一种基于自动选择副本因子模型的图计算方法与流程
本发明涉及云计算领域,具体涉及一种基于自动选择副本因子模型的图计算方法。
背景技术:
近年来,随着社交网络、基因和各种商业领域中的图结构数据数量和规模快速的增长,对于处理大规模图数据的需求也在随之增加。越来越多的公司需要图计算系统来对图数据进行分析和计算。许多分布式图计算系统应运而生,其中包括pregel、giraph、graphx、graphlab、powergraph、powerlyra和gemini。然而现有的图计算系统节点之间的大量通信使得网络成为瓶颈。分布式图计算系统想要达到很好的性能就需要高速网络。
另一种解决方案是不采用分布式架构。其中galois和ligra就是为共享内存/多核机器设计的,graphchi和x-stream也是为单机处理大规模图数据设计的。集中式的图计算系统避免了分布式系统中的管理和调度问题。但随着新的计算机硬件的出现(如图形处理器gpu),计算机硬件性能的不断提升,这些传统的图计算系统设计并不能完全发挥其计算能力。使用gpu加速的图计算系统似乎是一个可行的解决方案。尽管已经有一些系统进行过一些尝试,但使用gpu来支持大规模图计算系统仍然是一个很大的挑战。其主要问题在于:真实图数据中存在非常严重的节点度数倾斜(图中小部分的节点有大量的边)现象。这会导致gpu的多个线程计算的时候产生大量的写冲突。冲突的线程会被串行化,严重浪费并行计算能力,拖慢系统的计算速度。
技术实现要素:
针对上述问题,本发明的目的是提供一种基于自动选择副本因子模型的图计算方法,该方法能够使得gpu多线程并发计算时,不再受图数据中节点度数倾斜现象的影响,不仅解决了计算资源被浪费的问题,而且提高了图计算系统的速度。
为实现上述目的,本发明所采用的技术方案如下:
一种基于自动选择副本因子模型的图计算方法,其步骤包括:
将图数据切分得到若干个切片;
根据自动选择副本因子模型为上述每个切片选择最优的副本因子ri,其中所述副本因子ri是指为第i个切片si选择的副本个数;
初始化上述每个切片的所有节点值,计算每个切片的每一条边,并根据上述每个切片的副本因子ri将计算得到的目标节点的副本值存放在ri个副本中;
合并上述每一条边的ri个副本的目标节点的副本值,并将合并后得到的目标节点的更新值更新至globalvertices数组;其中所述globalvertices数组用于存放图数据的所有节点值。
进一步地,该方法步骤还包括:将globalvertices数组中存放的图数据的所有节点值传输至内存中进行同步。
进一步地,所述将图数据切分得到若干个切片是指:根据gpu显存大小将图数据切分成若干个页,并根据每个页的大小确定每个页中包含的若干个切片的尺寸以及根据共享内存(sharedmemory)大小确定每个切片中最大节点个数。
进一步地,所述切片采用csc和csr压缩格式保存。
进一步地,cpu将切片以批量发送的方式发送给gpu进行计算。
进一步地,所述自动选择副本因子模型的输入是一个切片的平均度数和gpu的存储限制,输出为该切片最优的副本因子ri;其中所述切片最优的副本因子ri的计算公式为:
其中ri代表第i个切片的副本因子;u和e分别代表第i个切片si中的目标节点和边。
进一步地,采用sum(合并)方法合并上述每一条边的ri个副本的目标节点的副本值。
更进一步地,所述sum方法是指利用两路归并策略将ri个副本的目标节点的副本值进行合并。
进一步地,采用apply(更新)方法将合并后得到的目标节点的更新值更新至globalvertices数组。
更进一步地,所述apply方法如果采用异步模式,则目标节点的更新值将直接提交到globalvertices数组;如果采用同步模式,则先将目标节点的更新值存储到一暂时的数组中,在所有切片计算结束后再更新到globalvertices数组中。
本发明的有益效果在于:本发明提供一种基于自动选择副本因子模型的图计算方法,该方法通过推导得到所述自动选择副本因子模型,并根据该模型得到每一个切片最优的副本因子,既解决了传统方法在gpu多线程并发计算时,受图数据中节点度数倾斜现象影响导致写冲突进而导致计算速度减慢的问题,也解决了选取过大副本因子而产生的硬件计算性能浪费的问题。另外本发明方法在图数据的预处理阶段(即图数据切分与选择最优的副本因子阶段)进行了一些额外的操作及对页和切片的限制。由于预处理阶段是几乎每个图计算系统都需要进行的,并且通常时间较长,因此使用本发明方法额外增加的时间可以忽略不计。
附图说明
图1是本发明提供的基于gpu加速的图计算系统计算过程示意图。
图2是合并方法示意图。
图3是本发明提供的一种基于自动选择副本因子模型的图计算方法流程图。
图4是预处理后的数据结构示意图。
图5是使用本发明方法与不使用副本的计算时间对比图。
图6是使用本发明方法与使用不同固定副本因子的计算时间对比图。
具体实施方式
为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。
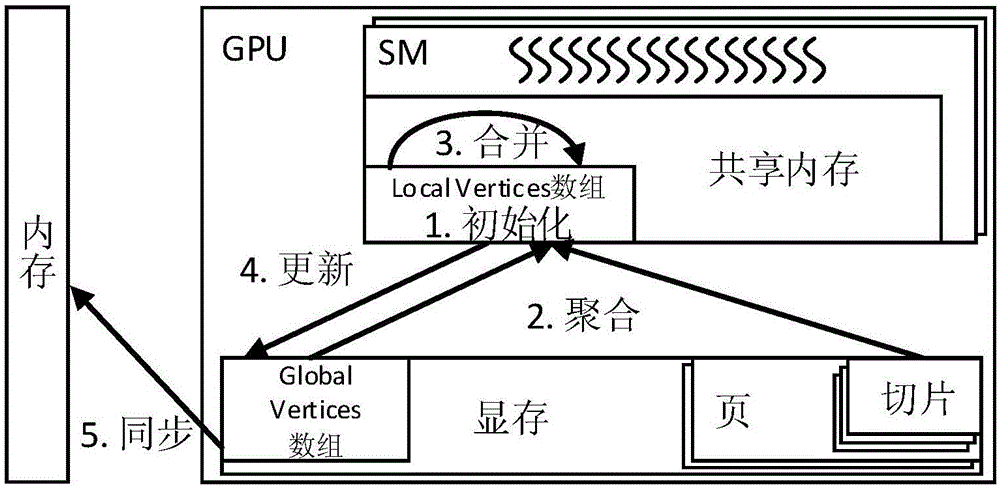
传统的基于gpu加速的图计算系统在计算过程中,sm执行计算是以切片为单位的。sm中的所有线程并发计算切片中的所有边,由于真实图数据的节点都呈幂律分布,存在严重的节点度数倾斜现象,因此在并发计算的过程中会产生严重的写冲突,导致计算能力被严重浪费,系统速度被拖慢。本发明通过基于自动选择副本因子模型的图计算方法解决了基于gpu加速的图计算系统中由于图数据的节点度数倾斜带来的时间损耗,从而大幅度提高图计算系统的性能。
gpu在其显存中保存globalvertices数组,用来存放图数据的所有节点值。如图1所示,计算一个切片分为四个阶段:init(初始化)阶段,gather(聚合)阶段,sum(合并)阶段,apply(更新)阶段。当计算结束后,gpu显存中存放的globalvertices数组,即新的节点值就会被同步到内存中。本发明用si={(u,v,w)|rs≤u≤re}来表示一个切片,其中si的下标i代表第i个切片,u代表该切片中的边的目标节点,v代表该切片中的边的起始节点,w代表该切片中的边的权值,rs和re分别代表这个切片中开始节点和截止节点的序号。一般情况下,用三元组(u,v,w)代表以v为起始节点,u为目标节点,边的权值为w的一条边。
下面详细介绍一个切片在gpu中计算的四个阶段。
init阶段:首先gpu在sm的共享内存中分配一个localvertices数组,该数组用来存储该sm计算的切片(图数据切分成若干个页,每个页中包含若干个切片,该过程在后文中有进一步说明)的所有节点值。然后一组连续的线程将该数组初始化为用户自定义的初始值(如pagerank算法中设置为0)。
gather阶段:对于每一条边(u,v,w),其中u为边的目标节点,v为边的起始节点,w为边的权值。一个gpu线程从显存中读取globalvertices数组中当前节点值和切片中边的全部信息即(u,v,w)合并到变量a′u中:
sum阶段:将上一步计算得到的同一个目标节点的多个副本值进行合并,得到目标节点u这一轮的更新值,即au←sum(a′u),其中au为在localvertices数组中合并得到的更新值,a′u为在localvertices数组中目标节点u的一个副本值。
apply阶段:在这一步,每个线程更新localvertices数组的节点值,即
上述提到的框架帮助用户很容易的写出大部分图计算的算法。但是由于多线程同时修改相同的共享地址空间(处理相同目标节点的边)会产生碰撞,会导致在gather阶段产生大量的写冲突。这种冲突通常需要使用原子操作将内存的更新串行化。原子更新相比于正常的更新操作延迟更高。
而如前所述真实图数据中节点的度数都是呈幂律分布的,这就意味着写冲突在计算中是非常频繁的,特别是对于那些大度数的节点。写冲突会导致gpu产生严重的计算性能问题。本发明提出的解决方案是使用副本,即把一个节点的更新值au在共享内存中放置r个副本,每个副本值a′u是au的一部分,所有a′u通过sum方法得到au,其中r也称为副本因子。另外本发明设计了对应(mapping)函数,将每个线程对应到一个节点的副本上。为了方便对应,在本发明中一个切片中所有节点的r都相同。对于一个切片内的所有目标节点uj,对应函数为:
尽管副本能够减少写冲突,但是由于共享内存大小有限,副本会使得共享内存中节点数减少,导致gpu的利用率降低。为了保持副本数和gpu利用率的平衡,本发明提出一个自动选择副本因子模型来最大化计算性能。该模型的推导过程如下:
该模型的输入是一个切片的平均度数和gpu的存储(共享内存等)限制,输出为最大化计算性能的副本因子ri。在下述描述中,u和e分别代表切片si中的目标节点和边,tl和ta分别代表访问显存的时间和共享内存上原子操作的时间。
在gather阶段,切片si的副本因子为ri,所有线程需要从显存中读入ri×|u|个目标节点值、|e|个边的权值到共享内存中,其需要的时间分别为ri×|u|×tl和|e|×tl。在共享内存中,所有线程需要执行|e|个原子操作,其平均度数为
本发明希望找到使得tg(ri)最小的副本因子ri,由于logri<<ri,因此当ri×|u|×tl=
根据上述模型,能够对每一个切片选择最优的副本因子。在gather阶段采用本发明提出的自动选择副本因子模型计算每一个切片最优的副本因子,既解决了传统方法写冲突导致速度减慢,也解决了选取过大副本因子而产生的硬件计算性能浪费的问题。另外采用本发明方法需要在图数据的预处理阶段进行一些额外的操作及对页和切片的限制。其中包括:预处理时需要保证切片内的目标节点是连续的,并且有数量限制。页的大小要小于gpu显存的大小。根据本发明提出的自动选择副本因子模型计算每个切片最优的副本因子,并存储在元数据中,随图数据一并发送至gpu进行计算。由于预处理阶段是几乎每个图计算系统都需要进行的,并且通常时间较长,因此使用本发明方法额外增加的时间可以忽略不计。其中所述元数据是用于描述数据属性的数据,本发明的副本因子就是元数据,且元数据还包含一些其他的描述信息,比如切片的目标节点范围等。
针对上述四个阶段(即init阶段、gather阶段、sum阶段和apply阶段),用户通过实现一个包含以下四个方法的接口来描述一个图算法。
方法1:init(vertex*localvertices,vertex*globalvertices),该方法用于根据globalvertices来初始化localvertices,其中localvertices为sm内部的共享内存中存放当前切片所有节点值的数组,globalvertices是存放在gpu显存中图数据的所有节点值的数组。
方法2:gather(vertex*v,vertex_static*v_static,edge*w,vertex*localvertices),该方法用于执行一条边的计算,其中v是边的起始节点,v_static为起始节点的其他相关数据(由用户自定义,如pagerank算法中可以存放每个节点的度数),w为该条边的权值(若是无权图则为空),localvertices是存放在共享内存中的当前切片所有节点值的数组(其内部包含副本)。
方法3:sum(vertex*v,vertex*u),该方法用于合并同一个目标节点的两个副本v、u的节点值。其中v和u是同一个目标节点在localvertices中的两个副本。
方法4:apply(vertex*globalvertices,vertex*localvertices),该方法用于根据localvertices更新globalvertices,其中此时localvertices存放该切片的目标节点的更新值,globalvertices是存放在gpu显存中图数据的所有更新的目标节点值的数组。
经过验证,绝大多数运行于图计算系统上的图算法都适用于此接口。
本发明提供一种基于自动选择副本因子模型的图计算方法,请参考图3,其实现过程为:
1、在图计算开始之前,系统对图数据进行预处理,根据gpu显存大小及共享内存大小确定每个切片的尺寸限制以及每个切片中最大节点个数。另外需要保证每个切片中的目标节点是连续的。为了降低显存开销,本发明采用了csc和csr的图数据压缩格式来保存数据。请参考图4,在该图左侧的图例中,0、1、2、3、4、5代表节点,两个节点之间的值代表边的权值。根据左侧图例,右侧csc压缩格式(入边)中idx数组表示从第idx[i]到第idx[i+1](不包含第idx[i+1])条边的目标节点为i;nbr数组表示所有边的起始节点;edge数组表示所有边的权值;idxoff数组为所有边的目标节点减去这个切片的起始节点的序号。右侧csr压缩格式(出边)中idx数组表示从第idx[i]到第idx[i+1](不包含第idx[i+1])条边的起始节点为i;nbr数组表示所有边的目标节点。localvertices数组在节点对应序号的位置存放该节点的计算结果。在产生一个切片的过程中,当切片的边数达到显存的大小限制,或者目标节点个数达到共享内存大小的限制时,统计其平均度数,根据本发明提出的自动选择副本因子模型,选择该切片最适合的副本因子ri。为了减少传输带来的开销可以使用批量的方式,将多个切片组成一个页送到gpu中进行计算。
2、切片被复制到gpu的显存之后,sm分配localvertices数组用于存放这个切片范围内的所有节点值,并根据用户自定义的init方法将其初始化(如pagerank算法中初始化为0)。计算正式开始时,sm中的所有线程连续读取切片中的数据,每一个线程根据用户自定义的gather方法处理每一条边,直到该切片中的边被全部计算。根据上述选择的该切片的副本因子ri及用户自定义的sum方法将gather得到的同一目标节点的副本值进行合并,得到目标节点这一轮的更新值。
3、每一个线程根据用户自定义的apply方法处理每一个目标节点值,直到该切片中范围内的目标节点被全部计算,完成这该切片这一轮的计算,并将计算结果提交至显存中。
4、重复执行步骤2和步骤3直至该图数据的所有切片都完成一次计算,则计算结束,并将显存中的计算结果传输至内存中进行一次同步。
下面详细介绍针对本发明方法所进行的实验。
1)实施步骤
a)首先在基于gpu加速的图计算系统之上实现本发明提出的自动选择副本因子模型。
b)启动系统,向系统提交计算任务,cpu将图数据以批量发送切片的方式发送给gpu进行计算,gpu计算结束后将结果返回给cpu。经过多轮计算,cpu将最终得到的结果输出,统计总计算时间以及每个页的计算时间。
2)实施效果
实验使用的gpu为nvidiageforcegtx1070,其包含15个sm和8gb显存;cpu为intelhaswell-epxeone5-2650v3,10核、主频2.3ghz,内存为64gb双通道,pcie3.016通道连接内存和显存。实验采用pagerank算法作为计算负载,并根据gpu对图数据进行预处理,根据系统接口实现相应的gather、apply等方法。所有系统与方法均使用c语言。
如图5所示,该图描述的是在sk-2005图数据集上运行pagerank算法,每一个页的计算时间对比图。不使用副本方式的计算时间对于不同的页变化很大,因为不同页中节点的度数差别很大。差距最大的在时间上慢了45.17倍。同时还发现计算时间与页中最大节点度数的相关系数为0.9853,这就意味着一个页的计算时间受最大度数节点影响。相比于不使用副本的方式,使用本发明方法每个页的计算时间快速且平稳,同时平均提升4.84倍速度,大大减少总的计算时间。
为了说明本发明的自动选择副本因子效果优于整个图数据选择固定的副本因子,在sk-2005图数据集上使用固定的副本因子ri∈{1,2,4,8,16,32}运行pagerank算法。如图6所示,计算时间在ri一开始增加的时候降低,之后又有增加。根据本发明提出的自动选择副本因子模型得到的副本因子运行速度最快,达到8.6s,比整个图数据选择固定副本因子中最快的情况(其计算时间为14.87s)仍然快1.73倍。
以上实施仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!