一种基于密度和扩展网格的数据流聚类方法与流程
本发明属于数据挖掘技术领域,具体涉及一种基于密度和扩展网格的数据流聚类方法。
背景技术:
随着硬件技术、网络通信技术、各种传感设备以及各种信息技术的飞速发展,在社会网络、传感器网络、电子商务、网络监控、气象环境监测以及金融零售企业等多个应用领域,产生了大量实时的动态数据,称之为流式数据。
与传统的数据类型不同,流式数据具有数据量大,无限长或未知长度,动态变化快,速率不稳定,访问历史数据成本高等特点。使用传统的数据挖掘算法来处理流式数据是非常困难的,所以基于数据流的聚类算法应运而生。
现有技术中的数据流聚类算法是基于距离的测量方法;对于具有连续属性的数据,集群的中心通常是质心,聚类的结果也偏球形,非凸数据的聚类质量较差。此为现有技术的不足之处。
因此,针对现有技术中的上述缺陷,提供设计一种基于密度和扩展网格的数据流聚类方法;以提升聚类的精度和效率,并有效地应用于大数据聚类。
技术实现要素:
本发明的目的在于,解决传统的数据流聚类算法人工设置聚类参数、初始质心选取不当、内存消耗大、聚类效率低等缺陷,通过对基于数据流的密度网格聚类算法进行改进,确保聚类结果的准确性,具有聚类效果好、挖掘效率高等优点。
为实现上述目的,本发明给出以下技术方案:
首先在线层处理已经积累了一段时间的数据流,得到初始聚类结果,根据数据流的更新信息,重新计算网格密度,不断更新聚类结果。首先假设数据集(s1,s2,…,sd)具有d维属性,并且数据空间s=s1×s2×…×sd是d维数据空间。x=(x1,x2,…,xd)表示在t时刻、数据空间s上的数据点集合。把数据空间的每个维度si(1≤i≤d)划分成p份,相等长度且互不相交,在每个维度的正方向上延长区间的长度,从而形成有限的超矩形区域。每一个超矩形区域就是一个网格单元,任何一个数据集合x都可以映射到相应的网格单元,记为g(x)=(j1,j2,…,jd),其中ji=1,2…p,共有
一般说来,网格内部的聚类密度值高于聚类以外密度值和边界点的密度值。聚类孤立点的密度值与聚类中心点的密度值之间存在明显的差距。由于相同的聚类集包含了相对较高密度点集合的连接区域,不同的聚类集合通过相对较低的密度点集合区域来区分,因此不同聚类之间的区域密度差异很大。在网格单元格中,找到网格的中心,就可以确定网格中的聚类个数。
由于集群中心点的密度不小于它邻近点的密度值,所以两个聚类中心之间的距离会非常远。定义样本点x的密度值为ρx:
ρx=∑yχ(dxy-dc)(1)
其中dxy是从点y到点x的距离,dc是距离的临界值。而ρx是距离样本点x的距离小于dc的点的个数。
δ用于测量样本点x和其他局部密度大于其自身密度的样本点的距离。δx表示样本点x的排斥点。
δx=min(dxy)y:ρy>ρx(3)
排斥点越小,表示点x和点y越接近,点x对点y的依赖越大,点x越有可能是点y的聚类;排斥点越大,说明点x和点y之间的距离越远,点x对点y的依赖越小,点x越可能是异常值或者是其它聚类的点。数据点ρ和δ的分布情况如图1所示。
根据数据点ρ和δ分布的决策图,并行计算每个数据点的ρx值和δx值。当ρ值和δ值都较大时,该数据点就是聚类中心,有几个这样的点,就有多少个聚类中心。当δ值很大但ρ值很小时,该数据点很可能是孤立点,因为它们距离聚类的中心点都很远。这就基本确定了网格内的聚类个数。确定聚类中心之后,网格内的其它数据点划分到距离最近、最高密度的聚类中心,从而形成网格内的聚类。
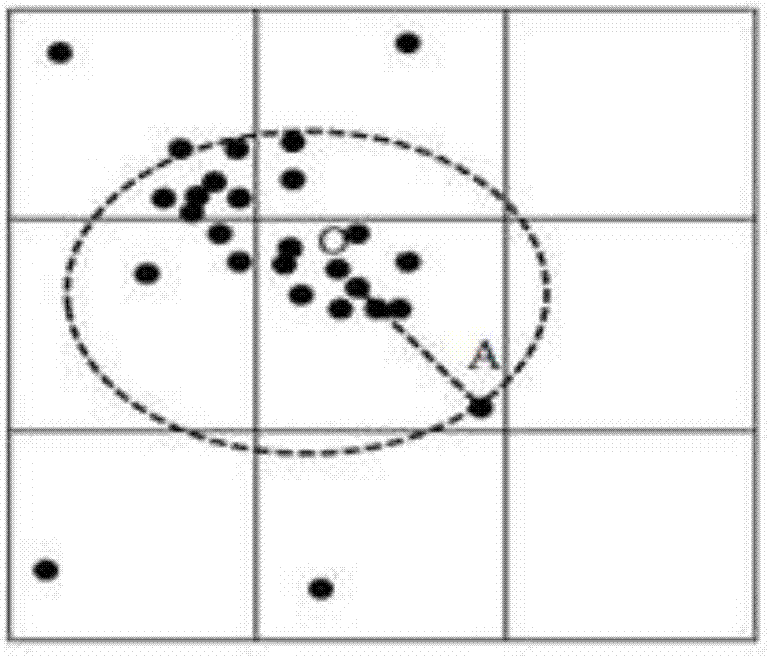
通过扩展网格对网格以外的数据点聚类。确定每个网格单元内部的聚类中心之后,以中心点o为圆心,从o到网格中距离o最远的点a为半径r做圆。扩展区域如图2所示。
用影响度inf(0<inf<1)表示在扩展区域中的数据点对网格内聚类的影响。
其中j表示扩展区域中第j个数据点对网格的影响,xj表示扩展区域内的数据点,cenj表示网格单元的质心,δj表示第j个网格单元的长度。影响程度越大,扩展区域的簇的聚集程度越高,相似度越高;影响程度越小,扩展区域的簇的聚集程度越小,相似度越低。
随着数据的不断流动,网格单元的情况不断发生变化,新的网格会越来越多。在存储空间有限的条件下,必须按照一定的规则对网格单元进行合并,以节省内存消耗。网格之间是否可以合并,由网格之间的连接程度和相邻网格元素的边界决定。如果两个相邻的网格是密集网格单元,则将它们合并成一个簇。如果两个相邻网格之间存在非密集网格单元,那么网格能否合并由相邻网格单元的边界确定。相邻网格单元如图3所示。
设网格密度是网格中数据点的数量。当新的数据流到达网格单元时,更新网格单元的密度。假设在t时刻数据点x的密度值为:d(x,t);那么在t+1时刻的网格密度为:
d(x,t+1)=λd(x,t)(5)
其中,数据权重λ(0≤λ≤1)表示密度衰减系数。
设网格单元g在tn时刻接收到新的数据流数据,更新的最后时间是ti(tn>ti),则更新后的网格单元的密度如下所示:
基于人为设置的网格密度阈值有着很大的局限性。当网格中的数据点累积到一定程度时,可以预先设置网格密度阈值,以区分不同类型的网格单元。设网格单元的最大密度为den_max,非空的最小网格单元的密度为den_min,所有网格单元的平均密度由den_ave表示,则
对于不满足密集条件的网格单元,根据网格的相邻边界进行合并。减少初始网格单元的边长,重复测试后,将网格边界设置为网格边长的1/4。合并两个相邻的非密集网格单元,只需要找到两个网格单元的相邻边界。若网格的边界区域为同一聚类,则合并其对应的相邻网格。
离线调整的过程相对独立,其工作依赖于中间知识库的积累。随着时间的推移,连续数据流不断到来,聚类结果不断更新。数据时间越长,重要性就越小。因此,引入数据权重λ(0≤λ≤1)作为密度衰减系数,降低了历史数据的权重。λ基于数据的权值和生命周期。假设ω为权值,生命周期为τ,则密度衰减系数满足λτ≤ω。也就是说,数据经过τ周期之后,其权重不大于ω。通过设定不同的ω值和τ值确定λ的取值。当新的数据流到达时,数据空间由初始聚类结果和有新数据更新的网格组成,得到的挖掘结果由pyramidtimeframe结构来存储数据。采用增量更新的方式,使得原始聚类结果不断更新,该方法有着良好的收缩性和高效率。
本发明的有益效果在于,解决传统的数据流聚类算法人工设置聚类参数、初始质心选取不当、内存消耗大、聚类效率低等缺陷,通过对基于数据流的密度网格聚类算法进行改进,确保聚类结果的准确性,具有聚类效果好、挖掘效率高等优点。此外,本发明设计原理可靠,具有非常广泛的应用前景。
由此可见,本发明与现有技术相比,具有突出的实质性特点和显著地进步,其实施的有益效果也是显而易见的。
附图说明
图1是数据点ρ和δ的分布。
图2是扩展区域示意图。
图3相邻网格单元。
具体实施方式
下面结合附图并通过具体实施例对本发明进行详细阐述,以下实施例是对本发明的解释,而本发明并不局限于以下实施方式。
本实施例给出基于密度和扩展网格的数据流聚类方法,首先在线层处理已经积累了一段时间的数据流,得到初始聚类结果,根据数据流的更新信息,重新计算网格密度,不断更新聚类结果。首先假设数据集(s1,s2,...,sd)具有d维属性,并且数据空间s=s1×s2×...×sd是d维数据空间。x=(x1,x2,...,xd)表示在t时刻、数据空间s上的数据点集合。把数据空间的每个维度si(1≤i≤d)划分成p份,相等长度且互不相交,在每个维度的正方向上延长区间的长度,从而形成有限的超矩形区域。每一个超矩形区域就是一个网格单元,任何一个数据集合x都可以映射到相应的网格单元,记为g(x)=(j1,j2,...,jd),其中ji=1,2...p,共有
一般说来,网格内部的聚类密度值高于聚类以外密度值和边界点的密度值。聚类孤立点的密度值与聚类中心点的密度值之间存在明显的差距。由于相同的聚类集包含了相对较高密度点集合的连接区域,不同的聚类集合通过相对较低的密度点集合区域来区分,因此不同聚类之间的区域密度差异很大。在网格单元格中,找到网格的中心,就可以确定网格中的聚类个数。
由于集群中心点的密度不小于它邻近点的密度值,所以两个聚类中心之间的距离会非常远。定义样本点x的密度值为ρx:
ρx=∑yx(dxy-dc)(1)
其中dxy是从点y到点x的距离,dc是距离的临界值。而ρx是距离样本点x的距离小于dc的点的个数。
δ用于测量样本点x和其他局部密度大于其自身密度的样本点的距离。δx表示样本点x的排斥点。
δx=min(dxy)y:ρy>ρx(3)
排斥点越小,表示点x和点y越接近,点x对点y的依赖越大,点x越有可能是点y的聚类;排斥点越大,说明点x和点y之间的距离越远,点x对点y的依赖越小,点x越可能是异常值或者是其它聚类的点。数据点ρ和δ的分布情况如图1所示。
根据数据点ρ和δ分布的决策图,并行计算每个数据点的ρx值和δx值。当ρ值和δ值都较大时,该数据点就是聚类中心,有几个这样的点,就有多少个聚类中心。当δ值很大但ρ值很小时,该数据点很可能是孤立点,因为它们距离聚类的中心点都很远。这就基本确定了网格内的聚类个数。确定聚类中心之后,网格内的其它数据点划分到距离最近、最高密度的聚类中心,从而形成网格内的聚类。
通过扩展网格对网格以外的数据点聚类。确定每个网格单元内部的聚类中心之后,以中心点o为圆心,从o到网格中距离o最远的点a为半径r做圆。扩展区域如图2所示。
用影响度inf(0<inf<1)表示在扩展区域中的数据点对网格内聚类的影响。
其中j表示扩展区域中第j个数据点对网格的影响,xj表示扩展区域内的数据点,cenj表示网格单元的质心,δj表示第j个网格单元的长度。影响程度越大,扩展区域的簇的聚集程度越高,相似度越高;影响程度越小,扩展区域的簇的聚集程度越小,相似度越低。
随着数据的不断流动,网格单元的情况不断发生变化,新的网格会越来越多。在存储空间有限的条件下,必须按照一定的规则对网格单元进行合并,以节省内存消耗。网格之间是否可以合并,由网格之间的连接程度和相邻网格元素的边界决定。如果两个相邻的网格是密集网格单元,则将它们合并成一个簇。如果两个相邻网格之间存在非密集网格单元,那么网格能否合并由相邻网格单元的边界确定。相邻网格单元如图3所示。
设网格密度是网格中数据点的数量。当新的数据流到达网格单元时,更新网格单元的密度。假设在t时刻数据点x的密度值为:d(x,t);那么在t+1时刻的网格密度为:
d(x,t+1)=λd(x,t)(5)
其中,数据权重λ(0≤λ≤1)表示密度衰减系数。
设网格单元g在tn时刻接收到新的数据流数据,更新的最后时间是ti(tn>ti),则更新后的网格单元的密度如下所示:
基于人为设置的网格密度阈值有着很大的局限性。当网格中的数据点累积到一定程度时,可以预先设置网格密度阈值,以区分不同类型的网格单元。设网格单元的最大密度为den_max,非空的最小网格单元的密度为den_min,所有网格单元的平均密度由den_ave表示,则
对于不满足密集条件的网格单元,根据网格的相邻边界进行合并。减少初始网格单元的边长,重复测试后,将网格边界设置为网格边长的1/4。合并两个相邻的非密集网格单元,只需要找到两个网格单元的相邻边界。若网格的边界区域为同一聚类,则合并其对应的相邻网格。
离线调整的过程相对独立,其工作依赖于中间知识库的积累。随着时间的推移,连续数据流不断到来,聚类结果不断更新。数据时间越长,重要性就越小。因此,引入数据权重λ(0≤λ≤1)作为密度衰减系数,降低了历史数据的权重。λ基于数据的权值和生命周期。假设ω为权值,生命周期为τ,则密度衰减系数满足λτ≤ω。也就是说,数据经过τ周期之后,其权重不大于ω。通过设定不同的ω值和τ值确定λ的取值。当新的数据流到达时,数据空间由初始聚类结果和有新数据更新的网格组成,得到的挖掘结果由pyramidtimeframe结构来存储数据。采用增量更新的方式,使得原始聚类结果不断更新,该方法有着良好的收缩性和高效率。
以上公开的仅为本发明的优选实施方式,但本发明并非局限于此,任何本领域的技术人员能思之的没有创造性的变化,以及在不脱离本发明原理前提下所作的若干改进和润饰,都应落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!