一种快速低资源开销的改进LZO压缩方法与流程
本发明涉及比特文件压缩技术领域,特别是一种快速低资源开销的改进lzo压缩方法。
背景技术:
lzo算法基于传统字典压缩算法,使用哈希表来记录滑动窗口内的字典数据,减少了搜索相同字符的时间,极大地提高了算法的压缩速度,其通过把压缩格式精细化到按每比特使用,可以使每个字节利用更充分,增大数据的压缩比。2004年,美国太空总署将lzo无损压缩应用在了探测火星的机会号和精神号上。
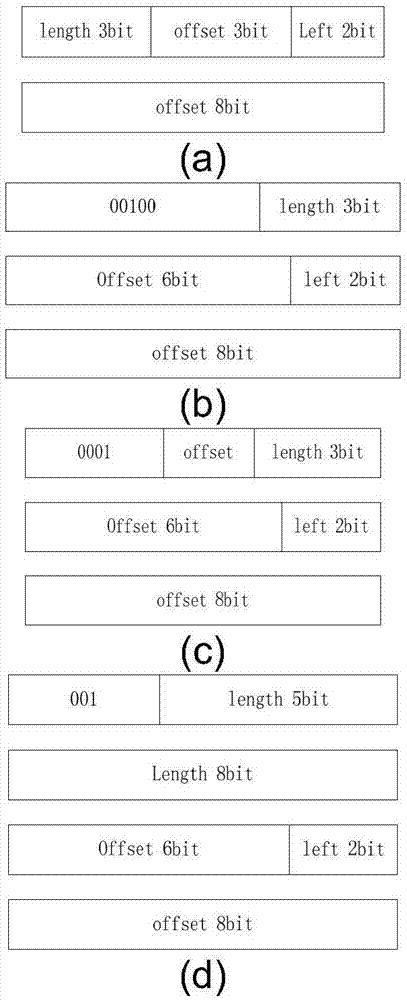
如图1所示为现有的lzo压缩算法流程图,其首先对输入数据做哈希运算,判断输入数据是否在哈希表内,如果输入数据不在哈希表内,则扩充哈希表,否则对输入数据按lzo压缩格式进行压缩。现有的lzo压缩算法压缩格式根据偏移距离和重复长度的不同共分为5种,如图2(a)、(b)、(c)、(d)、(e)所示为现有的lzo压缩算法5种lzo压缩格式。
如图2(a)、(b)、(c)所示三种压缩格式的重复长度小于等于8字节,格式1回指距离的范围小于等于2k,格式2回指距离小于等于16k,格式3回指距离大于16k,小于等于48k。格式4格式5是重复长度大于8字节的情况,格式4回指距离小于等于16k,格式5回指距离大于16k小于等于48k。
如图2所示的5种压缩格式最大可支持48k的回指距离,因此至少要存储48k的解压数据才能保证压缩数据被正确解压,过大的ram深度使解压缩的速率变慢,ram本身在解压缩时刷新频率降低,在空间辐射环境中,更易发生单粒子翻转。上述5种格式通过回指距离和重复长度共同判定使得判定过程繁琐,降低压缩速度;解压缩电路要区分5种压缩格式,需要大量的控制信号来保证解压缩正确性,使得解压缩过程复杂,增加了时序开销和硬件资源开销。
技术实现要素:
本发明解决的技术问题是:克服现有技术的不足,提供了一种快速低资源开销的改进lzo压缩方法,通过对现有的lzo压缩算法研究,在保留lzo压缩算法哈希运算的同时,通过统计分析比特文件的数据特点和lzo的五种压缩格式,设计了一种快速低资源开销的无损压缩方法,通过重新设计压缩格式,在几乎不影响压缩率前提下,压缩与解压缩速度较大提升、硬件资源开销大幅降低。
本发明的技术解决方案是:一种快速低资源开销的改进lzo压缩方法,包括如下步骤:
(1)根据回指距离构建lzo压缩方法对新字符进行压缩的第一压缩格式及对应的第一压缩算法、第二压缩格式及对应的第二压缩算法;所述的第一压缩格式适用且进行压缩的新字符的回指距离小于第二压缩格式适用且进行压缩的新字符的回指距离;
(2)记录进行lzo压缩的新字符长度,根据新字符长度、回指距离选择的压缩格式及对应的压缩算法进行lzo压缩。
所述的第一压缩格式适用且进行压缩的新字符的回指距离不大于1k,第二压缩格式适用且进行压缩的新字符的回指距离大于1k小于等于16k。
所述的第一压缩格式的第一字节t0为8bit,最高位为1,t0的6、5、4bit记录3≤重复长度≤8的值,3、2bit记录回指距离的低2位,1、0bit记录下次输入为新字符且新字符长度≤3时新字符长度的值,最后一字节u记录回指距离后8位。
所述的第一压缩格式对应的第一压缩算法包括如下步骤:
步骤1、判断待压缩数据的回指距离,如果待压缩数据的回指距离≤1k且重复长度m_len≥3,转入步骤2,如果待压缩数据的重复长度<3,则不进行压缩;
步骤2、当3≤重复长度m_len≤8时,将m_len-1的值记录在t(0)的6、5、4bit中;
当8<m_len≤263时,将t0的6、5、4bit分别记为0,然后将m_len-8的值记录在第二字节t(1)中;
当263<m_len≤n*255+263时,n≥1,将t(0的6、5、4bit分别记为0,将第2字节t(1)至第(n+1)字节t(n的8bit分别记为0,将m_len-8-n*255的值记录在第(n+2)字节t(n+1)中;
步骤3、如果下次输入数据为新字符且新字符长度≤3,则将新字符长度的值记录于t0的第1、0bit,如果新字符长度>3时,则将t(0的最后两bit记为0。
所述的第二压缩格式第一字节t(0的高两位分别置为0、1,t0的5、4、3、2、1、0bit记录4≤重复长度≤65的值,倒数第二字节u的7、6、5、4、3、2bit分别记录回指距离的低6位,u的1、0bit记录下次输入数据为新字符且新字符长度≤3时新字符长度的值,最后一字节v记录回指距离的后8位。
所述的第二压缩格式对应的第一压缩算法包括如下步骤:
步骤1、判断待压缩数据的回指距离,当1k<待压缩数据的回指距离≤16k且重复长度m_len≥4时,转入步骤2,当重复长度m_len<4时,不对数据进行压缩;
步骤2、当4≤m_len≤65时,将m_len-2的值记录在t(0)的5、4、3、2、1、0bit中;
当65<m_len≤320时,将t(0)的5、4、3、2、1、0bit分别置为0,将m_len-65的值记录在第二字节t(1)中;
当320<m_len≤n*255+320,t(0)的5、4、3、2、1bit位的值分别为0,将第2字节t(1)至第n+1字节t(n)的8bit分别记为0,将m_len-65-n*255的值记录于第n+2字节t(n+1)中。
步骤3、如果下次输入数据为新字符且新字符长度≤3,则将新字符长度的值记录于u的第1、0bit,如果新字符长度>3时,则将u的最后两bit记为0。
本发明与现有技术相比的优点在于:
(1)本发明以lzo算法为基础,对比特文件进行统计分析,基于统计结果对lzo算法进行改进,在保留哈希运算的前提下提出一套新的压缩格式,该压缩格式种类划分少,判断方式简单,在几乎不降低压缩率的前提下减小回指距离,压缩与解压缩速度均有较大提高;
(2)本发明通过减少压缩格式种类和回指距离,使得解压缩电路硬件开销(除io)仅为lzo算法的35%,sram刷新频率为传统lzo算法的3倍,工作时钟频率提高,解压缩译码时钟周期减少,更便于硬件实现和宇航应用,具有很好的使用价值。
附图说明
图1为现有的lzo压缩算法流程图;
图2为现有的lzo压缩算法对应的5种lzo压缩格式;
图3为本发明方法设计的压缩格式1;
图4为压缩格式1的运算流程;
图5为压缩格式格式2;
图6为压缩格式2的运算流程;
图7为本发明算法的新字符编码格式;
图8为新字符编码格式的运算流程;
图9为本发明方法对应的压缩算法设计流程图;
图10为本发明方法对应的解压缩算法设计流程图;
图11为解压缩电路框图;
图12为本发明快速低资源开销的比特文件无损压缩方法流程图。
具体实施方式
为了提升lzo压缩算法的压缩与解压缩速度,减少解压缩电路的硬件开销,提高电路抗单粒子翻转能力,本发明针对现有技术的不足,提出一种快速低资源开销的改进lzo压缩方法,本发明方法沿用传统lzo算法的哈希运算,并对压缩格式进行了改进,改进后的压缩算法压缩格式包括2种,只由回指距离判定区分;最大回指距离减小为16k,通过上述改进本发明解压缩电路硬件开销(除io)仅为传统lzo算法的35%,ram刷新频率为传统lzo算法的3倍,压缩速度提升18%,解压缩速度提升37%,压缩率减小0.3%以内。
如图12所示为本发明一种快速低资源开销的改进lzo压缩方法的设计流程包括如下步骤:
(1)研究无损压缩技术,选择合适的压缩算法作为基础。了解目前的无损压缩算法的种类以及它们的优缺点。字典编码算法从理论上克服了其他算法可能使压缩率反弹的问题,带来较高的压缩率,本发明以字典编码算法为基础进行研究。
(2)研究lzo压缩算法,分析其优缺点。传统的字典编码由于要与字典内的字符挨个比对,使得字典编码的压缩速度非常缓慢。lzo算法基于传统字典压缩算法,并使用哈希表来记录滑动窗口内的字典数据,使其搜索的复杂度一直为常数,在压缩速度上有很大提升。但lzo算法有5种不同的压缩格式,且最大回指距离为48k,这些都限制了lzo算法压缩与解压缩的速度,在解压缩电路实现时带来了较大的硬件开销,不利于宇航应用。
(3)选取大量实际工作中的比特文件作为样本,统计比特文件中数据的回指距离的规律。
(4)对lzo五种压缩格式和比特文件统计结果的分析,精细化的设计压缩格式,在提高算法速度以及理论上降低资源消耗的同时保证压缩率。
(5)设计本发明算法的压缩软件,验证算法的压缩率和压缩速度。
(6)设计本发明算法的解压缩软件,结合压缩软件验证算法的正确性以及解压缩速度。
(7)设计算法的硬件电路和fpga实现,验证解压缩算法的硬件实现和资源利用率。
本发明方法的具体设计方法包括如下步骤:
(1)分析lzo算法的5种压缩格式以及比特文件数据特点,设计压缩格式优化方案;
格式2和格式4,格式3和格式5的首字符格式编码方式相同,所不同的是在判断重复长度上。因此,本发明方法合并压缩格式2与格式4,格式3与格式5,从而使的压缩与解压缩更加方便,减小解压缩硬件开销与提高压缩和解压缩速度。统计回指距离,超过50%的比特文件的回指距离小于1k,而这种小于1k回指距离根据重复长度的不同可以按格式1、格式4进行压缩,第一种压缩格式的压缩结果为2字节,而第4种压缩格式压缩结果最少3字节。因此尽量多的数据按第一种压缩格式进行压缩对提高压缩率是非常有效的。
最大48k的回指距离,使得解压缩时至少需要48k深度的ram存储解压数据才能保证压缩数据被正确解压。为了提升压缩与解压缩速度,同时减少解压缩电路的硬件开销,提高电路抗单粒子翻转能力,本发明从减小压缩格式的回指距离入手。由于哈希表的深度为16k,在数据压缩时最多读入16k数据就会更新哈希表,同时超过95%的比特文件回指距离小于16k,因此本发明将回指距离也缩小为16k并不会带来过多的压缩率损耗,即可删除压缩格式3和5。
结合以上分析本发明方法得到一种简化的压缩格式编码,即压缩格式只由回指距离判定,压缩格式只有2种,回指距离小于等于16k。
(2)结合上述分析,设计快速低资源开销的压缩算法编码格式
如图3所示为本发明方法的两种压缩格式的第一种,即回指距离小于等于1k的情况,该压缩格式的第一字节t0的最高位(第7bit位)的值为1,解压缩时判定方法为首字符大于等于128;t0的6、5、4bit位用于记录3≤重复长度(m_len)≤8的值;t0的3、2bit位用于记录回指距离的低2位的值;t0的1、0bit位用于记录下一次输入的数据为新字符(n_len),且n_len≤3时n_len的值;最后一字节u用于记录回指距离后8位;t0与u之间的字节数≥0,由重复长度决定。详细压缩运算流程如图4所示。
如图4所示,t0为压缩格式第一字节,m_len为重复长度(压缩字符长度),u为压缩格式最后一字节式,n_len为下一次输入的新字节长度,n为t0与u之间0字节的个数。压缩格式1的回指距离为10位,其回指距离的范围小于等于1k,回指距离减1后记录于该压缩格式的offset中。重复长度不受限制,但m_len小于3时不对数据压缩,当m_len大于等于3,小于等于8时,m_len减1记录于第一个byte中的length的3bit中,该压缩格式的压缩结果为2byte;当m_len大于8时,第一个byte中的length的3bit全为0,第二个byte为m_len减去8;如果m_len减去8后还大于255,那么第二byte为全零,第三byte为m_len减8再减255……依次类推。第一字节的最后两bit用于存储新字符长度信息,当下一次输入的数据为新字符,且n_len小于等于3时,第一字节t0的最后两bit记录该长度,当n_len大于3时,t0的最后两bit为00。压缩格式判定方法为首字符大于128。
步骤1:回指距离(m_off)≤1k,且重复长度(m_len)≥3,该段重复字符按第一种压缩格式压缩;(m_len)<3不对该段字符压缩。
m_off-1的值的前2位记录于第一字节t0的3、2bit位中,后8位记录于该压缩格式的最后一字节u中。
步骤2:当3≤m_len≤8,(m_len-1)的值记录于t0的6、5、4bit位中;
当8<m_len≤263,t0的6、5、4bit位的值分别为0,将m_len-8的值记录于第二字节t1中;
当263<m_len≤n*255+263(n≥1),t0的6、5、4bit位的值分别为0,第二字节t1的8个bit位的值全为0……第(n+1)字节tn的8个bit位的值全为0,将m_len-8-n*255的值记录于第(n+2)字节t(n+1)中。
步骤3:下一次输入的数据为新字符(n_len),且n_len≤3时,n_len的值记录于t0的第1、0bit位中;当n_len>3时,t0的最后两bit为00。重复字符按第一种压缩格式压缩完成。
如图5所示为本发明算法的两种压缩格式的第二种,即回指距大于1k小于等于16k的情况,该压缩格式的第一字节(t0)的最高位和倒数第二位(第7bit位和第6bit位)的值为0和1,解压缩时判定方法为首字符大于等于64;t0的5、4、3、2、1、0bit位用于记录4≤重复长度(m_len)≤65的值;倒数第二字节u的7、6、5、4、3、2bit位用于记录回指距离的低6位的值;u的1、0bit位用于记录下一次输入的数据为新字符(n_len),且n_len≤3时n_len的值;最后一字节v用于记录回指距离后8位;t0与u之间的字节数≥0,由重复长度决定。详细压缩运算流程如图6所示。
如图6所示,t0为压缩格式第一字节,m_len为重复长度,u为压缩格式倒数第二字节,v为第二种压缩格式的最后一字节,n_len为下一次输入的新字节长度,n为t0与u之间0byte的个数。第2种压缩格式的回指距离为14位,其回指距离的范围小于等于16k,减1后记录于最后两个byte的offset中。重复长度不受限制,但m_len小于4时不对数据压缩,当m_len大于等于4,小于等于65时,重复长度减2记录于第一个byte中的length的6bit中;当m_len大于65时,第一个byte中的length的6bit全为零,第二个bit为m_len减去65;如果m_len减去65后还大于255,那么第二byte为全零,第三byte为m_len减65再减255……依次类推。当m_len小于65时,压缩字符为3byte。判定方法为首字符大于等于64。u的最后两bit用于存储新字符长度信息,当下一次输入的数据为新字符,且n_len小于等于3时,u的最后两bit记录该长度,当n_len大于3时,u的最后两bit为00。
步骤1:回指距离1k<(m_off)≤16k,且重复长度(m_len)≥4,该段重复字符按第二种压缩格式压缩;(m_len)<4不对该段字符压缩。
m_off-1的值的前6位记录于u的7、6、5、4、3、2bit位中,后8位记录于该压缩格式的最后一字节v中。
步骤2:当4≤m_len≤65,m_len-2的值记录于t0的5、4、3、2、1、0bit位中;
当65<m_len≤320,t0的5、4、3、2、1、0bit位的值分别为0,将m_len-65的值记录于第二字节(t1)中;
当320<m_len≤n*255+320(n≥1),t0的5、4、3、2、1bit位的值分别为0,t1的8个bit位的值全为0……第(n+1)字节tn的8个bit位的值全为0,将m_len-65-n*255的值记录于第(n+2)字节t(n+1)中。
步骤3:下一次输入的数据为新字符(n_len),且n_len≤3时,n_len的值记录于u的第1、0bit位中;当n_len>3时,u的最后两bit为00。重复字符按第二种压缩格式压缩完成。
如图7为本发明算法的新字符格式,首先记录新字符长度,新字符长度占用的字节数由新字符长度决定,完成新字符长度的记录后,依次记录输入的新字符。详细压缩运算流程如图8所示。
如图8所示,n_len为新字符长度。对于新字符串,本发明首先计算共有多少个新字符,当n_len小于4个的时候若回指距离大于1k会用的上面压缩格式2的倒数第二个字节的最后两个比特位记录,若回指距离小于等于1k,会用上面压缩格式1的第一字节的最后两个比特位记录。当n_len为4~66的时候,先把length减3,记录到第一个byte中;如果新字符长度大于66,记录0于第一byte,再记录新字符长度减去66的差值于第二个byte中;如减去66后仍然大于255,则在第一个0后再记录一个0,同时把差值再减去255得到新的差值,小于255,记录于第三byte中,大于255则记录一个0后继续减去255与255比较,直到最后的差值小于255时,记下最后的差值,记录完新字符的个数后,开始记录新字符。判定方法为首字符小于64。
步骤1:判断输入字符串的字符类型,是否为新字符,是新字符计算新字符长度(n_len)。
步骤2:根据n_len的大小,选择合适的格式,记录n_len值。
当n_len≤3时,记录n_len于前一次的压缩格式内;
当3<n_len≤66时,纪录(n_len-3)于新字符格式的第一字节n0中;
当66<n_len≤321,n0=00000000,第二字节n1=n_len-66;
当321<n_len≤321+n*255(n≥1),n0=00000000,n1=00000000……nn=00000000,n(n+1)=n_len-66-n*255。
步骤3:输出对应长度的新字符。
压缩后的比特文件是新字符与压缩字符交替出现,紧凑化判断条件,可提高比特文件压缩率。
(3)压缩和解压缩算法的整体设计,并验证算法的正确性、压缩率和速率:
本发明算法的压缩部分算法整体设计如图9所示:
步骤1:读入比特文件长度,用于判断数据是否结束。
步骤2:比特文件的前4byte不做任何处理,继续读入数据,记录索引于哈希表。
步骤3:字符类型判断。
接下来4byte数据做哈希运算,按所计算的哈希值从哈希表中取出数据索引,通过索引找到对应字符与做哈希运算的字符对比,若相同,则说明数据在哈希表内,不是新字符,更新哈希表中该字符索引,继续读入数据(每次读入1byte),重复以上操作,直到读入数据不在哈希表内为止,若读入重复长度小于3或重复长度小于4且回指距离大于1k按新字符处理,跳入步骤4;否则跳入步骤6。若不同,做第二次哈希运算并通过哈希地址中存储的索引值取值比较,若相同,继续读入数据,重复以上操作,直到读入数据不在哈希表内为止,若读入重复长度小于3或重复长度小于4且回指距离大于1k按新字符处理,跳入步骤4;否则跳入步骤6。
步骤4:记录新字符个数,按新字符长度格式进行编码
步骤5:记录新字符,完成新字符个数的记录后,在其后记录新字符。继续读入数据。
步骤6:计算重复字符长度与回指距离,并压缩数据。回指距离小于等于1k用第1种压缩格式压缩数据,跳入步骤7;否则用第二种压缩格式压缩数据跳入步骤8。
步骤7:第1种压缩格式编码
步骤8:第2种压缩格式编码
步骤9:判断压缩是否结束,结束则输出数据和数据长度,否则继续读入数据并重复以上操作。
本发明算法的解压缩部分算法整体设计如图10所示:
步骤1:读入比特文件长度,用于判断数据是否结束。
步骤2:首字符判断。
若首字符0≤t0<64,则判断为新字符,跳入步骤3。否则判断为重复字符,跳入步骤5。
步骤3:计算新字符长度
若0<t0<64时,新字符长度等于t0+3(t0到tn记录新字符长度信息);
若t0=0,当t1不等于0时,新字符长度n_len=66+t1;
若t0=0,当t1=0时,继续读入后面的数,直到tn\=0为止,n_len=(n-1)*255+66+tn。
步骤4:记录新字符
根据新字符的个数记录新字符
步骤5:解压压缩数据
若t≥128时,该数据是按压缩格式1进行压缩的,按照对应的压缩格式计算重复长度和回指距离,跳入步骤6。
若64≤t<128时,数据按压缩格式2进行压缩的,按照对应的压缩格式计算重复长度和回指距离,跳入步骤7。
步骤6:压缩格式1中新字符信息判定
若第一byte后两位不等于0时,其为新字符长度,解压数据完成后,跳入步骤4。否则,跳入步骤8。
步骤7:压缩格式2中新字符信息判断
若倒数第二byte后两位不等于0时,其为新字符长度,解压数据完成后,跳入步骤4。否则,跳入步骤8。
步骤8:判断压缩是否结束,结束则输出数据和数据长度,否则继续读入数据并重复以上操作。
压缩和解压缩软件使用c语言在visualstudio2008平台设计,对实际工作中产生的26组比特文件进行压缩和解压缩运算,压缩率均大于50%,平均压缩率为67.06%,lzo算法的平均压缩率67.21%,平均压缩率下降0.15%,26组比特文件压缩率较lzo压缩率下降均不超过0.3%;压缩速率提升18%,解压缩速率提升37%。
(5)本发明解压缩部分电路设计,验证功能、资源利用率及工作频率;
比特文件通过软件进行压缩,将压缩的结果上传给卫星,在卫星上实现解压缩功能。比特文件压缩在地面实现即可,无需fpga,只需用本发明基于c语言开发的软件在电脑上实现即可。解压缩在卫星上实现,需设计fpga电路。基本电路框图如图11所示:
电路包括新字符译码模块、压缩字符译码模块、1读1写sram16384x8、输出控制模块。当数据输入时,首先要对数据类型进行判定是新字符还是重复字符。是新字符的话,计算新字符长度,并直接输出新字符,同时这些新字符从地址0开始要依次写到sram中;是重复字符,判定是何种压缩格式,然后计算回指距离和重复长度,通过回指距离和重复长度从sram中取数进行解压缩并输出该数据。由于解压缩数据长度和新字符个数的不确定性,在电路输出部分设计一个输出数据有效的判定信号,该数据为高时输出结果有效。同样,通过设计反馈电路对输入信号进行控制,只有对某段压缩字符解压完成后才能继续输入字符。
由于不同压缩格式的字符长度和新字符长度以及压缩后数据不确定,各个模块内以及模块之间需要大量的控制逻辑进行判决,判决逻辑随压缩格式数量的增加成数倍增长,译码周期也因此增加,工作频率随之降低,因此压缩格式的减少对解压缩电路的硬件开销、时序开销有很好的优化。
sram的访问时间随其深度增加而增加,本发明的sram深度只有lzo压缩算法sram深度的1/3,因此提高了电路最高工作频率。同时sram内的数据每16384个时钟周期刷新一次,刷新频率是lzo算法的sram刷新频率的三倍,降低了星载电路seu的风险。
通过ise9.2i平台选用xc4vsx55-12ff1148器件对本发明解压缩电路验证,本发明的触发器资源使用率为1%,lut资源使用率为1.3%,slice的资源使用率为2%,ram的资源使用率为2%,io的资源使用率为3%,工作频率为138.1mhz。相较于lzo算法,本发明除了io资源使用率相当以外,其他器件的资源利用率都在1/3左右,且时钟频率也有很大提升。
本发明说明书中未作详细描述的内容属本领域技术人员的公知技术。
- 还没有人留言评论。精彩留言会获得点赞!