一种行人检测方法与流程
本发明涉及一种行人检测方法,属于目标检测领域。
背景技术:
近年来,行人检测技术在智能监控、自动驾驶、机器人视觉等方面具有广泛的应用。实际应用中行人的着装,姿态尤其是视频中捕捉到的行人尺寸多变使得行人检测面临极大的挑战性。行人检测主要有两大方式:一种是基于滑动窗口的传统的行人检测方法,一种是基于深度学习提取特征的行人检测方法。传统的行人检测方法计算量大且没有利用gpu资源检测速度受限,由于计算机性能不断增强并且利用了gpu计算能力,大多基于学习特征的深度学习方法检测速度优于传统方法,但是往往难以解决行人的多尺度问题。
技术实现要素:
为了解决行人检测过程中速度和检测精度难以权衡以及行人的多尺度问题,本发明提供一种行人检测方法,包括步骤:
步骤(1)确定当前帧图像:将测试集中的一张图片作为当前帧图像或者视频序列中待处理的帧图像作为当前帧图像;
步骤(2)求得特征图:将当前帧图像通过多个卷积层和池化层,通过最后一个卷积层得到一个(featuremap)特征图;
步骤(3)特征图扩展:通过图像特征金字塔规则计算图像临近尺度对应的特征图,依次扩展n个小尺度扩展特征图和n个大尺度扩展扩展特征图,扩展次数n和扩展倍数不设限,一共得到2n+1个特征图;
步骤(4)提议窗口分配:特征图经过区域建议网络rpn(regionproposalnetwork)生成候选窗口,根据行人尺寸分布进一步选择候选窗口;
步骤(5)分类网络训练:利用多种尺度行人在不同特征图中的的分布训练深度神经网络;
步骤(6)行人检测标注:将得到的三种规模特征图的提议窗口数目按比例汇总,经过步骤(5)中训练好的分类器分类,经过非极大值抑制后框出行人。
进一步的,步骤(1)具体为:将测试集中的一张图片作为当前帧图像或者视频序列中待处理的帧图像作为当前帧图像,记做i1。
进一步的,步骤(2)具体为:将当前帧图像通过多个卷积层和池化层,这里卷积层和池化层交叉进行并且层数不设限,通过最后一个卷积层得到一个特征图(featuremap),记做f1。
进一步的,步骤(3)具体为:通过图像幂率规则和图像特征金字塔规则计算图像i1临近规模对应的特征图,一般利用fm=cp(s(i1,m)),式中i1代表原图像,m代表缩放规模,s代表将原图缩放,cp代表卷积池化操作计算特征。现在为减少卷积运算提高运行速度,利用公式:
其中参数m表示当前规模,m’表示缩放后规模,s代表将特征图缩放m'/m倍,f表示特征,常系数α可以在训练集上通过实验测得,以上公式表明原图im通过卷积池化操作计算特征,临近缩放规模图像特征由已知特征图变化得到,将得到的特征图计算出原图α倍大小和β倍大小的图片对应的特征图,如1/2*i1和2*i1(此处扩展的图片规模和扩展次数不设限,考虑检测速度和表述方便选取这两个尺度),因为金字塔规则每次临近计算
fσ=σ*s(f1,σ))(2.2)
式中f1代表原图对应特征图,s代表将特征图f1放大σ倍,fσ为上采样图像。
进一步的,步骤(4)具体为:因为rpn有单一的感受野,在缩小规模的图像对应特征图上倾向于检测大目标,在放大规模的图像对应特征图上倾向于检测小目标,我们将图像中行人目标分为三个尺度,我们在有多尺度行人的kitti数据集上实验,将数据集中的行人按照高度height不同设置为height<h1,h1≤height<h2,...,hn-1≤height<hn,height≥hn,这里h1到hn是由小大的像素点个数,对应不同尺度的行人数目分别为a1,a2,...,an。然后在每一张特征图上对每个尺度的行人候选框按特征图中候选框比例分布选取t个,依次选取tuv个,
式中tuv是最终需要提取的第u张特征图上第v个规模尺度行人的个数,zu是第u张特征图上最终需要提取的候选窗口的总和,zu(1≤n≤2n+1)根据数据集情况而定,每张特征图上可以选取同样数目也可以提取不同数目),式中auv表示第u张特征图上第v个规模尺度行人的个数。因为提议窗口网络有单一的感受野(输出特征图上某个节点的响应对应的输入图像的区域),在缩小规模的图像对应特征图上倾向于检测大目标,在放大规模的图像对应特征图上倾向于检测小目标,这样根据不同尺度目标的比例提取候选窗口有利于发挥网络在不同特征图上的检测优势。
进一步的,步骤(5)具体为:
1)选择在有多种行人尺度的kitti数据集上实验,我们在训练数据集上将行人按高度分为x个尺寸的行人(此处尺寸级数不设限);
2)利用卷积层特征共享训练rpn(regionproposalnetwork)网络和softmax分类器联合网络,采用交叉轮流训练的方式,先训练rpn区域建议网络,再用候选窗口训练基于区域的分类器网络,再用分类器网络训练rpn区域建议网络。损失层(losslayer)是卷积神经网络(cnn)的终点,接受两个值作为输入,其中一个是cnn的预测值,另一个是真实标签。损失层则通过预测值和标签值进行一系列运算,得到当前网络的损失函数(lossfunction),一般记做l(w),其中w是当前网络权值构成的向量空间。训练网络的目的是在权值空间中找到让损失函数l(w)最小的权值w(opt),可以采用随机梯度下降(stochasticgradientdescent)的最优化方法逼近权值w(opt),网络中有两个损失函数,一个是分类损失函数一个是回归损失函数;
3)因为步骤(3)结构的改变,损失函数要进行相应的优化,要训练优化的参数为w,设
4)这样多任务损失函数为:
其中n是目标大小的规模级数,ex是每个规模对应的数据样本,mi是训练集采样到的感兴趣图像块,a1,a2,...,an分别代表n种尺度的行人的数量,l是分类和回归的联合损失函数,定义为:
l(m,(y,b)|w)=lcls(p(m),y)+β[y≥1]lloc(ty,b)(2.5)
其中β是权衡系数,ty是类y的预测边框位置,[y≥1]表示只有在正本时才存在回归损失,lclc和lloc分别是交叉熵损失和边界回归损失,定义为:
式中py(m)=p0(m)+p1(m),
5)由于4)中预测概率p和预测标签t都分别有经过proposal后的特征向量和各自权值向量相乘得到,所以由以上公式可根据预测值和标签不断调整分类和回归过程中的联合参数,使损失函数l(w)最小从而得到联合最优参数w(wcls,wloc),即
进一步的,步骤(6)具体为:将步骤(4)中的提议窗口汇总成j个,经过感兴趣池层和全连接层是输入特征图尺寸固定,经过步骤(5)中训练好的分类器分类,通过非极大值抑制,除去与最大置信度窗口重叠超过65%的窗口。
本发明公开了一种基于卷积神经网络的行人检测方法,通过图像的特征金字塔规则计算出原图相邻尺寸对应的特征图,避免了图像缩放计算得到特征图的繁重计算量,并且利不同特征图上检测用不同权值加权有效避免了单一特征图检测的误判和漏检。所以实现了行人检测速度和精度的有效权衡。
附图说明
图1是本发明的一种基于卷积神经网络的行人检测方法流程图;
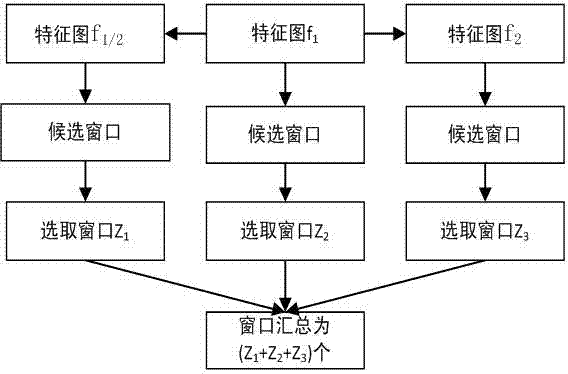
图2是本发明的行人检测方法的候选窗口(proposal)优化选取算法图;
图3是非极大值抑制实现方法示意图;
图4是本申请的行人检测方法在kitti数据集图片上的效果图。
具体实施方式
下面结合附图对本发明作进一步说明。
如图1所示,本发明的一种基于卷积神经网络的行人检测方法,包括以下步骤:
步骤(1)确定当前帧图像:将测试集中的一张图片作为当前帧图像或者视频序列中待处理的帧图像作为当前帧图像;
步骤(2)求得特征图:将当前帧图像通过多个卷积层和池化层,通过最后一个卷积层得到一个特征图(featuremap);
步骤(3)特征图扩展:通过图像幂率规则和图像特征金字塔规则计算图像临近规模对应的特征图,此处扩展的图片规模和扩展次数不设限;
步骤(4)提议窗口分配:选择一个合适的行人数据集或者自己制作一个行人尺度多变的数据集,将图片中目标分为小、中、大这三个规模(规模级数由数据集行人规模而定),按图片中同规模目标所占比例分配提议窗口数目;
步骤(5)分类网络训练:利用多种尺度行人在不同特征图中的的分布训练深度神经网络;
步骤(6)行人检测标注:将得到的三种规模特征图的候选窗口数目按比例汇总,经过步骤(5)中训练好的分类器分类,经过非极大值抑制后框出行人。
所述步骤(1)中对确定当前帧图像的步骤为:将测试集中的一张图片作为当前帧图像或者视频序列中待处理的帧图像作为当前帧图像,记做i1。
所述步骤(2)中对求得特征图的步骤为:将当前帧图像通过多个卷积层和池化层,这里卷积层和池化层交叉进行并且层数不设限,通过最后一个卷积层得到一个特征图(featuremap),记做f1。
所述步骤(3)中对特征图扩展的步骤为:通过图像幂率规则和图像特征金字塔规则计算图像i1临近规模对应的特征图,一般利用fm=cp(s(i1,m)),式中i1代表原图像,m代表缩放规模,s代表将原图缩放,cp代表卷积池化操作计算特征。现在为减少卷积运算提高运行速度,利用公式:
其中参数m表示当前规模,m'表示缩放后的规模,s代表将特征图缩放m'/m倍,f表示特征,常系数α可以在训练集上通过实验测得,以上公式表明原图im通过卷积池化操作得到特征,临近缩放规模图像特征由已知特征图近似计算得到,如1/2*i1可以计算得到f1/2,因为图像上采样没有高频损失,上采样图片的信息内容与低分辨率的内容相似,特征计算公式为:
fσ=σ*s(f1,σ))(3.2)
式中f1代表原图对应特征图,s代表将特征图f1放大σ倍,fσ为上采样图像。
所述步骤(4)中对提议窗口分配的步骤为:因为rpn有单一的感受野,在缩小规模的图像对应特征图上倾向于检测大目标,在放大规模的图像对应特征图上倾向于检测小目标,我们将图片里的目标分为三个尺度,我们在有多尺度行人的kitti数据集上实验,将数据集中的行人按照高度height不同设置为height<h1,h1≤height<h2,height≥h2这三个尺度,,这里h1到h2分别是50个、200个像素点,对应不同尺度的行人数目分别为a1,a2,a3。然后在不同特征图上行人高度小于50像素的候选窗口里按照置信度大小选取zk*a1/(a1+a2+a3)个,在行人高度大于50小于200个像素的候选窗口里按照置信度大小选取zk*a2/(a1+a2+a3)个,在行人高度大于200个像素的候选窗口里按照置信度大小选取zk*a3/(a1+a2+a3)个,这里a1,a2,a3分别代表提取前三种不同尺度行人候选窗口的数量,k=1,2,3分别表示缩小特征图、原特征图、放大特征图,zk表示每个特征图需要提取候选窗口的个数。如图2所示,f1、f1/2、f2分别代表图像i1经过最后一层卷积得到的特征图和扩展计算得到的图像i1临近规模对应的特征图,候选窗口选取个数分别为:z1、z2、z3。因为特征图检测行人偏向不同采用比例分配提议候选窗口的方式,这样根据不同目标规模的比例分配候选窗口有利于发挥网络在不同特征图上的检测优势。
所述步骤(5)中对分类网络训练的步骤为:
1)选择在有多种行人尺度的kitti数据集上实验,我们在训练数据集上将行人按高度分为x个尺寸的行人(此处尺寸级数不设限);
2)利用卷积层特征共享训练rpn(regionproposalnetwork)网络和softmax分类器联合网络,采用交叉轮流训练的方式,先训练区域提议网络(rpn),再用提议(proposal)训练基于区域的分类器网络,再用分类器网络训练区域提议网络。损失层(losslayer)是卷积神经网络(cnn)的终点,接受两个值作为输入,其中一个是cnn的预测值,另一个是真实标签。损失层则将这两个输入进行一系列运算,得到当前网络的损失函数(lossfunction),一般记做l(w),其中w是当前网络权值构成的向量空间。训练网络的目的是在权值空间中找到让损失函数l(w)最小的权值w(opt),可以采用随机梯度下降(stochasticgradientdescent)的最优化方法逼近权值w(opt),网络中有两个损失函数,一个是分类损失函数一个是回归损失函数;
3)因为步骤(3)结构的改变,损失函数要进行相应的优化,要训练优化的参数为w,设
4)这样多任务损失函数为:
其中n是目标大小的规模级数,ex是每个规模对应的数据样本,mi是训练集采样到的感兴趣图像块,a1,a2,...,an分别代表n种尺度的行人的数量,l是分类和回归的联合损失函数,定义为:
l(m,(y,b)|w)=lcls(p(m),y)+β[y≥1]lloc(ty,b)(3.4)
其中β是权衡系数,ty是类y的预测边框位置,[y≥1]表示只有在正本时才存在回归损失,lclc和lloc分别是交叉熵损失和边界回归损失,定义为:
式中py(m)=p0(m)+p1(m),
5)由于步骤4)中预测概率p和预测标签t都分别有经过提议(proposal)后的特征向量和各自权值向量相乘得到,所以由以上公式可根据预测值和标签不断调整分类和回归过程中的联合参数,使损失函数l(w)最小从而得到联合最优参数w(wcls,wloc),即w(wscl,wolc)=argminwl(w)+φ||w||。式中l(w)即多任务损失函数,φ是正则化参数。
所述步骤(6)中对行人检测标注的步骤为:将步骤(4)中的提议窗口汇总成j个,经过感兴趣池层和全连接层是输入特征图尺寸固定,经过训练好的分类器分类得到候选行人置信度,每个规模的候选行人分别与步骤(5)中训练得到的权重lx相乘,通过非极大值抑制,除去与最大置信度窗口重叠超过65%的窗口,如图3所示,s1,s3分别表示两个检测框面积,s2表示两个检测框的重叠面积,交并比为s2/(s1+s3-s2),如果交并比大于阈值0.65就舍弃置信度较小的那个框。图4是本申请的行人检测方法在kitti数据集图片上的效果图,可以看出,高度小于50pixels许多行人都检测出来了。由此可见本申请的行人检测方法的可行性和检测优势。
- 还没有人留言评论。精彩留言会获得点赞!