空间极大亚频繁co‑location模式挖掘方法与流程
本发明属于空间并置模式挖掘
技术领域:
,特别是涉及一种空间极大亚频繁co-location模式挖掘方法。
背景技术:
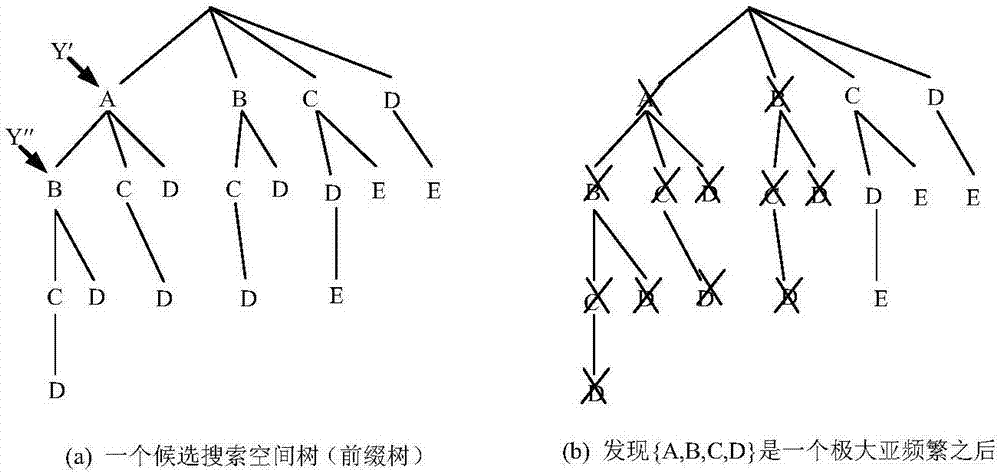
:随着基于位置的服务和空间信息处理技术的发展,产生了大量的带有空间信息的数据,例如经过预处理后的遥感数据、医学图像处理数据和超大规模集成电路芯片设计数据等,这使得如何从空间数据中发现有用的知识变得越来越重要。空间数据挖掘是一种技术,它将传统的空间数据分析方法与处理海量多维数据的复杂算法相结合。空间数据挖掘技术主要包括空间聚类、空间分类、空间关联规则挖掘、空间异常检测和空间趋势分析等。空间并置模式(spatialco-locationpatterns)挖掘是空间关联挖掘的一个特例。空间co-location模式是空间特征的一个子集,他们的实例在空间中频繁关联。空间co-location模式挖掘在许多应用领域发挥重要作用,例如地球科学、公共卫生、公共交通、基于位置的服务、个性化市场策略及军事策略计划等。然而,回顾现有的空间co-location模式方法,我们看到他们只考虑了特征实例的团关系,并没有注意到许多形成不了团关系的空间模式同样很重要。空间co-location模式的例子如:西尼罗河病毒往往发生在蚊子泛滥、饲养家禽的区域;植物学家发现“半湿润常绿阔叶林”生长的地方80%有“兰类”植物生长。在shekhar和huang提出的关于挖掘频繁co-location模式的传统框架里,co-location模式的频繁性度量标准是基于空间邻近关系的团实例来定义的。具体而言,一个co-location模式c的频繁性取决于c中最小的特征参与率,而c中一个特征f的参与率pr(f,c)是指特征f参与到模式c的团实例中的不同实例个数占f总实例个数的比例。例如图1中,我们给出了3个空间特征{a,b,c},a.i表示特征a的第i个实例,而用线相连的两个实例表示它们的距离小于等于给定的距离阈值,即两实例相邻。假如我们设定最小频繁性阈值,即min_prev=0.4,那么在图1中,co-location模式{a,b,c}不是频繁的。因为对于模式{a,b,c}而言,它只有一个团实例{a.1,b.1,c.1},因此它的频繁性度量值只有0.2<0.4。由于此研究领域具有较高的理论研究与实际应用价值,国内外许多研究者提出了不同的co-location模式挖掘算法,但大致都包含两个方面的工作:“产生”与“测试”。首先,我们要产生候选模式;其次,测试生成的候选模式是否是频繁的。在图1中,我们可以看到特征a有3/4的实例是和特征b的实例、特征c的实例相邻近的;特征b有2/5的实例是和特征a的实例、特征c的实例相邻近的;而特征c也有2/3的实例是和两个特征的实例相邻近的。也就是说,在模式{a,b,c}中,每个特征至少有40%的实例是和其他特征的实例相邻近的。但是如果按照传统的co-location模式挖掘框架,即基于团实例的频繁性度量准则,将挖掘不到如图1中特征a,b和c所具有的如上所述的空间关联关系。进一步地,在传统框架中,挖掘的频繁co-location模式仅仅考虑了团实例作为频繁性的度量标准。但是,像“特征a的实例存在的邻近区域内也存在特征b和c的实例”这样的陈述,并没有指明b和c的实例必须是邻近的。因此,需要提出新的空间模式概念(亚频繁co-location模式)来阐述这样的情况,同时设计新的方法来挖掘相应的模式。技术实现要素:本发明实施例的目的在于提供一种空间极大亚频繁co-location模式挖掘方法,以实现有效地挖掘空间数据集中的极大亚频繁co-location模式。本发明所采用的技术方案是,空间极大亚频繁co-location模式挖掘方法,按照以下步骤进行:步骤1,在空间数据集中,用f={f1,f2,…fn}表示n个特征的集合,用s表示f的实例集,其中,每个空间实例用三元组<实例编号,空间位置,实例所属特征>描述;空间邻近关系描述空间实例之间的一种空间关系,用r表示,且r是对称的和自反的;步骤2,使用星型邻居关系来物化空间实例之间的邻近关系;步骤3,给定一个亚频繁co-location模式l,v∈{1,2,…,n},如果c的直接超集不是亚频繁的,那么co-location模式c是一个极大亚频繁co-location模式;步骤4,然后通过基于前缀树的方法或基于划分的方法有效地挖掘一个空间数据集中的所有极大亚频繁co-location模式。本发明的特征还在于,进一步的,所述步骤4中,基于前缀树的方法按照以下步骤进行:预处理和生成候选模式:给定一个空间数据集和一个邻近关系阈值作为输入,首先寻找所有的邻近实例对,即2阶co-location实例集si2,接下来,计算它们的星型参与度spi,并找出spi值不小于用户指定的亚频繁阈值min_sprev的所有2阶亚频繁co-location模式,并将它记为scp2的值,基于scp2,通过字典有序寻找极大团的方法,生成所有极大亚频繁co-location候选模式;挑选出l阶co-location候选模式:把l设置为最长候选模式的阶数lmax,从候选模式池中选出l阶候选模式集cl;计算l阶亚频繁co-location模式:对于cl中的每一个候选模式c,基于2阶co-location实例集si2,计算每个候选模式c的spi(c)值;当且仅当spi(c)≥min_sprev时,把这个模式c插入到l阶极大亚频繁模式集scpl中;更新结果集并进行剪枝:更新极大亚频繁co-location模式的结果集mscp;并基于scpl中模式对剩余候选模式实施子模式剪枝过程;最后循环处理过程,直到l=3或者没有可处理的候选模式为止,最后,返回极大亚频繁co-location模式的最终结果集mscp。进一步的,所述计算l阶亚频繁co-location模式中,计算每个候选模式c的spi(c)值的方法如下:给定一个空间数据集的2阶co-location模式实例,那么k阶co-location模式c={f1,…fk}的星型参与度spi(c)的计算方式如下:其中spins(fi,c)是c中特征fi的星型参与实例集,是特征fi的实例的个数。进一步的,所述步骤4中,基于划分的方法按照以下步骤进行:预处理:先找出2阶co-location模式的实例集si2,并计算所有的2阶亚频繁co-location模式集scp2,然后,基于划分1和划分2,得到有序字符串集l;获取以“i”为头的有序字符串:先把l中以“i”为头的有序字符串放到li中,并将以“i”为头的极大亚频繁co-location模式集scpi的值设为“null”,标志数组b初始化为0;当b中对应的模式是亚频繁时,赋值为1;否则,赋值为-1;而“i”则从第一个特征开始,迭代至最后一个特征;使用核模式策略处理li中的有序字符串:对于li中的每个有序字符串c,通过递归过程cpd(c,|c|)计算c中极大亚频繁co-location模式集hsc,然后,把得到的结果集hsc合并到以“i”为头的scpi中;所述递归过程cpd(c,|c|):若c已被识别过,那么递归过程直接返回;如果处理的模式c是3阶的,那么应用引理2直接判定c是否是亚频繁的,然后返回;否则,递归调用cpd判定c的两个核模式c′和c″是否是亚频繁的;当c的两个核模式c′和c″都是亚频繁模式时,用核模式方法判定c是否是亚频繁模式,当c不是亚频繁时,处理c中以“i”为头的其他子模式,否则直接标记模式c,然后处理c中以“i”为头的其他子模式;更新结果集并剪枝:更新极大亚频繁结果集mscp,并对集合l中所有属于scpi中模式的子模式进行剪枝处理;返回最终结果集:继续处理以下一个特征为头的有序字符串,直到l中不存在待处理的有序字符串为止,最后,返回极大亚频繁co-location模式的最终结果集mscp。进一步地,所述预处理步骤中,得到有序字符串集l的步骤是:划分1(partition_1):通过等价关系“=head”,将2阶亚频繁co-location模式集scp2划分成有序字典序字符串集l1,即:根据2阶亚频繁模式的头字母(特征),划分scp2,然后合并同一类(相同头字母)的模式形成字典序字符串;划分2(partition_2):根据2阶非亚频繁co-location模式,对l1中的有序字符串进行进一步划分,使每一个有序字符串的所有2阶子串均是亚频繁的。l1被进一步划分直到有序字符串中不再含有2阶非亚频繁co-location模式时,得到的就是有序字符串集l。本发明的有益效果:(1)提出亚频繁co-location模式新概念,相比于频繁co-location模式,亚频繁co-location模式是一类更一般的,具有更广泛用途的空间模式;(2)提出两个有效的挖掘算法,与改进过的join-less算法相比(join-less算法是目前已有挖掘极大频繁co-location模式算法中较好的算法),本算法更高效。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1是空间数据分布示例图。图2a是一个候选搜索空间树,图2b是剪枝示例图。图3是基于划分方法中的核心过程(称为核模式方法)的示意图。图4是本发明实施例中{a,b,c,d,g}和它的所有“a”为头的子集。图5是二维空间的一个珍稀植物分布数据集。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明提出了空间亚频繁co-location模式和空间极大亚频繁co-location模式新概念,并给出了两种挖掘极大亚频繁co-location模式的新方法,它们分别是:基于前缀树的算法(prefix-tree-basedalgorithm,ptba)和基于划分的算法(partition-basedalgorithm,pba)。首先,介绍极大亚频繁co-location模式的基本概念并讨论它的单调性。在空间数据集中,通常用f={f1,f2,…fn}表示n个特征的集合,用s表示f的实例集,其中,每个空间实例用三元组<实例编号,空间位置,实例所属特征>描述。空间邻近关系描述了空间实例之间的一种空间关系,我们用r表示,且r是对称的和自反的,在这里满足空间关系指的是实例间的欧几里德距离小于等于一个距离阈值d。空间co-location模式是空间特征的一个子集,模式我们使用在join-less算法中提到的星型邻居关系来物化空间实例之间的邻近关系。一个空间实例的星型邻居是由中心实例和与它有邻近关系的邻居实例组成的集合。具体定义如下:定义1.(星型邻居实例,starneighborhoodsinstance,snsi):snsi(oi)={oj|distance(oi,oj)≤d,d为距离阈值}表示oi的星型邻居实例。snsi(oi)是由oi和与oi的距离小于等于d的其他空间特征实例共同构成的一个集合。例如,在图1中,snsi(a.1)={a.1,b.1,c.1},snsi(b.3)={a.4,b.3,c.2,c.3}。基于星型邻居关系,我们将进一步给出星型参与实例、星型参与率和星型参与度等概念来描绘一个co-location的亚频繁性。定义2.(星型参与实例,starparticipationinstance,spins):spins(fi,c)={oi|oi是fi的实例且snsi(oi)包含了c的所有特征}是c中特征fi的星型参与实例,也就是说,spins(fi,c)是由fi的实例所构成的集合,且对于此集合中的每个实例,它的星型邻居实例集应包含模式c中的所有特征的实例。定义3.(星型参与率,starparticipationratio,spr):是co-location模式c中特征fi的星型参与率,其中是特征fi的实例集。也就是说,spr(fi,c)是指模式c中特征fi不同的星型参与实例个数占fi总实例数的比例。定义4.(星型参与度,starparticipationindex,spi):spi(c)=minf∈c{spr(f,c)}是co-location模式c的星型参与度。也就是说,spi(c)是c中所有特征fi的星型参与率的最小值。定义5.(亚频繁co-location模式,sub-prevalentco-locationpatterns,scp):co-location模式c是亚频繁的,当且仅当它的星型参与度不小于给定的亚频繁阈值min_sprev,也就是说,spi(c)≥min_sprev。例如,从图1中可以得到模式{a,b,c}中特征a的星型参与实例spins(a,{a,b,c})={a.1,a.3,a.4},spins(b,{a,b,c})={b.1,b.3},spins(c,{a,b,c})={c.1,c.2},于是spr(a,{a,b,c})=3/4。这是因为,特征a的4个实例中有3个实例出现在了a的星型参与实例中。同理,spr(b,{a,b,c})=2/5,spr(c,{a,b,c})=2/3。因此,spi({a,b,c})=min{3/4,2/5,2/3}=2/5=0.4。此时,如果我们设定min_sprev=0.4,那么{a,b,c}便是一个空间亚频繁co-location模式。scps(scps是多个亚频繁co-location模式)具有如下性质:引理1(spr和spi的单调性,monotonicityofsprandspi)给定两个co-location模式c和c′,且那么任取特征f∈c′,都满足spr(f,c′)≥spr(f,c)。因此spi(c′)≥spi(c)。通过引入亚频繁这一概念,我们会挖掘到传统频繁概念挖掘不到的co-location模式。当然,不可避免地,最终挖掘的结果集也将会很大,且由于引理1,结果集的模式之间也会存在相互包含的情况。为了解决这个问题,我们引入极大亚频繁co-location模式。定义6.(极大亚频繁co-location模式,maximalsub-prevalentco-locationpatterns,mscp):给定一个亚频繁co-location模式l,v∈{1,2,…,n},如果c的直接超集(直接超集是特征数比c多一个)不是亚频繁的,那么co-location模式c是一个mscp。极大亚频繁模式集合是亚频繁模式集合的精简集。它是能够推导出全部亚频繁co-location模式的最小集。下面介绍我们提出的两个挖掘算法:一、基于前缀树的算法(prefix-tree-basedalgorithm,ptba)首先,我们注意到空间实例的星型邻居关系是对称的,也就是说,如果oj∈snsi(oi),那么oi∈snsi(oj)。因此,算法的起始工作便是收集互为邻居的实例对,然后选出不小于亚频繁性阈值min_sprev的所有2阶亚频繁co-location模式。其次,根据引理1,从2阶亚频繁co-location模式集中生成高阶的亚频繁co-location候选模式,方法是识别在2阶亚频繁关系下能够形成团的特征集。例如,如果有一个2阶亚频繁co-location模式集scp2={{a,b},{a,c},{a,d},{b,c},{b,d},{c,d},{c,e},{d,e}},那么,特征集{a,b,c,d}在2阶亚频繁关系下形成了团,所以,它是一个4阶候选亚频繁模式。然而,由于2阶亚频繁co-location模式{b,e}并不属于scp2,所以特征集{b,c,d,e}不是一个4阶亚频繁候选模式。这里,我们应用一种字典有序寻找极大团的方法,生成全部高阶的亚频繁co-location候选模式。对于scp2={{a,b},{a,c},{a,d},{b,c},{b,d},{c,d},{c,e},{d,e}},我们得到所有候选模式集{{abcd,abc,abd,acd,ac,ad},{bcd,bc,bd},{cde,ce},{de}}。为了在挖掘过程中进行动态剪枝,我们把所有生成的候选模式组织成一棵候选搜索空间树(前缀树)。在前缀树中,每个候选模式都有自己的分支且新的分支会共享相同的前缀。如图2所示,候选模式{a,b,c,d}生成候选模式搜索空间树的第一条分支,而第二个候选模式{a,b,c}由于可以共享前缀,因此没有生成新的分支。同时,由于{a,b,d}只能共享两个前缀,所以生成了一个新分支。标识某个结点的特征集被称为该结点的头(head),而后面可能的扩展被称为该结点的尾。如图2所示,结点y′和y″的头分别是{a}和{a,b},而他们的尾分别是{b,c,d}和{c,d}。y′的“头”并“尾”(headuniontail,hut)是{a,b,c,d}。在候选搜索空间树中,我们以最长l=lmax的co-location模式开始,检测其是否是极大亚频繁co-location模式。一旦算法检测到了某个候选模式是极大亚频繁的,那么算法便启动剪枝过程。剪枝过程以广度优先算法的方式检查每个结点的“头”并“尾”(hut)是否是已识别极大亚频繁模式的子集。如果是,那么以这个结点为根节点的整个子树将被剪掉。如图2所示,假设{a,b,c,d}是一个极大亚频繁co-location模式,那么,算法以广度优先的方式在搜索空间树中对候选模式进行剪枝。在第一层,结点a的hut是{a,b,c,d},由于它是{a,b,c,d}的子集,所以算法剪掉以a为根结点的子树。接下来看同在第一层的结点b,它的hut是{b,c,d}。由于这个模式依旧是{a,b,c,d}的子集,所以算法剪掉这棵子树,以此类推,检查完第一层所有结点后,继续检查下一层,直到得到如图2(b)中所示结果。上述过程直到在候选搜索空间树中,没有可处理的候选模式为止。在上述方法中,如何基于2阶co-location模式的实例(邻居实例对),计算一个候选模式c的星型参与度spi(c)(即亚频繁性)?引理2回答了这个问题。引理2(k阶co-location模式的亚频繁性度量,thesub-prevalencemeasureofk-sizeco-locations(k>2))给定一个空间数据集的2阶co-location模式实例,那么k阶co-location模式c={f1,…fk}的星型参与度spi(c)的计算方式如下:其中spins(fi,c)是c中特征fi的星型参与实例集,是特征fi的实例的个数。例如,对于图1,若假设候选模式c={a,b,c},那么spi(c)=min{|{a.1,a.3,a.4}∩{a.1,a.3,a.4}|/4,|{b.1,b.2,b.3}∩{b.1,b.3}|/5,|{c.1,c.2}∩{c.1,c.2,c.3}|/3}=min{3/4,2/5,2/3}=0.4.ptba方法是一种典型的候选“产生”与“测试”方法。由于这个方法的本质是依托候选模式搜索空间树(前缀树),所以称这个算法为基于前缀树的算法。具体算法如下:input:f={f1,…,fn}:空间特征集;s:空间实例集;d:空间邻近关系距离阈值;min_sprev:最小亚频繁性阈值;output:mscp:所有极大亚频繁co-location模式集;variables:si2:2阶co-location实例集;l:有趣co-location模式的长度;c:所有候选模式集;cl:长度为l的候选模式集;spi:星型参与度;lmax:最长候选模式c的长度;scpl:l阶极大亚频繁co-location模式集;stepspreprocessandcandidategeneration(预处理和候选模式生成)预处理和生成候选模式(step1-4):给定一个空间数据集和一个邻近关系阈值作为输入,首先寻找所有的邻近实例对(所有的2阶co-location实例)。接下来,计算它们的星型参与度(spi),并找出spi值不小于用户指定的亚频繁阈值min_sprev的所有2阶亚频繁co-location模式,并将它记为scp2的值。基于scp2,通过字典有序寻找极大团的方法,生成所有极大亚频繁co-location候选模式。挑选出l阶(l从最大阶lmax到2阶)co-location候选模式(step5-8):首先,把lmax设置为最长候选模式的阶数(因为挖掘从最大阶lmax到2阶),因为极大亚频繁co-location模式的挖掘是从l=lmax开始的。接下来就是从候选模式池中选出l阶候选模式集cl。计算l阶亚频繁co-location模式(step9-13):对于cl中的每一个候选模式c,我们基于2阶co-location实例集si2,通过使用引理2给出的方法,计算每个候选模式c的spi(c)值。当且仅当spi(c)≥min_sprev时,便把这个模式c插入到l阶极大亚频繁模式集scpl中(即从候选模式池中选出l阶候选模式集scpl)。更新结果集并进行剪枝(step14-15):更新极大亚频繁结果集mscp,并基于scpl中模式对剩余候选模式实施子模式剪枝过程。返回最终结果集(step16-17):循环7-17步的处理过程,直到l=3或者没有可处理的候选模式为止。最后,返回极大亚频繁co-location模式的最终结果集mscp。二、基于划分的算法(partition-basedalgorithm,pba)基于划分的方法(partition-basedalgorithm,pba)采用的是分治策略。首先,通过等价关系“=head”把2阶亚频繁co-location模式集划分成有序字典序字符串集。然后,基于一种核模式方法分别挖掘每个字符串。定义7(划分模式和核模式,partitionpattern(pp)andcorepattern(cp))包含于一个co-location模式c中一个2阶模式被称为c的一个划分模式(pp),当且仅当这个2阶模式的星型参与度(spi)是c中所有2阶co-location模式spi值中的最大者。而由划分模式划分得到的c的两个子模式,则被称为c的核模式(cp)。例如,如果co-location模式c={a,b,c,d,g}的划分模式为{c,d},那么c的核模式便是{a,b,c,g}和{a,b,d,g}。由于划分模式的spi是c中所有2阶模式当中spi值的最大者,所以c是否是亚频繁的就很有可能取决于这些关键的核模式。核模式方法:若一个l阶co-location模式c={f1,…fl},它的划分模式为{fl-1,fl},那么c有两个l-1阶核模式{f1,…,fl-2,fl-1}和{f1,…,fl-2,fl}。如果这两个核模式是亚频繁的,且满足以下两个条件,那么我们可以判定模式c是亚频繁的。条件(1):|spins(fl-1,{f1,…,fl-2,fl-1})∩spins(fl-1,{fl-1,fl})|/|sfl-1|≥min_sprev且|spins(fl,{f1,…,fl-2,fl})∩spins(fl,{fl-1,fl})|/|sfl|≥min_sprev条件(2):事实上,spi(c)=min{|spins(f1,{f1,…,fl-2,fl-1})∩spins(f1,{f1,…,fl-2,fl})|/|sf1|,…|spins(fl-2,{f1,…,fl-2,fl-1})∩spins(fl-2,{f1,…,fl-2,fl})|/|sfl-2|,|spins(fl-1,{f1,…,fl-2,fl-1})∩spins(fl-1,{fl-1,fl})|/|sfl-1|,|spins(fl,{f1,…,fl-2,fl})∩spins(fl,{fl-1,fl})|/|sfl|}。图3形象地描述了这个方法的思想。两个核模式{f1,…,fl-2,fl-1}和{f1,…,fl-2,fl}的识别,可以使用核模式方法递归地处理它们。事实上,pba方法采用的是一种自底向上的迭代策略,它从识别3阶模式开始,接着4阶,…,直到l阶模式。下面将详细地阐述pba方法是如何工作的。假设某个空间数据集中包含7个空间特征,它们分别是{a,b,c,d,e,f,g},且它的2阶亚频繁co-location模式集scp2={{a,b},{a,c},{a,d},{a,f},{a,g},{b,c},{b,d},{b,g},{c,d},{c,f},{c,g},{d,e},{d,f},{d,g},{e,f}}。首先,通过等价关系“=head”,将scp2划分成有序字典序字符串集,并将此结果集记为l1。那么,l1={δhead(a)=abcdfg,δhead(b)=bcdg,δhead(c)=cdfg,δhead(d)=defg,δhead(e)=ef,δhead(f)=f,δhead(g)=g}。我们称此划分为划分1(partition_1)。然后,根据2阶非亚频繁co-location模式,我们对l1中的有序字符串进行进一步划分。而在我们的例子中,2阶非亚频繁co-location模式集因此,bf将有序字符串δhead(a)=abcdfg进一步划分成两个字符串,它们分别是:abcdg和acdfg。之后,我们继续分别划分这两个子字符串直到有序字符串中不再含有非亚频繁co-location模式或者它的阶小于等于2为止。那么,l1将会被l={abcdg,acdfg,bcdg,cdfg,defg,ef}取代。此基于非亚频繁模式的划分被称为划分2(partition_2)。接下来,我们通过使用核模式方法一个一个处理l中的字符串以得到全部的极大亚频繁co-location模式。对于我们的例子,首先考虑有序字符串“abcdg”。假设{c,d}是c={a,b,c,d,g}的划分模式,那么c的核模式是{a,b,c,g}和{a,b,d,g}。继续划分{a,b,c,g},将会得到3阶的核模式{a,b,c}和{a,b,g};而划分{a,b,d,g},则会得到{a,b,d}和{a,b,g}。我们通过划分模式得到核模式的过程称为划分3(partition_3)。图4中实线部分清楚地展示了将{a,b,c,d,g}通过划分3得到的划分结果。使用引理2我们可以直接计算3阶核模式的星型参与度(spi值),从而判定其是否是亚频繁模式。而后,基于3阶核模式与核模式方法则可以判定相应的4阶核模式,而后再5阶模式。例如:假设两个3阶核模式{a,b,c}和{a,b,g}都是亚频繁的,而通过计算,可得它们是满足条件(1)和条件(2)的,那么,我们可以确定4阶co-location模式{a,b,c,g}是亚频繁的。类似的,我们可以判定{a,b,d,g}是否是亚频繁的。而后,通过{a,b,c,g}和{a,b,d,g},我们又可以判定{a,b,c,d,g}的亚频繁性。而一旦5阶模式{a,b,c,d,g}不是亚频繁的,那么除去4阶核模式,其他具有相同头(即“a”)的4阶模式{a,b,c,d}和{a,c,d,g}需要被判断亚频繁性(如图4虚线所示)。从图4中,我们可以看到对于高阶模式有一些共有模式是可以相互使用的。例如,{a,b,g}是判别{a,b,c,g}和{a,b,d,g}是否是亚频繁的共有模式,而{a,b,c}则是判别{a,b,c,g}和{a,b,c,d}的共有模式。由此,我们最好把低阶模式存储起来以便再次使用。此外,若5阶模式{a,b,c,d,g}是亚频繁的,那么,余下的其他4阶模式可立即判定是亚频繁模式了。当完成有序字符串“abcdg”的频繁性判断过程后,我们将处理δhead(a)中的有序字符串“acdfg”。这样我们便可得到以“a”为头的极大亚频繁co-location模式集mscpa,并剪掉l中所有属于mscpa的子集。接下来,继续处理l中以“b”为头的有序字符串。给出了pba挖掘算法input:f={f1,…,fn}:空间特征集;s:空间实例集;d:空间邻近关系距离阈值;min_sprev:最小亚频繁性阈值;output:mscp:所有极大亚频繁co-location模式集;variables:si2:2阶co-location实例集;scp2:2阶亚频繁co-location模式集;l:经过划分1和划分2处理后的scp2的有序字符串集;li:在l中以“i”为头的有序字符串集;scpi:以“i”为头的极大亚频繁co-location模式集;b:标志数组,用来标识模式是否已判断过其频繁性;mscp:所有极大亚频繁co-location模式集steps预处理(step1-4):先找出2阶co-location模式的实例集si2,并计算所有的2阶亚频繁co-location模式集scp2。然后,基于划分1和划分2,我们得到有序字符串集l。获取以“i”为头的有序字符串(step5-8):先把l中以“i”为头的有序字符串放到li中,并将以“i”为头的极大亚频繁co-location模式集scpi的值设为“null”,标志数组b初始化为0(b可防止重复计算)。当b中对应的模式是亚频繁时,赋值为1;否则,赋值为-1。而“i”则从第一个特征开始,迭代至最后一个特征。使用核模式策略处理li中的有序字符串(step9-15):对于li中的每个有序字符串c,通过递归过程cpd(c,|c|)计算c中极大亚频繁co-location模式集hsc。其中,递归过程是基于核模式策略设计出来的。而在主程序的第13步中,根据cpd(c,|c|)的计算结果,我们可得到c的mscps。例如,如果b(hash(c))=1,那么c→hsc。可以看出,要么c本身就是亚频繁的,那么hsc中就只有一个模式c;要么c不是亚频繁的,那么,我们就不得不检查c的两个核模式c′和c″。然后,我们把得到的结果集hsc合并到以“i”为头的scpi中。不过,在主程序的第14步的合并过程中,我们需要删除一些模式(这些模式已是亚频繁模式的子模式)。接下来再处理li中的其它有序字符串,直到没有可处理的字符串为止。递归过程cpd(c,|c|):若c已被识别过,那么返回到递归过程的step1;steps2-5是递归过程的出口;step6和7用c的两个核模式c′和c″做参数分别调用递归过程cpd;当c的两个核模式c′和c″都是亚频繁模式时,我们用steps8-15来处理,否则我们用steps16-20来处理。同时,steps12-14和steps17-19都是用来处理非亚频繁模式c的子模式(不包括c的核模式),如图4虚线部分所示。更新结果集并剪枝(step16-17):更新极大亚频繁结果集mscp,并对集合l中所有属于scpi中模式的子模式进行剪枝处理。返回最终结果集(step18):接下来,继续处理以下一个特征为头的有序字符串,直到l中不存在待处理的有序字符串为止。最后,返回极大亚频繁co-location模式的最终结果集mscp。通过本发明,我们可以挖掘到类似于图1中{a,b,c}这样的模式,它可以帮人们了解空间特征在空间环境中的分布情况。例如,在某个地区,我们从植被分布数据集中发现了模式{a,b,c},那么,在这一地区,如果发现生长的有{a,b,c}中的任一植被,我们就能在它的邻近区域找到{a,b,c}中的其他植被。即,{a,b,c}代表了在该地区的共生植被。这样的模式在实际应用中是非常有用的。比如说,它们可以协助进行植被分布分析和植被保护等。因此,我们用星型参与实例替换团实例,定义了星型参与率和星型参与度,从而提出了亚频繁co-location模式这一新的概念。当然,传统的频繁co-location模式一定是亚频繁co-location模式,反之则不然。也就是,我们挖掘到的亚频繁co-location模式的数目会比频繁co-location模式的数目多,为此,我们提出挖掘极大亚频繁co-location模式来精简最终结果数目。我们设计了两个挖掘极大亚频繁co-location模式的方法,它们分别是:基于前缀树的算法(prefix-tree-basedalgorithm,ptba)和基于划分的算法(partition-basedalgorithm,pba)。为了说明我们设计的两个算法的效率,我们改进并优化了挖掘频繁co-location模式的一个经典算法:join-less算法,使其能够挖掘极大频繁co-location模式,记做m-join-less算法,且m-join-less算法与其他已有的算法相比,在相同运行时间内能处理更多的数据。一、合成数据集上的实验合成数据集使用类似[1,4]的空间数据生成器进行生成。我们合成了3种不同密度分布的数据集来检测不同计算复杂性因素的影响。在稀疏数据集里,可以从20个特征中生成6阶的极大亚频繁模式,而在稠密数据集里,可以从20个特征中生成9阶的极大亚频繁模式。其中,为了能够观察到ptba相对于pba的优势,我们生成了一个极稠密的数据集dense*(表1所示),这个数据集可以从15个特征中生成13阶的极大亚频繁模式。在表1中,除了总执行时间,其他的所有数值都是百分比值。从表1可以看到,m-join-less算法总是比我们设计的两个算法要慢,因为m-join-less算法是通过识别团实例来计算候选模式的频繁性,这样一来,它的计算代价会比交运算要昂贵很多。表1.各算法及算法各要素计算复杂性比较挖掘一个非常稠密的数据集(例如密度为dense*的数据集),ptba的性能要比pba好很多;然而,针对稀疏数据集(sparse)和一般稠密的数据集(dense),pba的性能又比ptba好很多。这是因为,pba是一个自底向上处理的算法,当遇到稀疏数据时,它的结束时间要比ptba早;而ptba是一个自上向下处理的算法,它的优点是能够快速找到高阶极大亚频繁模式。而且我们也可以看到对于ptba,若数据集越是密集,那么tpruning(剪枝)所花费的时间代价比也就越大。当然类似地,我们也可以看到ptba所展现的性能越好,pba反而就会越差。此外,我们还可以注意到,tgen_max_sub-prev_col和tpruning的占比要比其他任何部分都要大。很显然,两个算法的区别主要体现在候选模式的识别上,而且某些要素是某些算法独有的,例如torder_features(特征排序)只是pba算法在选择候选模式的核模式才需要的。二、真实数据上的实验如图5所示,这里给出了二维空间的一个植物分布图,x和y坐标分别代表的是实例关于0度经纬度线的地理位置。我们可以看到这是一个带状植物分布数据集。这是因为植物的生长会受到海拔和河流形状的影响,所以在自然生态学研究领域带状的植物分布是一种很常见的现象。基于星型参与实例可挖掘到极大亚频繁模式(mscps),而基于团实例则可挖到极大频繁模式(mcps),那么首先我们通过实验来对比这两个结果集在数量上的差异。在实验中,我们选用如图5中的珍稀植物分布作为数据集,它包含31个空间特征(植物),336个实例。同时,设置邻近距离阈值d=12000m,兴趣度阈值min_sprev=min_prev=0.3。表2给出了不同阶的mscps和mcps的个数。表2.珍稀植物数据集的挖掘结果阶挖掘到的极大亚频繁模式数挖掘到的极大频繁模式数251534170464115595986727372331835991051073113-如表2所示,在相同参数设置下,在同一数据集上,生成的最高阶的极大亚频繁co-location模式的长度比最高阶的极大频繁模式的长度要长。这是因为,若一个实例属于团实例,那么,它一定也属于星型参与实例,反之则不然。而且从表中我们还可以得出,极大亚频繁长模式所占总模式数的比例要比极大频繁模式的高。例如,在极大亚频繁模式集中,超过7阶的模式数量占模式总数量的15.5%,而极大频繁模式集是4.1%。通常,用户对长模式更感兴趣,原因在于长模式会含有更多的有趣信息。接下来,我们具体分析一下挖掘到的co-location模式。表2中的3个11阶极大亚频繁模式分别是{b,g,j,o,q,r,t,v,w,c,e},{g,j,o,q,r,t,v,w,a,c,e}和{g,h,j,o,q,r,v,w,a,c,e},而3个10阶的极大频繁模式则分别是{g,j,o,r,t,v,w,a,c,e},{g,j,q,r,t,v,w,a,c,e}和{j,o,q,r,t,v,w,a,c,e}。我们注意到,3个10阶的极大频繁模式分别是3个11阶的极大亚频繁模式的子模式。在图5中,虚线圈中的珍稀植物“o”基本上都是分布在植物生长密集区的中心部位,而这样的位置正好也是植物生长的聚集地,这也就是为什么3个11阶的亚频繁模式中都包含植物“o”了,同样的,这也可以解释为什么3个11阶的亚频繁模式都会包含植物“g”和“q”。最后,我们使用另一组大数据量的植物分布数据来测试pba算法的效率。这组数据包含了15个特征,487,857个实例。并通过设置min_sprev=0.3和不同的邻近距离阈值(1000m,3000m和5000m),得到了pba的运行时间分别为148.26(sec.),1967.84(sec.)和7906.74(sec.)。说明了算法pba的可伸缩性。本说明书中的各个实施例均采用相关的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1