一种面向多变元个体中心网络演变的可视化方法与流程
本发明涉及可视化领域,具体涉及一种面向多变元个体中心网络演变的可视化方法。
背景技术:
网络数据在生活中无处不在,如人口迁移中构成的城市间的迁移网络、生物研究中的蛋白质网络、金融账户之间的交易网络、生活中的人际关系网络等;个体中心网络以某一特定个体为中心,分析其与关联对象以及包括中心个体与关联对象在内的所有对象间的关系;其作为个体与外界关联的概括抽象,揭示了个体与外界的联系与相互影响;在人类学、社会学、商业管理等方面已得到广泛重视与应用;如行为学家通过对比个体中心网络,发现用户在不同社交网络平台上的交流模式及角色;医生通过患者的社交网络,分析患者的个人健康状况。
个体中心网络演变分析常被应用到各个科学研究及应用领域,一直以来都是网络研究中的一项重要课题;研究这类网络的时序变化规律,不仅能揭示网络的演变模式与规律,还能进一步发现个体及其网络特征、识别关键的变化与异常;该类数据除了具备网络结构信息(节点和边)意外,还包含了多变元信息,如在人口迁移网络中,代表每一个节点的城市具有gdp、犯罪率、环境状况等属性;结合这些多变元信息我们可以发现更加有意思的一些规律(如:单个城市的迁入迁出与其自身或者与其相关的城市多变元信息之间的关联);可视化对于展开并分析这种具备图结构的网络数据,以及探索未知的演变规律较为有利;基于时间轴的方式是常用的用于探索网络演变的主要技术之一,相比于动画的方式,该方法更有利于交互式分析,适用于较小规模的网络数据;将网络快照并列排放是基于时间轴的方式中最流行的一种方式;如timearctree将每一时刻的节点放置到竖直的坐标轴上,同一水平线上对应着不同时刻相同的节点,以便于有效追踪节点变化;相同时刻下的节点间的连线通过曲线进行连接,同时优化了节点顺序降低了边交叉带来的视觉混淆度;pes为了达到更好的视觉扩展性(降低同一时刻下节点间边重叠、交叉带来的视觉混淆),采用了二部图的方式;目前的这种方法存在由于不同时刻下相同的节点处于同一水平线上,容易导致可视空间利用率低(许多对象不会出现在每一个时刻都出现),数据扩展性较差;节点布局较为固定,无法充分利用节点的位置信息,相比于其它视觉变量,用户的感官对于位置信息更加敏感;最后,同一时刻下网络快照中连线过多容易造成视觉混淆。
技术实现要素:
本发明提供一种具有更高扩展性、更灵活的布局和更低视觉混淆度的面向多变元个体中心网络演变的可视化方法。
本发明采用的技术方案是:一种面向多变元个体中心网络演变的可视化方法,包括以下步骤:
步骤1:获取网络结构信息,根据自定义的时间戳和确定的个体中心对象得到网络快照信息;
步骤2:获取多变元信息;
步骤3:对步骤1和步骤2中得到的信息进行视觉映射,将数据转换为图形结构;
步骤4:将步骤3得到的图形进行视图转换,转换为交互式视图,进行人机交互。
进一步的,所述步骤3中的图形结构采用基于时间轴的布局方法,对应时刻竖轴下的节点表示在当前时刻下与个体中心有关联的数据对象;相邻时刻相同的节点通过二次贝塞尔曲线进行连接;多变元信息映射为节点颜色;节点在纵轴上的位置根据属性布局或者拓扑结构布局确定。
进一步的,所述多变元信息包括类别型属性和数值型属性。
进一步的,当颜色映射为类别型属性时,用不同的色调加以区分;为数值型属性时,具体映射方法如下:
a、对将要编码的属性值域根据盒须图中的位点划分为n段,每一段包含的不同值的个数用ti表示,其中i表示段序号;
b、计算每段中数据点占所有数据点的比例pi以及累积百分比spi,
c、为每个值域段分配颜色空间,整个色带的起点和终点分别为scolor,dcolor,根据颜色插值函数color(per)得到第i个段分配的颜色区间的起始色
color(per)=interpolation(scolor,dcolor,per),per∈[0,1](2)
d、为每个值域段中的数据点按序列均分的形式编码。
进一步的,所述根据属性布局确定节点在纵轴上位置的方法如下:
s1:获取第i个值域段中最大堆的节点数
式中:
s2:计算所有值域段最大堆节点数之和tnum,
s3:根据s2中得到的最大堆节点数之和,计算上下段之间的自适应间距gpad,
式中:h为画布高度,r为节点半径,pad为堆内节点间距离,δ为绘制空间上下预留距离;
s4:计算时间片t中节点n在纵轴上的位置
式中:heapygindex为节点所在堆的中心纵坐标,localindex为节点在该堆中的局部序号。
进一步的,所述根据拓扑布局确定节点在纵轴上位置的方法如下:
s1:对每个时刻下的网络节点进行社区划分,同一社区中的节点构成堆;
s2:每个时间片t下允许的最大间距
式中:cheapt为每个时间片t下包含堆数量,cnodest为每个时间片t下包含节点数量,h为画布高度,r为节点半径,pad为堆内节点间距离,δ为绘制空间上下预留距离;
s3:计算最优堆间距bestpad:
s4:计算t时刻下第一个堆距离画布顶端的距离topt:
s5:计算节点n在纵轴上的位置
式中:gindex为节点n所在堆序号,index为节点n在t时刻下所有节点的全局编号。
进一步的,所述图形结构布局完成后,对堆内节点顺序优化:
对每个时间片从上至下遍历每一个堆,判断节点是否连续出现,将连续出现的节点置于非连续出现节点之前;连续出现的节点保持与前一时刻的先后顺序。
本发明的有益效果是:
(1)本发明具有更高的节点扩展性;
(2)本发明具有更灵活的布局,充分利用了节点位置信息;
(3)本发明具有更低的视觉混淆度。
附图说明
图1为本发明流程示意图。
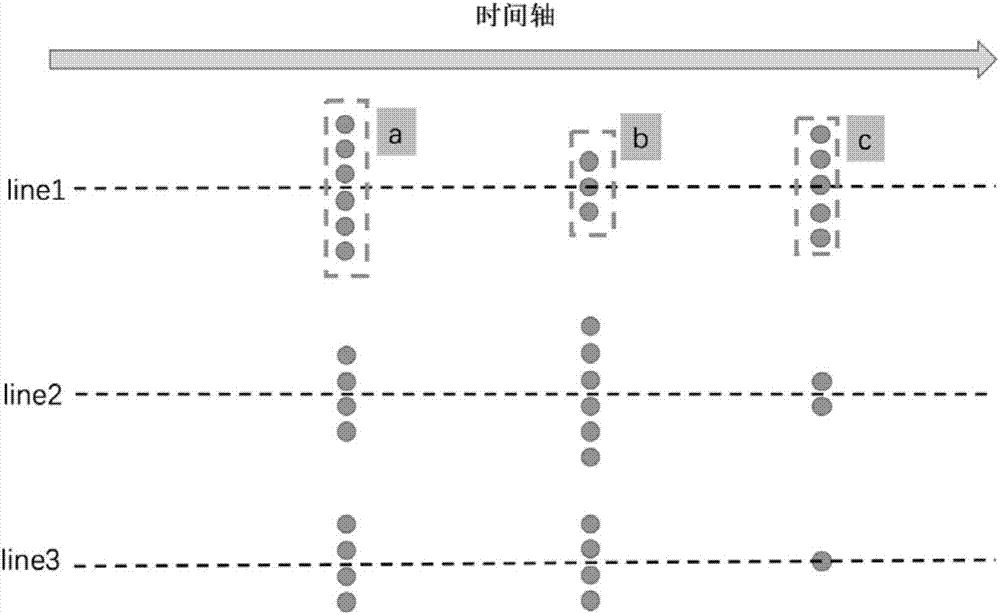
图2为本发明中基于属性布局示意图。
图3为本发明中基于拓扑结构布局示意图。
图4为本发明堆内节点排序前效果图。
图5为本发明堆内节点排序后效果图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步说明。
如图1所示,一种面向多变元个体中心网络演变的可视化方法,包括以下步骤:
步骤1:获取网络结构信息,根据自定义的时间戳和确定的个体中心对象得到网络快照信息;对于原始数据,无论是何种原始文件格式,根据自定义的时间戳,以及确定的个体中心对象,得到一系列的网络快照信息,用g=(g1,g2,…,gi,…,gn)表示网络快照序列;其中gi表示时间戳ti下的网络快照,其由一系列与个体中心相关的节点和边所构成。
步骤2:获取多变元信息;部分节点和边属性可以从原始文件中直接解析抽取得到,而部分属性则需要根据统计方法得到,如节点局部聚集系数,度中心性等。
步骤3:对步骤1和步骤2中得到的信息进行视觉映射,将数据转换为图形结构;
当得到网络结构信息以及多变元信息之后,对这些信息进行视觉映射,以便于用户更加形象直接的解决分析需求;视觉映射定义了数据到图形结构的变换;在该可视化方法中,采用了基于时间轴的布局方法,对应时刻数轴下的节点表示在当前时刻下与个体中心有关联的数据对象,用圆进行表示;相邻时刻相同的节点通过二次贝塞尔曲线进行连接,以便对节点进行追踪;节点的颜色则映射为不同的属性,包括节点属性或者边属性;节点在纵轴上的位置则取决于根据属性布局还是根据拓扑结构布局;用户可通过灵活可视重编码技术,根据具体的分析需求,对颜色映射及节点布局(位置)进行调整;在节点颜色映射时,当用户选择将颜色映射为类别型属性时,使用不同的色调加以区分节点,而当映射为数值型属性时,为了更好地适用于数据分布规律未知的情况,采用类似于盒须图的分段映射方式,包括如下步骤:
a、对将要编码的属性值域根据盒须图中的位点划分为n段,每一段包含的不同值的个数用ti表示,其中i表示段序号;例如将要编码的属性值域根据盒须图中的1/4、1/2、3/4位点划分成四段;
b、计算每段中数据点占所有数据点的比例pi以及累积百分比spi,
c、为每个值域段分配颜色空间,整个色带的起点和终点分别为scolor,dcolor,根据颜色插值函数color(per)得到第i个段分配的颜色区间的起始色
color(per)=interpolation(scolor,dcolor,per),per∈[0,1](2)
d、为每个值域段中的数据点按序列均分的形式编码,即为每个值域段中的数据点按新的颜色空间进行编码。
节点布局方式如下:为了更好的利用空间以及有效追踪节点,将同一时刻的节点置于同一竖轴上;任一节点n在水平方向上的坐标取决于其出现的时间:
x=f(t)
而节点的竖直位置取决于用户的选择方式,基于属性或基于拓扑结构;这两种方式分别从多变元以及拓扑的视角探索网络演化;以下为基于这两种模式划分下的纵坐标计算进行说明:
基于属性布局确定节点在纵轴上位置的方法如下:
同一属性值或处在同一值域段的节点划分到同一堆(提供了按每个属性值划分的方式以及按分位点划分的方式);如图2所示,其中处在line1、line2和line3虚线上的堆表示其属性值相同或者处在同一值域段;并且这些堆的中心都在同一直线上(如图2中的a、b、c中心都过line1);对于按数值型属性划分的堆,其代表的值或值域段在数轴上自上至下不断减小(即line1>line2>line3);假设划分后包含n个属性值或值域段,并且包含m个时间片,则每一段在m个时间片下最多包含m个堆;
s1:获取第i个值域段中最大堆的节点数
式中:
s2:计算所有值域段最大堆节点数之和tnum,
s3:根据s2中得到的最大堆节点数之和,计算上下段之间的自适应间距gpad,
式中:h为画布高度,r为节点半径,pad为堆内节点间距离,δ为绘制空间上下预留距离;
s4:计算时间片t中节点n在纵轴上的位置
式中:heapygindex为节点所在堆的中心纵坐标,gindex为任一时间片t上任一节点n所在堆序号,localindex为节点在该堆中的局部序号;上述序号从1开始编号,且从上至下逐渐增大。
基于拓扑结构布局时,为了保持较高的对称性,不同时刻下的数轴的中心都在画布的中轴线上,如图3所示,节点位置计算过程如下:
s1:对每个时刻下的网络节点进行社区划分,同一社区中的节点构成堆;
s2:每个时间片t下允许的最大间距
式中:cheapt为每个时间片t下包含堆数量,cnodest为每个时间片t下包含节点数量,h为画布高度,r为节点半径,pad为堆内节点间距离,δ为绘制空间上下预留距离;
s3:为了满足所有时间片下堆与堆之间的距离一致,同时绘制不超过画布空间,需要计算最为合适的堆间距bestpad:
s4:计算t时刻下第一个堆距离画布顶端的距离topt:
s5:计算节点n在纵轴上的位置
式中:gindex为节点n所在堆序号,index为节点n在t时刻下所有节点的全局编号。
上述基于属性或者基于拓扑结构的布局已经能得到一个较为对称美观的布局,然而为了追踪相邻时刻节点的变化,同一节点会通过曲线连接,从而造成较多的交叉;为了减少连线交叉,对堆内节点进行优化;对每一个时间片从上至下遍历每一个堆,对每个堆中的节点进行如下两步判断:
判断节点是否连续出现(即前一时刻也存在),将连续出现的节点置于非连续出现节点之前;
连续出现的节点保持与前一时刻的先后顺序,排序前后的效果如图4和图5所示。
步骤4:将步骤3得到的图形结构进行视图转换,转换为交互式视图,进行人机交互;利用灵活的交互方式,用户可以反馈操作,如重新选择映射方案,从而解决不同的分析需求。
下面以dblp的论文合作者数据为例,说明本发明得到最终的可视化视图方法:
步骤一:数据解析与处理,对dbpl提供的xml原始文件进行解析,以年为时间戳,并输入感兴趣的个体中心对象,得到每一年中的结构信息,即由作者(节点)和作者之间的合作关系(边)所构成的网络结构;同时获取节点和边的多变元信息,如:代表节点属性的发表量、合作者数量等,代表边属性的合作强度,合作类型等信息。
步骤二:视觉映射,用圆表示一个作者,同一时间段的作者将会位于同一数轴下(拥有相同的横坐标),当基于拓扑结构布局时,根据louvain社区划分算法,对每一个时刻下的节点进行划分,得到一系列的堆(社区),每一个堆内部具有较强的合作关系,而堆与堆之间的合作则较弱;当基于属性进行布局时,可以选择根据每一个属性值或者分位点(适用于不同属性值较多的情况)将每一个时刻下的节点划分为不同的堆;此时每一堆中的节点则表示拥有相同的值或者处于同一值域段内;而节点的颜色默认情况下映射为节点的类型(首次出现、连续出现或者曾经出现),分别用绿色、灰色以及紫色表示;也可映射为其它属性,包括节点和边属性(数值型或类别型);当映射为数值型属性时,为了避免数据分布不均的情况,采用上述类似于盒须图的分段映射方法;而相邻时刻相同的节点之间我们采用贝塞尔曲线进行连接,用于表示连续的合作关系,有利于追踪和作者的个体行为以及个体中心与该合作者之间合作关系的变化。
步骤三:视图转换,通过上述的映射关系,将图形结构通过浏览器渲染引擎,渲染到浏览器的可视界面中,得到最后的交互式视图;通过灵活的交互方式,可以捕获多变元个体中心网络不同角度的演化模式,如将节点布局切换为基于拓扑结构布局时,可探索整个合作结构的变化;同时通过颜色映射,也可观察社团特征以及个体特征(多变元角度)的演化模式。
本发明具有更高的节点扩展性、更加灵活的布局(充分利用了节点位置信息),以及更低的视觉混淆度;本发明能够从拓扑和多变元两个角度探索小规模多变元网络的演变规律。
- 还没有人留言评论。精彩留言会获得点赞!