一种基于字典学习的车牌识别方法与流程
本发明涉及一种基于字典学习的车牌识别方法,属于数字图像处理领域。
背景技术:
随着互联网技术的不断发展和人们生活水平的不断提高,越来越多的人家拥有一辆代步的汽车,有的家庭甚至不止一辆。
当车辆进入停车场时,需要电子登记车辆的号牌信息,当车辆驶出停车场时,需要自动识别出车辆的号牌信息,停车时间以及缴费情况。车牌的自动识别是停车场自动管理的基础,因此车牌的自动识别具有很强的重要性。
现有的车牌识别技术多是基于图像处理方法的,有些需要提取特征点进行匹配,运算时间较长,且结果不是很精确,存在误识别的情况,而本发明的算法是基于字典学习的车牌识别方法,一次采集训练图像进行字典学习后就不需再进行字典学习了,每次新的待识别图像进入系统时,只需要进行稀疏表示,求得待识别图像在已知车牌字典下的稀疏表示系数,再对其系数的1范数进行判断,最大值所对应的字母或者数字即所求,运算速度很快,基本可以做到实时。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供一种基于字典学习的车牌识别方法,旨在快速、方便的识别待识别车牌。
技术方案:为实现上述目的,本发明采用的技术方案为:
一种基于字典学习的车牌识别方法,包括以下步骤:
步骤1)收集清晰的已知车牌图像,提取车牌区域,缩放至同样大小,人工标记并分割每个字母和数字,标记分割完的已知车牌图像作为训练库样本;
步骤2)基于字典学习算法训练已知车牌字典,得到车牌字母或数字所对应的已知车牌字典和相应的稀疏表示系数;
步骤3)当拍到一幅包含车牌的待识别图像时,进行预处理,利用hsv空间找到待识别车牌所在蓝色区域,提取待识别车牌区域,将其缩放至与字典学习训练前已知车牌图像同样的大小,平均分割每个字母或数字,得到待识别数字图像;
步骤4)将预处理后的待识别数字图像在已知车牌字典下稀疏表示,得到一组稀疏系数,稀疏系数的1范数最大的那列表示预处理后的待识别数字图像在已知车牌字典的该原子下最稀疏,因此待识别数字图像应该为该原子代表的数字或字母;
步骤5)将所有待识别数字图像都进行步骤4)的处理后,按顺序拼起来就是待求的车牌号。
优选的:所述字典学习算法采用k-svd算法。
优选的:所述稀疏表示求解时采用迭代收缩阈值法。
优选的:所述稀疏表示中稀疏性的约束采用1范数。
优选的:所述车牌区域缩放至的大小为140×440像素。
本发明相比现有技术,具有以下有益效果:
1.一次采集训练图像进行字典学习后就不需再进行字典学习了,接下来每来一幅新的预处理后的待识别图像,就利用求得的已知车牌字典进行稀疏表示求解,求得待识别图像在已知车牌字典下的稀疏表示系数,再对其系数的1范数进行判断,最大值所对应的字母或者数字即所求待识别车牌号码。
2.步骤简单,运算时间短,基本可以做到实时求解。
附图说明
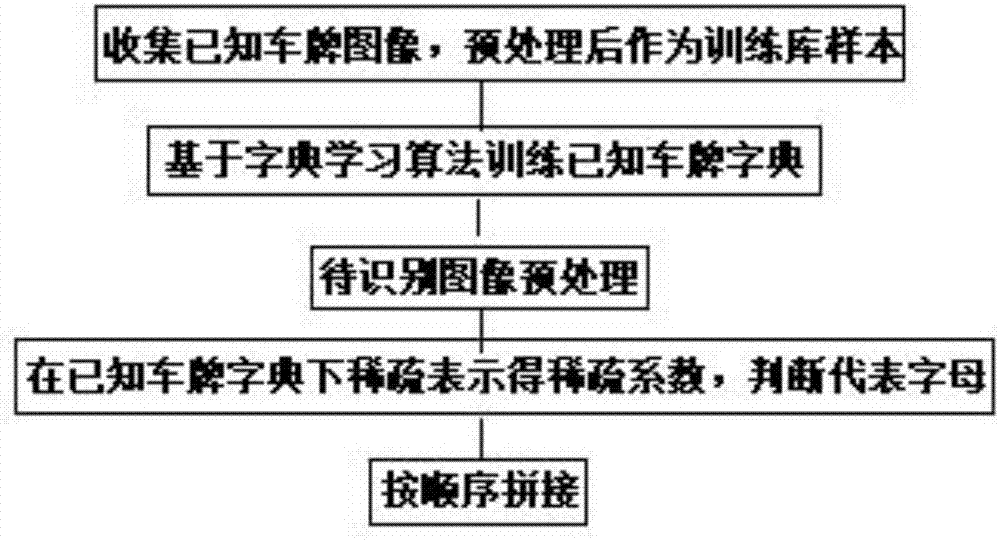
图1为本发明一种基于字典学习的车牌识别方法的算法流程图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
如图1所示为一种基于字典学习的车牌识别方法的算法流程图,包括以下步骤:
步骤1)收集清晰的已知车牌图像,提取车牌区域,缩放至同样大小,人工标记并分割每个字母和数字,标记分割完的已知车牌图像作为训练库样本;
步骤2)基于字典学习算法训练已知车牌字典,得到车牌字母或数字所对应的已知车牌字典和相应的稀疏表示系数;
步骤3)当拍到一幅包含车牌的待识别图像时,进行预处理,利用hsv空间找到待识别车牌所在蓝色区域,提取待识别车牌区域,将其缩放至与字典学习训练前已知车牌图像同样的大小,平均分割每个字母或数字,得到待识别数字图像;
步骤4)将预处理后的待识别数字图像在已知车牌字典下稀疏表示,得到一组稀疏系数,稀疏系数的1范数最大的那列表示预处理后的待识别数字图像在已知车牌字典的该原子下最稀疏,因此待识别数字图像应该为该原子代表的数字或字母;
步骤5)将所有待识别数字图像都进行步骤4)的处理后,按顺序拼起来就是待求的车牌号。
所述字典学习算法采用k-svd算法。
所述稀疏表示求解时采用迭代收缩阈值法。
所述稀疏表示中稀疏性的约束采用1范数。
所述车牌区域缩放至的大小为140×440像素。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
技术特征:
技术总结
本发明公开了一种基于字典学习的车牌识别方法,包括以下步骤:收集清晰的已知车牌图像,提取车牌区域,人工标记并分割每个字母和数字,标记分割完的已知车牌图像作为训练库样本;基于字典学习算法训练已知车牌字典,得到车牌字母或数字所对应的已知车牌字典和相应的稀疏表示系数;当拍到一幅包含车牌的待识别图像时,进行预处理,得到待识别数字图像;将预处理后的待识别数字图像在已知车牌字典下稀疏表示,得到一组稀疏系数,稀疏系数的1范数最大的那列表示该原子代表的数字或字母为待识别数字图像所求的数字或字母;将所有待识别数字图像都进行前一步的处理后,按顺序拼起来就是待求的车牌号。
技术研发人员:林夏民
受保护的技术使用者:南京锦冠汽车零部件有限公司
技术研发日:2017.08.25
技术公布日:2019.03.05
- 还没有人留言评论。精彩留言会获得点赞!