一种网络个体或群体价值观自动辨别方法与流程
本发明涉及价值观技术领域,具体涉及一种网络个体或群体价值观自动辨别方法。
背景技术:
价值观是基于人的一定的思维感官之上而作出的认知、理解、判断或抉择,也就是人认定事物、辩定是非的一种思维或取向,从而体现出人、事、物一定的价值或作用;在阶级社会中,不同阶级有不同的价值观念。
公开号为cn100389412a的中国专利文献公开了一种自动辨别多个串连装置位置的方法,该方法包括下列步骤:启动串连连接着的串连装置;延迟ta时间段;判断当前装置的输入端的输入讯号是否为0;如果当前装置的输入端的输入讯号为0,则该串连装置的位置为1即该装置为第一装置,延迟tb时间段,第一装置的输出端输出第一数字讯号s(1);相反,如果当前装置的输入端的输入讯号不为o,即当前装置的输入端等待输入第n-1数字讯号s(n-1),则该装置为第n装置,其中n>1;该第n装置输出第n数字讯号s(n)。通过本发明,可在不改变串连装置设定的情况下,辨别每一装置的位置,从而简化安装程序,同时也方便了库存管理。
公开号为cn1276354a的中国专利文献公开了一种自动辨别模拟信号输出和输入的装置及方法,利用插入语音插座(phonejack)的外接装置的阻抗,判断插入语音插座(phonejack)的外接装置为模拟输出,如:喇叭(speaker)、耳机(earphone)等,或是模拟输入,如麦克风(microphone)等。并且,自动的切换内部电路与外接装置的连接。
由于价值观的主观性,且随着时间变化,价值观的内涵会发生变化,因此,通过现有的自动辨别方法无法进行价值观的自动辨别。
技术实现要素:
本发明的目的在于提供一种网络个体或群体价值观自动辨别方法,本发明的自动辨别方法通过设置价值观数据库,然后将网络信息在价值观数据库中进行分类,从而自动辨别网络个体或群体价值观。
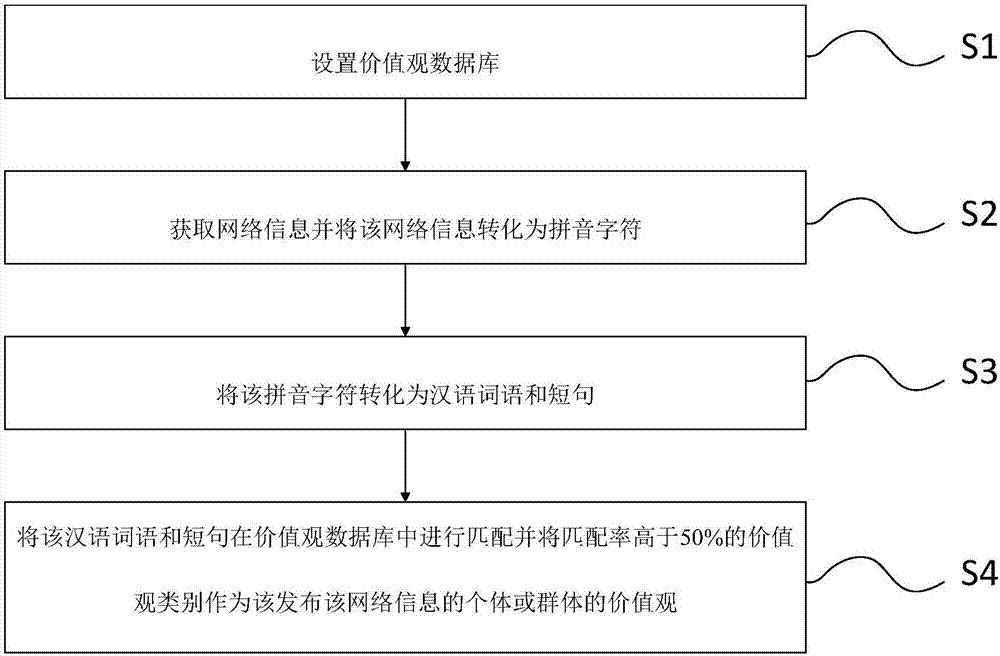
为实现上述目的,本发明提供一种网络个体或群体价值观自动辨别方法,该方法包括:
设置价值观数据库;该价值观数据库包括不同的价值观类别和归属于该类别价值观的词语和短句;
获取网络信息并将该网络信息转化为拼音字符;
将该拼音字符转化为汉语词语和短句;
将该汉语词语和短句在价值观数据库中进行匹配并将匹配率高于50%的价值观类别作为该发布该网络信息的个体或群体的价值观。
可选的,该方法还包括:
获取发布该网络信息的个体或群体的用户标识,并将该用户标识赋予用户特征值并与本地数据库中的用户特征值进行匹配;
若在本地数据库中无法匹配用户特征值,则将该用户特征值储存在本地数据库中。
可选的,该方法还包括:若汉语词语和短句在价值观数据库中进行匹配的匹配率低于50%,则对该汉语词语和短句进行拆分并分别进行匹配,直到匹配至匹配率高于50%的价值观类别。
可选的,若进行拆分至单个词语时,仍旧无法匹配至匹配率高于50%的价值观类别,将该汉语词语和短句进行人工分析,并生成单个类别的价值观。
可选的,该方法还包括:统计归属不同价值观类别的网络信息的数量,并记载于价值观数据库中。
可选的,所述网络信息为网络语音、网络视频、网络文字和网络符号中的至少一种。
可选的,所述设置价值观数据库的步骤包括:
建立价值观类别;
在每个类别价值观中添加归属于该类别价值观的词语和短句。
可选的,所述获取网络信息并将该网络信息转化为拼音字符的步骤包括:
接收用户客户端在网站发布的信息;
将该信息传输至后台处理单元并在处理单元中将该信息转化为拼音字符。
本发明具有如下优点:
本发明的自动辨别方法通过设置价值观数据库,然后将网络信息转化成拼音字符后再次转化成汉语语言和短句并在价值观数据库中进行分类,从而自动辨别网络个体或群体价值观。另外,价值观数据库可以进行更新和增加新的价值观,从而适应价值观内涵的变化。
附图说明
图1是本发明网络个体或群体价值观自动辨别方法一示例性实施例的流程示意图。
具体实施方式
以下实施例用于说明本发明,但不用来限制本发明的范围。
图1是本发明网络个体或群体价值观自动辨别方法一示例性实施例的流程示意图。该方法包括如下步骤:
步骤s1:设置价值观数据库;该价值观数据库包括不同的价值观类别和归属于该类别价值观的词语和短句;价值观是一种人文价值观,会随着时间的变化而变化,因此,需要建立一个可以随时间进行更新的价值观数据库,该数据库中设置有不同类别的价值观,并且每个类别的价值观都可以对应添加汉语词语和短句,例如该价值观是爱国的价值观,则诸如爱国、热爱祖国、守卫祖国、祖国母亲等汉语词语或者短句可以类属于该爱国价值观。
步骤s2:获取网络信息并将该网络信息转化为拼音字符。由于现有网络词语会出现错别字或者出现用同音词的方式进行表达,例如妈妈会被书写成麻麻或嫲嫲等,爸爸会被书写成粑粑、巴巴、叭叭等,因此,为了防止数据库中无该词语或短句,可以先转化成拼音字符。
步骤s3:将该拼音字符转化为汉语词语和短句。由于数据库中归属于价值观的词语和短句都以汉字的形式存在,因此,需要将拼音字符再次转化为汉语词语或短句,例如:麻麻→ma’ma→妈妈,而该转化成的汉语词语或短句具有不同的优先级别,首先是转化成数据库中存有的词语或短句,然后是转化成最常用的词语。
步骤s4:将该汉语词语和短句在价值观数据库中进行匹配并将匹配率高于50%的价值观类别作为该发布该网络信息的个体或群体的价值观。若汉语词语和短句在价值观数据库中进行匹配的匹配率低于50%,则对该汉语词语和短句进行拆分并分别进行匹配,直到匹配至匹配率高于50%的价值观类别。若进行拆分至单个词语时,仍旧无法匹配至匹配率高于50%的价值观类别,将该汉语词语和短句进行人工分析,并生成单个类别的价值观。该人工分析的方式可以是找思想德育或者语文老师进行,若有疑问或不确定之处,可以以小组讨论的形式进行商量。
以学校而言,某一时间段之内重复统计相同个体或群体的价值观并无太大意义,因此需要避免该问题,该方法还可以包括:
获取发布该网络信息的个体或群体的用户标识,并将该用户标识赋予用户特征值并与本地数据库中的用户特征值进行匹配;例如,学校论坛中某人的id为12345,则将该网名按照某种编码形式进行转化为用户特征值,例如转化为100000,并在在本地数据库中进行寻找该赋予特征值,若在本地数据库中无法匹配用户特征值,则将该用户特征值储存在本地数据库中。若下次再次检测到该用户特征值,并且将该用户特征值所辨别到的相同的价值观进行忽略。
为了得到不同类别价值观的数据,以便于发现问题,并进行相应的教育,该方法还可以包括:统计归属不同价值观类别的网络信息的数量,并记载于价值观数据库中。例如,若归属于爱国价值观的网络信息的数量过少,可以适时进行爱国价值观的教育。
网络信息可以来自学校互联网外部的信息,也可以来自学校论坛上的信息,例如,所述网络信息可以为网络语音、网络视频、网络文字和网络符号中的至少一种。
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!