神经网络处理单元及包含该处理单元的处理系统的制作方法
本发明涉及深度学习技术领域,尤其涉及一种神经网络处理单元和包含该处理单元的处理系统。
背景技术:
近年来,深度学习技术得到了飞速的发展,在解决高级抽象认知问题,例如图像识别、语音识别、自然语言理解、天气预测、基因表达、内容推荐和智能机器人等领域得到了广泛应用,成为学术界和工业界的研究热点。
深度神经网络是人工智能领域具有最高发展水平的感知模型之一,其通过建立模型来模拟人类大脑的神经连接结构,通过多个变换阶段分层对数据特征进行描述,为图像、视频和音频等大规模数据处理任务带来突破性进展。深度神经网络模型是一种运算模型,由大量节点通过网状互连结构构成,这些节点被称为神经元。每两个节点间连接强度都代表通过该连接信号在两个节点间的加权重,即权重,与人类神经网络中的记忆相对应。
然而,在现有技术中,神经网络存在处理速度慢,运行功耗大等问题。这是由于深度学习技术依赖于极大的计算量,例如,在训练阶段,需要在海量数据中通过反复迭代计算得到神经网络中的权重数据;在推理阶段,同样需要神经网络在极短的响应时间(通常为毫秒级)内完成对输入数据的运算处理,特别是当神经网络应用于实时系统时,例如,自动驾驶领域。神经网络中涉及的计算主要包括卷积操作、激活操作和池化操作等,其中,卷积操作和池化操作占用了神经网络处理的大部分时间。
因此,需要对现有技术进行改进,以提高神经网络中卷积操作和池化操作等的计算效率和对输入数据的响应速度,使神经网络的适用范围更广。
技术实现要素:
本发明的目的在于克服上述现有技术的缺陷,提供一种基于流水线的神经网络处理单元和包含该处理单元的处理系统。
根据本发明的第一方面,提供了一种神经网络处理单元。该处理单元包括:
乘法器模块,所述乘法器模块包含构成流水线的多级结构,并用于执行神经网络中待计算的神经元和权值的乘法运算,其中,所述乘法器模块的每一级结构完成所述神经元和权值的乘法运算的子运算;
自累加器模块,所述自累加器模块基于控制信号对所述乘法器模块的乘法运算结果进行累加运算或将累加结果输出。
在一个实施例中,所述乘法器模块包括:输入级,由数据选通器构成,用于接收所述神经元和权值;多个中间级,排列为二叉树结构,由寄存器和加法器构成,每个中间级用于执行权值和神经元的乘法的子运算并传递中间结果;乘法输出级,用于输出所述神经元和权值的相乘结果。
在一个实施例中,所述自累加器模块包括累加器和第一数据选通器,所述累加器的第一输入端接收所述乘法器模块的输出,所述累加器的输出端通过由所述控制信号控制的所述第一数据选通器与所述累加器的第二输入端连接。
根据本发明的第二方面,提供了一种神经网络处理系统。该处理系统包括:处理单元阵列,由多个根据本发明的处理单元构成,用于获得卷积层的输出神经元;池化单元,用于对所述卷积层的输出神经元进行池化处理;控制单元,用于控制神经网络处理系统中数据的传递。
在一个实施例中,所述处理单元阵列组织为二维矩阵形式。
在一个实施例中,所述控制单元基于卷积参数和所述处理单元阵列的规模确定神经元和权值的分批策略。
在一个实施例中,所述控制单元根据所述分批策略确定每个周期向所述处理单元阵列输入的神经元和权值。
在一个实施例中,当同一批次的神经元和相应权值的计算任务未完成时,所述控制单元向所述处理单元阵列输入第一控制信号以控制自累加器模块执行累加操作,当同一批次的神经元和相应权值的计算任务完成时,所述控制单元向所述处理单元阵列输入第二控制信号以控制自累加器模块输出累加结果。
在一个实施例中,本发明的神经网络处理系统还包括神经元缓存单元,用于存储所述卷积层的输出神经元。
在一个实施例中,所述控制单元分析所述卷积层的输出神经元,在所述卷积层的输出神经元不属于同一池化域的情况下,将其存储到所述神经元缓存单元,在所述卷积层的输出神经元属于同一池化域的情况下,将其直接传递到所述池化单元。
与现有技术相比,本发明的优点在于:对神经网络中的乘法计算过程采用流水线处理,并将乘法计算的结果进行自累加,实现了神经网络处理系统对数据处理速度以及吞吐量的提升;通过神经元和权值进行分批次处理以及控制每周期处理的数据数量,实现了计算资源的充分利用;通过适当的缓存计算结果,实现了神经网络权值和神经元的输入输出数据的快速转换。
附图说明
以下附图仅对本发明作示意性的说明和解释,并不用于限定本发明的范围,其中:
图1示出了根据本发明一个实施例的神经网络处理系统的示意图;
图2示出了根据本发明一个实施例的处理单元的示意图;
图3示出了图1的神经网络处理系统的数据处理流程图;
图4示出了根据本发明一个实施例的对神经元和权值进行分割的示意图;
图5示出了根据本发明另一个实施例的神经网络处理系统的示意图。
具体实施方式
为了使本发明的目的、技术方案、设计方法及优点更加清楚明了,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
典型地,深度神经网络是具有多层神经网络的拓扑结构,并且每层神经网络具有多个特征图层。例如,对于卷积神经网络,其处理数据的过程由卷积层、池化层、归一化层、非线性层和全连接层等多层结构组成,其中,卷积层的操作过程是:将一个k*k大小的二维权重卷积核对输入特征图进行扫描,在扫描过程中权重与特征图内对应的神经元求内积,并将所有内积值求和,得到卷积层的输出特征图或称输出神经元,然后,通过非线性激活函数(如relu)进一步把该输出特征图传递到下一层(例如,池化层),当每个卷积层具有n个输入特征图时,会有n个k*k大小的卷积核与该卷积层内的特征图进行卷积操作。池化层又称下采样层,其具体过程是:将一个p*p大小的二维窗口(即池化域)对特征图(例如,由卷积层输出给池化层的特征图)进行扫描,在扫描过程中计算窗口在图层对应神经元的最大值或平均值,得到池化层的输出神经元,池化层一方面可以消除部分噪声信息,有利于特征提取,另外一方面也可以减少下一层特征神经元的数量,从而减小网络规模。
为了改进神经网络中卷积计算和池化处理的过程,图1示出了根据本发明一个实施例的神经网络处理系统,其能够应用于训练好的神经网络,获得待测的目标神经元的输出。
参见图1所示,该处理系统101包括输入数据存储单元102、控制单元103、输出数据存储单元104、权重存储单元105、输入数据缓存单元106、权重缓存单元107、神经元缓存单元108、输出缓存单元109、处理单元阵列110(示出为多个)、池化单元111(示出为多个)。
输入数据存储单元102与输入数据缓存单元106相连,用于存储参与计算的数据,该数据包括原始特征图和参与中间层计算的输入特征图。
权重存储单元105与权重缓存单元107相连,用于存储已经训练好的权重数据。
处理单元阵列110接收输入数据缓存单元106与权重缓存单元的数据,完成卷积运算任务。
神经元缓存单元108用于暂存卷积层计算出来的中间结果以及激活处理后的神经元。
池化单元111与神经元缓存单元108相连,用于池化卷积层计算出的特征图,并将结果输出至输出缓存单元109。
输出缓存单元109与池化单元111相连,用于存储池化后的神经元。
输出数据存储单元104与池化缓存单元109相连,用于存储池化后的批量输出结果。
控制单元103分别与输出数据存储单元104、权重存储单元105、处理单元阵列110、神经元缓存单元108、池化单元111、输出数据存储单元104相连,控制单元103获得神经网络待计算的目标层相关参数并控制各单元进行神经网络的数据传输与计算。
为更详细地阐述本发明的神经网络处理系统,下面结合图1具体说明处理单元阵列110和其计算过程。
处理单元阵列110是由多个处理单元构成,每个处理单元能够实现乘法操作并对乘法结果进行累加,图2是一个处理单元的结构示意,能够对2输入的8位数据进行乘累加。
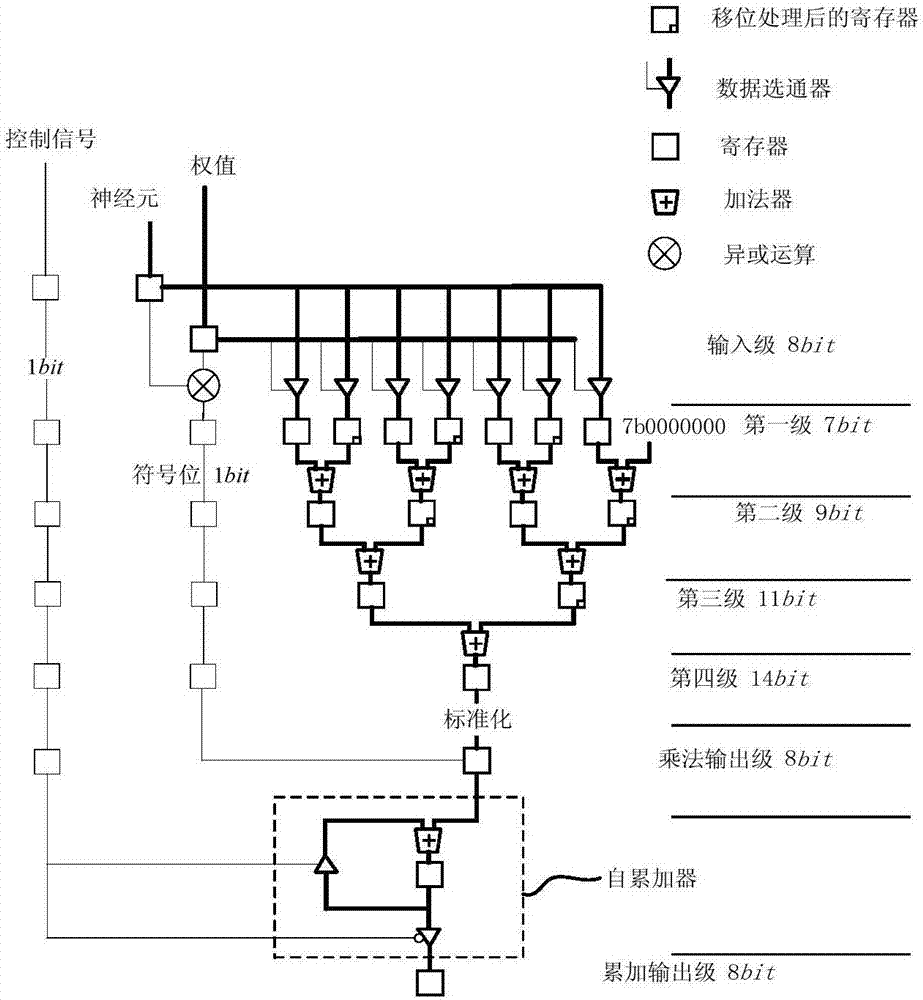
参见图2所示,该处理单元包括输入级,由数据选通器构成,用于接收待运算的神经元和权值;执行乘法运算的第一级至第四级,排列为二叉树结构,形成乘法计算的流水线,每一级用于执行权值和神经元的乘法的子运算并传递中间结果,其中,第一级至第三级由寄存器和加法器构成,第四级由寄存器构成;乘法输出级,用于获得神经元和权值的最终相乘结果并将结果输出给自累加器;自累加器基于控制信号决定对乘法结果进行自累加或将累加结果通过数据选通器输出给累加输出级,其中,自累加器的一个输入端连接乘法输出级的寄存器,自累加器的输出端通过由控制信号控制的数据选通器与自累加器的第二输入端连接。
在图2处理单元的计算过程中,神经元和权值分为符号位和数值位,其中,最高位的符号位在进行异或运算之后通过专用的寄存器层层传递到乘法输出级,其余的数值位通过排列为二叉树形式的第一级至第四级完成乘法操作;控制信号基于专用寄存器层层传递到自累加器。
具体地,处理单元的乘法操作和自累加过程包括:
步骤s210,根据待计算的权值和神经元数据对各第一级寄存器赋值。
以8位定点数相乘的算式01011111*00001010为例,假设被乘数为神经元值,乘数为权值,其中,最高为符号位,其余的7位是数值位。第一级的寄存器赋值原则是将权值数值位是1的第一级寄存器赋值为神经元的原码,将权值数值位是0的第一级寄存器赋值为0。例如,在第一级寄存器中,权值00001010从低位排列的第2、4位为1,因此,在第一级寄存器值中,只有从低位排列(从右至左)的第2和第4个寄存器赋值为神经元原码01011111。
步骤s220,处理单元的第一级至第四级执行相应的子运算。
具体地,第一级的各加法器将对应的相邻两个寄存器中的数据进行累加,依据同位相加原则对各运算进行补位操作,由于相邻的寄存器位数在运算中相差一位,因此,对于两个相邻寄存器中的高位寄存器,需在其存储的数据的低位补一位0之后,才可与相邻的低位寄存器进行相加运算,第一级各加法器的运算结果传输至与其相连的第二级寄存器。
类似地,第二级至第三级的加法器执行本级寄存器的累加操作并将结果传递到下一级的寄存器。应理解的是,第二级的相邻寄存器运算相差两位,故对于高位寄存器,需在低位补两位0后与相邻的低位寄存器相加。
第四级的寄存器接收第三级的累加结果,在进行标准化后传递至输出级。
应理解的是,第一级寄存器用于接收除符号位之外的7位数据,因此,第一级寄存器可以为7bit,而为了防止第一级寄存器的数据在相加之后溢出,将第二级的寄存器设置为9bit,同理,第三级为11bit的寄存器,第四级为14bit的寄存器。此外,处理单元的中间级(即此实施例中的第一级至第四级,共四级)的数量与参与计算的数据位宽相关,例如,对于16bit的位宽,需包括5个中间级,而如果是32bit的位宽,则需要包括6个中间级。
在此实施例中,对于处理单元的流水线结构中每一级,在将计算结果传递给下一级之后,即可开始接收上一级的输出结果,因此,各级计算资源不需要等待状态,从而提高了计算效率和资源利用率。
步骤s230,获得神经元和权值的最终相乘结果。
在输出级,接收来自于第四级的标准化后的结果并与1bit的符号位(即
步骤s240,自累加器对乘法结果进行累加。
处理单元的自累加器每周期接收流水线乘法部分的输出结果和控制信号,根据控制信号对累加操作进行控制,例如,当控制信号为0时,将来自于乘法输出级的乘法结果与自累加器的输出寄存器值进行累加,并将结果暂存于自累加器输出寄存器;当控制信号为1时,自累加器的输出寄存器将当前的乘累加结果输出给累加输出级。
通过以上描述可知,一个处理单元能够对接收的神经元和权值进行乘法操作,并基于控制信号对多次的乘法结果进行累加,适用于卷积操作。
进一步地,为了能够并行处理多个神经元和权值的乘累加操作,可将多个处理单元组织为阵列形式,例如,将256个处理单元组织为16*16的二维处理单元阵列,其中,列数可指示同时接收的神经元数目,行数可指示同时接收的权值数目。
应理解的是,尽管图2未示出,上述处理单元阵列根据需要还可包括其它模块,以对乘累加结果进行进一步处理,例如,包括缓存单元,以暂存乘累加的中间结果,又如,包括其它的累加模块,以对多次的乘累加结果进一步累加。
将处理单元阵列应用于神经网络系统,能够实现对神经元和权值的卷积过程,此外,基于处理单元阵列的规模进行控制神经元和权值的加载顺序和数量,能够充分利用处理单元的流水线结构以及计算资源,从而加快数据处理速度。
图3示出了基于本发明的处理单元阵列的神经网络处理过程示意图。仍结合图1,处理过程包括以下步骤:
步骤s310,基于处理单元阵列的规模对神经元和权值进行批次划分。
图4示出了对参与计算的神经元和权值进行批次划分的示意图。在该示例中,卷积核为3x3、卷积移动步长为2、48个输入特征图、96个输出特征图,处理单元阵列110的规模是16*16。
参见图4所示,当以3x3的卷积核对48个输入特征图进行扫描时,以3x3x48卷积域的神经元作为一个神经元批次,即每个神经元批次包括3x3x48的神经元,由于处理单元阵列110的列可用于接收神经元,因此,对于16列的处理阵列,每批次神经元可分为27个(即3x3x48/16)神经元组,每一个神经元组包括16个神经元。由于每批次神经元将对应所有96个输出特征图权值,对于16*16规模的处理阵列,每次需满足16个特征图的计算规模,因此,需要16组权值,也就是说,对于96个输出特征图,可将权值分为6个批次,每个权值批次包括16个权值。
在图4的实施例中,以权值和神经元原位宽是8比特定点数为例进行阐述,为了后续流水线处理单元阵列可持续输入权值或神经元,以减少等待时间,将输入神经元拼接为至少128比特的宽度,将权值拼接为至少宽度为2048bit的宽度。在另一个实施例中,权值与神经元的原位宽也可以是32比特,16比特等。
步骤s320,获得同一批次神经元和相应权值的乘累加结果。
在每个周期,向处理单元阵列110加载一个神经元组以及相应的一个权值组,并对其进行流水线式的乘法操作,并将同一个神经元批次的每组神经元和相应权值的乘法结果通过图2所示的自累加器连续累加,当一个神经元批次的数据处理完毕时,输出自累加结果。在此过程中,输入到处理阵列单元阵列110的控制信号可根据当前处理的批次序号进行更新,例如,当开始处理一个神经元批次的数据时,将控制信号设置为0,以控制进行自累加,当每个批次的计算任务计算完成时,将控制信号设置为1,以输出该神经元批次的自累加结果。
在此步骤s320,通过更新输入到处理单元阵列的神经元批次,可以获得所有神经元批次的乘累加结果。已完成神经元批次的计算结果可保存在神经元缓存单元108中。
步骤s330,获得同一卷积域的计算结果
将各神经元批次属于相同卷积域的乘累加结果继续累加,以获得一个卷积域的计算结果。通过更新输入到处理单元阵列110的权值批次,可以获得每个卷积域的计算结果。
步骤s340,对每个卷积域的计算结果进行激活处理,以获得卷积层的输出神经元。
在此步骤s340,对每个卷积域的计算结果进行激活处理,以获得整个卷积层的输出神经元。
步骤s350,对卷积层的输出神经元进行池化处理。
对属于同一池化域的卷积层输出神经元进行池化处理,以获得池化结果。
在一个实施例中,池化单元111加载卷积层直接输出的或来自于神经元缓存单元108的属于同一池化域的神经元,对其进行池化处理,以获得池化结果,例如,以最大值或平均值为池化规则。当控制单元103根据卷积层的实时输出的神经元分布或神经元缓存单元中的神经元分布调用足够数量的池化计算资源时,即当池化单元111每周期均能获取一组相同池化域的神经元时,多个池化单元111可持续流水线式的工作,每周期均能输出池化结果。
在一个实施例中,控制单元103控制将池化结果输出至输出缓存单元109,当输出缓存单元109中的神经元满足神经网络的下一层卷积核参数分布时(例如,已得到下一层的相关运算所需要的神经元),将相应卷积域的神经元批量存储至输出数据存储单元104,以供下一层调用。
在上述数据处理过程中,控制单元103的功能包括但不限于:基于处理单元阵列110的规模和卷积参数对神经元和权值进行分批,并根据当前处理的批次向处理单元阵列110加载相应的神经元、权值和控制信号;控制计算结果到缓存中的加载以及在各处理单元之间的传递。
进一步地,图5以8位数据为例示意了本发明的神经网络处理系统的工作过程。
如图5所示,该处理系统包括输入数据存储单元、输入神经元缓存单元、权重存储单元、输出神经元存储单元、神经元缓存单元、激活单元、池化单元、输出缓存单元和控制单元(未示出)、权重缓存单元(未示出)、处理单元阵列为16x16,每周期可处理256对不同神经元和权值的乘法,其结果将累加至其自带的内置列累加单元。具体包括以下步骤:
步骤s510,将已训练权值和待测的目标神经元分别存储在权重存储单元和输入数据存储单元。
步骤s520,控制单元依据卷积参数和处理单元阵列规模将神经元和权重进行分批处理。
例如,控制单元获取神经网络当前层的卷积参数,假设卷积核为3x3、输入特征图为48个、输出特征图为96,卷积移动步长为2。控制单元依据处理单元阵列的规模对输入特征图进行分割处理。
步骤s530,将处理后的神经元与对应权值分批存储至输入神经元缓存单元与权重缓存单元。
步骤s540,控制单元依据卷积参数向处理单元阵列加载神经元和权值。
控制单元依据卷积参数调用对应批次数据至处理单元阵列,每周期均从神经元缓存单元和权重缓存单元分别加载数据至处理单元阵列的输入端。同时,控制单元根据处理的批次顺序向处理单元阵列输入控制信号。
步骤s550,处理单元阵列对各输入数据进行流水线式处理,并将累加结果(即卷积结果)输出至神经元缓存单元。
步骤s560,对卷积结果进行激活处理,并将激活结果传递给池化单元。
步骤s570,池化单元对已激活处理的神经元进行池化处理,并将结果输出至输出缓存单元。
步骤s580,控制单元依据输出缓存单元中的数据分布将池化结果分批输出,已备神经网络下一层使用。
需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺序,只要能够实现所需要的功能即可。
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
- 还没有人留言评论。精彩留言会获得点赞!