一种基于MapReduce的大规模公交乘客OD并行计算方法与流程
本发明涉及一种基于mapreduce的大规模公交乘客od并行计算方法。
背景技术:
随着定位技术的成熟,位置传感器硬件得到广泛普及,城市中客运车辆都装备有车载定位系统,公交车实时的位置信息以及其他状态信息能够被轻易获得。由传感器采集得到的数据具有时效性强、范围广、数据量大等特点,通过数据挖掘技术手段我们能够从中计算出有价值的信息。
hadoop是目前在大数据领域中比较成熟,应用最为广泛的分布式计算平台,主要由分布式文件存储系统hdfs和分布式计算框架mapreduce组成,在处理海量数据时具有高可靠性、高扩展性、高效性和高容错性。hbase是一个构建在hdfs上的分布式面向列的数据库,可以存储海量数据,基于行键有较高的查询效率。
公交车辆轨迹数据和ic卡刷卡数据中蕴藏着城市客流、城市居民出行规律、城市居民的乘车需求等有用的信息。现有根据公交车辆轨迹数据和公交ic卡刷卡数据推算公交乘客od(origin-destination)点的方法包括:基于概率论的站点吸引度法、基于居民出行规律的出行链方法。这些方法大都基于传统的关系型数据库计算,在数据量较小,如几条线路或是较小量用户出行模式分析的情况下具有较好的效果。然而随着公交数据量与日俱增,传统关系型数据存储系统在存储计算大规模的数据时已经捉襟见时,用传统的推算公交乘客od点的方法已不能满足当下快速推算大规模公交乘客od点的需求。
技术实现要素:
本发明的目的在于提供一种基于mapreduce的大规模公交乘客od并行计算方法,该方法运用hadoop的mapreduce并行计算框架和hbase数据库在出行链方法基础上结合乘客历史相似出行行为规律来并行计算大规模公交乘客od点,不仅提高了大规模公交乘客od点的计算效率,同时也提高了推算公交乘客od点的准确率,具有较高的实用价值。
为实现上述目的,本发明的技术方案是:一种基于mapreduce的大规模公交乘客od并行计算方法,包括如下步骤,
步骤s1:对原始公交数据包括ic卡数据、公交车辆gps数据、公交车辆信息数据以及公交线路站点数据进行预处理;
步骤s2:将预处理过ic卡数据、公交车辆gps数据存储到hbase数据库;将公交车辆信息数据和公交线路站点数据存储到hdfs;
步骤s3:根据mapreduce的特点,在map函数中依次读取每条ic卡记录,获取其相关信息,根据车辆编号及其刷卡时间等信息获取到相应车辆进出站数据,再结合公交线路站点数据计算出该ic卡持有者乘坐公交出行的上车站点,即o点;
步骤s4:在reduce函数中对能够计算得到o点的ic卡记录,以ic卡号为单位进行归并,以键值对的形式输出到hdfs;
步骤s5:在步骤s4的基础上,在新的map函数中,依次读取每个用户已计算出o点的所有ic卡记录,将该些用户按照连续出行链方法推算得到出行d点的刷卡记录添加到集合sb,而未能推算出d点刷卡记录添加到集合sa;其中,出行d点即乘客公交出行的下车站点;
步骤s6:在步骤s5的基础上,对集合sa的刷卡记录,在map函数中根据居民工作日和非工作日的出行特征,以及历史出行站点频次来推算乘客公交出行的下车站点;
步骤s7:在reduce函数中,按照刷卡时间对每个ic卡号的出行od记录进行排序,并以ic卡号为键,以出行od记录为值输出,完成大规模公交乘客od并行计算过程。
在本发明一实施例中,所述步骤s1中,对原始公交数据进行预处理包括:
步骤s11:删除原始公交ic卡数据中不必要的字段,即保留ic卡号、刷卡时间、线路编号、公交车辆编号字段信息;
步骤s12:删除原始公交车辆gps数据中不必要字段,即保留gps设备编号、线路编号、行驶方向、gps时间、进出站标志、纬度、经度、站点编号字段信息;
步骤s13:整理公交车辆信息数据,根据车辆编号和车辆gps设备编号对应关系,即根据一个公交车辆编号找到对应的车辆gps设备编号;
步骤s14:整理公交线路及公交站点数据,转换公交站点的经纬度坐标系为wgs-84坐标系,同时转换公交站点经纬度信息为墨卡托平面坐标。
在本发明一实施例中,所述步骤s2,具体包括:
步骤s21:在hbase数据库中创建表ic_card,包含列簇ic_info,将ic卡数据以ic卡号和刷卡时间为组合行键,分别以ic卡号、刷卡时间、线路编号、公交车辆编号为属性值添加到列簇ic_info;
步骤s22:在hbase数据库中创建表bus_avl,包含列簇avl_info,将公交车辆gps数据以gps设备编号和gps时间为组合行键,分别以gps设备编号、线路编号、行驶方向、gps时间、进出站标志、纬度、经度、站点编号为属性值添加到列簇avl_info;
步骤s23:将公交车辆信息数据以车辆编号为键,以车辆gps设备编号为属性值,创建文件bus_info并存储到hdfs;
步骤s24:将公交线路站点数据以线路编号为键,以该条线路所有的站点为属性值,创建文件line_info并存储到hdfs。
在本发明一实施例中,所述步骤s3,具体包括:
步骤s31:在map函数中,从表ic_card中读取一条ic卡记录,并获取其ic卡号、公交线路编号、刷卡时间、公交车辆编号信息;
步骤s32:根据公交车辆编号从文件bus_info中获得相应公交车辆gps设备编号;
步骤s33:根据车辆gps设备编号和刷卡时间对bus_avl表进行索引,查询出刷卡时间前3分钟,后7分钟时间段内该公交车辆所有进出站数据;
步骤s34:遍历所有进出站数据,依次判断刷卡时间是否大于第一条车辆进站时间并且小于第二条车辆进站时间,若是,则计算刷卡时间与两次进站之间出站时间的时间差绝对值δt1和刷卡时间与后进站时间的时间差绝对值δt2;若δt1<δt2,返回第一条进站数据的行驶方向、经纬度信息,否则返回第二条进站数据的行驶方向、经纬度信息;若刷卡时间不符合条件,则开始读取下一条刷卡记录;
步骤s35:根据步骤s31获取的线路编号和步骤s34获取的车辆行驶方向从文件line_info中获取对应的站点集合station,包括每个站点的站点编号、站点名称、平面坐标信息;
步骤s36:将步骤s34获取的车辆进站经纬度信息转换为墨卡托平面坐标;
步骤s37:计算步骤s36获取的车辆位置信息与集合station中每个站点的距离,并获得最小距离dmin,dmin所对应的公交站点即为该条ic卡记录的o点;
步骤s38:判断该条刷卡记录是否是最后一条,若是,在结束该map任务,若不是,则读取下一条刷卡记录,进入下一条刷卡记录上车站点推算过程;
在本发明一实施例中,所述步骤s4,具体包括:
步骤s41:在reduce函数中,以ic卡号为单位,将该ic卡卡号的所有上车记录按照刷卡时间排序;
步骤s42:以ic卡号为键,以该ic卡用户的所有o点记录为属性值,以键值对形式输出到hdfs。
在本发明一实施例中,所述步骤s5,具体包括:
步骤s51:在步骤s4的基础上,map函数中读取一个ic卡用户的所有上车记录;
步骤s52:读取第i条上车记录,判断第i+1条数据是否存在,若不存在,则将第i条上车记录添加到集合sa;若存在,则读取第i条和第i+1条上车记录;
步骤s53:在步骤s52的基础上,当第i条和第i+1条上车记录都存在时,比较这两条记录的日期,若在同一天内,则计算两次乘车时间间隔δt,如果δt<α,第i条上车记录为代刷卡情况,将第i条上车记录添加到集合sa;若δt>α,则计算两条记录的乘车线路编号,若乘车线路编号相等,则将第i+1条上车记录的上车站点视为第i条上车记录的下车站点,将第i条od记录添加到集合sb;如果乘车线路编号不相等,则计算第i+1条记录的上车站点与第i条记录乘车线路的所有站点的距离,获得其最小距离dmin,如果dmin<=β,则dmin所对应的公交站点为第i条上车记录的下车站点,将第i条od记录添加到sb,否则将第i条上车记录添加到sa;其中,α为时间阈值,设置为1分钟;β为距离阈值,设置为500米,代表换乘中可接受的最大步行距离;
步骤s54:在步骤s52的基础上,当第i条和第i+1条上车记录都存在时,比较这两条记录的日期,若第i条和第i+1条上车记录不在同一天时间内,则第i条为前一天的最后一条乘车记录,而第i+1条为次日第一条乘车记录;根据第i条上车记录的线路编号、线路方向、站点编号信息获取该次乘车的可能下车站点;将这些可能的下车站点与当日第一次乘车的上车站点进行比较,如果两个站点相等或相近,则该站点为第i条上车记录的下车站点,并将第i条od记录添加到sb;否则将这些可能的下车站点与次日第一条乘车记录的上车站点进行比较,如果两个站点相等或相近,则该站点为第i条上车记录的下车站点,并将第i条od记录添加到sb,否则将第i条上车记录添加到sa;
步骤s55:输出sa和sb。
在本发明一实施例中,所述步骤s6,具体包括:
步骤s61:在步骤s5的map函数中读取集合sa的第k条记录,判断第k条记录的刷卡时间是否属于工作日,若是,则在集合sb中寻找相似的工作日d点作为该条上车记录的d点,将od记录添加到sb;如果未找到相应的d点则将该条上车记录添加到集合sc;若不是,则在集合sb中寻找相似非工作日的d点作为该条上车记录的d点,将od记录添加到sb;如果未找到相应的d点则将该条上车记录添加到集合sc;
步骤s62:统计该ic卡用户历史出行的上车站点频次,按频次排序并存入一个map集合m;读取集合sc的第j条上车记录,根据线路编号、行驶方向、站点编号获取该次乘车所有可能的下车站点,添加到集合sd;
步骤s63:在步骤s62基础上将sd的站点名称和集合m中的站点名称进行匹配,若匹配的站点数为1,则该站点就是第j条上车记录的下车站点,将第j条od记录添加到sb;若匹配的站点数大于1,则比较匹配结果中每个站点的频次,频次最高的站点为第j条记录的下车站点,将第j条od记录添加到sb;
步骤s64:在步骤s63的基础上,若第j条上车记录未匹配到相应的d点,则该条记录无法推算到下车站点;若该条记录不是该用户最后一条上车记录,则读取下一条上车记录,否则就结束该用户的下车站点推算工作,输出集合sb并进行下一个用户的下车站点推算,直到所有用户下车站点推算完毕。
在本发明一实施例中,所述步骤s7,具体包括:
步骤s71:reduce函数中,在步骤s5和步骤s6的基础上读取一个ic卡用户公交出行的所有od记录,并按照刷卡时间进行排序;
步骤s72:在步骤s71的基础上,以ic卡号为键,以已排序的所有od记录为属性值,输出到hdfs,循环读取每一个ic卡用户,直到结束,完成大规模公交乘客od并行计算过程。
在本发明一实施例中,所述步骤s36中,将步骤s34获取的车辆进站经纬度信息转换为墨卡托平面坐标的转换方式如下:
其中,b为纬度,l为经度,x表示横坐标,y为纵坐标,
相较于现有技术,本发明具有以下有益效果:
1、本发明使用了能存储海量数据的hbase数据库和目前比较成熟的mapreduce并行计算框架来存储、推算大规模公交乘客od点,提高了大规模公交乘客od点的计算效率;
2、本发明在现有的推算公交乘客od点的基础上,充分考虑了ic卡用户的历史出行行为规律,根据居民工作日和非工作日的出行特征,以及历史出行站点频次来推算公交乘客下车站点,推算结果更加准确;
3、本发明对于不同城市的公交数据都能快速并行推算公交乘客od点,具有较好的适用性。
附图说明
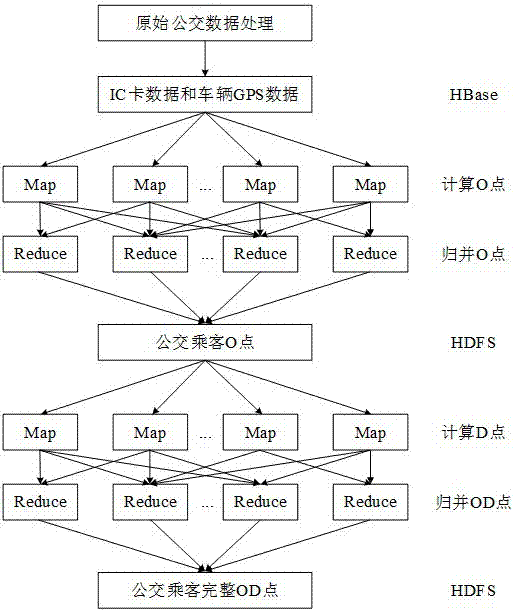
图1是本发明方法的流程图。
图2是本发明方法的具体实施例流程图
图3是本发明大规模公交乘客o点并行推算流程图。
图4是本发明基于连续性公交出行链方法推算大规模公交乘客d点流程图。
图5是本发明根据乘客历史相似出行行为规律推算大规模公交乘客d点流程图。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
请参照图1-2,本发明提供一种基于mapreduce的大规模公交乘客od并行计算方法,包括以下步骤:
步骤s1:对原始公交数据包括ic卡数据、公交车辆gps数据、公交车辆信息数据以及公交线路站点数据进行预处理;所述公交数据预处理包括:
步骤s11:删除原始公交ic卡数据中不必要的字段,保留ic卡号、刷卡时间、线路编号、公交车辆编号字段信息。
步骤s12:删除原始公交车辆gps数据中不必要字段,保留gps设备编号、线路编号、行驶方向、gps时间、进出站标志、纬度、经度、站点编号字段信息。
步骤s13:整理公交车辆信息数据,根据车辆编号和车辆gps设备编号对应关系,可根据一个公交车辆编号找到对应的车辆gps设备编号。
步骤s14:整理公交线路及公交站点数据,转换公交站点的经纬度坐标系为wgs-84坐标系,同时也转换公交站点经纬度信息为墨卡托平面坐标。
步骤2:在步骤s1基础上设计公交数据的存储方案如下:
步骤s21:在hbase数据库中创建表ic_card,包含列簇ic_info,表结构如表1所示。将ic卡数据以ic卡号和刷卡时间为组合行键,分别以ic卡号、刷卡时间、线路编号、公交车辆编号为属性值添加到列簇ic_info。
表
步骤s22:在hbase数据库中创建表bus_avl,包含列簇avl_info,表结构如表2所示。将公交车辆gps数据以gps设备编号和gps时间为组合行键,分别以gps设备编号、线路编号、行驶方向、gps时间、进出站标志、纬度、经度、站点编号为属性值添加到列簇avl_info。
表
步骤s23:将公交车辆信息数据以车辆编号为键,以车辆gps设备编号为属性值,创建文件bus_info并存储到hdfs。
步骤s24:将公交线路站点数据以线路编号为键,以这条线路所有的站点为属性值,创建文件line_info并存储到hdfs。
步骤s3:根据mapreduce的特点,在map函数中依次读取每条ic卡记录,获取其相关信息,根据车辆编号及其刷卡时间等信息获取到相应车辆进出站数据,再结合公交线路站点数据计算出该ic卡持有者乘坐公交出行的上车站点(即o点)。具体计算流程如图3所示,包括以下步骤:
步骤s31:在map函数中,从表ic_card中读取一条ic卡记录,并获取其ic卡号、公交线路编号、刷卡时间、公交车辆编号信息。
步骤s32:根据公交车辆编号从文件bus_info中获得相应公交车辆gps设备编号。
步骤s33:根据车辆gps设备编号和刷卡时间对bus_avl表进行索引,查询出刷卡时间前3分钟,后7分钟时间段内该公交车辆所有进出站数据。
步骤s34:遍历所有进出站数据,依次判断刷卡时间是否大于第一条车辆进站时间并且小于第二条车辆进站时间,若是,则计算刷卡时间与两次进站之间出站时间的时间差绝对值δt1和刷卡时间与后进站时间的时间差绝对值δt2。若δt1<δt2,返回第一条进站数据的行驶方向、经纬度信息,否则返回第二条进站数据的行驶方向、经纬度信息。若刷卡时间不符合条件,则开始读取下一条刷卡记录。
步骤s35:根据步骤s31获取的线路编号和步骤s34获取的车辆行驶方向从文件line_info中获取对应的站点集合station,包括每个站点的站点编号、站点名称、平面坐标信息。
步骤s36:将步骤s34获取的车辆进站经纬度信息转换为墨卡托平面坐标。这一步是为了后续步骤中车辆位置信息与公交站点以及公交站点之间欧式空间距离的计算与表示。转换方法如下:
其中,b为纬度,l为经度,x表示横坐标,y为纵坐标,
步骤s37:计算步骤s36获取的车辆位置信息与集合station中每个站点的距离,并获得最小距离dmin,dmin所对应的公交站点即为该条ic卡记录的o点。
步骤s38:判断该条刷卡记录是否是最后一条,若是,在结束该map任务,若不是,则读取下一条刷卡记录,进入下一条刷卡记录上车站点推算过程。
步骤s4:在reduce函数中对能够计算得到o点的ic卡记录,以ic卡号为单位,以键值对的形式输出到hdfs,包括以下步骤:
步骤s41:在reduce函数中,以ic卡号为单位,将该ic卡卡号的所有上车记录按照刷卡时间排序。
步骤s42:以ic卡号为键,以该ic卡用户的所有o点记录为属性值,以键值对形式输出到hdfs。
步骤s5:在步骤s4的基础上,在map函数中,依次读取每个用户已计算出o点的所有ic卡记录,将该用户按照连续出行链方法推算得到出行d点的刷卡记录添加到集合sb,而未能推算出d点刷卡记录添加到集合sa。具体流程如图4所示,包括以下步骤:
步骤s51:在步骤s4的基础上,map函数中读取一个ic卡用户的所有上车记录。
步骤s52:读取第i(初始值为1)条上车记录,判断第i+1条数据是否存在,若不存在,则将第i条上车记录添加到集合sa(sa是按照连续出行链方法未能推算出下车站点的上车记录集合);若存在,则读取第i条和第i+1条上车记录。
步骤s53:在步骤s52的基础上,当第i条和第i+1条上车记录都存在时,比较这两条记录的日期,若在同一天内,则计算两次乘车时间间隔δt,如果δt<α(α为时间阈值,设置为1分钟),第i条上车记录为代刷卡情况,将第i条上车记录添加到集合sa;若δt>α,则计算两条记录的乘车线路编号,若乘车线路编号相等,则将第i+1条上车记录的上车站点视为第i条上车记录的下车站点,将第i条od记录添加到集合sb。如果乘车线路编号不相等,则计算第i+1条记录的上车站点与第i条记录乘车线路的所有站点的距离,获得其最小距离dmin,如果dmin<=β(β为距离阈值,设置为500米,代表换乘中可接受的最大步行距离),则dmin所对应的公交站点为第i条上车记录的下车站点,将第i条od记录添加到sb,否则将第i条上车记录添加到sa。
步骤s54:在步骤s52的基础上,当第i条和第i+1条上车记录都存在时,比较这两条记录的日期,若第i条和第i+1条上车记录不在同一天时间内,则第i条为前一天的最后一条乘车记录,而第i+1条为次日第一条乘车记录(上车记录已按刷卡时间排序)。根据第i条上车记录的线路编号、线路方向、站点编号信息获取该次乘车的可能下车站点。将这些可能的下车站点与当日第一次乘车的上车站点进行比较,如果两个站点相等或相近(相等:站点名称一样,相近:两个站点距离<=
步骤s55:输出sa和sb。
步骤s6:在步骤s5的基础上,对集合sa的刷卡记录,在map函数中根据居民工作日和非工作日的出行特征,以及历史出行站点频次来推算乘客公交出行的下车站点(即d点)。具体流程如图5所示,包括如下步骤:
步骤s61:在步骤s5的map函数中读取集合sa的第k条记录(初始k=1),判断第k条记录的刷卡时间是否属于工作日,若是,则在集合sb中寻找相似的工作日d点作为该条上车记录的d点,将od记录添加到sb;如果未找到相应的d点则将该条上车记录添加到集合sc;若不是,则在集合sb中寻找相似非工作日的d点作为该条上车记录的d点,将od记录添加到sb;如果未找到相应的d点则将该条上车记录添加到集合sc。
步骤s62:统计该ic卡用户历史出行的上车站点频次,按频次排序并存入一个map集合m。读取集合sc的第j条上车记录(初始j=1),根据线路编号、行驶方向、站点编号获取该次乘车所有可能的下车站点,添加到集合sd。
步骤s63:在步骤s62基础上将sd的站点名称和集合m中的站点名称进行匹配,若匹配的站点数为1,则该站点就是第j条上车记录的下车站点,将第j条od记录添加到sb;若匹配的站点数大于1,则比较匹配结果中每个站点的频次,频次最高的站点为第j条记录的下车站点,将第j条od记录添加到sb。
步骤s64:在步骤s63的基础上,若第j条上车记录未匹配到相应的d点,则该条记录无法推算到下车站点。若该条记录不是该用户最后一条上车记录,则读取下一条上车记录,否则就结束该用户的下车站点推算工作,输出集合sb并进行下一个用户的下车站点推算,直到所有用户下车站点推算完毕。
步骤s7:在reduce函数中,按照刷卡时间对每个ic卡号的出行od记录进行排序,并以ic卡号为键,以出行od记录为值输出,完成大规模公交乘客od并行计算过程。具体步骤如下:
步骤s71:reduce函数中,在步骤s5和步骤s6的基础上读取一个ic卡用户公交出行的所有od记录,并按照刷卡时间进行排序。
步骤s72:在步骤s71的基础上,以ic卡号为键,以已排序的所有od记录为属性值,输出到hdfs,循环读取每一个ic卡用户,直到结束,完成大规模公交乘客od并行计算过程。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!