一种特定真人行为快速建模方法与流程
本发明涉及一种行为建模方法,特别涉及一种特定真人行为快速建模方法。
背景技术:
2017年7月8日,国务院印发了国发〔2017〕35号关于新一代人工智能发展规划的通知。其中提到人工智能的迅速发展将深刻改变人类社会生活、改变世界。而人工智能对人类行为的模拟、仿真、学习正是人机交互的桥梁,人工智能通过仿真沟通学习人类的动作行为来实现智能化、拟人化,从而更进一步实现人工智能社会化服务。
目前人工智能对人类行为的仿真学习,主要是通过场景设计以及计算机辅助技术来实现,例如通过穿戴传感节点骨架并借助计算机采集分析真人行为动作数据、通过拍摄真人行为视频图像或借助增强现实技术(ar)实现提取三维仿真行为特征数据、通过植入模型数据库以及借助神经算法实现逻辑推理等。但是这样的仿真建模学习过程耗时太长,需要花费大量的时间与成本来、拍摄、采集、建库、分析、提取特征行为数据。因此不利于将至快速应用于商业社会化活动中实现快速推广,也因此制约了快速商业化行为对人工智能的促进发展。
而在科学家们研究机器人仿真行为研究过程中提出的社会化思维理论,认为一个人的社会活动、社交活动中,他的思维有定势可循,行为举止套路化。因此可以依此理论提出一种能够针对特定真人的特定行为进行快速商业化建模的方法。
技术实现要素:
为了解决上述现有技术不能快速建模的问题,本发明提供了一种特定真人行为快速建模方法应用于商业化真人行为快速建模。
本发明所采用的技术方案是:一种特定真人行为快速建模方法,包括:
sa、采集特定真人形体动作和/或语音:
sa1、选取并设计特定社会活动;
sa2、选定特定真人执行特定社会活动;
sa3、同步采集特定真人的形体动作和/或语音作为样本:以特定真人为采集对象,采集其在进行特定社会活动时的行为形体动作样本和/或语音样本;
sb、划分形体动作样组单元:
sb1、对形体动作样本和/或语音样本划分样组:将步骤sa3采集所得的形体动作样本和/或语音样本根据动作思维和/或语言逻辑断点划分样组;
sb2、划分子样组:将步骤sb1划分后各样组内的形体动作样本以帧为单位按自定义数量划分子样组;
sb3、划分样组单元:将步骤sb3的子样组的各帧图像,以形体动作重合误差的百分比小于某个自定义值为参考依据,划分样组单元;
sc、建立特定真人模型:
sc1、优化处理样本:重组、提取、编辑、优化步骤sb3样组单元内的形体动作样本和/或语音样本并存储;
sc2、定义样本标签:将步骤sc1所存储的形体动作样本自定义样本标签,或者以语音样本按语音内容分析提取关键文字并按关键文字定义样本标签;
sc3、生成样本特征数据库:以步骤sc1中优化后的形体动作样本和/或语音样本为样本特征,与步骤sc2中所定义的样本标签建立对应联系关系,生成特定真人的样本特征数据库,实现对特定真人行为的快速建模。
作为优选,所述步骤sb1中的思维逻辑断点包括:语音对话逻辑断点、或形体动作停顿逻辑断点、或形体动作转折逻辑断点。
与现有技术相比,本发明的有益效果是:
1、在语音、视觉上实现对特定真人的社会化活动95%的相似性仿真。
2、本方法是以特定真人进行特定社会商业活动来实现最终建模的,相比现有技术中需要大范围不间断的录制采集提取的建模方式,针对性更强,适用性更强,建模过程更快,实现更容易。
附图说明
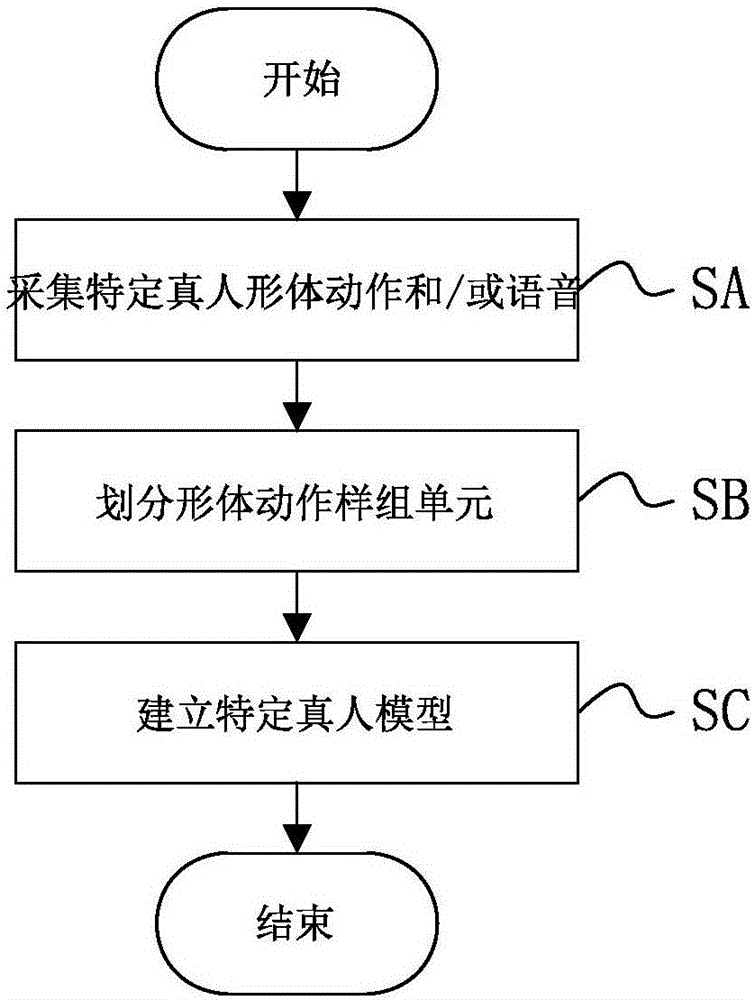
图1为本发明一种特定真人行为快速建模方法步骤简图;
图2为本发明一种特定真人行为快速建模方法步骤流程图;
图3为本发明一种特定真人行为快速建模方法重要步骤说明图1;
图4为本发明一种特定真人行为快速建模方法重要步骤说明图2;
图5为本发明一种特定真人行为快速建模方法场景示意图。
具体实施方式
下面结合附图对本发明进一步说明。
本发明一种特定真人行为快速建模方法所依据的理论为“社会化思维”理论,该理论概要认为一个人的社会活动、社交活动中,他的思维是定势可循,行为举止是套路化的;因此在对某特定真人在特定社会活动中的行为和思维的片段化提取和智能重组,就能达成95%相似性的重现这个人的特定社会化活动。因此本发明一种特定真人行为快速建模方法并非要实现对特定真人行为的100%仿真,只需能够在达成相对相似,使特定真人的特定行为特征集能够实现广泛商业应用,使所建立的特定真人模型能够实现与普通用户进行类真人化的行为交流和语言交流。
如图1所示,图1为本发明一种特定真人行为快速建模方法步骤简图。其快速建模方法步骤简图包括:
sa、采集特定真人形体动作和/或语音;
sb、划分形体动作样组单元;
sc、建立特定真人模型。
如图2所示,图2为本发明一种特定真人行为快速建模方法步骤流程图。其快速建模方法包括如下步骤:
sa、采集特定真人形体动作和/或语音:
sa1、选取并设计特定社会活动;
sa2、选定特定真人执行特定社会活动;
sa3、同步采集特定真人的形体动作和/或语音作为样本:以特定真人为采集对象,采集其在进行特定社会活动时的行为形体动作和/或语音作为样本;
sb、划分形体动作样组单元:
sb1、划分形体动作样本和/或语音样组:将步骤sa3采集所得的形体动作样本和/或语音样本根据动作思维和/或语言逻辑断点划分样组;
sb2、划分子样组:将步骤sb1划分后各样组内的形体动作样本以帧为单位按自定义数量划分子样组;
sb3、划分样组单元:将步骤sb3的子样组的各帧图像,以形体动作重合误差的百分比小于某个自定义值为参考依据,划分样组单元;
sc、建立特定真人模型:
sc1、优化处理样本:重组、提取、编辑、优化步骤sb3样组单元内的形体动作样本和/或语音样本并存储;
sc2、定义样本标签:将步骤sc1所存储的形体动作样本自定义样本标签,或者以语音样本按语音内容分析提取关键文字并按关键文字定义样本标签;
sc3、生成样本特征数据库:以步骤sc1中优化后的形体动作样本和/或语音样本为样本特征,与步骤sc2中所定义的样本标签建立对应联系关系,生成特定真人的样本特征数据库,实现对特定真人行为的快速建模。
图3为本发明一种特定真人行为快速建模方法重要步骤说明图1。在该图中主要包括四组关联图,分别为图3a、图3b、图3c、图3d。由于该图说明的是同步采集了特定真人的形体动作和语音作为样本的情况,所以这四幅图中的标记a2、标记b2、标记c2、标记d2指示的是语音样本;标记a1、标记b1、标记c1、标记c1指示的是形体动作样本。图中,虚线表示的形体动作样本与语音样本为原始采集样本,实线表示的形体动作样本与语音样本为优化处理后的样本。
具体的,图3a对应于图2中的步骤sb1:划分形体动作样本和/或语音样组:将步骤sa3采集所得的形体动作样本和/或语音样本根据动作思维和/或语言逻辑断点划分样组。如图,形体动作样本a1和语音样本a2同步对应于时间轴nt,其中语音样本a2出现两次逻辑断点,以此为划分依据,将整个时间轴nt上的形体动作样本a1与语音样本a2划分为6t、3t、7t这三段,并分别对应于x段、y段、z段。由该图标记a1指示的形体动作样本上的连续帧图像集,还能演示并看出形体动作样本的连续和动作变化。
图3b对应于图2中的步骤sb2:划分子样组:将步骤sb1划分后各样组内的形体动作样本以帧为单位按自定义数量划分子样组。如图,形体动作样本b1与语音样本b2选取的是图3a中的x段,其动作样本b1共包括了四个中共包括了四个类同的形体动作,例如共包括了16帧图像,所以以4帧图像为1个子样组,将x段样本划分为1x/4、2x/4、3x/4、4x/4这四个子样组。因此划分子样组后形成图3b。
图3c对应于图2中的步骤sb3:划分样组单元:将步骤sb3的各帧的子样组,以形体动作重合误差的百分比小于某个自定义值为参考依据,划分样组单元。如图,形体动作样本c1与语音样本c2为是图3b中的x段,其动作样本c1共包括了四个中共包括了四个类同的形体动作,但是在图3b的1x/4子样组上出现了两种形体动作,因此依照形体动作重合误差超过了预设值的判断,需要将1x/4子样组上的这两种动作再次分组,分为1x样组单元和2x样组单元;图3b的2x/4子样组上只出现一种形体动作,所以其为3x样组单元;图3b的3x/4子样组上也出现了两种形体动作,因此依照形体动作重合误差超过了预设值的判断,需要将3x/4子样组上的这两种动作再次分组,分为4x样组单元和5x样组单元;图3b的4x/4子样组上只出现一种形体动作,所以其为6x样组单元;因此图3b在划分样组单元后形成图3c。
图3d对应于图2中的步骤sc1:优化处理样本:重组、提取、编辑、优化步骤sb3样组单元内的形体动作样本和/或语音样本并存储。通过重组图3c中形体动作样本的1x、2x、3x、4x、5x、6x样组单元,形成新的形成x1、x2、x3、x4样组单元;其中由于2x、3x、4x样组单元的形体动作类同,因此重组合并后变成x2样组单元。再从x1、x2、x3、x4样组单元的动作样本中提取出典型动作帧图像,进行编辑、图像优化后存储。
图4为本发明一种特定真人行为快速建模方法重要步骤说明图2。该图与图3所描述的不同之处在于,真实采集过程中,存在特定真人的只有形体动作而没有产生语音的情况,所以不存在语言逻辑断点,在步骤sb1中只需要以形体动作的转折或停顿帧图像作为逻辑断点。这四幅图中的标记a2指示的是语音样本;标记a1、标记b1、标记c1、标记c1指示的是形体动作样本。图中,虚线表示的形体动作样本与语音样本为原始采集样本,实线表示的形体动作样本与语音样本为优化处理后的样本。
具体的,图4a对应于图2中的步骤sb1:划分形体动作样本和/或语音样组:将步骤sa3采集所得的形体动作样本和/或语音样本根据动作思维和/或语言逻辑断点划分样组。如图,形体动作样本a1和语音样本a2同步对应于时间轴nt,但是语音样本a2中并未全程贯穿于时间轴nt,所以在对形体动作样本a1划分逻辑断点时不再以语言逻辑断点来对形体动作样本划分样组,而是以形体动作的转折作为逻辑断点将整个时间轴nt上的形体动作样本a1划分为6t、3t、7t这三段,并分别对应于x段、y段、z段。由该图标记a1指示的形体动作样本上的连续帧图像集,还能演示并看出形体动作样本的转折变化。
与图3b相同,图4b对应于图2中的步骤sb2:划分子样组:将步骤sb1划分后各样组内的形体动作样本以帧为单位按自定义数量划分子样组。如图,形体动作样本b1与语音样本b2选取的是图3a中的x段,其动作样本b1共包括了四个中共包括了四个类同的形体动作,例如共包括了16帧图像,所以以4帧图像为1个子样组,将x段样本划分为1x/4、2x/4、3x/4、4x/4这四个子样组。因此划分子样组后形成图3b。
与图3c相同,图4c对应于图2中的步骤sb3:划分样组单元:将步骤sb3的各帧的子样组,以形体动作重合误差的百分比小于某个自定义值为参考依据,划分样组单元。如图,形体动作样本c1与语音样本c2为是图3b中的x段,其动作样本c1共包括了四个中共包括了四个类同的形体动作,但是在图3b的1x/4子样组上出现了两种形体动作,因此依照形体动作重合误差超过了预设值的判断,需要将1x/4子样组上的这两种动作再次分组,分为1x样组单元和2x样组单元;图3b的2x/4子样组上只出现一种形体动作,所以其为3x样组单元;图3b的3x/4子样组上也出现了两种形体动作,因此依照形体动作重合误差超过了预设值的判断,需要将3x/4子样组上的这两种动作再次分组,分为4x样组单元和5x样组单元;图3b的4x/4子样组上只出现一种形体动作,所以其为6x样组单元;因此图3b在划分样组单元后形成图3c。
与图3d相同,图4d对应于图2中的步骤sc1:优化处理样本:重组、提取、编辑、优化步骤sb3样组单元内的形体动作样本和/或语音样本并存储。通过重组图3c中形体动作样本的1x、2x、3x、4x、5x、6x样组单元,形成新的形成x1、x2、x3、x4样组单元;其中由于2x、3x、4x样组单元的形体动作类同,因此重组合并后变成x2样组单元。再从x1、x2、x3、x4样组单元的动作样本中提取出典型动作帧图像,进行编辑、图像优化后存储。
对比图3和图4,两图其实最终的目的都是对所采集的形体动作样本进行划分并加以重组、提取、编辑、优化,所不同的是图3中的形体动作样本伴随同步语音,因此可以利用语言逻辑断点对样本划分样组,在划分形体动作样本时参照了同步语音,使得最终的形体动作加语音建模对特定真人的模拟更加真实。而图4中的形体动作样本因为缺失同步语音,因此只能以行为动作转折点来作为动作思维上的断点依据,这样使得最终的形体动作需要后期配音,因此相应地需要做更多技术处理。
如图5所示,图5为本发明一种特定真人行为快速建模方法场景示意图。其主要对方法中步骤sa1、sa2、sa3加以演示和说明:
sa1、选取并定义特定社会商业活动,如选取并设计一个真实的营销导购对话场景,整个建模的定义为营销导购;
sa2、选定真人执行所定义的社会商业活动;如选定明星1与顾客2进行产品营销导购交流对话;
sa3、录制该特定社会商业活动;如利用录制设备3将明星1进行产品营销导购时所产生的行为形体动作和/或语音录制存储;该录制设备3可以为摄像机或录音器或ar设备。
以上所述的实施例仅仅是对本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案作出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!