一种建立索引的方法和装置与流程
本发明涉及计算机技术领域,尤其涉及一种建立索引的方法和装置。
背景技术:
随着网络技术和物流技术的发展,近年来电商迅速崛起,电商平台的商品数量及种类数量正在成指数级的增长,大型平台都有数十亿的商品,如何更加高效和智能地满足用户的搜索需求是非常大的挑战。用户的搜索词多种多样,同一个事物存在口语化、简称、缩写等多种不同名称,而商品名称通常比较规范且偏书面语,两者之间直接进行文本匹配往往会出现问题。
在电商搜索的初期,商品数比较少,索引可以直接按字切分,最大可能的保证能够召回用户所需的商品,随着商品数量及种类数量逐渐丰富,这种不考虑词序的方法会带来很多问题,比如用户搜“红酒”,喝的红酒和酒红色的衣服,同样可以被召回。因此就有了先分词再建索引的方法,这样固定搭配如“火龙果”,建索引的时候就是整个词一个索引链,不必为“火”“龙”“果”都建索引,大大提高了搜索召回的准确率。但是因为分词精度以及用户搜索词和商品名称不能直接匹配,例如商品中“女士连衣裙”被正常分词为“女士|连衣裙”,但是用户常搜“女裙”、“夏裙女”,文本匹配没有办法召回该商品。因此索引端在正常的分词结果中,又增加了更多细粒度的词,比如上例中在索引字段又增加了“女,裙”,方便用户在搜索“女裙”、“夏裙女”等的时候也能召回名称为“女士连衣裙”的商品。这些增加的更细粒度的词被称为“语义项”,语义项是按字索引到按词索引之间的桥梁。
尽管现有的建立索引的方案中为索引端的分词结果中添加了一些细粒度的词(语义项),但在实际的搜索应用中仍存在一些缺陷,例如,用户在搜索乐高时,可能得到了高乐高这样的搜索结果,而用户搜索乐高时召回与高乐高相关的商品显然是不符合用户预期的。
在实现本发明过程中,发明人发现现有技术中至少存在如下问题:
现有方案存在召回的商品不准确的问题。
技术实现要素:
有鉴于此,本发明实施例提供一种建立索引的方法和装置,能够在商品索引召回阶段,既能够保证召回率以尽可能多地召回与用户搜索词相关的商品,又能提高准确率以尽可能地过滤掉不相关的商品。
为实现上述目的,根据本发明实施例的一个方面,提供了一种建立索引的方法。
一种建立索引的方法,包括:将输入的文本序列分为多个词,根据所述多个词和所述多个词的子串得到多个词与所述词对应语义项的映射关系;根据所述多个词与所述词对应语义项的映射关系建立第一索引;通过历史搜索数据确定候选词与所述候选词对应语义项的映射关系,以根据所述候选词与所述候选词对应语义项的映射关系修正所述第一索引,获得第二索引。
可选地,所述历史搜索数据包括搜索词和对应的用户点击的文本序列,通过历史搜索数据确定候选词与所述候选词对应语义项的映射关系的步骤,包括:对所述搜索词和所述用户点击的文本序列进行分词,以得到搜索词分词和对应的文本序列分词;根据所述搜索词分词和所述对应的文本序列分词中存在包含关系的搜索词分词和文本序列分词确定所述候选词与所述候选词对应语义项的映射关系。
可选地,所述历史搜索数据包括搜索词和对应的用户点击的文本序列,以及由所述搜索词形成的搜索轨迹,通过历史搜索数据确定候选词与所述候选词对应语义项的映射关系的步骤,包括:获取预先添加到所述第一索引中的新词;从包含所述新词的搜索轨迹中,查找与所述新词存在包含关系的搜索词,并根据所述新词和与所述新词存在包含关系的搜索词确定所述候选词与所述候选词对应语义项的映射关系。
可选地,所述历史搜索数据包括搜索词和对应的用户点击的文本序列,通过历史搜索数据确定候选词与所述候选词对应语义项的映射关系的步骤,包括:获取预先添加到所述第一索引中的新词;根据所述新词和与特定文本序列对应的搜索词中属于所述新词的子串的搜索词确定所述候选词与所述候选词对应语义项的映射关系,其中,所述特定文本序列为包括所述新词的所述用户点击的文本序列。
可选地,通过历史搜索数据确定候选词与所述候选词对应语义项的映射关系的步骤之后,包括:判断所述候选词与所述候选词对应语义项的映射关系是否正确,其中包括:判断所述候选词与所述候选词对应语义项的映射关系中的候选词对应语义项的总体使用占比是否超过第一阈值,若是,则所述候选词与所述候选词对应语义项的映射关系正确,否则,所述候选词与所述候选词对应语义项的映射关系有误,所述候选词对应语义项的总体使用占比为n1与n2的比值,其中,n1为所有与包括所述候选词对应语义项的搜索词对应、且与所述候选词与所述候选词对应语义项的映射关系相关的文本序列的点击量总和中,由所述候选词对应语义项召回的点击量之和,n2为所有与包括所述候选词对应语义项的搜索词对应的文本序列点击量总和。
可选地,通过历史搜索数据确定候选词与所述候选词对应语义项的映射关系的步骤之后,包括:判断所述候选词与所述候选词对应语义项的映射关系是否正确,其中包括:计算所有包括所述候选词与所述候选词对应语义项的映射关系中的候选词对应语义项的搜索词之中,使用率最大的预设数量个搜索词分别对应的候选词对应语义项使用占比;判断所述使用率最大的预设数量个搜索词之中,是否存在至少一个搜索词满足如下条件:该搜索词对应的候选词对应语义项使用占比大于第二阈值,且该搜索词的搜索量大于第三阈值,且该搜索词对应的文本序列点击量大于第四阈值,且该搜索词对应的文本序列点击率大于第五阈值。如果存在所述至少一个搜索词,则所述候选词与所述候选词对应语义项的映射关系正确,否则,所述候选词与所述候选词对应语义项的映射关系有误,每个搜索词对应的候选词对应语义项使用占比为n3与n4的比值,其中,n3为与该搜索词对应、且与所述候选词与所述候选词对应语义项的映射关系相关的文本序列的点击量总和中,由所述候选词对应语义项召回的点击量之和,n4为与该搜索词对应的文本序列点击量总和。
可选地,通过历史搜索数据确定候选词与所述候选词对应语义项的映射关系的步骤之后,包括:判断所述候选词与所述候选词对应语义项的映射关系是否正确,其中包括:判断所述候选词与所述候选词对应语义项的映射关系中的候选词对应语义项与候选词是否相似,若所述候选词对应语义项与所述候选词相似,则所述候选词与所述候选词对应语义项的映射关系正确,否则,所述候选词与所述候选词对应语义项的映射关系有误。
可选地,判断所述候选词与所述候选词对应语义项的映射关系中的候选词对应语义项与候选词是否相似的步骤,包括:获取预设历史时间段内的用户搜索数据,所述用户搜索数据包括搜索词和用户对搜索到的文本序列的预设各级别的多个类目的点击量或搜索量;根据所述搜索词包括所述候选词对应语义项时的所述预设各级别的多个类目的点击量或搜索量生成所述预设各级别的第一候选词对应语义项向量,以及根据所述搜索词包括所述候选词时的所述预设各级别的多个类目的点击量或搜索量生成所述预设各级别的第一候选词向量;分别计算所述预设各级别的第一候选词对应语义项向量与第一候选词向量之间的向量相似度,以得到分别对应所述预设各级别的多个第一向量相似度;判断每个所述第一向量相似度是否大于预先设置的与相应预设级别对应的第六阈值,若是,则所述候选词对应语义项与所述候选词相似,否则,所述候选词对应语义项与所述候选词不相似。
可选地,判断所述候选词与所述候选词对应语义项的映射关系中的候选词对应语义项与候选词是否相似的步骤,包括:通过预设模型生成第二候选词对应语义项向量和第二候选词向量;计算所述第二候选词对应语义项向量和所述第二候选词向量的向量相似度,以得到第二向量相似度;判断所述第二向量相似度是否大于第七阈值,若是,所述候选词对应语义项与所述候选词相似,否则,所述候选词对应语义项与所述候选词不相似。
可选地,所述向量相似度为余弦相似度或者杰卡德相似度。
可选地,根据所述候选词与所述候选词对应语义项的映射关系修正所述第一索引的步骤,包括:当所述候选词与所述候选词对应语义项的映射关系正确时:如果所述第一索引中不存在所述候选词与所述候选词对应语义项的映射关系,则将该映射关系添加到所述第一索引;当所述候选词与所述候选词对应语义项的映射关系有误时:如果所述第一索引中存在所述候选词与所述候选词对应语义项的映射关系,则将该映射关系从所述第一索引中删除。
根据本发明实施例的另一方面,提供了一种建立索引的装置。
一种建立索引的装置,包括:词对生成模块,用于将输入的文本序列分为多个词,根据所述多个词和所述多个词的子串得到多个词与所述词对应语义项的映射关系;索引建立模块,用于根据所述多个词与所述词对应语义项的映射关系建立第一索引;修正模块,用于通过历史搜索数据确定候选词与所述候选词对应语义项的映射关系,以根据所述候选词与所述候选词对应语义项的映射关系修正所述第一索引,获得第二索引。
可选地,所述历史搜索数据包括搜索词和对应的用户点击的文本序列,所述修正模块包括第一确定模块,用于:对所述搜索词和所述用户点击的文本序列进行分词,以得到搜索词分词和对应的文本序列分词;根据所述搜索词分词和所述对应的文本序列分词中存在包含关系的搜索词分词和文本序列分词确定所述候选词与所述候选词对应语义项的映射关系。
可选地,所述历史搜索数据包括搜索词和对应的用户点击的文本序列,以及由所述搜索词形成的搜索轨迹,所述修正模块包括第二确定模块,用于:获取预先添加到所述第一索引中的新词;从包含所述新词的搜索轨迹中,查找与所述新词存在包含关系的搜索词,并根据所述新词和与所述新词存在包含关系的搜索词确定所述候选词对应语义项与词的映射关系。
可选地,所述历史搜索数据包括搜索词和对应的用户点击的文本序列,所述修正模块包括第三确定模块,用于:获取预先添加到所述第一索引中的新词;根据所述新词和与特定文本序列对应的搜索词中属于所述新词的子串的搜索词确定所述候选词与所述候选词对应语义项的映射关系,其中,所述特定文本序列为包括所述新词的所述用户点击的文本序列。
可选地,所述修正模块包括第一判断模块,用于:判断所述候选
语义项与词的映射关系是否正确,其中包括:判断所述候选词与所述候选词对应语义项的映射关系中的候选词对应语义项的总体使用占比是否超过第一阈值,若是,则所述候选词与所述候选词对应语义项的映射关系正确,否则,所述候选词与所述候选词对应语义项的映射关系有误,所述候选词对应语义项的总体使用占比为n1与n2的比值,其中,n1为所有与包括所述候选词对应语义项的搜索词对应、且与所述候选词与所述候选词对应语义项的映射关系相关的文本序列的点击量总和中,由所述候选词对应语义项召回的点击量之和,n2为所有与包括所述候选词对应语义项的搜索词对应的文本序列点击量总和。
可选地,所述词对判断模块包括第二判断模块,用于:判断所述候选词与所述候选词对应语义项的映射关系是否正确,其中包括:计算所有包括所述候选词与所述候选词对应语义项的映射关系中的候选词对应语义项的搜索词之中,使用率最大的预设数量个搜索词分别对应的候选词对应语义项使用占比;判断所述使用率最大的预设数量个搜索词之中,是否存在至少一个搜索词满足如下条件:该搜索词对应的候选词对应语义项使用占比大于第二阈值,且该搜索词的搜索量大于第三阈值,且该搜索词对应的文本序列点击量大于第四阈值,且该搜索词对应的文本序列点击率大于第五阈值。如果存在所述至少一个搜索词,则所述候选词与所述候选词对应语义项的映射关系正确,否则,所述候选词与所述候选词对应语义项的映射关系有误,每个搜索词对应的候选词对应语义项使用占比为n3与n4的比值,其中,n3为与该搜索词对应、且与所述候选词与所述候选词对应语义项的映射关系相关的文本序列的点击量总和中,由所述候选词对应语义项召回的点击量之和,n4为与该搜索词对应的文本序列点击量总和。
可选地,所述词对判断模块包括第三判断模块,用于:判断所述候选词与所述候选词对应语义项的映射关系是否正确,其中包括:判断所述候选词与所述候选词对应语义项的映射关系中的候选词对应语义项与候选词是否相似,若所述候选词对应语义项与所述候选词相似,则所述候选词与所述候选词对应语义项的映射关系正确,否则,所述候选词与所述候选词对应语义项的映射关系有误。
可选地,所述第三判断模块包括第一相似性判断模块,用于:获取预设历史时间段内的用户搜索数据,所述用户搜索数据包括搜索词和用户对搜索到的文本序列的预设各级别的多个类目的点击量或搜索量;根据所述搜索词包括所述候选词对应语义项时的所述预设各级别的多个类目的点击量或搜索量生成所述预设各级别的第一候选词对应语义项向量,以及根据所述搜索词包括所述候选词时的所述预设各级别的多个类目的点击量或搜索量生成所述预设各级别的第一候选词向量;分别计算所述预设各级别的第一候选词对应语义项向量与第一候选词向量之间的向量相似度,以得到分别对应所述预设各级别的多个第一向量相似度;判断每个所述第一向量相似度是否大于预先设置的与相应预设级别对应的第六阈值,若是,则所述候选词对应语义项与所述候选词相似,否则,所述候选词对应语义项与所述候选词不相似。
可选地,所述第三判断模块包括第二相似性判断模块,用于:通过预设模型生成第二候选词对应语义项向量和第二候选词向量;计算所述第二候选词对应语义项向量和所述第二候选词向量的向量相似度,以得到第二向量相似度;判断所述第二向量相似度是否大于第七阈值,若是,所述候选词对应语义项与所述候选词相似,否则,所述候选词对应语义项与所述候选词不相似。
可选地,所述向量相似度为余弦相似度或者杰卡德相似度。
可选地,所述修正模块还用于:当所述候选词与所述候选词对应语义项的映射关系正确时:如果所述第一索引中不存在所述候选词与所述候选词对应语义项的映射关系,则将该映射关系添加到所述第一索引;当所述候选词与所述候选词对应语义项的映射关系有误时:如果所述第一索引中存在所述候选词与所述候选词对应语义项的映射关系,则将该映射关系从所述第一索引中删除。
根据本发明实施例的又一方面,提供了一种服务器。
一种服务器,包括:一个或多个处理器;存储器,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现建立索引的方法。
根据本发明实施例的又一方面,提供了一种计算机可读介质。
一种计算机可读介质,其上存储有计算机程序,其特征在于,所述程序被处理器执行时实现建立索引的方法。
上述发明中的一个实施例具有如下优点或有益效果:将输入的文本序列分为多个词,根据多个词和多个词的子串得到多个词与所述词对应语义项的映射关系,根据该多个与所述词对应语义项的映射关系建立第一索引,通过历史搜索数据确定候选词与所述候选词对应语义项的映射关系,以根据候选词与所述候选词对应语义项的映射关系修正第一索引,获得第二索引。能够在商品索引召回阶段,既能够保证召回率以尽可能多地召回与用户搜索词相关的商品,又能提高准确率以尽可能地过滤掉不相关的商品。
上述的非惯用的可选方式所具有的进一步效果将在下文中结合具体实施方式加以说明。
附图说明
附图用于更好地理解本发明,不构成对本发明的不当限定。其中:
图1是根据本发明实施例的建立索引的方法的主要步骤示意图;
图2是根据本发明实施例的建立索引的装置的主要模块示意图;
图3是本发明实施例可以应用于其中的示例性系统架构图;
图4是适于用来实现本发明实施例的服务器的计算机系统的结构示意图。
具体实施方式
以下结合附图对本发明的示范性实施例做出说明,其中包括本发明实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本发明的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。
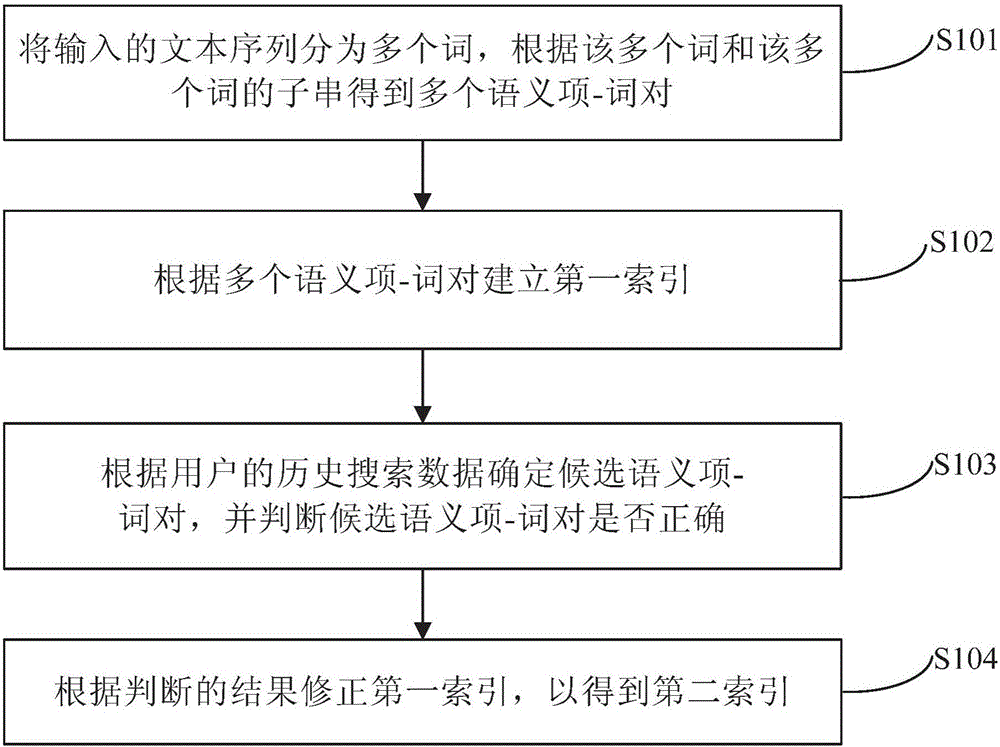
图1是根据本发明实施例的建立索引的方法的主要步骤示意图。
以下为了表述方便,以“语义项-词对”表示词与所述词对应语义项的映射关系,并以“候选语义项-词对”表示候选词与所述候选词对应语义项的映射关系。其中,“语义项-词对”中的语义项为该“语义项-词对”中的词的对应语义项,“候选语义项-词对”中的词也可称为候选词,“候选语义项-词对”中的候选语义项为该“候选语义项-词对”中的候选词的对应语义项(即候选词对应语义项),候选词和候选词对应语义项分别是根据用户的历史搜索数据确定的词和语义项,相应地,“候选语义项-词对”(即候选词与所述候选词对应语义项的映射关系)是根据用户的历史搜索数据确定的词和语义项的映射关系,该候选词与所述候选词对应语义项的映射关系是否正确需要通过一定的判断标准来判定,具体的判断标准即判断一候选语义项-词对是否正确的标准将在下文详细介绍),如果某一候选语义项-词对正确,即某一候选词与所述候选词对应语义项的映射关系正确,则该候选语义项是该候选词的语义项,如果某一候选语义项-词对有误,即某一候选词与所述候选词对应语义项的映射关系有误,则该候选语义项不是该候选词的语义项,本发明实施例通过定期将索引(即第一索引)中的有误的候选语义项-词对删除,以及定期在索引(即第一索引)中添加新的且正确的候选语义项-词对,从而不断地修正第一索引,以获得第二索引。
如图1所示,本发明实施例的建立索引的方法主要包括如下的步骤s101至步骤s104。
步骤s101:将输入的文本序列分为多个词,根据该多个词和该多个词的子串得到多个语义项-词对。
输入的文本序列可以是商品title(标题)信息。
将输入的文本序列按照已存的分词词表进行分词,即按照已存的分词词表将输入的文本序列切分成多个单独的词,从而得到多个词。将得到多个词中每个词所有的子串都找出,其中,组成一个词的其中一个字或多个(包括两个)位置相邻的字的组合构成该词的子串,例如一个词为“高乐高”,则该词的子串包括:“高”、“乐”、“高”、“高乐”、“乐高”。把一个词的所有子串都视为该词的语义项,从而得到多个语义项-词对,语义项-词对中的词也可称为该语义项的原词。
步骤s102:根据多个语义项-词对建立第一索引。
由于将一个词的所有子串都视为该词的语义项,因此其中包括合适(即语义项与词的映射关系正确)的语义项,例如:电视-电视机、阿迪-阿迪达斯,其中电视是电视机的语义项,阿迪是阿迪达斯的语义项,用户使用这些语义项作为搜索词进行搜索召回的商品通常是符合用户预期的。也包括一些不合适(即语义项与词的映射关系有误)的语义项,例如:菠萝-菠萝蜜、乐高-高乐高,显然,用户搜索“菠萝”、“乐高”召回的商品中“菠萝蜜”和“高乐高”并不是期望搜索到的结果,用户使用这些语义项作为搜索词进行搜索召回的商品通常是不符合用户预期的。
本发明实施例的第一索引可以是倒排索引。通过建立“单词-文档”矩阵来存储搜索词、语义项(搜索词、语义项相当于“单词”)与文本序列(文本序列相当于“文档”)之间的映射关系,通过倒排索引,可以快速找到包含某单词的文档集合。
在建立第一索引之后,通过历史搜索数据确定候选语义项-词对,以根据候选语义项-词对修正第一索引,获得第二索引。具体可包括如下的步骤s103和步骤s104。
步骤s103:根据用户的历史搜索数据确定候选语义项-词对,并判断候选语义项-词对是否正确。
用户的历史搜索数据可以从app(应用程序)端和pc(个人计算机)端的用户搜索点击日志中获得,历史搜索数据可以是最近三个月用户搜索使用的query(搜索词)和点击的文本序列,文本序列可以是获取的由商家编写录入的商品title(标题)。query(搜索词)和点击的商品title(标题)信息的关联关系可表示为:query-商品title。候选语义项-词对中的词(即候选词)也可称为该候选语义项-词对中的候选语义项的原词。
具体地,根据用户的历史搜索数据,可以通过如下三种方式(方式a1~方式a3)确定候选语义项-词对。
方式a1:对搜索词和用户点击的文本序列进行分词,以得到搜索词分词和对应的文本序列分词;根据搜索词分词和对应的文本序列分词中存在包含关系的搜索词分词和文本序列分词确定候选语义项-词对。其中,历史搜索数据可包括搜索词和对应的用户点击的文本序列。
对搜索词和用户点击的文本序列进行分词之前,还可进行归一化处理,具体为将query(搜索词)和商品title(标题)归一化,可包括大写转小写、繁体转简体、全角转半角等处理。
根据搜索词分词和对应的文本序列分词中存在包含关系的搜索词分词和文本序列分词确定候选语义项-词对,具体地,可以扫描商品title,将其中包含query中的某词语的字符串选取出来,组成候选语义项-词对,并且其中只选择该词语与字符串为子串包含关系的字符串,而不考虑该词语与字符串相同的字符串。例如:
query为:腰椎牵引;
商品title为:永辉b04人体拉伸器颈椎腰椎牵引床牵引架颈椎牵引器牵引家用;
那么,其中,通过扫描该商品title,商品title中包含query中的“牵引”的字符串为“牵引床”、“牵引架”、“牵引器”,组成候选语义项-词对相应地为:牵引-牵引床、牵引-牵引架、牵引-牵引器,而商品title中的“牵引”为与query中的“牵引”相同的字符串,则不选取。
方式a1通过使用用户的历史搜索数据,利用用户历史搜索反馈数据中的query-商品title确定出一些语义项-词的映射关系,建立相应的候选语义项-词对,通过判定这些候选语义项-词对是否正确,即可确定第一索引中对应的这些语义项与词之间的映射关系是否合适。
随着新事物的出现或者已有事物的新叫法的产生,会不断出现一些新词,每当有新词加入已存的分词词表中时,相应的也需要增加新词的语义项。例如出现一款新产品叫“章鱼足”,当用户搜索“章鱼”时可能是搜索到“章鱼足”的相关商品,因此需要为“章鱼足”增加相应的语义项“章鱼”,即确定语义项-词对为:“章鱼-章鱼足”。新词可以通过现有的各种新词识别算法来识别,例如,可以通过如下的新词识别算法来识别新词:统计所有商品库中的商品title,将所有4字以下的相邻的字,连成一个候选新词,判断这个候选新词的左右信息熵以及凝合度,当该候选新词的左右信息熵以及凝合度均大于某个阈值时,判断该候选新词为一个独立的词,将该独立的词跟已存的分词词表做差集,如果该独立的词不在已存的分词词表,则将该独立的词作为新词。本发明实施例的方式a2和方式a3介绍了为识别出的新词增加语义项的方法。
方式a2:获取预先添加到第一索引中的新词;从包含新词的搜索轨迹中,查找与新词存在包含关系的搜索词,并根据新词和与新词存在包含关系的搜索词确定候选语义项-词对。其中,历史搜索数据可包括搜索词和对应的用户点击的文本序列,以及由搜索词形成的搜索轨迹。
新词被识别出来之后,可以被添加到已存的分词词表中,并且,在对query和商品title进行分词时,分词词表中的该新词被分成一个独立的词语,并被添加到第一索引中。
搜索轨迹可以是用户搜索session(时间段)的信息,一个用户搜索session是用户搜索完一个词之后,因未得到期望的搜索结果(例如得到的搜索结果过少或过多)等原因而更换另外一个搜索词的相关信息,用户搜索session指示了用户的一系列相关搜索行为。例如,用户以“虾”作为搜索词进行搜索之后,搜索得到的商品标题中包括各种各样的虾,如果用户的期望搜索结果是“小龙虾”,那么用户会更改搜索词为“小龙虾”,再如,用户以“零食榴莲酥”作为搜索词进行搜索之后,召回(搜索到)的商品较少,或者有一些商品title中既包括榴莲酥又包括榴莲饼,而用户期望搜索到更多的相关商品,可能会更改搜索词为“零食榴莲”,通过用户搜索session(时间段)的信息,可以得到上述两例中,用户的搜索轨迹为:“虾→小龙虾”;“零食榴莲酥→零食榴莲”。从包含新词的搜索轨迹中查找与新词存在包含关系的搜索词,可将新词和与该新词存在包含关系的搜索词确定为候选语义项-词对。例如上述两个例子中,假设“小龙虾”和“榴莲”为新词,且搜索轨迹中,“虾”和“榴莲酥”为分别与新词“小龙虾”和“榴莲”存在包含关系的搜索词,则可以确定候选语义项-词对分别为:虾-小龙虾;榴莲-榴莲酥。
方式a3:获取预先添加到第一索引中的新词;根据新词和与特定文本序列对应的搜索词中属于新词的子串的搜索词确定候选语义项-词对,其中,特定文本序列为包括新词的用户点击的文本序列,且历史搜索数据可包括搜索词和对应的用户点击的文本序列。
可将商品title中的新词加入已存的分词词表中,这样,在对query和商品title进行分词时,分词词表中的该新词会被分成一个独立的词语,并被添加到第一索引中。可根据用户的历史搜索数据确定该新词对应的候选语义项-词对。具体地,可以使用最近三个月历史搜索数据,其中,历史搜索数据包括搜索词和对应的用户点击的文本序列,其中用户点击的文本序列中包括一些含有该新词的特定文本序列,根据新词和与特定文本序列对应的搜索词中属于新词的子串的搜索词确定候选语义项-词对。例如,假设商品title中含有一新词为“阿迪达斯”,则根据方式a3,可以使用最近三个月用户使用的query和点击的商品title,将用户点击的商品title中含有该新词“阿迪达斯”的商品title对应的query中,属于该新词“阿迪达斯”的子串的query选出,将该子串和“阿迪达斯”确定为候选语义项-词对,假设属于该新词“阿迪达斯”的子串的某个query为“阿迪”,则确定候选语义项-词对为“阿迪-阿迪达斯”。
需要说明的是,本发明实施例的根据用户的历史搜索数据确定候选语义项-词对的方法可以采用上述三种方式(方式a1~方式a3)的一种或多种方式的组合。
可以通过如下三种方式(方式b1~方式b3)中的其中一种方式判断上述方式a1~方式a3确定的候选语义项-词对是否正确。
下面举例说明分别通过方式b1、方式b2、方式b3确定候选语义项-词对是否正确的具体方法。例如,一候选语义项-词对为“风扇-电风扇”,如下为对应商品title点击量最大的20个含有候选语义项“风扇”的搜索词(query)的相关搜索和点击数据。
1、风扇:416734/494199(0.84)1690445||
2、风扇落地:73795/80872(0.91)196629||
3、美的风扇:67226/68015(0.99)147385||
4、无叶风扇:23185/47864(0.48)133882||
5、风扇台式:23055/28270(0.82)94839||
6、艾美特风扇:18767/21304(0.88)43743||
7、格力风扇:17340/21056(0.82)45162||
8、风扇小:14204/26035(0.55)132645||
9、落地风扇:13445/14779(0.91)36242||
10、台式风扇:11801/14479(0.82)43809||
11、制冷风扇:9494/13310(0.71)25880||
12、迷你风扇:6645/31710(0.21)98000||
13、usb风扇:6382/44415(0.14)113902||
14、静音风扇:6114/8217(0.74)24376||
15、风扇静音:5648/7432(0.76)25114||
16、奥克斯风扇:3934/4628(0.85)12116||
17、风扇迷你:3488/10803(0.32)34133||
18、遥控风扇:3280/3534(0.93)7300||
19、工业风扇:3246/4319(0.75)13773||
20、美的风扇落地扇:3211/3212(1)6540||
其中,对于该20个query,某个query的对应商品title点击量为使用该query搜索并点击各商品title时用户对该各商品title的点击量总和。该20个query的相关搜索和点击数据对应含义为(按照20条相关搜索和点击数据中的每条相关搜索和点击数据的格式):“query1:n3的值/n4的值(n3/n4的结果)query1的搜索量||”,其中,query1表示如下20个query中的任意一个query,n3/n4即n3与n4的比值,以query1为:“风扇落地”为例,对应的一条相关搜索和点击数据为:“风扇落地:73795/80872(0.91)196629||”,其中,73795为n3的值,80872为n4的值,n3/n4的结果为0.91,该query1的搜索量为196629。以下详细解释n3和n4的具体含义。
n3/n4为所有包括候选语义项-词对中的候选语义项的搜索词之中,使用率最大的预设数量个搜索词分别对应的候选语义项使用占比,其中,n3为与该搜索词对应、且与候选语义项-词对相关的文本序列的点击量总和中,由候选语义项召回的点击量之和。与该搜索词对应、且与候选语义项-词对相关的文本序列为通过该搜索词搜索并点击的文本序列中与候选语义项-词对相关的文本序列。与候选语义项-词对相关的文本序列是使用包括候选语义项-词对中的候选语义项的搜索词(query)时搜索并点击的文本序列之中包括该候选语义项-词对中的候选语义项或候选词的文本序列。由候选语义项召回的点击量之和即通过包括候选语义项-词对中的候选语义项的搜索词搜索并点击的与候选语义项-词对相关的文本序列中,用户对包含该该候选语义项-词对中的候选词的文本序列的点击量之和。结合本例,候选语义项-词对为“风扇-电风扇”,假设通过query“风扇落地”搜索到1000个商品title,其中800个商品title中包含“风扇”或“电风扇”(例如商品title为“美的落地电风扇”、“美的落地风扇”),200个商品title不包含“电风扇”(某商品title为“美的落地冷风扇”),那么包含“风扇”或“电风扇”的该800个商品title为与候选语义项-词对“风扇-电风扇”相关的文本序列,而既不包含“风扇”又不包含“电风扇”的该200个商品title则不是与候选语义项-词对“风扇-电风扇”相关的文本序列(该200个商品title可能是与其他候选语义项-词对相关的文本序列)。并且,假设包含“风扇”或“电风扇”的该800个商品title中,有300个商品title中包含“电风扇”、500个包含“风扇”,那么根据n3的定义,n3为与该搜索词对应、且与候选语义项-词对相关的文本序列的点击量总和中,由候选语义项召回的点击量之和,根据本例,用户对包含“电风扇”的该300个商品title的点击量之和即为n3。结合本例中的搜索和点击数据,例如,“风扇落地:73795/80872(0.91)196629||”,用户对包含“电风扇”的该300个商品title的点击量之和为73795,即n3=73795。
n4为与该搜索词对应的文本序列点击量总和,具体指通过该搜索词搜索并点击的各文本序列中,用户对其中至少有一个文本序列含候选语义项-词对中的候选词的各文本序列的点击量总和。根据本例,候选语义项-词对为“风扇-电风扇”,以query为“风扇落地”为例,假设用户使用该query搜索到1000个商品title,则该1000个商品title应该至少有一个商品title含“电风扇”,这时统计该1000个商品title的点击量总和即为n4。结合本例中的搜索和点击数据,“风扇落地:73795/80872(0.91)196629||”之中,该1000个商品title的点击量总和为80872,即n4=80872。n3/n4即n3与n4的比值为:73795/80872=0.91。由于使用该query“风扇落地”搜索到的商品title全部为与其他候选语义项-词对相关的商品title时得到的数据对于确定候选语义项-词对为“风扇-电风扇”是否正确时没有意义的,因此要限定该1000个商品title应该至少有一个商品title含候选语义项-词对为“风扇-电风扇”中的候选词“电风扇”,即保证搜索并点击的商品title中至少有一条商品title是与候选语义项-词对为“风扇-电风扇”相关的商品title。
query1的搜索量即用户使用query1作为搜索词时搜索到的文本序列(如商品title)的总数量,结合本例中的搜索和点击数据,例如,query1为“风扇落地,对应的搜索和点击数据为“风扇落地:73795/80872(0.91)196629||”,“风扇落地”这一搜索词的搜索量即为196629。
方式b1:判断候选语义项-词对中的候选语义项的总体使用占比是否超过第一阈值(设为threshold_a),若是,则候选语义项-词对正确,否则,候选语义项-词对有误。候选语义项的总体使用占比为n1与n2的比值,其中,n1为所有与包括候选语义项的搜索词对应、且与候选语义项-词对相关的文本序列的点击量总和中,由候选语义项召回的点击量之和,n2为所有与包括候选语义项的搜索词对应的文本序列点击量总和。
结合本例,假设包括候选语义项“风扇”的搜索词为w个(本例示出了其中的对应商品title点击量最大的20个query),且用户使用该w个query搜索并点击5000个商品title,其中与候选语义项-词对相关的商品title(即该5000个商品title中包含“风扇”或“电风扇”的商品title)为3000个,并且,该3000个商品title中包含“电风扇”的商品title为2000个,则n1为用户对包含“电风扇”的该2000个商品title的点击量之和。n2为所有与包括候选语义项的搜索词对应的文本序列点击量总和,具体指通过所有与包括候选语义项的搜索词搜索各文本序列时,用户对其中至少有一个文本序列含候选语义项-词对中的候选词的各文本序列的点击量总和。结合本例,用户使用该w个query搜索并点击5000个商品title中,应该至少有一个商品title含“电风扇”,假设n1为916978,n2为1339534,则n1/n2即n1与n2的比值为916978/1339534=0.68。
方式b2:计算所有包括候选语义项-词对中的候选语义项的搜索词之中,使用率最大的预设数量个搜索词分别对应的候选语义项使用占比(设为query_sem_userato);判断该使用率最大的预设数量个搜索词之中,是否存在至少一个搜索词满足如下条件:该搜索词对应的候选语义项使用占比大于第二阈值(设为threshold_b_userato),且该搜索词的搜索量(设为query_search)大于第三阈值(设为threshold_b_pv),且该搜索词对应的文本序列点击量(设为query_click)大于第四阈值(设为threshold_b_click),且该搜索词对应的文本序列点击率(设为ctr)大于第五阈值(设为threshold_ctr)。如果存在该至少一个搜索词,则候选语义项-词对正确,否则,所述候选语义项-词对有误。
每个搜索词对应的候选语义项使用占比为n3与n4的比值,其中,n3为与该搜索词对应、且与候选语义项-词对相关的文本序列的点击量总和中,由候选语义项召回的点击量之和,n4为与该搜索词对应的文本序列点击量总和。
上文已对n3和n4的具体含义进行了详细解释,此处不再赘述。方式b2中预设数量可以设置为10,结合本例,假设包括候选语义项“风扇”的搜索词为w个,则分别计算该w个搜索词中每个搜索词对应的候选语义项使用占比n3/n4(即n3与n4的比值),然后对计算得到的w个候选语义项使用占比进行排序,选取其中数值最大的10个候选语义项使用占比即使用率最大的10个搜索词分别对应的候选语义项使用占比。并且,在判断候选语义项-词对正确时,如果该10个搜索词中,有至少一个搜索词满足:query_search>threshold_b_pv,且query_click>threshold_b_click,且query_sem_userato>threshold_b_userato,且ctr>threshold_ctr,则候选语义项-词对“风扇-电风扇”正确,否则该候选语义项-词对有误。
方式b3:判断候选语义项-词对中的候选语义项与候选词是否相似,若候选语义项与候选词相似,则候选语义项-词对正确,否则,候选语义项-词对有误。
其中,在方式b3中,可以通过两种方式(方式b3-1,方式b3-2)之中的任意一种方式判断候选语义项-词对中的候选语义项与候选词是否相似。
方式b3-1:获取预设历史时间段内的用户搜索数据,用户搜索数据包括搜索词和用户对搜索到的文本序列的预设各级别的多个类目的点击量或搜索量;根据搜索词包括该候选语义项时的预设各级别的多个类目的点击量或搜索量生成预设各级别的第一候选词对应语义项向量(本发明实施例中的候选词对应语义项向量也可简称为候选语义项向量,因此第一候选词对应语义项向量也可称为第一候选语义项向量),以及根据搜索词包括该候选词时的预设各级别的多个类目的点击量或搜索量生成预设各级别的第一候选词向量;分别计算预设各级别的第一候选语义项向量与第一候选词向量之间的向量相似度,以得到分别对应预设各级别的多个第一向量相似度;判断每个第一向量相似度是否大于预先设置的与相应预设级别对应的第六阈值,若是,则该候选语义项与该候选词相似,否则,该候选语义项与该候选词不相似。
下面以候选语义项-词对为“风扇-电风扇”(其中候选语义项为“风扇”,该候选语义项“风扇”的原词为“电风扇”),预设级别的数量为三为例详细介绍方式b3-1。可使用搜索端(如app端)的预设历史时间段(如六个月)之内的搜索点击数据,来判断候选语义项-词对中的候选语义项与候选词是否相似。
当原词和语义项的点击量均大于预设值(该预设值可以根据需要设置,例如预设值设为100)时,则根据搜索词包括该候选语义项时的预设的三个级别的多个类目的点击量生成预设的三个级别的第一候选语义项向量(一级第一候选语义项向量、二级第一候选语义项向量、三级第一候选语义项向量),以及根据搜索词包括该候选词时的预设的三个级别的多个类目的点击量生成预设的三个级别的第一候选词向量(一级第一候选词向量、二级第一候选词向量、三级第一候选词向量)。假设第一级别共有5个类目,即有5个一级类目,设一级第一候选语义项向量为v_semantic_cid1,设一级第一候选词向量为v_word_cid1。搜索词包括“风扇”时点击3个一级类目,该3个一级类目编号为(1,2,3)且分别对应的点击量为(100,50,50),组成一个5维向量为(100,50,50,0,0),经归一化处理即得到一级第一候选语义项向量v_word_cid1为(0.5,0.25,0.25,0,0),搜索词包括“电风扇”时点击2个一级类目,该2个一级类目编号为(3,4)且分别点击量为(200,400),组成一个5维向量为(0,200,400,0,0),进行归一化处理之后即得到一级第一候选词向量v_word_cid1为(0,0,0.333,0.667,0)。同理,可以确定生成另外两个级别(二级、三级)的第一候选语义项向量和第一候选词向量,二级第一候选语义项向量设为v_semantic_cid2,三级第一候选语义项向量设为v_semantic_cid3,二级第一候选词向量设为v_word_cid2,三级第一候选词向量设为v_word_cid3。分别计算一级第一候选语义项向量与一级第一候选词向量之间、二级第一候选语义项向量与二级第一候选词向量之间、三级第一候选语义项向量与三级第一候选词向量之间的余弦相似度或者杰卡德相似度。
以计算预设各级别的第一候选语义项向量与第一候选词向量之间的余弦相似度为例,其中:
一级第一候选语义项向量与一级第一候选词向量之间的余弦相似度(设为sim_cid1_cos)为:
sim_cid1_cos=cosine(v_word_cid1,v_semantic_cid1);
二级第一候选语义项向量与二级第一候选词向量之间的余弦相似度(设为sim_cid2_cos)为:
sim_cid2_cos=cosine(v_word_cid2,v_semantic_cid2);
三级第一候选语义项向量与三级第一候选词向量之间的余弦相似度(设为sim_cid3_cos)为:
sim_cid3_cos=cosine(v_word_cid3,v_semantic_cid3)。
以计算预设各级别的第一候选语义项向量与第一候选词向量之间的杰卡德相似度,以计算第三级别的第一候选语义项向量与第一候选词向量之间的杰卡德相似度(设为sim_cid3_jacc)为例:
其中,vword3为三级第一候选词向量,vse3为三级第一候选语义项向量,其中,∩表示三级第一候选词向量与三级第一候选语义项向量的交集的元素个数,∪表示三级第一候选词向量与三级第一候选语义项向量的并集的元素个数。根据本例,例如搜索词包括“电风扇”时点击3个三级类目,三级第一候选词向量为(1,2,3),搜索词包括“风扇”时点击4个三级类目,三级第一候选语义项向量为(2,3,4,5),则根据上述计算杰卡德相似度的公式:sim_cid3_jacc=2/5。同理,可以计算出一级第一候选语义项向量与一级第一候选词向量之间的杰卡德相似度(设为sim_cid1_jacc)、二级第一候选语义项向量与二级第一候选词向量之间的杰卡德相似度(设为sim_cid2_jacc)。
当原词或语义项的点击量小于或等于上述预设值(该预设值可以根据需要设置,例如预设值设为100)时,则可以根据搜索词包括该候选语义项时的预设各级别的多个类目的搜索量生成预设各级别的第一候选语义项向量,以及根据搜索词包括该候选词时的预设各级别的多个类目的搜索量生成预设各级别的第一候选词向量,然后按照上述介绍的计算向量之间的余弦相似度或者杰卡德相似度的公式计算一级第一候选语义项向量与一级第一候选词向量之间、二级第一候选语义项向量与二级第一候选词向量之间、三级第一候选语义项向量与三级第一候选词向量之间的余弦相似度或者杰卡德相似度。并且,搜索词包括该候选语义项时的预设各级别的多个类目的搜索量可以是从线上抓取的该搜索词(query)的搜索结果,具体也可以只选取其中设定数量的搜索结果,例如选取其中的300条,统计该300条商品标题中搜索词包括候选语义项和候选词时对应商品的预设各级别的多个类目的搜索量,然后生成预设各级别的第一候选语义项向量和第一候选词向量,再计算各级候选语义项向量与第一候选词向量之间的余弦相似度或者杰卡德相似度。
方式b3-2:通过预设模型生成第二候选词对应语义项向量(也可称为第二候选语义项向量)和第二候选词向量;计算第二候选语义项向量(设为vword2vec_semantic)和第二候选词向量(设为vword2vec_word)的向量相似度(设为sim_em(word,semantic)),以得到第二向量相似度;判断第二向量相似度是否大于第七阈值,若是,则该候选语义项与该候选词相似,否则,该候选语义项与该候选词不相似。
预设模型可以是word2vec模型,word2vec模型是google(谷歌公司)于2013年开源推出的一个用于获取词语的低维度向量表示的工具包,该word2vec模型可使用已存商品库中的商品title训练之后再使用。
以第二向量相似度为余弦相似度为例,第二向量相似度为:
sim_em(word,semantic)=cosine(word2vec_word,word2vec_semantic)
以第二向量相似度为杰卡德相似度为例,第二向量相似度为:
需要说明的是,本发明实施例可以采用方式b1、方式b2、方式b3之中的任意一种方式来判断通过上述的方式a1~方式a3中的一种或多种方式组合所确定的候选语义项-词对是否正确,并且方式b3之中,可以通过方式b3-1、方式b3-2该两种方式之中的任意一种方式来判断候选语义项-词对中的候选语义项与候选词是否相似。
本发明是实施例的方式b1~方式b3之中所使用的各个阈值(即上述的第一阈值、第二阈值、第三阈值、第四阈值、第五阈值、第六阈值、第七阈值)可根据候选语义项-词对中的候选语义项和候选词分别是产品词或非产品词而设置为不同的具体数值。候选语义项-词对中的候选语义项和候选词(即候选语义项的原词)分别是产品词或非产品词可包括如下四种情况:
候选语义项是产品词,原词也是产品词(记为p-p);
候选语义项是产品词,原词非产品词(记为p-np);
候选语义项非产品词,原词是产品词(记为np-p);
候选语义项非产品词,原词非产品词(记为np-np)。
由于基于产品词之间(如榴莲-榴莲酥)的语义关系和非产品词之间(如冬-冬季)的语义关系及用户搜索方式不同(产品词通常可单独作为搜索词,而修饰词通常不会单独作为搜索词而是通常都是与产品词相搭配来组合为搜索词),通过以上四种情况可分别采用上述三种方式(方式b1~方式b3)之中的任意一种方式来判断候选语义项-词对是否正确,四种情况中,每种情况的阈值设置数值都不同,以提高商品的过滤效果。
此外,产品词或非产品词可以通过查找已存的产品词表来识别。通常基于产品词来过滤不相关的商品的过滤效果比较好,为了完善产品词表以将产品词准确地识别出来,可从非产品词(np-np的情况)中挖掘出一些产品词。具体做法如下:统计候选语义项中所有的单字,以及以这个单字结尾的原词,例如,{豆{芸豆麻豆,磨豆,金豆,菜豆,豇豆,赤豆,伊豆,憨豆,煎豆,芸豆,毛豆,酷豆,魔豆,干豆,酱豆,米豆,彩豆,胡豆,花豆,扁豆,蜜豆,福豆,笋豆,溶豆,挑豆,奶豆,香豆,腰豆,焗豆}};{机{仿真机,卷烟机,刻章机,散步机,旋耕机,裁切机,胶纸机,存款机,倒角机,孵蛋机,挖坑机,童颜机,封包机,飘香机,砂带机,伞袋机,套丝机,天井机,冷喷机,修剪机,碎脂机,娃娃机,足球机,砂光机,播种机,盾构机,相印机,内燃机,蜡疗机,拉坯机}},统计以某个字结尾的原词中产品词的个数以及占比。将原词分为2个字和3个字及以上两种情况,其中,对于2个字的情况可通过人工查找并核实不是产品词的那些原词,并在核实是产品词之后将这个字加入白名单中,对于3个字的情况,可以设置一个条件,例如产品词个数>=10且产品词占比>=25%,满足该条件的字则加入白名单中。从np-np中选取出以白名单中的词结尾的词为新识别出来的产品词。
步骤s104:根据判断的结果修正第一索引,以得到第二索引。
具体地,根据判断的结果修正第一索引的步骤,具体可以包括:当候选语义项-词对正确时:如果第一索引中不存在候选语义项-词对中的候选语义项与候选词的映射关系,则将该映射关系添加到第一索引;当候选语义项-词对有误时:如果第一索引中存在候选语义项-词对中的候选语义项与候选词的映射关系,则将该映射关系从第一索引中删除,从而使得基于步骤s101得到的语义项-词对建立的第一索引中存在的一些语义项与词之间的不合适的映射关系被删除,
根据本发明实施例,方式a1利用用户历史搜索反馈数据中的query-商品title确定出一些语义项-词的映射关系,建立相应的候选语义项-词对,通过方式a1确定的候选语义项-词对的映射关系为第一索引中已存在的语义项-词对的映射关系,可以通过方式b1、方式b2、方式b3(方式b3-1或方式b3-2)之中的任意一种方式判断通过方式a1确定的候选语义项-词对的映射关系是否正确,如果该映射关系有误,则删除第一索引中相应的语义项-词对的映射关系,如果该映射关系正确,则保留第一索引中的该映射关系。方式a2从包含新词的搜索轨迹中,查找与新词存在包含关系的搜索词,并根据新词和与新词存在包含关系的搜索词确定候选语义项-词对,通过方式a2确定的候选语义项-词对中的词为新词,第一索引中不存在该新词与相应的语义项之间的映射关系,可以通过方式b1、方式b2、方式b3(方式b3-1或方式b3-2)之中的任意一种方式判断通过方式a2确定的候选语义项-词对的映射关系是否正确,如果该映射关系正确,则在第一索引中添加该候选语义项-词对的映射关系,如果该映射关系错误,则不在第一索引中添加该映射关系。方式a3根据新词和与特定文本序列对应的搜索词中属于新词的子串的搜索词确定候选语义项-词对,其中,特定文本序列为包括新词的用户点击的文本序列。通过方式a3确定的候选语义项-词对中的词也为新词,第一索引中不存在该新词与相应的语义项之间的映射关系,可以通过方式b1、方式b2、方式b3(方式b3-1或方式b3-2)之中的任意一种方式判断通过方式a3确定的候选语义项-词对的映射关系是否正确,如果该映射关系正确,则在第一索引中添加该候选语义项-词对的映射关系,如果该映射关系错误,则不在第一索引中添加该映射关系。在通过方式b1、方式b2、方式b3(方式b3-1或方式b3-2)之中的任意一种方式判断通过方式a2和/或方式a3确定的候选语义项-词对的映射关系是否正确时,可以根据实际对新词的语义项的置信度需求设置第二阈值、第三阈值、第四阈值、第五阈值、第六阈值、第七阈值的具体数值。
本发明实施例一方面保证了固定搭配的词语,使得在索引时无需考虑用户的搜索方式,可直接将词语建立一个索引项,如“连衣裙”、“电视机”、“防滑垫”。通过建立语义项词对:(连衣/裙—连衣裙)、(电视—电视机)、(防滑/垫--防滑垫),当用户搜索“连衣长裙”、“小米电视”、“浴室防滑地垫时,相应的商品名称中写法为“连衣裙长款”、“小米智能云电视机”、“防滑垫浴室用品”等的商品仍然能够被召回。另一方面,在第一索引中增加新词和相应的语义项之间的映射关系,可以提高在召回阶段的准确率。例如,新词为“鸡翅木”“浴室柜”“手机保护壳”’等,增加相应的语义项之后可避免在分词阶段需要将词分的过于零散(即切词切得很碎)才能满足用户的搜索需求,从而避免召回一些不相关的商品。例如,为“鸡翅木”添加语义项“木”,用户搜索“木筷子”即可召回商品标题中包含“鸡翅木”的商品,而如果“鸡翅木”没有“木”这一语义项,在分词阶段只能分词为“鸡翅”和“木”才能保证用户搜索“木筷子”时召回商品标题中包含“鸡翅木”的商品,而这样会导致用户搜索“鸡翅”时召回“鸡翅木”等一些筷子、桌子、茶盘等不相关商品。同样,再如,“牛仔蓝”如果没有对应的“蓝”这一语义项,在分词阶段则需要分词为“牛仔”和“蓝”,而这样分词会导致用户搜索“牛仔外套”时召回非牛仔材质的牛仔蓝颜色的外套。语义项是索引中按字切分和按词切分的折中,在商品数增长快速的索引中起到重要作用,是用户多样化的搜索词和商家规范化的商品名称之间的桥梁。本发明实施例通过定期修正第一索引中的语义项与词的映射关系,并为不断出现的新词增加语义项与新词的映射关系,在保证商品召回率的情况下,提高召回商品的准确率。
需要说明的是,本发明实施例可定期(以第一时间周期)删除第一索引中的有误的语义项-词的映射关系,并定期(以第二时间周期)在第一索引中增加新词与语义项的映射关系,其中,第一时间周期和第二时间周期可以相同或不同,例如,可以每隔三个月通过方式a1确定候选语义项-词对并在判断该确定的候选语义项-词对有误时,删除有误的语义项-词的映射关系,而每隔6个月将新词与候选语义项的映射关系之中正确的映射关系添加到第一索引。或者,每隔三个月将第一索引中有误的语义项-词的映射关系删除,同时将新词的正确的语义项-词的映射关系添加到第一索引。本发明实施例使用用户的历史搜索数据,通过用户的不断反馈,找出第一索引中不合适的语义项-词的映射关系,并定期删除这些不合适的语义项-词的映射关系,以及定期在第一索引中增加一些新词与其语义项的映射关系,如此不断地迭代更新,持续性地修正第一索引而得到第二索引,能很好地适应用户的搜索习惯,保证索引的正确性和时效性。
图2是根据本发明实施例的建立索引的装置的主要模块示意图。
如图2所示,本发明实施例的建立索引的装置200主要包括:词对生成模块201、索引建立模块202、词对判断模块203、索引修正模块204。
词对生成模块201,用于将输入的文本序列分为多个词,根据多个词和多个词的子串得到多个语义项-词对。
索引建立模块202,用于根据多个语义项-词对建立第一索引。
词对判断模块203,用于根据用户的历史搜索数据确定候选语义项-词对,并判断候选语义项-词对是否正确。
索引修正模块204,用于根据判断的结果修正第一索引,以得到第二索引。
其中,词对判断模块203和索引修正模块204可以通过一个独立的模块即修正模块来实现,该修正模块主要用于通过历史搜索数据确定候选词与所述候选词对应语义项的映射关系,以根据候选词与所述候选词对应语义项的映射关系修正第一索引,获得第二索引。其中,以“语义项-词对”表示词与所述词对应语义项的映射关系,并以“候选语义项-词对”表示候选词与所述候选词对应语义项的映射关系。该修正模块可包括词对判断模块203和索引修正模块204。
根据本发明的一个实施例,历史搜索数据可包括搜索词和对应的用户点击的文本序列,词对判断模块203可包括第一确定模块,用于:对搜索词和用户点击的文本序列进行分词,以得到搜索词分词和对应的文本序列分词;根据搜索词分词和对应的文本序列分词中存在包含关系的搜索词分词和文本序列分词确定候选语义项-词对。
根据本发明的另一实施例,历史搜索数据可包括搜索词和对应的用户点击的文本序列,以及由搜索词形成的搜索轨迹,词对判断模块203可包括第二确定模块,用于:获取预先添加到第一索引中的新词;从包含新词的搜索轨迹中,查找与新词存在包含关系的搜索词,并根据新词和与新词存在包含关系的搜索词确定候选语义项-词对。
根据本发明的又一实施例,历史搜索数据可包括搜索词和对应的用户点击的文本序列,词对判断模块203可包括第三确定模块,用于:获取预先添加到第一索引中的新词;根据新词和与特定文本序列对应的搜索词中属于新词的子串的搜索词确定候选语义项-词对,其中,特定文本序列为包括所述新词的用户点击的文本序列。
根据本发明的又一实施例,词对判断模块203可包括上述的第一确定模块、第二确定模块、第三确定模块三者之中的任意一个或多个模块。
根据本发明的一个实施例,词对判断模块203可包括第一判断模块,用于:判断候选语义项-词对中的候选语义项的总体使用占比是否超过第一阈值,若是,则候选语义项-词对正确,否则,候选语义项-词对有误,候选语义项的总体使用占比为n1与n2的比值,其中,n1为所有与包括候选语义项的搜索词对应、且与候选语义项-词对相关的文本序列的点击量总和中,由候选语义项召回的点击量之和,n2为所有与包括候选语义项的搜索词对应的文本序列点击量总和。
根据本发明的另一实施例,词对判断模块203可包括第二判断模块,用于:计算所有包括候选语义项-词对中的候选语义项的搜索词之中,使用率最大的预设数量个搜索词分别对应的候选语义项使用占比;判断使用率最大的预设数量个搜索词之中,是否存在至少一个搜索词满足如下条件:该搜索词对应的候选语义项使用占比大于第二阈值,且该搜索词的搜索量大于第三阈值,且该搜索词对应的文本序列点击量大于第四阈值,且该搜索词对应的文本序列点击率大于第五阈值。如果存在至少一个搜索词,则候选语义项-词对正确,否则,候选语义项-词对有误,每个搜索词对应的候选语义项使用占比为n3与n4的比值,其中,n3为与该搜索词对应、且与候选语义项-词对相关的文本序列的点击量总和中,由候选语义项召回的点击量之和,n4为与该搜索词对应的文本序列点击量总和。
根据本发明的又一实施例,词对判断模块203可包括第三判断模块,用于:判断候选语义项-词对中的候选语义项与候选词是否相似,若候选语义项与候选词相似,则候选语义项-词对正确,否则,候选语义项-词对有误。
其中,第三判断模块可包括第一相似性判断模块,用于:获取预设历史时间段内的用户搜索数据,用户搜索数据包括搜索词和用户对搜索到的文本序列的预设各级别的多个类目的点击量或搜索量;根据搜索词包括候选语义项时的预设各级别的多个类目的点击量或搜索量生成预设各级别的第一候选语义项向量,以及根据搜索词包括候选词时的预设各级别的多个类目的点击量或搜索量生成预设各级别的第一候选词向量;分别计算预设各级别的第一候选语义项向量与第一候选词向量之间的向量相似度,以得到分别对应预设各级别的多个第一向量相似度;判断每个第一向量相似度是否大于预先设置的与相应预设级别对应的第六阈值,若是,则候选语义项与所述候选词相似,否则,候选语义项与候选词不相似。
或者,第三判断模块可包括第二相似性判断模块,用于:通过预设模型生成第二候选语义项向量和第二候选词向量;计算第二候选语义项向量和第二候选词向量的向量相似度,以得到第二向量相似度;判断第二向量相似度是否大于第七阈值,若是,候选语义项与候选词相似,否则,候选语义项与候选词不相似。
上述的向量相似度可以为余弦相似度或者杰卡德相似度。
索引修正模块204可以在当候选语义项-词对正确时:如果第一索引中不存在候选语义项-词对中的候选语义项与候选词的映射关系,则将该映射关系添加到第一索引;在当候选语义项-词对有误时:如果第一索引中存在候选语义项-词对中的候选语义项与候选词的映射关系,则将该映射关系从第一索引中删除。
另外,在本发明实施例中所述建立索引的装置的具体实施内容,在上面所述建立索引的方法中已经详细说明了,故在此重复内容不再说明。
图3示出了可以应用本发明实施例的建立索引的方法或建立索引的装置的示例性系统架构300。
如图3所示,系统架构300可以包括终端设备301、302、303,网络304和服务器305。网络304用以在终端设备301、302、303和服务器305之间提供通信链路的介质。网络304可以包括各种连接类型,例如有线、无线通信链路或者光纤电缆等等。
用户可以使用终端设备301、302、303通过网络304与服务器305交互,以接收或发送消息等。终端设备301、302、303上可以安装有各种通讯客户端应用,例如购物类应用、网页浏览器应用、搜索类应用、即时通信工具、邮箱客户端、社交平台软件等。
终端设备301、302、303可以是具有显示屏并且支持网页浏览的各种电子设备,包括但不限于智能手机、平板电脑、膝上型便携计算机和台式计算机等等。
服务器305可以是提供各种服务的服务器,例如对用户利用终端设备301、302、303所浏览的购物类网站提供支持的后台管理服务器。后台管理服务器可以对接收到的产品信息查询请求等数据进行分析等处理,并将处理结果(例如产品信息)反馈给终端设备。
需要说明的是,本发明实施例所提供的建立索引的方法一般由服务器305执行,相应地,建立索引的装置一般设置于服务器305中。
应该理解,图3中的终端设备、网络和服务器的数目仅仅是示意性的。根据实现需要,可以具有任意数目的终端设备、网络和服务器。
下面参考图4,其示出了适于用来实现本申请实施例的服务器的计算机系统400的结构示意图。图4示出的服务器仅仅是一个示例,不应对本申请实施例的功能和使用范围带来任何限制。
如图4所示,计算机系统400包括中央处理单元(cpu)601,其可以根据存储在只读存储器(rom)402中的程序或者从存储部分408加载到随机访问存储器(ram)403中的程序而执行各种适当的动作和处理。在ram403中,还存储有系统400操作所需的各种程序和数据。cpu401、rom402以及ram403通过总线404彼此相连。输入/输出(i/o)接口405也连接至总线404。
以下部件连接至i/o接口405:包括键盘、鼠标等的输入部分406;包括诸如阴极射线管(crt)、液晶显示器(lcd)等以及扬声器等的输出部分407;包括硬盘等的存储部分408;以及包括诸如lan卡、调制解调器等的网络接口卡的通信部分409。通信部分409经由诸如因特网的网络执行通信处理。驱动器410也根据需要连接至i/o接口405。可拆卸介质411,诸如磁盘、光盘、磁光盘、半导体存储器等等,根据需要安装在驱动器410上,以便于从其上读出的计算机程序根据需要被安装入存储部分408。
特别地,根据本发明公开的实施例,上文参考主要步骤示意图描述的过程可以被实现为计算机软件程序。例如,本发明公开的实施例包括一种计算机程序产品,其包括承载在计算机可读介质上的计算机程序,该计算机程序包含用于执行主要步骤示意图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分409从网络上被下载和安装,和/或从可拆卸介质411被安装。在该计算机程序被中央处理单元(cpu)401执行时,执行本申请的系统中限定的上述功能。
需要说明的是,本发明所示的计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质或者是上述两者的任意组合。计算机可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子可以包括但不限于:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机访问存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本申请中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本申请中,计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:无线、电线、光缆、rf等等,或者上述的任意合适的组合。
附图中的主要步骤示意图和框图,图示了按照本申请各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,主要步骤示意图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,上述模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图或主要步骤示意图中的每个方框、以及框图或主要步骤示意图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
描述于本发明实施例中所涉及到的模块可以通过软件的方式实现,也可以通过硬件的方式来实现。所描述的模块也可以设置在处理器中,例如,可以描述为:一种处理器包括词对生成模块201、索引建立模块202、词对判断模块203、索引修正模块204。其中,这些模块的名称在某种情况下并不构成对该模块本身的限定,例如,词对生成模块201还可以被描述为“用于将输入的文本序列分为多个词,根据多个词和多个词的子串得到多个语义项-词对的模块”。
作为另一方面,本发明还提供了一种计算机可读介质,该计算机可读介质可以是上述实施例中描述的设备中所包含的;也可以是单独存在,而未装配入该设备中。上述计算机可读介质承载有一个或者多个程序,当上述一个或者多个程序被一个该设备执行时,使得该设备包括:将输入的文本序列分为多个词,根据所述多个词和所述多个词的子串得到多个语义项-词对;根据所述多个语义项-词对建立第一索引;根据用户的历史搜索数据确定候选语义项-词对,并判断所述候选语义项-词对是否正确;根据所述判断的结果修正所述第一索引,以得到第二索引。
根据本发明实施例的技术方案,将输入的文本序列分为多个词,根据多个词和多个词的子串得到多个语义项-词对,根据该多个语义项-词对建立第一索引,根据用户的历史搜索数据确定候选语义项-词对,并判断候选语义项-词对是否正确,根据判断的结果修正第一索引,以得到第二索引。能够在商品索引召回阶段,既能够保证召回率以尽可能多地召回与用户搜索词相关的商品,又能提高准确率以尽可能地过滤掉不相关的商品。
上述具体实施方式,并不构成对本发明保护范围的限制。本领域技术人员应该明白的是,取决于设计要求和其他因素,可以发生各种各样的修改、组合、子组合和替代。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!