一种软件问答社区中的技术标签推荐方法与流程
本发明涉及一种系统推荐方法,尤其涉及一种软件问答社区中的技术标签推荐方法。
背景技术:
软件问答社区是指专注于解决技术性问题以及软件开发的问答社区,例如全球影响力较大的stackoverflow社区。因其庞大的用户与资源量(超过五百万的用户数,千万级的问题、回答数),使得软件资源管理变得复杂。为了缓解这一问题,stackoverflow要求用户在提出问题时给出1~5个tag,即技术性标签。而由于部分提问者对自己提出的技术问题缺乏足够的理解以及设置标签本身存在极大的自由度,使得这种tag系统变得臃肿,违背了其初衷。因此,研究人员研究了自动化的标签(tag)推荐方法,即用户在给出问题描述后,能够自动的把合适的标签推荐给用户的方法。
现有技术中,面向软件问答社区的代表性标签推荐技术包括基于贝叶斯学习、labeled-lda以及信息检索的方法,分别称为tagcombine、entagrec以及tagmulrec。其中,tagcombine是研究人员首次提出的应用在互联网软件信息社区中的tag推荐技术。该技术主要考虑了问题中的文本信息,包含三个不同组件:多标签排序、基于相似度计算以及基于标签-术语(tag-term)的排序组件。多标签排序是利用多项式朴素贝叶斯分类器来对问题进行分类的组件;基于相似度计算的组件是通过tf-idf方法搜索相似的问题并推荐这些问题的标签;基于标签-术语的排序组件则是根据历史标记计算出问题中的术语与标签的亲和度,以此进行标签的排序,将这三个组件加权求和得到最终的推荐结果。entagrec方法包括两部分,分别是基于labeledlda的贝叶斯推断组件以及基于频率的推断组件。前者使用labeledlda的方法对问题进行多分类处理,后者则首先借助于stanfordnlp工具对问题描述进行词性标注以去除无关词语,然后使用激活扩散算法(spreadingactivationalgorithm)寻找相关的tag。相对于tagcombine,该方法在准确性方面有着大幅度的提升。tagmulrec专注于解决大规模的标签推荐问题,借助于lucene,该项技术首先构造问题描述中的词语-文档的索引,然后通过计算相似度的方法搜索出相似的问题,将这些问题的标签作为候选集合。对于该集合,tagmulrec提出了一种简单的标签排序算法来推荐合适的标签。
tagcombine技术由于在多标签排序时需要构建多个“一对多”的贝叶斯分类器,所以耗费大量时间。此外,其准确性相对于另外两项技术较低。entagrec技术受限于数据集的大小。原因在于其使用的labeledlda以及基于频率的推断方法复杂度高,训练所需要的时间随着数据集的大小急剧增加,因此不适用于百万级甚至几十万级的数据量的训练,这极大地限制了其应用范围,尤其是stackoverflow这种拥有海量软件问答资源的社区。tagmulrec技术的准确性不如entagrec,并且在推荐标签时需要实时搜索相似问题。在百万级的数据集上,即使依靠索引机制,其推荐所需要的时间也较长。
总体来说,现有技术进行标签推荐时考虑了文本的统计信息,如词频等等,忽略了问题本身包含的语义信息,从而导致推荐的准确性低,耗费时间长。
技术实现要素:
本发明首基于深度学习提出面向软件问答社区的标签推荐方法。该项方法包括:步骤1,预处理;步骤2,词义表示学习;步骤3,短语以及句子语义学习;步骤4,语义融合;在预处理前为训练阶段,所述训练阶段用于构造词典并保存模型的结构与权重;在预处理后为部署阶段,所述部署阶段则是对于新的问题,在转化成索引序列后,加载保存的模型以预测并推荐最有可能的k个标签,k为正整数。本发明可以提供软件问答社区中的问题资源管理、维护已有的标签系统的功能,并且为用户提供自动化的标签标注服务。针对现有的标签推荐技术存在的缺陷,本发明可以提高技术标签推荐的准确性以及效率,使得标签推荐在软件问答社区中能够更加实用。
附图说明
图1为本发明的整体流程图;
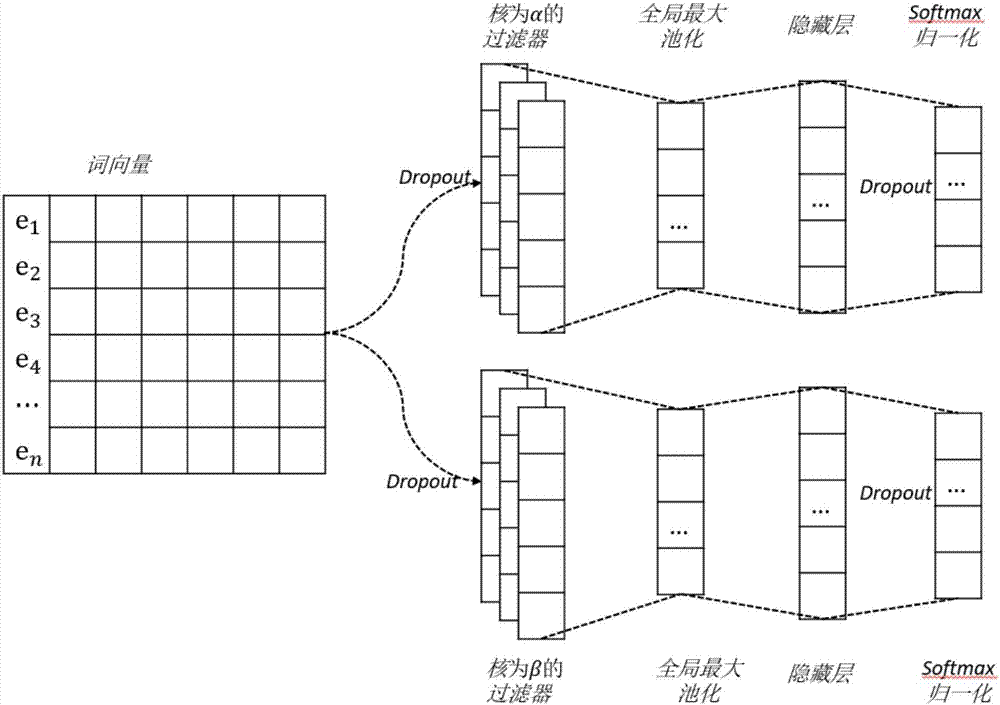
图2为本发明中学习短语和句子语义的模型图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本方法的整体流程具体流程如图1所示,包括:步骤1,预处理;步骤2,词义表示学习;步骤3,短语以及句子语义学习;步骤4,语义融合。其中,训练阶段用于构造词典并保存模型的结构与权重;部署阶段则是对于新的问题,在转化成索引序列后,加载保存的模型以预测并推荐最有可能的k个标签,k为正整数。
在训练阶段,首先从源数据中抽取出训练样本,即问题与tag集合形成的元组。然后将其中的问题文本进行预处理,并且把单词对应的序列索引值记录保存下来,转化成整数索引序列。将这些序列作为word2vec的输入以训练词向量,并将这些预训练的词向量加载到模型的词向量模块中。同时,经过预处理后的问题与tag作为模型参数训练的样本,也就是作为图中核心模块的输入。在训练结束后,保存该模型。
在部署阶段,对于未知tag的新问题,借助于保存的单词词典,形成对应的索引序列,然后加载训练好的核心模型,进行tag的预测,得到对应的概率。最后将这些tag按概率排序,取前k大的tag作为推荐结果。
在预处理中,首先在从stackoverflow获取源数据后,将其中的问题与标签数据提取出来,形成供训练的问题标签对。对于每个问题,去除其中的标点符号与html标签,并对诸如.net等含有标点的技术关键词作转换处理,如转换成“dotnet”。然后对于问题中的代码数据,利用正则表达式过滤掉长度大于三个词的代码片段。接下来,经过预处理的问题信息用于构造词语-索引对应的词典,以将原始数据转化成固定长度的序列,即词的索引的序列,如[2,6,8…]。此长度由问题的平均长度决定,本方法取固定值200,约为平均长度的两倍。即限定每个问题的长度为200词,若不足200,则以0填充。
在语义表示学习中,为了以向量的形式表示每个词的含义,本方法利用词嵌入(wordembedding)技术来训练从stackoverflow获取的海量软件开发问题的文本数据,以此充分学习出词语的精确语义表示。词嵌入的直观解释为:两个可相互替换的词有相似的向量表示。比如,在讨论java相关问题时,其中的“class”和“object”均适用于句子“thismethodinthe__extendsitsparentinjava”,因此他们的向量表示非常相近。本发明使用skip-gram模型来训练词向量。该模型本质上是一个三层的神经网络,即输入层、隐藏层和输出层。首先,对于独热(one-hot)表示的输入xk,有相邻的词语y1,y2,…,ym,m为正整数,隐藏层与输入层之间的权重矩阵为w,则xk的向量表示为ek=wkxk。θ为中间的参数。在训练时,使用最大似然准则,即最大化下式:
其中的n为总的词数,条件概率使用softmax函数来计算,如下:
这里d表示训练样本的词汇表。此外,考虑到训练的语料数量过大,本发明借助负采样(negativesampling)方法来加速训练过程。本方法用工具gensim的word2vec来训练词向量,训练的语料库为stackoverflow中的大量已有问题。
在训练结束后,便可以得到每个词的向量表示,用于进一步地语义提取。
在步骤2中,本发明构建了单个模型来同时学习短语和句子语义,其模型结构图如图2所示。从词向量到句义学习,首先需要将句子转化成语义矩阵。这里的做法是,对于句子中的每个词,抽取对应的词向量,并将这些向量进行拼接,形成类似于图像处理中的“图片”格式,用公式表述成如下形式:
其中q1:k表示用前k个词组成该矩阵,k为正整数。为了从该矩阵中提取出短语的语义特征,本模型使用卷积神经网络(convolutionalneuralnetwork,cnn)作为模型在接收到输入后的第一步特征提取。在这之前,添加dropout以防止过拟合。从图中可以看出,短语的语义学习使用了kernelα作为短语级别的语义特征提取部件f,该部件将上文的文档矩阵转化成特征映射(featuremap)c。具体的计算方式如下:ci=σ(f·qi:i+s-1+b)
其中i和s表示短语起始位置以及短语长度,qi:i+s-1是ei到ei+s-1的合并,b是偏置,σ是激活函数relu。接下来,对于多个特征提取部件提取到的特征映射c=[c1,c2,…,ci+s-1],添加池化来提取这些特征语义空间中的最具代表性的向量,即每一维度的最大值,有公式
这里wt是该层与输出层之间的权重。最终的输出层用于计算每个标签的概率,取值为0~1,为如下公式中的f:
在训练时,使用公式
其中y是问题对应的真实的标签集合,取值为0或1。本发明利用优化器来最小化ε,从而训练出最优模型。该模型借助于深度学习实现,在三个大小不同的数据集(小、中、大)上的参数见下表。
其中,d表示词向量的维数,f表示模型中过滤器的数目,k表示卷积核的大小,λ表示模型中dropout的概率,ζ表示隐藏层的单元数,ι表示问题长度的阈值,ψ表示融合后继续训练的周期次数,δ表示训练时的批大小,τ表示词向量是否可被再训练。
句子语义学习与短语语义学习类似,所不同的是在模型中采用了不同的内核,即采样更长的序列以提取出句子所表达的含义。
在步骤3语义融合中,将上述模型的两个不同的输出分别看作是短语与句子对应于标签的语义表示向量,本发明提出了一种融合方法来对其进行融合,以更好地决策推荐标签。该方法利用学习的方式训练出对应于两种语义的权重,以此进行累加。
首先获取训练损失y:
之后在遍历训练数据时可以逐步更新这两个权重。
以上学习出的权重最终用于预测新问题所对应的标签集合。即经过模型得到出的两个语义向量αn和βn,最终输出为γ=w*αn+v*βn。对γ进行按概率值排序,推荐出概率最大的k个标签,k为正整数。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!