一种基于改进欧式聚类的散乱工件点云分割方法与流程
本发明涉及点云分割领域,尤其涉及一种基于改进欧式聚类的散乱工件点云分割方法。
背景技术:
近年来随着三维扫描设备精度的提高和成本的降低,研究者能够快速精确地获取对象表面的三维点云信息。相对于二维图像,点云包含了对象的深度信息,在目标识别和定位方面具有独特的优势和潜力,因此该项技术在随机箱体抓取(randombinpicking,rbp)领域引起了广泛的关注。使用三维扫描设备获取箱体内散乱工件表面点云,结合点云处理算法计算单个工件位姿,引导工业机器人进行抓取,效率更高、速度更快、智能化程度更好。但是,受箱体内工件杂乱性,物体间的重叠、碰撞等因素的影响,如何将单个工件从复杂场景中准确的分离出来,仍是有效抓取面临的主要问题,分割结果的好坏,会直接影响后续位姿定位的准确性。
常见的分割算法有基于区域生长的分割、基于模型的分割、基于属性的分割。基于区域生长的点云分割因为效果好,被广泛应用在三维场景重建,逆向工程等领域,但是时间消耗大,不适合解决rbp问题;基于模型的分割方法采用几何图元进行归类,将具有相同数学表示的点归为一类,常用的方法为ransac(随机采样一致性)算法。该方法使用纯粹的数学方法,速度快、对于离群点的稳健性好,但是在处理不同来源点云时精度不高;基于属性的分割是将具有相同属性的点归为一类,也称聚类分割,分割结果灵活准确,但是在处理大场景多维点云时的时间消耗大。
本发明采用编码结构光3d视觉测量系统获取点云,综合考虑该系统获取的点云的特点、分割效果和实时性,基于属性的分割方法效果最好。聚类分割常用的属性如边缘、欧式距离、表面法线等,其中基于欧式距离的聚类分割速度最快,满足工业生产的实时性要求。欧式聚类算法根据点与点之间的欧氏距离进行归类,将距离小于阈值的点归为当前类,但该方法需要手动设置点与点之间的距离阈值,阈值过大过小会导致不同程度的欠分割和过分割,对分割的效果造成影响。
技术实现要素:
本发明为实现散乱工件点云的分割,提供了一种基于改进欧式聚类的散乱工件点云分割方法,该方法在满足实时性要求的同时,能很好的分割出单个目标工件,且最大程度上保留了工件表面的特征。
为了达到此目的,本发明提供的技术方案实现如下:
一种基于改进欧式聚类的散乱工件点云分割方法,步骤如下:
(1)对目标点云和模板点云进行相同预处理,通过迭代半径滤波方法去除聚集分布的离群点;
(2)对步骤(1)中预处理后的模板点云进行线下信息注册,获取单个工件点云的信息,所述信息包括所述单个工件点云在不同k邻域下点与邻近点之间的平均距离和标准差以及所述单个工件点云在不同r邻域下点与邻近点之间的法线夹角均值;
(3)将步骤(2)中所述单个工件点云在不同r邻域下点与邻近点之间的法线夹角均值设置为阀值,将局部邻域法线夹角均值小于阈值的点判定为边缘点,从而分离出目标点云的边缘点和非边缘点,并分别保存成两幅点云;
(4)对步骤(3)得到的所述非边缘点点云进行分割,操作如下:将步骤(2)中所述k邻域下点与邻近点之间的平均距离和标准差设定初始邻域搜索半径阈值,将目标点云中点和其k个邻近点的平均距离和所设阈值相比较,根据两者差异确定自适应搜索半径,然后进行聚类,最终将散乱工件点云分割成多个包含单个工件的点云子集。
(5)对步骤(4)中所述多个包含单个工件的点云子集筛选聚类,滤除数目过少的子集,得到新的点云子集;
(6)对步骤(3)中得到的所述边缘点点云集中搜索属于它的边缘点并归入步骤(5)所述新的点云子集进行边缘点补齐,最终完成散乱工件点云分割。
进一步地,所述步骤(1)中通过迭代半径滤波方法去除聚集分布的离群点,其过程如下:
第一步,采用kd树建立无序点云点与点之间的拓扑关系,实现单个点邻近点的快速查找;
第二步,对点云中任意一点pi,搜索其r邻域半径内的邻近点集合
进一步地,所述步骤(2)中进行模板点云进行线下信息注册,其过程如下:
第一步,设模板点云有n个数据点,构建模板点云kd树,对任意一点qi∈q,搜索其r邻域半径内的所有邻近点,得到邻近点集合
第二步,对任意一点qi∈q,搜索距离其最近的k个邻近点,记作{qi1,qi2,…qik},计算每个邻近点距qi点的平均距离
其中dij表示第j个邻近点到qi的距离,遍历点云q中所有的点,得到n个平均距离值,根据下式求得点云q在k邻域下的平均距离均值和标准差;
第三步,采用pca(主成分分析法)求取点云中所有点的法线,具体步骤是:对任意一点qi∈q,构建其k邻近点{qi1,qi2,…qik}对应的协方差矩阵m:
其中
计算得到qi点与k邻近点法线夹角的均值、点云q的k邻域法线夹角均值。
本发明的有益效果:提供了一种基于改进欧式聚类的散乱工件点云分割方法,该方法能够快速高效地将箱体内散乱堆放工件点云分割成多个包含单个工件的点云子集,同时尽可能地保留工件表面的特征,为后续工件的定位和抓取奠定良好的基础。为了去除点云中的离群点,在基于邻域半径内点云密度的基础上,引入迭代思想,提出迭代半径滤波方法,去除少数聚集分布的离群点,提高了离群点去除的效率;线下处理阶段,对模板点云进行信息注册,为在线分割提供参数选取依据,提高了分割结果的准确性;在线点云分割阶段,通过边缘点去除和补齐避免欧式聚类容易出现欠分割或过分割的现象,保证了分割的效率,自适应搜索半径的欧式聚类方法,大大提高了分割速度。
附图说明
图1是本发明的整体流程图
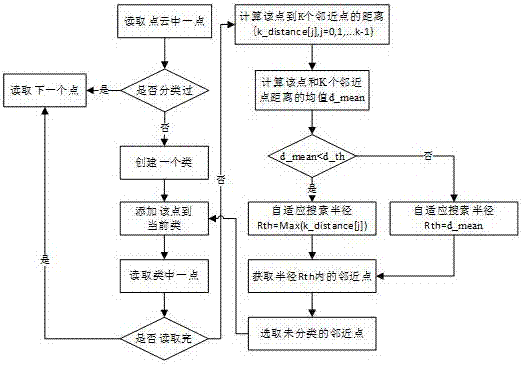
图2是搜索半径自适应的聚类分割算法流程图
具体实施方式
为了更清楚的说明本发明的技术方案和优点,下面结合具体实施例,并参附图,阐述本发明的具体实施方式。
本发明的目的是将箱体内散乱堆放工件点云分割成多个包含单个工件的点云子集,主要流程分成以下五个部分:点云预处理、模板点云线下信息注册、目标点云边缘点提取、基于自适应邻域搜索半径的聚类分割、边缘点补齐,如图1所示。
具体实现步骤为:
(1)点云预处理(以目标点云p为例)
(1.1)采用随机采样一致性算法计算箱体底部平面方程,将点云中接近箱底平面的点去除。
(1.2)迭代半径滤波方法去除离群点的思想是:首先采用kd树邻近点搜索算法建立无序点云p点与点之间的拓扑关系,实现邻近点的快速查找;然后,对任意一点pi∈p,搜索其r邻域半径内的邻近点集合
(1.3)对去除离群点后的点云使用栅格法进行降采样,根据点云在三个维度上最小包围盒和点云分辨率定义单个体素网格大小,用距离重心最近的点代替体素网格内所有的点,达到点云精简的目的。
(2)线下模板点云q的信息注册
(2.1)设模板点云有n个数据点,构建模板点云kd树,对任意一点qi∈q,搜索其r邻域半径内的所有邻近点,得到邻近点集合
(2.2)对任意一点qi∈q,搜索距离其最近的k个邻近点,记作{qi1,qi2,…qik},计算每个邻近点距qi点的平均距离
其中dij表示第j个邻近点到qi的距离,遍历点云q中所有的点,得到n个平均距离值,根据下式求得点云q在k邻域下的平均距离均值和标准差。
(2.3)采用pca(主成分分析法)求取点云中所有点的法线,具体步骤是:
对任意一点qi∈q,构建其k邻近点{qi1,qi2,…qik}对应的协方差矩阵m:
其中
(3)目标点云边缘点提取
根据(2.3)中得到的法线夹角均值
(4)基于自适应邻域搜索半径的聚类分割
欧式聚类分割是根据点与点之间的欧式距离是否满足所设阈值进行归类的算法,其缺点在于邻域搜索半径是固定的,半径较大或较小容易出现欠分割和过分割的现象。而基于自适应半径阈值的聚类分割方法可以根据点云局部邻域密度自适应确定搜索半径,避免了欠分割或过分割现象的产生,同时提高了算法的速度,其流程如图2所示。具体实现步骤如下:
1)构建非边缘点云p2的kd树,以(2.1)节中求得的点云密度为参考初始化邻域点个数k,由(2.2)求得k邻近点距离均值mean和标准差devia,初始化最小聚类数目min和最大聚类数目max。
2)新建一个空的点云索引向量cluster_indices用于存储聚类结果;新建一个整型向量queue并初始化为空,用于存储单次聚类结果;新建一个bool型向量processed,尺寸和点云p2相同,初始化向量为false,用于表示点云是否被处理过。
3)初始化i=0,对任意一点pi∈p2,执行以下步骤:
a)初始化c=0,将pi点的索引值加入当前序列queue[c],标记该点为已分类,即processed[i]=true;
b)根据序列queue中第c个元素存储的点索引找到其在点云p2中的对应点pc,在kd树中,搜索距离该点最近的(k+1)个点,记作集合
aversinglepoint≤(mean+μ*devia)
rth=max{dist[j],j=1,2...k}
反之,自适应搜索半径rth根据如下公式求得。
c)根据b)求得的搜索半径rth,将位于该半径范围内邻近点的索引加入序列queue,并标记邻近点为已分类,c=c+1;
d)重复步骤b)、c),直到queue中对应的所有点都被处理过,根据如下公式判断该聚类结果是否满足数目要求,若满足,则将queue中所有的点索引放入点云索引向量cluster_indices中,清空队列queue,反之,则舍弃并清空序列queue,i=i+1。
min≤queue.size()≤max
4)重复步骤3),直到点云p2中所有的点都已处理完毕,聚类结果存放在cluster_indices[0],cluster_indices[1]...cluster_indices[num-1]中,将每组点云索引向量中索引在p2中对应的点保存成点云文件输出。
(5)边缘点补齐
经过步骤(4),目标点云p2被分割成num个点云子集,每个子集都代表一个目标工件,表示为{cluster1,cluster2...clusterm},但此时所有子集所表示的工件缺乏边缘部分,边缘的缺失会增大位姿估计的误差,因此需要进行边缘点的修补。根据边缘点与其在点云子集中最邻近点的距离是否满足阈值进行边缘点补齐,过程如下:
1)初始化j=0,初始化阈值thk。
2)构建子集clusterj的kd树,对边缘点云p1中任意一点p1i,计算该点到子集clusterj中最邻近点的欧式距离dj,比较dj和thk大小,若dj<thk,则将p1点归入子集clusterj,并标记该点已处理,反之取下一个边缘点。
3)遍历点云p1中的数据点,检测所有属于子集clusterj的边缘点,完成边缘点补齐。
4)重复步骤2)3),直到所有子集边缘点补齐完全,输出补齐边缘点后的点云子集,完成点云分割。
以上所述仅为说明本发明的实施方式,并不用于限制本发明,对于本领域的技术人员来说,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!