一种基于视频数据的牦牛计数方法与流程
本发明属于信息自动化技术领域,尤其涉及一种基于视频数据的牦牛计数方法。
背景技术:
《基于视频数据的牦牛技术软件》目前牦牛养殖在我国畜牧业当中尚处于发展阶段,它的发展很大程度上影响我国畜牧业的经济水平,尤其是对我国以青藏高原地区为主的藏区畜牧养殖业。长期以来,我国牦牛养殖以原始粗狂放牧型为主,在藏区的藏牧民群众,将牦牛视为宝贵的物质财富和基础,从而每家每户长期都存栏了大量的牦牛,少则二百到三百只,多则上千只。为了具体弄清家中牦牛的头数,对于牧民来说显得极为重要,长期以来,很多牧户都是通过将牛群赶至圈窝或巷道圈内,通过家中多个人力围住圈窝进行头数统计,即便如此,也只能统计到大概。然而牦牛属于原始牛种,具有一定的野性,对于人类具有一定的警觉性,通常情况下因为见到生人而受到惊吓,四处乱跑,这为牦牛个数统计又增加了一定的难度。
现有肉牛统计技术中,如申请公布号为cn105160394a的专利文件公开了一种利用读取供单头牛经过的计数通道的前后方向上设置的一对前部红外对射光电传感器s1、一对后部红外对射光电传感器s2、以及设置在后部红外对射光电传感器的正下方或正下方靠后的一对底部红外对射光电传感器s3的信号状态,进行牛只计数统计。
然而上述技术只受限与肉牛等性格较为温顺的动物,牦牛具有一定的野性,在其身上装置以上传感器设备,会具有一定的困难和危险性;牦牛又属于长期放牧型物种,对于计数的统计效果来说,还需要定点安装信号接收器,这些都具有一定的局限性,当大量牦牛拥挤时还会对信号设备产生影响,不适合在高原上牦牛养殖户的应用。
为了今后牦牛群按照生长繁育阶段、产奶性能等指标进行分群,以及各牛群之间的流通管理等,进行牛群准确计数等精细化管理提供科学基础,在牛舍管理、分群管理等需要计数牛只的场合,能够方便、快速、准确统计牛只计数。
综上所述,现有技术存在的问题是:不适合牦牛生物学特性,统计效果具有受信号传感器影响的特点,费时费力,结果不准确。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于视频数据的耗牛计数方法。
本发明是这样实现的,一种基于视频数据的牦牛计数方法,所述基于视频数据的牦牛计数方法包括以下步骤:
步骤一,获取高分辨率的牦牛进出圈舍时的图像数据;
步骤二,对图像进行均值滤波,并且采用构建金字塔的结构;
步骤三,利用金字塔顶层图像数据作为数据源,并灰度化图像,进行直方均衡化操作;
步骤四,使用sobel梯度算子对图像进行卷积滤波,并且对图像进行二值化处理;
步骤五,采用7x7模板对图像进行形态学运算滤波,对滤波后图像进行连通域标记,提取出疑似的目标区域;
步骤六,提取区域的特征,建立特征空间;同时通过离线学习的方法,运用基于最小错误率准则的bayes分类器,将牦牛样本分为正样本和负样本,进行训练;
步骤七,在线预测形状指数、区域灰度值标准差、区域灰度的颜色均值和基于最小分类错误率准则的bayes分类器,判断是否为牦牛区域;
步骤八,如果是牦牛区域,基于颜色特征的区域进行生长分割,连接断裂的牦牛区域,将目标区域计数,输出当前的牦牛数量,重新返回步骤一;如果不是,则返回步骤一,重新开始;
步骤九,在识别的后期使用区域生长算法对其进行补偿,这样可以有效的提高算法的计数性能。
进一步,采用多维随机变量的正态分布概率密度来模拟牦牛和非牦牛特征的概率密度函数为:
式中的ωi代表牦牛特征类或非牦牛特征类,i为0代表牦牛类,i为1代表非牦牛类;p(x|ωi)代表的是条件概率即在ωi类条件下出现特征向量x的概率密度。x代表的是特征空间中的一个特征向量,si代表的是类i的协方差矩阵。
判别函数的对数形式定义为:
进一步,选取regioncut作为图像分割的算法,根据事先定义的准则将像素聚集成更大区域的过程;从一组生长点开始,将与生长点性质相似的相邻像素与生长点进行合并,形成新的生长点,重复这个过程直到不能生长为止。
进一步,所述步骤二在对图像进行降采样的过程中,采用平均加权的均值滤波器:
其中n表示图像金字塔的第n层。fn(x,y)代表在图像金字塔第n层位置x,y处的像素值。如果是彩色图像分别对各个通道进行降采样。
进一步,所述步骤三将彩色图像转化为灰度图像转化公式如下:
fg(x,y)=0.3*fr(x,y)+0.59*fg(x,y)+0.11*fb(x,y);
其中fg(x,y)代表的是转化后灰度图像在x行,y列处的灰度值。fr(x,y),fg(x,y),fb(x,y)分别代表的是彩色图的红色通道,绿色通道和蓝色通道在x,y处的像素值。
直方图均衡化的变换公式如下所示:
其中o(l),n(l)分别代表变换前后直方图第l级的像素点数。
进一步,所述步骤四的sobel算子的公式如下:
其中mx代表垂直方向的梯度模板,my代表代表水平方向的梯度模板。
通过sobel模板对原始图像进行卷积运算后,采用二值化来选择牦牛所在的图像区域,数学公式如下:
其中f(x,y)代表的是二值图像在x,y处的状态。
进一步,所述步骤七采用基于最小错误率的判别准则,数学表达式如下:
本发明的优点及积极效果为:利用本发明在通过收集牦牛群体的影像视频资料后,就可以有效地解决牦牛个数统计问题,比传统牧民通过围栏或人力围堵后,再通过人为进行数量统计相比,牦牛属于原始野生型物种,这节约牧区大量人力资源;比传统利用为每头牛安装红外信号传感器,节约了大量的设备成本,因为藏区牧民家中牦牛数量较大,且购买红外信号传感器不受老百姓喜爱。为藏区的藏牧民群众提供了一个便捷的处理方法,大大降低了所需要的时间成本和人力成本。
附图说明
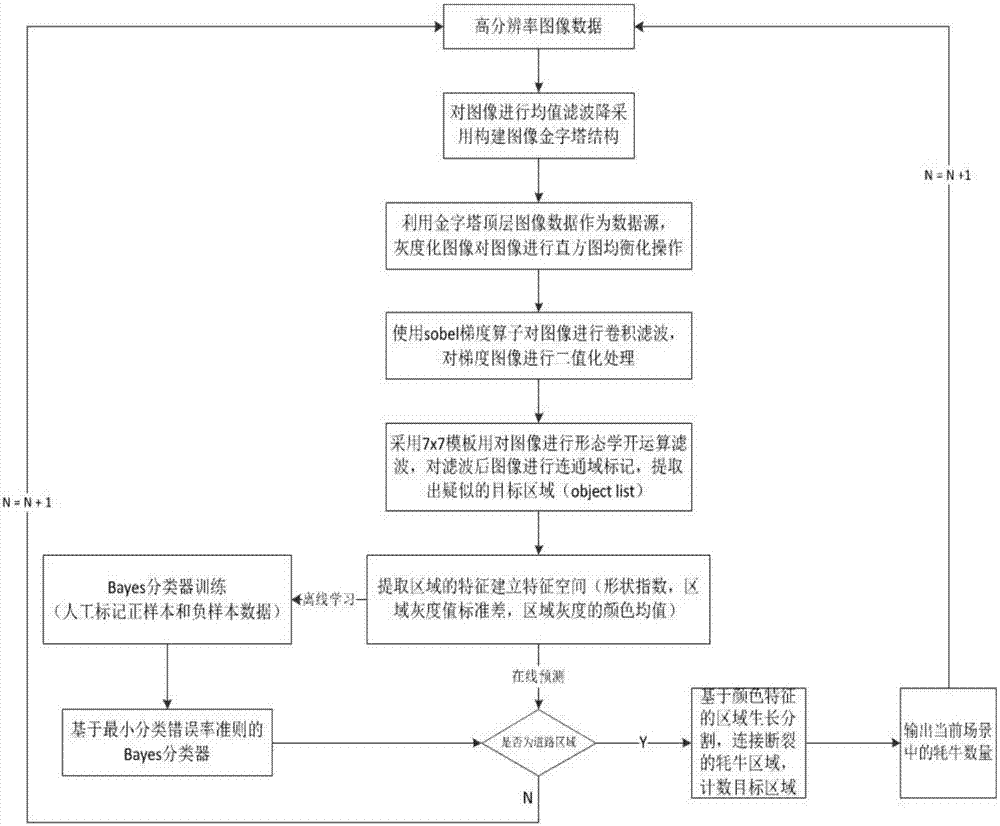
图1是本发明实施例提供的基于视频数据的耗牛计数方法流程图。
图2是本发明实施例提供的基于视频数据的耗牛计数方法实现流程图。
图3是本发明实施例提供的数据分布示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合附图对本发明的应用原理作详细的描述。
如图1所示,本发明实施例提供的基于视频数据的牦牛计数方法包括以下步骤:
s101:获取高分辨率的牦牛出栏时的图像数据;
s102:对图像进行均值滤波,并且采用构建金字塔的结构;
s103:利用金字塔顶层图像数据作为数据源,并灰度化图像,进行直方均衡化操作;
s104:使用sobel梯度算子对图像进行卷积滤波,并且对图像进行二值化处理;
s105:采用7x7模板对图像进行形态学运算滤波,对滤波后图像进行连通域标记,提取出疑似的目标区域;
s106:提取区域的特征,建立特征空间(形状指数、区域灰度值标准差、区域灰度的颜色均值)。同时通过离线学习的方法,运用基于最小错误率准则的bayes分类器,将牦牛样本分为正样本和负样本,进行训练;
s107:在线预测形状指数、区域灰度值标准差、区域灰度的颜色均值和基于最小分类错误率准则的bayes分类器,判断是否为牦牛牦牛区域;
s108:如果是牦牛牦牛区域,基于颜色特征的区域进行生长分割,连接断裂的牦牛区域,将目标区域计数,输出当前的牦牛数量,重新返回s101。如果不是,则返回s101,重新开始;
s109:在识别的后期使用区域生长算法对其进行补偿,这样可以有效的提高算法的计数性能。
本发明具体包括以下步骤:
步骤一,获取高分辨率的牦牛进出圈舍时的图像数据;
为了准确计数远距离大场景中的牦牛数量并且平衡整个算法的复杂度,选择了分辨率为400万像素、焦距为4mm、30米景深的枪机网络摄像头(海康威视)。根据具体需求可选择硬盘录像机记录拍摄到的视频作为以后的查找或分析使用,在的算法中没有对视频进行记录,将数据传回分析主机后实时对数据进行分析,给出牛群数量的计数结果。分析主机配置为:intelcorei52.3ghz,500g硬盘,windows7系统。
步骤二,对图像进行均值滤波,并且采用构建金字塔的结构;
由于图像分辨率太高会影响到算法的时间复杂度,故采用了低分辨率粗略定位,高分辨率精确识别的策略。在对图像进行降采样的过程中,如果采用简单的取图像奇数行计数列的方法会出现锯齿效应,故采用了平均加权的均值滤波器:
其中n表示图像金字塔的第n层,这样处理的益处在于1消除降采样过程中的锯齿效应;2可以对图像进行平滑消除一些单点噪声。代表在图像金字塔第n层位置x,y处的像素值。如果是彩色图像分别对各个通道进行降采样。
步骤三,利用金字塔顶层图像数据作为数据源,并灰度化图像,进行直方均衡化操作;
如果使用彩色图像数据作为牦牛计数的数据源,那么计数的结果将不可避免的受到亮度变化的干扰。故将彩色图像转化为灰度图像转化公式如下所示:
fg(x,y)=0.3*fr(x,y)+0.59*fg(x,y)+0.11*fb(x,y)
其中fg(x,y)代表的是转化后灰度图像在x行,y列处的灰度值。fr(x,y),fg(x,y),fb(x,y)分别代表的是彩色图的红色通道,绿色通道和蓝色通道在x,y处的像素值。
为进一步增强图像对比度,采用直方图均衡化技术对图像进行增强,这样处理后可增加图像内容之间的对比度。直方图均衡化是一个非线性处理过程,这个算子的目的是通过一种适合人类视觉分析的图像增强技术。经过这个算子处理后图像的直方图变为平坦,所有亮度级将等概率出现。变换公式如下所示:
其中o(l),n(l)分别代表变换前后直方图第l级的像素点数。
步骤四,使用sobel梯度算子对图像进行卷积滤波,并且对图像进行二值化处理;
观测了大量的牦牛视频,发现牦牛在图像中表现为灰度值较为均匀的区域,这样可以使用梯度检测算子来初步筛选出图像中的疑似目标区域。sobel算子的数学描述为如下所示:
其中mx代表垂直方向的梯度模板,my代表代表水平方向的梯度模板。
通过sobel模板对原始图像进行卷积运算后,得到梯度图像知道在灰度图像中亮度均匀的区域梯度的响应较小,故采用二值化来选择牦牛所在的图像区域,数学描述如下所示:
其中f(x,y)代表的是二值图像在x,y处的状态。
步骤五,采用7x7模板对图像进行形态学运算滤波,对滤波后图像进行连通域标记,提取出疑似的目标区域;
在进行二值化的过程中必然产生孤立噪声,故采用形态学开运算对图像进行滤波处理,这样处理后就可以提取到完整的牦牛区域;采用二次扫描图像的方法来标记图像中的目标区域,形成疑似目标链。
步骤六,提取区域的特征,建立特征空间;同时通过离线学习的方法,运用基于最小错误率准则的bayes分类器,并且用人工标记的牦牛样本(分为正样本和负样本),对分类器进行训练;
利用在图像中牦牛区域的形状指数,区域灰度标准差和灰度均值建立特征空间,由于形状指数数据和标准差、灰度均值不在相同的数量级,在训练的过程中将灰度、标准差进行了归一化处理。数据分布如图3所示:
使用人工标记的方法分类好正样本和负样本,bayes分类训练实际上就是用统计学的方法估计两个类的先验概率密度函数的参数,假设牦牛区域和非牦牛区域的特征都符合正太分布。概率密度函数的表达式如下所示:
式中的ωi代表牦牛特征类或非牦牛特征类,i为0代表牦牛类,i为1代表非牦牛类;p(x|ωi)代表的是条件概率即在类条件下出现特征向量x的概率密度。x代表的是特征空间中的一个特征向量,代表的是类i的协方差矩阵。
步骤七,在线预测形状指数、区域灰度值标准差、区域灰度的颜色均值和基于最小分类错误率准则的bayes分类器,判断是否牦牛牦牛区域;
在离线状态训练好bayes分类器后,通过摄像头和视频采集卡将视频传回视频分析主机,作为牦牛计数算法的数据源实现实时对牦牛数量进行统计。通过前面描述的牦牛特征提取算法,实时的提取出疑似牦牛区域特征(形状指数,区域灰度均值和区域灰度值标准差)传递给bayes分类器对当前可疑目标是否为牦牛做出决策。为了提高算法的准确性,采用了基于最小错误率的判别准则。数学表达式如下所示:
步骤八,如果是牦牛区域,进一步选取regioncut作为图像分割的算法,根据事先定义的准则将像素聚集成更大区域的过程;从一组生长点开始,将与生长点性质相似的相邻像素与生长点进行合并,形成新的生长点,重复这个过程直到不能生长为止。基于颜色特征的区域进行生长分割,连接断裂的牦牛区域,将目标区域计数,输出当前的牦牛数量,重新返回步骤一;如果不是,则返回步骤一,重新开始。
下面对本发明的应用原理作进一步的描述。
1界面信息说明
在分析了大量养牛场实地获取到的视频图像中的牦牛特征后,把这个问题归结为是监督型的机器学习问题。由于牦牛的概念是一个主观的概念,样本标记的行为就是把人们主观概率传递给机器的过程。所以应该人为的选择样本并将它们标记为正本和负样本,牦牛是一个区域级的概念故不选择基于像素级的特征,由于放牧牦牛都是在光照比较好的情况下进行故可以选择区域的色彩作为特征。bayes分类器是被研究最为广泛的分类器之一,其统计学理论基础比较完善,而且容易实现,训练过程比较快,性能比较稳定,故在设计本发明中的牦牛计数算法时选择了bayes分类器。在牦牛特征提取的过程中对梯度图像进行了阈值化处理和形态的开运算,这样不可避免的引入了噪声导致目标区域的断裂,故在识别的后期使用区域生长算法对其进行补偿,这样可以有效的提高算法的计数性能。
1.1特征选择的重要性
确定适合的特征空间,即各类样本能分布在该特征空间中彼此分割的区域内,为分类器设计成功提供良好的基础。流程如图2。
1.2基于最小分类错误率的bayes决策准则
如果已知有m类模式,以及这m类模式在n维空间中的统计分布,即已知各类模式ωi,i=1,2,3,…,m的先验概率p(ωi)以及类条件概率密度函数p(x|ωi)。对于待测样品,bayes公式可以计算出该样本分属各类模式的概率即后验概率;估计模式x属于哪个类别的可能性最大,就把模式x归于可能性最大的那个类,将后验概率作为判断待识别模式归属的判据。bayes公式(1)所示:
在实际的工程问题中,统计数据往往呈现正太分布的特征。假设牦牛区域和非牦牛区域的特征都服从正态分布,这样模型训练的问题就变成了如何利用标记的样品对正太分布的参数进行估计的过程。采用多维随机变量的正态分布概率密度来模拟牦牛和非牦牛特征的概率密度函数(2)所示:
牦牛识别问题转化为了二分类问题,(2)式中的ωi代表牦牛特征类或非牦牛特征类,在的实验中i为0代表牦牛类,i为1代表非牦牛类。p(x|ωi)代表的是条件概率即在类条件下出现特征向量x的概率密度。x代表的是特征空间中的一个特征向量,代表的是类i的协方差矩阵。判别函数的对数形式定义为(3)所示:
1.3基于区域生长的图像分割
选取regioncut作为图像分割的算法,区域生长(regioncut)是根据事先定义的准则将像素聚集成更大区域的过程。它的思想是从一组生长点开始(在本发明中采用bayes分类器识别出来的牦牛区域),将与该生长点性质相似的相邻像素与生长点进行合并,形成新的生长点,重复这个过程直到不能生长为止。采用的相似准则是像素点之间的颜色信息。
1.4软件安装及使用
软件可以处理两种数据源1实时视频流数据,2各种格式的静态视频文件。运行环境为window操作系统或者是linux系统,目前不支持mac系统。以下的使用说明以在window7系统下为例进行说明。在window软件安装完成后的效果。
下面结合测试对本发明的应用效果作详细的描述。
1、本发明通过数据和数据库完整性测试、压力测试、集成测试、功能测试、用户界面测试、性能评测和负载测试等方面的测试,直至达到高品质为止。
在windows764位上使用qt和msvc编译器实现了本发明中所提出的算法。硬件环境为:intel(r)core(tm)i5-4200ucpu@1.6ghz2.3ghz,4.00gb内存。在本发明的实验中选择了22个正样本,31个负样本,样本数据如表1所示,在表中只给出了10个数据。
表1训练样本数据
2、实时性能测试
测试图像分辨率为5000万像素(8688*5792),通过均值滤波器进行降采样建立图像塔形后取第四层图像分辨率为80万像素(1086*724),算法的处理时间为38ms这样的处理速度已经达到实时视频采样的帧率。所以在本发明中提出的算法可以烧入嵌入式设备中作为养牛场常备设备实时给出牛群的分析结果。
2、识别性能测试
随机抽取了53个样本图像组成测试样本库,对本发明所提出的算法进行了分类性能测试。
表2bayes牦牛识别算法性能分析
在测试图像集上,记录了80个目标的分类结果如表2所示,算法的正确识别率为:(tp+tn)/(p+n)=76/80=95%,识别错误率为:5%,灵敏度为:tp/p=94.35%,特效度为:tn/n=95.56%,精度为:tp/(tp+fp)=94.29%。从以上的数据中看到在的测试库上面本发明的算法可以达到95%的识别正确率。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!