相关函数并识别出arima模型和估计参数,计算出arima模型的阶数和参数;
(23)对arima模型进行有效性检验,通过检验后,利用该模型进行预测,得到容器的资源未来使用量;
(24)对比预测后一段时间内容器的资源使用量和预测得到此段时间的资源未来使用量,得到预测误差,使用rbf神经网络对误差进行建模,得到误差预测;
(25)将容器资源未来使用量和误差预测结合,得到修正后容器资源未来使用量。
(3)将容器资源未来使用量、容器资源目前使用量和资源限制量进行对比后,进行动态调整容器对资源的限制量和容器对资源的权重;
如图3所示为步骤(3)具体工作流程,具体包括:
(31)从容器s的r资源开始遍历,检查节点上r资源占用率是否饱和,若不饱和,进入步骤(32);否则进入步骤(33);
(32)比较容器s的rfuture和rnlimit,若rfuture大,则使rnlimit=rfuture;其中,rfuture表示容器的r资源未来使用量;rnlimit表示容器对r资源的限制量;进入步骤(34);
(33)检测r资源的调度策略中是否有权重这一属性,若没有,则等待下一轮调度;否则比较容器s的rfuture、rcur和rnlimit,若rfuture>rcur=rnlimit,则使rnlimit=rfuture;其中,rcur表示容器的r资源当前使用量;
(34)将rfuture与rnwgt/rallwgt·rall的比值记为
(35)将更新后的rnlimit和rnwgt,传递到dockerdaemon中。
(4)根据容器的资源历史使用量来确定容器对资源的使用偏向程度;
具体为容器对资源的使用偏向程度由偏向参数m确定,
其中,ε为资源阈值,0<ε<1,ε=0.7;ni为i时刻资源的使用率;p表示取p个时刻;f()为指示函数,若x>0时,则f(x)=1,否则f(x)=0;偏向参数m越大,说明该容器对资源越偏向。
(5)在集群管理器分配容器到节点上时,根据容器对资源的使用偏向程度筛选出部署该容器的节点;
如图4所示为步骤(5)具体工作流程,具体包括:
(51)在集群部署一个新的容器时,先检测这个容器之前是否分析过资源偏向;若有则筛选出能够运行该容器的节点集,计算节点集中所有节点的balance;
其中,mi是所有容器对资源i的偏向参数之和;
(52)选出balance最小的节点,作为部署节点。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!