一种为图书添加标签属性的方法与流程
本发明涉及一种为图书添加标签属性的方法,属于数据业务领域。
背景技术:
为了便于用户从图书平台上的海量图书中快速了解、并挑选自己偏好的图书,通常采用标签来描述每本图书的主题内容。为了给每本图书添加符合其内容的标签属性,当前主要依靠图书编辑来人工为图书添加标签属性。这样,在基于标签的图书推荐过程中,经常会遇到图书标签稀少或者缺失的情况。
因此,如何能自动为图书添加符合其内容的标签属性,已成为技术人员急需解决的技术问题,目前还未发现有效的技术解决方案。
技术实现要素:
有鉴于此,本发明的目的是提供一种为图书添加标签属性的方法,能自动为图书添加符合其内容的标签属性。
为了达到上述目的,本发明提供了一种为图书添加标签属性的方法,包括有
步骤一、挑选一定数量的用户作为样本用户,并提取每个样本用户的历史阅读图书记录,然后从样本用户的历史阅读图书所包含的通用标签中挑选多个标签来分别为每个样本用户构成一个偏好标签集,所有样本用户的偏好标签集构成用户偏好标签集群;
步骤二、提取未添加标签图书的所有阅读用户,然后从用户偏好标签集群中寻找所有阅读用户对应的偏好标签集,最后从所有阅读用户的偏好标签集中挑选多个标签作为所述未添加标签图书的标签属性。
与现有技术相比,本发明的有益效果是:本发明通过用户行为来提取用户的偏好标签,当某本图书的大量阅读用户同时具备某个偏好标签时,也就意味着该本图书应具有同样的标签属性,从而实现标签从有标签图书到无标签图书之间的传递。
附图说明
图1是本发明一种为图书添加标签属性的方法的流程图。
图2是步骤一的具体操作流程图。
图3是步骤二的具体操作流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明作进一步的详细描述。
如图1所示,本发明一种为图书添加标签属性的方法,包括有:
步骤一、挑选一定数量的用户作为样本用户,并提取每个样本用户的历史阅读图书记录,然后从样本用户的历史阅读图书所包含的通用标签中挑选多个标签来分别为每个样本用户构成一个偏好标签集,所有样本用户的偏好标签集构成用户偏好标签集群;
步骤二、提取未添加标签图书的所有阅读用户,然后从用户偏好标签集群中寻找所有阅读用户对应的偏好标签集,最后从所有阅读用户的偏好标签集中挑选多个标签作为所述未添加标签图书的标签属性。
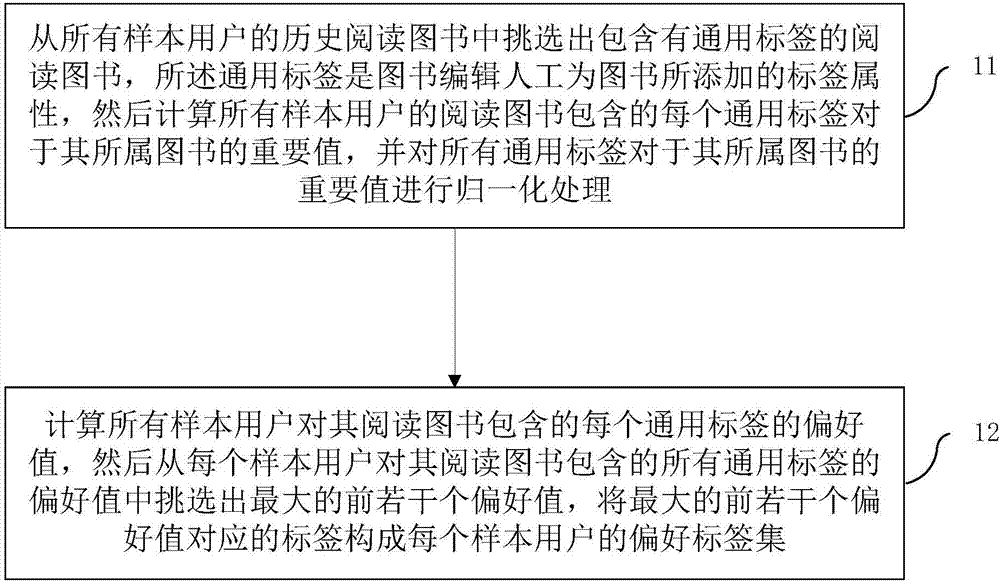
如图2所示,步骤一还可以进一步包括有:
步骤11、从所有样本用户的历史阅读图书中挑选出包含有通用标签的阅读图书,所述通用标签是图书编辑人工为图书所添加的标签属性,然后计算所有样本用户的阅读图书包含的每个通用标签对于其所属图书的重要值:tfidf(li,bj)=tf(bj)×idf(li),其中,tfidf(li,bj)是标签li对于其所属图书bj的重要值,tf(bj)是标签li的词频,idf(li)是标签li的逆向文件频率,并对所有通用标签对于其所属图书的重要值进行归一化处理;
步骤11中,只有对包含通用标签的图书具有一定深度阅读量的用户,才能根据其历史阅读行为,较准确的从所阅读图书的通用标签中挑选出偏好标签,因此,本发明可以根据用户对包含通用标签的图书的深度阅读量来挑选具有代表性的样本用户,例如:深度阅读包含通用标签的图书量大于或等于5本、且少于1000本,进一步的说,tf(bj)的计算公式如下:
步骤12、计算所有样本用户对其阅读图书包含的每个通用标签的偏好值:
步骤二中,本发明除了考虑每个偏好标签的出现频率,还可以根据用户对标签的偏好程度来选择标签,从而能为每本未添加标签属性的图书添加最符合其内容的标签属性。如图3所示,步骤二还可以进一步包括有:
步骤21、获取未添加标签图书的所有阅读用户,为所述未添加标签图书新建一个图书标签集,然后从所有阅读用户的偏好标签集中逐一提取每个偏好标签;
步骤22,计算所提取的偏好标签的出现频率:
步骤23、判断所提取的偏好标签的出现频率是否大于预设值?如果是,则将所提取的偏好标签写入图书标签集中,然后继续下一步;如果否,则转向步骤25;例如,预设值可以是20%;
步骤24、计算所提取的偏好标签的用户偏好平均值:
步骤25、判断所有阅读用户的偏好标签集中是否还有未提取的偏好标签?如果是,则继续提取下一个未提取的偏好标签,然后转向步骤22;如果否,则继续下一步;
步骤26、从图书标签集的所有标签中,挑选出其用户偏好平均值最大的前若干个标签,并将其他未挑选的标签从图书标签集中删除;
步骤27、将图书标签集中的所有标签添加为所述未添加标签图书的标签属性。
本发明采用已有标签的图书作为测试集进行试验,根据实验证明,图书的原有标签都保留在本发明计算所获得的标签集中,因而充分说明,通过实施本发明方法,能为图书自动添加符合其实际内容的标签属性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!