基于最优分割法的运营商营销渠道价值评估方法与流程
本发明属于价值评估技术领域,具体是涉及一种基于最优分割法的运营商营销渠道价值评估方法。
背景技术:
目前,一方面运营商在营销渠道管理方面的投入日益加大,但是投入成本的加大,并未有效解决管理方面的问题,因此必须合理控制成本,将有限的资源向高价值渠道倾斜,提升资源利用率,确保运营商在运营渠道管理方面的竞争优势;另一方面,营销渠道数量虽然多,但部分渠道极不规范,鱼龙混杂其间,多数规模小,缺乏连锁的规模优势,管理难度大,自我约束能力弱,违规从事批发业务渠道较多,“跨区”经营时有发生,价格战层出不穷,另外缺乏对渠道运营状况快捷有效的监控,无法及时捕捉渠道运营异常信息;这就需要对营销渠道客观评估,识别优质渠道,优化渠道管理队伍,建立分层分级渠道价值评估体系。
通讯领域营销渠道价值评估基本直接采用平衡计分卡法进行评估,虽然理论上能够体现渠道价值,但在评估过程中主观因素较多,如:在设置指标权重中,基本都采用凭靠业务经验主观定位权重占比,导致部门问题门店未能及时体现。
另外在门店价值评估过程中还有其它因素会影响整个门店价值评估的结果,实体门店运营过程中由于管理规范的原因个别指标会出现极值的现象,如:目前甩单政策执行,部分门店只进行记录客户资料,业务受理集中在一个门店进行,导致承接受理业务的门店业务量很大,或校园门店在开学期间业务量剧增;如果在价值评估过程中不剔除这些极值指标将影响整个评估模型的准确性。
另外平衡计分卡评估门店只能依据门店的整体得分来查看门店好与坏,给予管理层提供一个参考值,未通过有效手段对门店评估结果进行有效分割,如:找出收入很高但风险也很高等类型的门店;并不能反映门店的问题所在,从而导致门店后期的发展重点不明。
综上所述,目前实体门店价值评估方法,由于评估过程中主观因素较多、管理规范的原因个别指标会出现极值的现象、未通过有效手段对门店评估结果进行有效分割从而不能反映门店的问题所在等原因,不能比较精确地对实体门店进行价值评估。因此,需要一种新型的实体门店价值评估方法。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,由于评估过程中主观因素较多、管理规范的原因个别指标会出现极值的现象、未通过有效手段对门店评估结果进行有效分割从而不能反映门店的问题所在等,不能比较精确地对实体门店进行价值评估,从而不能实现对实体门店的优化管理,本发明提供一种基于最优分割法的运营商营销渠道价值评估方法,从营销渠道的效益、规模、风险和服务四方面对生产运营数据利用数据挖掘分析方法,量化分析影响渠道运营生产各种属性,构建分层分级的渠道效能评估模型,识别优质、高价值渠道,并及时捕捉渠道运营异常信息,从而促进渠道的有效有序发展。
技术方案:为实现上述目的,本发明的基于最优分割法的运营商营销渠道价值评估方法,包括以下步骤:
a:梳理评估指标;
b:将评估指标各项关联属性转换为系统可处理的字段格式;
c:采集数据源并将数据源加载到数据库中,然后对数据进行处理,得到指标数据表;
d:对评估指标对应的指标数据源进行计算,并将结果最终汇聚到对应的门店,得到原始数据矩阵;
e:将原始数据矩阵归一化得到归一化指标数据矩阵;
f:采用熵值法测算各评估指标在评估模型中的权重;
g:计算得到门店分别在收益、规模、风险和服务四个维度上的得分;
h:将评估的门店分为八个象限,即:高收益高规模高风险,高收益高规模低风险,高收益低规模低风险,高收益低规模高风险,低收益高规模高风险,低收益高规模低风险,低收益低规模高风险,低收益低规模低风险;并分别计算门店所属象限类型;
i:最后采用最优分割法对门店进行评级。
进一步地,所述步骤a中,按照效益、规模、风险和服务四个纬度进行梳理评估指标;按照效益纬度进行梳理参与评估的指标包括渠道投入产出比、百元成本拉动收入、渠道收入增长率、发展增长率和户均投入,按照规模纬度进行梳理参与评估的指标包括新发展移动、宽带、净增用户数和完成率,按照风险纬度进行梳理参与评估的指标包括活跃用户占比、月均arpu、离网率、平均在网时长、户均流量、出账率、欠费率、融合套餐占比和高值套餐占比,按照服务进行梳理参与评估的指标包括面积、人员总数、促销员比例、区域、客户满意度和人均办理业务量。
进一步地,所述步骤c中,通过powercenteretl工具进行自动同步测算需要的指标数据源。
进一步地,所述步骤d包括以下步骤:对采集的指标数据源通过sql分组,通过引用sql中groupby分组功能将数据源分组到对应的指标,通过sql中sum求和功能对评估指标对应的指标数据源进行计算,并将结果最终汇聚到对应的门店。
进一步地,所述步骤d中,在参与评估的门店中评价指标的评价系统中,按指标分别剔除各自的极值。
进一步地,所述步骤e中,
对上述原始数据矩阵归一化:
正向指标是指指标值越大越好的指标,包括收益、规模和服务;负向指标是指指标值越小越好的指标,包括风险;
对上述原始数据矩阵正向指标归一化按计算公式(一)计算:
其中,i=(1,2,...,m),j=(1,2,...,n),aij为第i个门店的第j项指标值,
对上述原始数据矩阵负向指标归一化按计算公式(二)计算:
其中,i=(1,2,...,m),j=(1,2,...,n),aij为第i个门店的第j项指标值,
进一步地,所述步骤f中,
采用熵值法测算各评估指标在评估模型中的权重,参照计算公式(3)~公式(6)
k=1/lnm公式(6)
其中,公式(5)中aij为第i个门店的第j项指标值,门店包括m个,指标包括n个,i=(1,2,...,m),j=(1,2,...,n)。
进一步地,所述步骤g中,
按照下述公式计算得到门店i分别在收益、规模、风险和服务四个维度上的得分,收益、规模、风险和服务四个维度分别对应的指标个数为n1、n2、n3、n4,且n1+n2+n3+n4=n;
则门店i在收益维度上的得分为:
门店i在规模维度上的得分为:
门店i在风险维度上的得分为:
门店i在服务维度上的得分为:
得到门店i在收益、规模、风险和服务四个维度上的得分。
进一步地,所述步骤h中,
计算m个门店在收益维度上的得分均值,m个门店在规模维度上的得分均值,m个门店在风险维度上的得分均值,m个门店在服务维度上的得分均值;
将门店i在收益、规模、风险和服务四个维度上的得分分别与四个维度上的得分均值比较,若高于均值,则为高值指标,否则为低值指标;
根据门店的效益、规模、风险、服务的得分,利用sql语言按照k1*效益+k2*规模+k3*风险+k4*服务的算法计算门店的综合得分。
进一步地,取k1=30%,k2=30%,k3=30%,k4=10%。
有益效果:本发明与现有技术比较,具有的优点是:
1、本发明的一种基于最优分割法的运营商营销渠道价值评估方法,从营销渠道的效益、规模、风险和服务四方面对生产运营数据利用数据挖掘分析方法,量化分析影响渠道运营生产各种属性,构建分层分级的渠道效能评估模型,识别优质、高价值渠道,并及时捕捉渠道运营异常信息,从而促进渠道的有效有序发展;
2、本发明的运营商营销渠道价值评估方法可以较为准确地对营销渠道进行价值评估;
3、本发明方法中最优分割法将门店依据评估结果进行有效分割,从而反映门店的问题所在,进一步比较精确地对实体门店进行价值评估。
附图说明
图1是本发明的价值评估指标四个维度示意图。
图2是本发明运营商营销渠道价值评估方法流程示意图一。
图3是本发明运营商营销渠道价值评估方法中数据准备过程示意图。
图4是本发明运营商营销渠道价值评估方法流程示意图二。
具体实施方式
下面结合附图对本发明作更进一步的说明。
梳理评估指标:
参照图1,按照效益、规模、风险和服务四个纬度进行梳理评估指标;
按照效益纬度进行梳理参与评估的指标包括渠道投入产出比、百元成本拉动收入、渠道收入增长率、发展增长率和户均投入等,按照规模纬度进行梳理参与评估的指标包括新发展移动、宽带、净增用户数和完成率等,按照风险纬度进行梳理参与评估的指标包括活跃用户占比、月均arpu、离网率、平均在网时长、户均流量、出账率、欠费率、融合套餐占比和高值套餐占比等,按照服务进行梳理参与评估的指标包括面积、人员总数、促销员比例、区域、客户满意度和人均办理业务量等;
将评估指标各项关联属性转换为系统可处理的字段格式,指标配置表如下表1所示:
表1
上述表1中,评估指标涉及到的字段包括指标编码、指标名称、指标解释(基础指标存放口径,衍生指标存放计算公式)、地市、指标单位、指标类别id、指标类别名称、数据格式、展现顺序、指标类型(1基础指标,2衍生指标)、指标状态(1生效,0失效)、数据来源、指标创建人和指标创建时间,字段名称为指标编码对应的字段编码为kpi_id,字段名称为指标名称对应的字段编码为kpi_nm,字段名称为指标解释对应的字段编码为kpi_desc,字段名称为地市对应的字段编码为city_id,字段名称为指标单位kpi_unit_tp,指标类别id为kpi_tree_id,指标类别名称为kpi_tree_nm,数据格式为frmt_tp,展现顺序为show_order,指标类型为kpi_tp,指标状态为kpi_st,数据来源为data_src,指标创建人为crtd_user,指标创建时间为crtd_tmst;
上述评估指标包括基础指标和衍生指标,其中衍生指标通过基础指标的组合运算派生出来,渠道分析人员依据评估运营经验通过界面配置衍生指标,衍生指标计算方式:依据基础指标并结合加、减、乘、除等公式配置衍生指标的计算方法,如:天翼净增用户=天翼当月出账用户-去年12月份出账用户,系统依据配置的公式进行自动计算;例如基础指标:百元成本拉动收入,衍生指标:渠道投入产出比、渠道收入增长率;
在门店价值评估过程中,定义基础指标和衍生指标,可以进一步体现各指标类型对应的指标对价值评估结果的贡献程度;
参照图2和图3,采集数据源并将数据源加载到数据库中,然后对数据进行处理;
通过数据同步工具进行自动同步测算需要的指标数据源;
通过powercenteretl工具进行自动同步测算需要的指标数据源;
依据上述步骤中设置的指标配置表对应的指标配置信息,通过powercenteretl工具从计费、bss和佣金结算等系统中获取用户收入,天翼、宽带等发展量,代理商酬金和补贴等清单级数据,并加载到oracle数据库中;
将指标数据源用sql语言描述,为了进一步被系统可处理;
指标数据在系统中对应的字段如下指标数据表所示:
表2
对采集的指标数据源通过sql分组,通过引用sql中groupby分组功能将数据源分组到对应的指标,通过sql中sum求和功能对评估指标对应的指标数据源进行计算,并将结果最终汇聚到对应的门店;
如:最终计算得到门店a对应天翼发展量20个,宽带10户等;
在m个参与评估的门店中n个评价指标的评价系统中,按指标分别剔除各自的极值,避免个别极值影响整个模型的准确性;
按指标分别剔除各自的极值,将指标极值设定为2%,即在得到最终的指标值过程中,用于计算的离散数据源中设定2%的离散数据源为极值,在计算过程中将该2%的离散数据源(极值)剔除;
例如,在一次价值评估过程中,参数设定:m:500个门店,n:50个参与评价的指标个数,x:2%指标极值百分比;
通过上述步骤得到原始数据矩阵(原始数据源):如下表所示:
表3
表3中,包括门店和指标两种属性,门店包括m个,指标包括n个,i=(1,2,...,m),j=(1,2,...,n),aij表示第i个门店的第j项指标值,得到m×n的原始数据矩阵;
对上述原始数据矩阵归一化:
正向指标是指指标值越大越好的指标,包括收益、规模和服务;负向指标是指指标值越小越好的指标,包括风险;
对上述原始数据矩阵正向指标归一化按计算公式(一)计算:
其中,i=(1,2,...,m),j=(1,2,...,n),aij为第i个门店的第j项指标值,
对上述原始数据矩阵负向指标归一化按计算公式(二)计算:
其中,i=(1,2,...,m),j=(1,2,...,n),aij为第i个门店的第j项指标值,
最终得到的归一化指标数据矩阵如下:
采用熵值法测算各评估指标在评估模型中的权重:ωj(j=1,2,...,n),其中ωj是指第j个指标熵权重,共有n个指标,采用熵值法测算各评估指标在评估模型中的权重,参照计算公式(3)~公式(6)
k=1/lnm公式(6)
其中,公式(5)中aij为第i个门店的第j项指标值,门店包括m个,指标包括n个,i=(1,2,...,m),j=(1,2,...,n);
按照下述公式计算得到门店i分别在收益、规模、风险和服务四个维度上的得分,收益、规模、风险和服务四个维度分别对应的指标个数为n1、n2、n3、n4,且n1+n2+n3+n4=n;
则门店i在收益维度上的得分为:
门店i在规模维度上的得分为:
门店i在风险维度上的得分为:
门店i在服务维度上的得分为:
得到门店i在收益、规模、风险和服务四个维度上的得分;
计算m个门店在收益维度上的得分均值,m个门店在规模维度上的得分均值,m个门店在风险维度上的得分均值,m个门店在服务维度上的得分均值;
将门店i在收益、规模、风险和服务四个维度上的得分分别与四个维度上的得分均值比较,若高于均值,则为高值指标,否则为低值指标;
将参与评估的门店分为八个象限,即:高收益高规模高风险,高收益高规模低风险,高收益低规模低风险,高收益低规模高风险,低收益高规模高风险,低收益高规模低风险,低收益低规模高风险,低收益低规模低风险;
如:a门店收益高于均值,规模高于均值,且风险低于均值,则该门店为高收益高规模低风险类门店;
根据门店的效益、规模、风险、服务的得分,利用sql语言按照k1*效益+k2*规模+k3*风险+k4*服务的算法计算门店的综合得分;其中k值为电信运营分析中通用参数,本实施例采用:k1:30%,k2:30%,k3:30%,k4:10%;k1:30%,k2:30%,k3:30%,k4:10%采用该实施例更能体现价值评估的准确性。
最后采用最优分割法对门店进行评级:
通过sql语言orderby函数对门店综合得分按从大到小进行排名,形成有序数据序列(这样做的目的:减少程序运算量,且保证数据均匀的分散在调查总体中,不会集中某些层次,增加样本的代表性)。
首先将m个门店得分按顺序分割为3段,使组内离差平方和尽可能小,而组间离差平方尽可能大,能够清晰的将门店评估为3个等级:优秀、中等、劣质;
分别针对优秀、中等、劣质的门店在进行操作:
首先通过sql查询出参与评估门店的最低分和最高分,作为分段起点和终点,两点之间预设置两个点i和j为,为此,用{xi,xi+1,…,xj}表示从第i个门店数据开始至第j个门店数据为止的某段门店数据,其中1≤i≤j≤n;该段门店变量的离差平方和为
实施例二:
基于实施例一,效益评价模型的计算主要通过三个线程队列自动完成所有工作,数据封装队列、计算队列和告警队列;
数据封装队列:通过etl工具获取本次评估需要的指标数据,如:计费系统用户收入数据,bss系统的天翼,宽带发展量数据,佣金系统代理商酬金和补贴等数据源,线程依据指标配置的计算周期(默认每月1号凌晨2点执行)自动循环检测指标数据源是否到位,如果数据源到位,则把评估执行任务节点修改成数据源就绪、等待指标计算,否则继续循环检测,若超过设置预警时限(预定时间24小时之后)自动把待计算指标编码推送到告警线程进行短信或邮件告警。
计算队列:依据预先编写的sql脚本对指标数据源进行计算、汇聚等工作,计算队列循环检测任务表中是否存在等待指标计算流程节点,如果存在系统自动按照评估参数配置中的纬度、指标等信息进行测算和数据汇聚,若出现异常计算终止并回滚,记录异常信息推送到告警线程进行告警和人工干预,主要完成如计算权重、指标汇聚、门店象限分布计算和门店评级测算等工作
告警队列:主要负责在整个评估过程中出现的未知问题进行实时告警支撑人员。
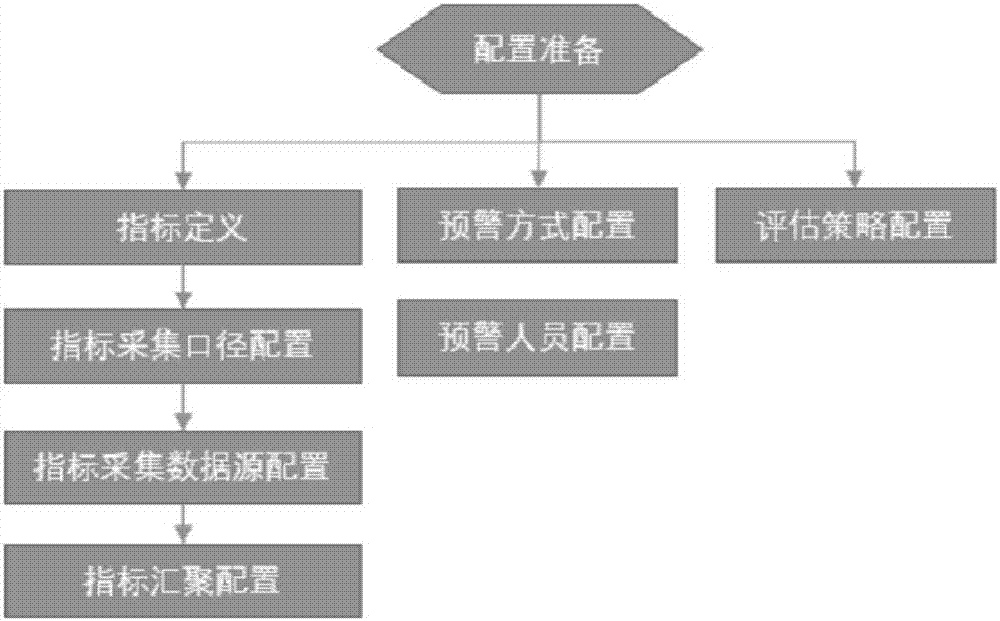
评估参数配置说明:
指标采集数据源配置:参与评估的指标散落在各生产系统,需要配置生产指标对应外部系统的数据库,数据表及字段,主要用于门店评估指标数据源采集;如配置天翼,宽带发展指标采集数据源,
数据库ip:132.xxx.xxx.xx
service_name:xxxx
登录帐号:xxxx
密码:xxxx
数据表:fct_chnl_busi_xxxx
字段:tyxl:天翼销量,kdfz:宽带发展量
异常预警配置:配置计算异常告警方式及人员等;
指标汇聚配置:配置门店评估数据向上汇聚使用的组织树,如:江苏省-南京市-鼓楼区=xx支局-xx门店,门店评估结果将按照门店维护向上逐级汇聚
评估策略配置:配置评估计算策略,配置数据采集队列开始执行时间(默认每月1号凌晨2点),极值剔除比例配置默认值(默认2%);
指标值中间表:存放参与计算指标的数据源信息,该表为原始未清洗数据
检测数据到位:检测计算指标是否全部到位,只有参与计算的所有指标到位之后清洗队列才进行执行,发现存在未到位数据进行预警,采集队列继续等待
数据清洗:将采集的数据源按照极值剔除,重复记录的检测及剔除和不一致数据进行清理,具体步骤如下:
1.重复记录的检测及剔除,按照购物车编码、产品实例id剔除重复数据
2.数据一致性清理,对比生产系统指标数据源中受理门店如果不存在门店管理关系中,则进行剔除
3.按照预先设置的极值测算比例进行剔除在极值范围内的指标数据
计算指标宽表:数据封装队列对采集的指标数据源,按照清洗步骤进行清洗,并把清洗结果存放到计算指标宽表
指标权重计算:采用熵值法客观测算各指标在评估模型中的权重,通过sql语言封装成数据库的存储过程实现熵值法计算指标权重过程
门店评估计算:依据指标和计算出的指标权重,通过sql根据各自指标熵权重ωi乘以rij矩阵归一化后的标准化数据,得到各个因子的总得分,其次根据门店的效益、规模、风险、服务的得分,再次利用sql语言按照k1*效益+k2*规模+k3*风险+k4*服务的算法计算门店的综合得分;
实施例三:
基于实施例一,本实施例方法包括以下步骤:
步骤一:配置评估执行的策略
按照业务需要配置评估中涉及的参数,数据汇聚方式及执行策略等,如:配置采集指标对应的生产系统数据库及字段,数据汇聚的方式行政组织或营销组织进行向上汇聚,计算程序执行的策略(按天/月/季度及执行的时间点),并配置程序异常预警对象或方式等;见图2
步骤二:数据源采集与清洗
首先依据配置信息和业务规则采集各个生产系统门店对应的指标值,并通过etl工具定时同步指标数据源;
其次依据规则对采集数据源通过sql语言关联进行清洗和校验,删除重复数据、纠正存在的错误,补充残缺数据,并提供数据一致性,如:发展量数据重复,指标对应门店已关闭等;数据清洗完毕系统自动导入参与计算的指标宽表,如下表4所示:
表4
步骤三:门店运营指标数据计算
门店纬度指标数据宽表到位之后,系统按照预先配置的执行策略自动调用权重计算程序,计算出用于评估中各指标间权重值;
权重占比计算完成之后系统依据指标值、权重等信息自动计算门店得分情况,并按照组织树(省-市-区县-支局-片区-门店)进行向上汇聚;把计算出的门店得分按照由高到低进行排序并导入到待评级宽表;见图4
步骤四:门店象限分布计算
按收益、发展和风险三个维度,分别根据各自指标熵权重ωi乘以rij矩阵归一化后的标准化数据,得到各个因子的总得分,如果各因子得分高于所有门店均值为高值指标,否则为底值指标,按照此方法将参与评估的门店分为八个象限;
步骤五:门店评级计算
首先根据门店的效益、规模、风险、服务的得分,利用sql语言按照k1*效益+k2*规模+k3*风险+k4*服务的算法计算门店的综合得分。
将这n个门店得分按顺序分割为3段,使组内离差平方和尽可能小,而组间离差平方尽可能大,能够清晰的将门店评估为3个等级:优秀、中等、劣质;
分段的分割方式:
首先通过sql查询出参与评估门店的最低分和最高分,作为分段起点和终点,两点之间预设置两个点i和j,为此,用{xi,xi+1,…,xj}表示从第i个门店数据开始至第j个门店数据为止的某段门店数据,其中1≤i≤j≤n;该段门店变量的离差平方和为
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!