一种文章属性识别方法以及电子设备与流程
本发明涉及通信技术领域,尤其涉及的是一种文章属性识别方法以及电子设备。
背景技术:
随着互联网技术的发展,网络上的文章的数目越来越多,处于安全等多种考虑,需要识别出互联网上的垃圾文章。
现有技术中,一般采用基于语义的深度学习方法来进行文章的识别,以确定出文章是否为垃圾文章,其中,深度学习方法会首先将文章转换为文本向量,即可根据所述文本向量对所述文章进行识别,基于语义的方法在构建文本向量时,将所有文本表示为固定长度的数值向量,如word2vec、sentence2vec方法等。word2vec可以求得词语的向量,文本向量可以用核心词的向量变换得到;sentence2vec可以求得句子的向量,文本向量可以有文本中句子的向量组合得到。深度学习方法主要有循环神经网络(recurrentneuralnetworks,rnn),卷积神经网络(convolutionalneuralnetwork,cnn)以及长短期记忆网络(longshort-termmemory,lstm)等。
采用现有技术所示的文章识别的缺陷在于,现有的基于深度学习方法的的文章识别方法训练所需资源多、耗时长,另外由于接口、语言兼容等原因,比较难达到实时性的要求。
技术实现要素:
本发明实施例提供了一种文章属性识别方法以及电子设备,其能够提升对垃圾文章进行识别的效率和准确率。
本发明实施例第一方面提供了一种文章属性识别方法,包括:
将待识别文章进行向量化处理以转换为词袋向量,所述词袋向量所包括的任一数值为词语在所述待识别文章中的词频逆向文件频率tf-idf值;
通过第一模型对所述词袋向量进行处理,获取所述第一预设模型输出的第一预测值;
通过第二模型对所述第一预测值以及所述待识别文章的文本特征进行处理,获取所述第二预设模型输出的第二预测值,或通过第三模型对所述第一预测值以及所述待识别文章的页面特征进行处理,获取所述第三预设模型输出的第三预测值,所述第二预测值和所述第三预测值用于指示所述待识别文章的属性。
本发明实施例第二方面提供了一种电子设备,包括:
第一处理单元,用于将待识别文章进行向量化处理以转换为词袋向量,所述词袋向量所包括的任一数值为词语在所述待识别文章中的词频逆向文件频率tf-idf值;
第二处理单元,用于通过第一模型对所述词袋向量进行处理,获取所述第一预设模型输出的第一预测值;
第三处理单元,用于通过第二模型对所述第一预测值以及所述待识别文章的文本特征进行处理,获取所述第二预设模型输出的第二预测值,或通过第三模型对所述第一预测值以及所述待识别文章的页面特征进行处理,获取所述第三预设模型输出的第三预测值,所述第二预测值和所述第三预测值用于指示所述待识别文章的属性。
本发明实施例第三方面提供了一种电子设备,包括:
一个或多个中央处理器、存储器、总线系统、以及一个或多个程序,所述中央处理器和所述存储器通过所述总线系统相连;
其中所述一个或多个程序被存储在所述存储器中,所述一个或多个程序包括指令,所述指令当被所述电子设备执行时使所述电子设备执行如本发明实施例第一方面所示的方法。
本发明实施例第四方面提供了一种存储一个或多个程序的计算机可读存储介质,所述一个或多个程序包括指令,所述指令当被电子设备执行时使所述电子设备执行如本发明实施例第一方面所示的方法。
从以上技术方案可以看出,本发明实施例具有以下优点:
本实施例所示在将待识别文章进行向量化处理以转换为词袋向量,通过第一模型对所述词袋向量进行处理,获取所述第一预设模型输出的第一预测值,且能够通过第二模型对所述第一预测值以及所述待识别文章的文本特征进行处理,获取所述第二预设模型输出的第二预测值,或通过第三模型对所述第一预测值以及所述待识别文章的页面特征进行处理,获取所述第三预设模型输出的第三预测值,所述第二预测值和所述第三预测值用于指示所述待识别文章的属性,其中,所述第二预测值和所述第三预测值可指示出所述待识别文章是垃圾文章还是正常文章,且能够提升对待识别文章识别的准确率以及效率,避免了检索到垃圾文章的可能性。
附图说明
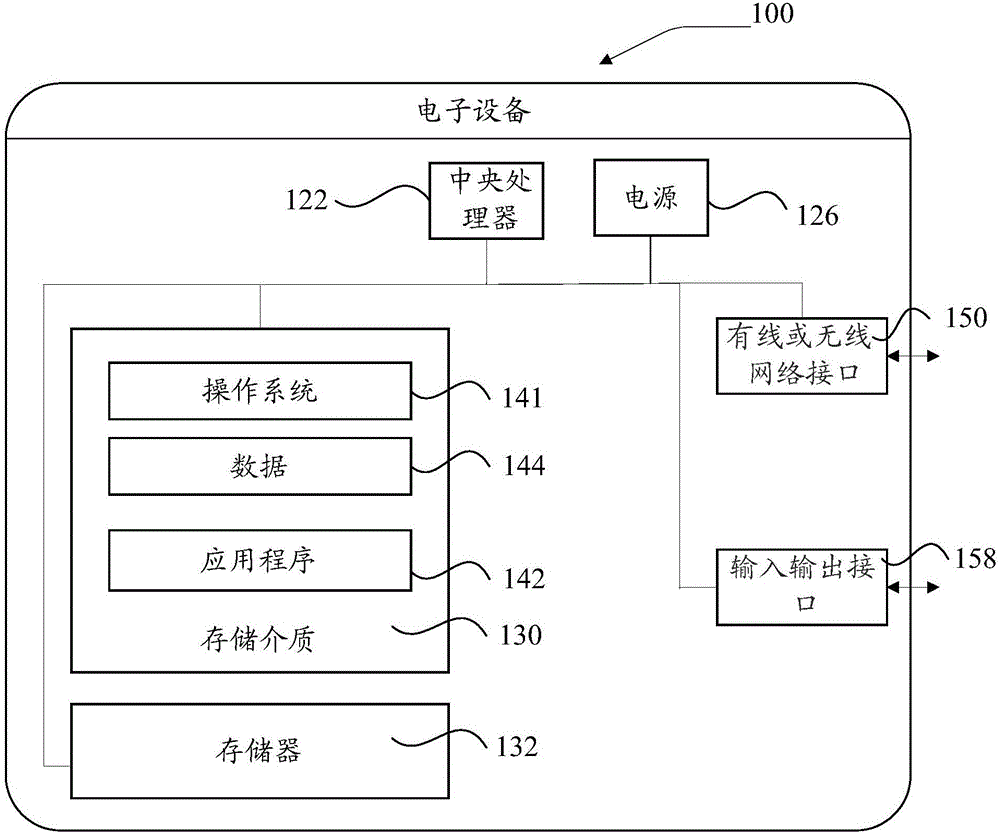
图1为本发明所提供的电子设备的一种实施例结构示意图;
图2为本发明所提供的文章属性识别方法的一种实施例步骤流程图;
图3为本发明所提供的电子设备的显示界面的一种实施例示意图;
图4为本发明所提供的文章属性识别方法的另一种实施例步骤流程图;
图5为本发明所提供的电子设备的一种实施例结构示意图。
具体实施方式
本申请提供了一种文章属性识别方法,本申请所示的所述文章属性识别方法应用至电子设备上,即由所述电子设备执行所述文章属性识别方法,从而使得电子设备能够识别出文章的属性。
具体的,所述属性为所述文章是正常文章,或所述属性为所述文章为垃圾文章。本申请所示的垃圾文章可为涉及黄赌毒、垃圾广告、恶意营销等的文章。
以下首先结合图1所示对能够执行所述文章属性识别方法的所述电子设备的具体结构进行详细说明:
本实施例所提供的电子设备100可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上中央中央处理器(centralprocessingunits,cpu)122(例如,一个或一个以上中央处理器)和存储器132,一个或一个以上存储应用程序142或数据144的存储介质130(例如一个或一个以上海量存储设备)。
其中,存储器132和存储介质130可以是短暂存储或持久存储。存储在存储介质130的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对电子设备中的一系列指令操作。
更进一步地,中央中央处理器122可以设置为与存储介质130通信,在电子设备100上执行存储介质130中的一系列指令操作。
电子设备100还可以包括一个或一个以上电源126,一个或一个以上有线或无线网络接口150,一个或一个以上输入输出接口158,和/或,一个或一个以上操作系统141,例如windowsservertm,macosxtm,unixtm,linuxtm,freebsdtm等等。
基于图1所示的电子设备,以下对电子设备执行本实施例所示的文章属性识别方法的具体执行流程进行说明:
本实施例所示的本章属性识别方法,具体包括两个执行流程,第一个执行流程用于进行模型训练,第二执行流程基于已训练完成的模型进行文章属性的识别,从而判断出文章是否为垃圾文章。
以下首先结合图2所示对所述电子设备如何进行模型训练的进行详细说明:
其中,图2为本发明所提供的文章属性识别方法的一种实施例步骤流程图。
步骤201、所述电子设备接收第一待测试数据集s1。
以下对所述第一待测试数据集s1进行详细说明:
本实施例所示的所述第一待测试数据集s1包括有多篇文章,且所述第一待测试数据集s1所包括的任一文章所包括的文本为长文本,即所述第一待测试数据集所包括的任一文章的文本量大于或等于目标数值。
本实施例所示的文本量可为如下所示的至少一项:
字数,词汇数,分词数,短语数以及短句数等。
本实施例以所述文本量为字数为例进行示例性说明,需明确的是,本实施例对所述文本量的说明为可选的示例,不做限定,只要所述文本量能够度量出文章是否为长文本即可。
本实施例对所述目标数值做限定,例如,所述目标数值为大于或等于150,即本实施例所示的所述第一待测试数据集所包括的任一文章的字数大于或等于150个字。
本实施例所示的所述第一待测试数据集s1已被标注完成,本实施例所示的标注是指,所述第一待测试数据集s1所包括的多篇文章中,已标注出哪些是正类属性的文章,哪些是负类属性的文章。
其中,所述正类属性的文章是指垃圾文章,所述负类属性的文章是指正常文章。
具体的,本实施例所示的所述第一待测试数据集s1包括m个正类属性的文章以及n个负类属性的文章。
本实施例对所述m以及所述n之间的比例关系不做限定,只要所述m以及所述n为大于1的正整数即可,本实施例以所述m与所述n之间的比例为7:3为例进行示例性说明。
以下对电子设备具体是如何接收到用户输入的所述第一待测试数据集s1的进行可选的说明:
所述电子设备上运行有用于进行文章属性识别的识别系统,用户可调出所述识别系统的文章上传界面,所述文章上传界面如图3所示,其中,图3为本发明所提供的电子设备的显示界面的一种实施例示意图。
在需要对文章属性进行识别时,需要将已经确定的垃圾文章以及正常文章上传至运行在所述电子设备上的识别系统,具体上传过程可为,用户将已经确定的垃圾文章拖拽至区域303,从而将所述垃圾文章上传至所述电子设备,或者,用户可点击按键301,通过用于存储所述垃圾文章的存储路径,将所述垃圾文章上传至运行在所述电子设备上的识别系统。
在需要将已经确定的正常文章上传至运行在所述电子设备上的识别系统,具体上传过程可为,用户将已经确定的正常文章拖拽至区域304,从而将所述正常文章上传至所述电子设备,或者,用户可点击按键302,通过用于存储所述正常文章的存储路径,将所述正常文章上传至运行在所述电子设备上的识别系统。
所述识别系统即可分别对正常文章和所述垃圾文章进行分类,且在没有接收到足够数量的用于进行模型训练的正常文章和垃圾文章的数量时,可在所述电子设备的显示屏幕上弹出提示信息,指示用户还需上传的正常文章和所述垃圾文章的数量。
需明确的是,本实施例对所述电子设备如何获取到所述正常文章和所述垃圾文章的过程为可选的示例,不做限定。
以下对垃圾文章的来源进行示例性说明:
本实施例所示的垃圾文章的来源可为:由用户随机获取互联网上的文章并进行阅读,从而判断出垃圾文章,可选的,为提升获取到垃圾文章的效率,则用户可在已被封禁的网站里所发表的文章进行人工审核,从而确定出垃圾文章。
本实施例所示的正常文章的来源可为:由用户随机获取互联网上的文章并进行阅读,从而判断出正常文章,可选的,为提升获取到正常文章的效率,则用户可在已发表的优质网站里所发表的文章进行人工审核,从而确定出正常文章。
所述电子设备可将已获取所述第一待测试数据集s1划分为训练集和测试集,其中,所述训练集包括已标注的垃圾文章,所述测试集包括已标注的正常文章。
步骤202、所述电子设备对所述第一待测试数据集进行预处理以获取到分词处理后的所述第一待测试数据集。
以下对第一待测试数据集s1如何进行预处理进行说明:
可选的,本实施例所示的所述预处理可为除去所述第一待测试数据集s1中的非文本部分,从而提升了模型训练的效率。
例如,若本实施例所示的所述文章包括有html的一些标签,则所述电子设备可将html的一些标签进行删除。
本实施例所示的所述预处理可为对所述第一待测试数据集s1所包括的任一文章进行分词处理;
具体的,因中文词语之间没有空格,为进行模型训练,则需要对文章进行分词处理,实施例对分词处理的工具不做限定,例如采用hanlp进行分词处理;
为更好的理解本实施例所示的对文章进行分词处理,结合具体示例进行说明:
分词处理前的文本如:“沙瑞金向毛娅打听他们家在京州的别墅,毛娅笑着说,王大路事业有成之后,要给欧阳菁和她公司的股权,她们没有要,王大路就在京州帝豪园买了三套别墅,可是李达康和易学习都不要,这些房子都在王大路的名下,欧阳菁好像去住过,毛娅不想去,她觉得房子太大很浪费,自己家住得就很踏实。”
采用本实施例所示的预处理,则将上段文本进行分词处理,从而输出的文本为:“沙瑞金向毛娅打听他们家在京州的别墅,毛娅笑着说,王大路事业有成之后,要给欧阳菁和她公司的股权,她们没有要,王大路就在京州帝豪园买了三套别墅,可是李达康和易学习都不要,这些房子都在王大路的名下,欧阳菁好像去住过,毛娅不想去,她觉得房子太大很浪费,自己家住得就很踏实。”
本实施例所示的电子设备即可基于分词处理后的所述文本进行模型训练,具体训练过程请详见下述步骤所示。
可选的,本实施例所示的所述预处理还可为删除停用词,在对文本进行分词处理时,会分出很多无效的词,比如“着”,“和”,还有一些标点符号,这些词语对模型训练是无效的,因此需要去掉,这些词就是停用词,在识别出文本中的停用词后,即可将所述停用词进行删除。
可选的,本实施例所示的所述预处理还可为去除文本中的噪声,如空格,制表符等。
步骤203、所述电子设备计算分词处理后的所述第一待测试数据集所包括的任一词语的所述tf-idf值。
经由上述的步骤202,所述电子设备将所述训练集所包括的多篇垃圾文章中的任一文章进行分词处理,所述电子设备将所述测试集所包括的多篇正常文章中的任一文章进行分词处理。
所述电子设备为计算出所述训练集所包括的任一词语的tf-idf值,则首先需要基于词袋模型对所述训练集进行向量化。
具体的,本实施例所示的词袋模型(bagofwords,bow)可不考虑任一文章中词语与词语之间的上下文关系,仅仅只考虑文章中所有词语的权重,而权重与词语在文章中出现的频率有关。
在对所述训练集所包括的所有垃圾文章进行分词处理后,可统计所述训练集所包括的每个词语在文本中出现的次数,就可以得到任一文章基于词语的特征,如果将各个文章样本的词语与对应的词频放在一起,就完成了对所述训练集的向量化,即所述电子设备可得到每个词语在各个文章中形成的词向量。
在对所述训练集的向量化的过程中,词频高的词语,如语气词,连接词等,该词语的重要性很低,可见若仅仅通过词频来判断词语的重要性显然是不准确的,则本实施例所示的电子设备可计算训练集所包括的任一词语的tf-idf值。
其中,所述tf-idf(termfrequency-inversedocumentfrequency)值包括两部分,即tf和idf,所述tf为上文所示的词频,所述idf反应了一个词语在所述训练集所包括的所有文章中出现的频率,如果一个词语在所述训练集所包括的很多文章中出现,那么该词语的idf值应该低。而反过来如果一个词语在所述训练集所包括的比较少的文章中出现,那么该词语的idf值应该高。
本实施例中,所述电子设备计算出所述测试集所包括的任一词语的tf-idf值的具体过程,请详见上述所示的所述电子设备计算出所述训练集所包括的任一词语的tf-idf值的说明,具体不做赘述。
步骤204、所述电子设备确定第一排序列表。
本实施例所示的所述第一排序列表根据所述训练集所生成,具体的,所述第一排序列表包括所述m个正类属性的文章所包括的词语,且所述第一排序列表按照词语的所述tf-idf值由大到小的顺序进行排序。
步骤205、所述电子设备确定第二排序列表。
本实施例所示的所述第二排序列表根据所述测试集所生成,具体的,所述第二排序列表包括所述n个负类属性的文章所包括的词语,且所述第二排序列表按照词语的所述tf-idf值由大到小的顺序进行排序。
步骤206、所述电子设备获取第一测试词袋向量。
所述电子设备根据所述第一排序列表和所述第二排序列表获取所述第一测试词袋向量。
具体的,所述电子设备将所述第一排序列表中排序在前a位的词语与所述第二排序列表中排序在前b位的词语去重后得到第一测试词袋向量。
本实施例对所述a以及所述b的具体数值不做限定,只要所述a以及所述b为大于1的正整数即可。
具体的,所述电子设备将所述第一排序列表中排序在前a位的词语与所述第二排序列表中排序在前b位的词语去重后可得到t个词,作为词袋,从而使得本实施例所示的电子设备分别为所述测试集和所述训练集构建一个t维的数值向量,第i维的值是第i个词语的tf-idf值。
步骤207、利用逻辑回归lr模型对所述第一测试词袋向量进行训练,以得到所述第一预设模型。
本实施例中,所述电子设备在获取到所述第一测试词袋向量之后,即可将所述第一测试词袋向量输入至逻辑回归lr模型,以使所述逻辑回归lr模型对所述第一测试词袋向量进行训练以得到所述第一预设模型。
本实施例所示的逻辑回归(logisticregression,lr)是机器学习中的一种分类模型,由于算法的简单和高效,在实际中应用非常广泛。
步骤208、所述电子设备抽取所述第一待测试数据集的文本特征。
本实施例所示的所述电子设备抽取所述第一待测试数据集所包括的任一文章的文本特征,本实施例对所述文本特征不做限定,只要所述文本特征能够表征文章是否为垃圾文章即可。
本实施例所示的所述文本特征是基于文字定义的特征,例如,所述文本特征为字、词、句的堆砌长度、无意义词语占比、长词语的占比、中文字符占比、正常英文单词占比、词语最大连接度等。
步骤209、所述电子设备利用逻辑回归lr模型对所述第一待测试数据集的文本特征和所述第一测试词袋向量的预测值进行训练,以得到所述第二预设模型。
本实施例所示电子设备在步骤208获取到所述第一待测试数据集的文本特征的情况下,即可结合所述第一待测试数据集的文本特征和所述第一测试词袋向量的预测值进行训练。
具体的,本实施例所示的所述电子设备可对所述第一测试词袋向量进行训练以得到所述第一测试词袋向量的预测值,例如,所述电子设备可基于逻辑回归lr模型对所述第一测试词袋向量进行训练以得到所述第一测试词袋向量的预测值。
本实施例以所述电子设备获取到的所述第一待测试数据集的文本特征为20个特征为例,则所述电子设备将计算好的20个文本特征和所述第一测试词袋向量的预测值组合形成一个21维的向量,并将已获取到的21维的向量通过逻辑回归lr模型进行训练以得到所述第二预设模型。
步骤210、所述电子设备接收第二待测试数据集s2。
以下对所述第二待测试数据集s2进行详细说明:
本实施例所示的所述第二待测试数据集s2包括有多篇文章,且所述第二待测试数据集s2所包括的任一文章所包括的文本为短文本,即所述第二待测试数据集所包括的任一文章的文本量小于所述目标数值。
本实施例对所述目标数值做限定,例如,所述目标数值为小于150,即本实施例所示的所述第二待测试数据集所包括的任一文章的文本量小于150个字。
本实施例所示的所述第二待测试数据集s2已被标注完成,本实施例所示的标注是指,所述第二待测试数据集s2所包括的多篇文章中,哪些是正类属性的文章,哪些是负类属性的文章。
所述电子设备获取所述第二待测试数据集s2的具体过程,请参见所述电子设备获取所述第一待测试数据集s1的具体过程,具体在本步骤中不做赘述。
本实施例所示的步骤210与步骤201至步骤209之间无执行时序上的先后限定,即可先执行本实施例所示的步骤201至步骤209,后执行本实施例所示的步骤210,或可先执行本实施例所示的步骤201至步骤209,后执行本实施例所示的步骤210,或可同时执行本实施例所示的步骤210与步骤201至步骤209。
步骤211、所述电子设备对所述第二待测试数据集进行预处理以获取到分词处理后的所述第二待测试数据集。
对所述第二待测试数据集进行预处理的具体过程,请详见所述第一待测试数据集进行预处理的具体过程,具体在本步骤中不做赘述。
步骤212、所述电子设备计算分词处理后的所述第二待测试数据集所包括的任一词语的所述tf-idf值。
对所述第二待测试数据集所包括的任一词语的所述tf-idf值的具体过程,请详见所述第一待测试数据集所包括的任一词语的所述tf-idf值的具体过程,具体在本步骤中不做赘述。
步骤213、所述电子设备确定第三排序列表。
本实施例所示的所述第三排序列表包括所述m个正类属性的文章所包括的词语,且所述第三排序列表按照词语的所述tf-idf值由大到小的顺序进行排序。
步骤214、所述电子设备确定第四排序列表。
本实施例所示的所述第四排序列表包括所述n个负类属性的文章所包括的词语,且所述第四排序列表按照词语的所述tf-idf值由大到小的顺序进行排序。
步骤215、所述电子设备获取第二测试词袋向量。
所述电子设备根据所述第三排序列表和所述第四排序列表获取所述第二测试词袋向量。
具体的,所述电子设备将所述第三排序列表中排序在前a位的词语与所述第四排序列表中排序在前b位的词语去重后得到第二测试词袋向量。
本实施例对所述a以及所述b的具体数值不做限定,只要所述a以及所述b为大于1的正整数即可。
具体的,所述电子设备将所述第三排序列表中排序在前a位的词语与所述第四排序列表中排序在前b位的词语去重后可得到t个词,作为词袋。
步骤216、所述电子设备抽取所述第二待测试数据集的页面特征。
所述电子设备抽取所述第二待测试数据集的页面特征,本实施例所示页面特征包括但不限于视频,音频,图片的特征、文字颜色和背景色特征、空白行特征等。
步骤217、所述电子设备利用逻辑回归lr模型对所述第二待测试数据集的页面特征和所述第二测试词袋向量进行训练,得到所述第三预设模型。
本实施例中,以所述第二待测试数据集的页面特征为19个页面特征为例进行示例性说明,则所述电子设备在获取到所述第二测试词袋向量之后,即可将所述第二测试词袋向量以及第二待测试数据集的页面特征组合形成一个20维的向量,所述电子设备利用逻辑回归lr模型对所述第二待测试数据集的页面特征和所述第二测试词袋向量进行训练以得到所述第三预设模型。
基于图2所示的实施例获取到所述第一预设模型、所述第二预设模型以及第三预设模型的情况下,以下结合图4所示说明本实施例所示的电子设备基于上述已训练完成的模型是如何进行文章属性识别方法。
其中,图4为本发明所提供的文章属性识别方法的一种实施例步骤流程图。
步骤401、所述电子设备接收待识别文章。
在用户需要进行文章属性的识别时,用户即可将待识别文章输入至所述电子设备。
步骤402、所述电子设备将已接收到的待识别文章进行向量化处理以转换为词袋向量。
以下对待识别文章如何进行预处理进行说明:
可选的,本实施例所示的所述预处理可为除去所述待识别文章中的非文本部分,从而提升了对文章进行识别的效率。
例如,若本实施例所示的所述待识别文章包括有html的一些标签,则所述电子设备可将html的一些标签进行删除。
本实施例所示的所述预处理可为对所述待识别文章进行分词处理;
具体的,因中文词语之间没有空格,为准确的对待识别文章的属性进行识别,即判断所述待识别文章是否为垃圾文章,则需要对文章进行分词处理,实施例对分词处理工具不做限定,例如采用hanlp进行分词处理;
本实施例对所述待识别文章进行分词处理的具体说明,请详见上述实施例所示的对所述第一待测试数据集s1进行分词处理的具体过程,具体在本实施例中不做赘述。
可选的,本实施例所示的所述预处理还可为删除停用词,在对待识别文章进行分词处理时,会分出很多无效的词,比如“着”,“和”,还有一些标点符号,这些词语对待识别文章进行识别是无效的,从而降低了对待识别文章进行识别的效率,因此需要去掉,这些词就是停用词,在识别出文本中的停用词后,即可将所述停用词进行删除。
所述电子设备即可计算分词处理后的所述待识别文章所包括的任一词语的所述tf-idf值。
所述电子设备为计算出所述待识别文章所包括的任一词语的tf-idf值,则首先需要基于词袋模型对所述待识别文章进行向量化。
具体的,本实施例所示的词袋模型(bagofwords,bow)可不考虑待识别文章中词语与词语之间的上下文关系,仅仅只考虑待识别文章中所有词语的权重,而权重与词语在文章中出现的频率有关。
在对所述待识别文章进行分词处理后,可统计所述待识别文章所包括的每个词语在待识别文章中出现的次数,就可以得到待识别文章基于词语的特征,如果将待识别文章的词语与对应的词频放在一起,就完成了对所述待识别文章的向量化,即所述电子设备可得到每个词语在所述待识别文章中形成的词向量。
在对所述待识别文章向量化的过程中,词频高的词语,如语气词,连接词等,该词语的重要性很低,可见若仅仅通过词频来判断词语的重要性显然是不准确的,则本实施例所示的电子设备可计算待识别文章所包括的任一词语的tf-idf值。
步骤403、所述电子设备将所述词袋向量输入至第一预设模型,以获取所述第一预设模型输出的第一预测值。
所述第一预设模型的具体说明请详见上述实施例所示,具体在本实施例中,不做赘述。
在所述第一预设模型接收到所述词袋向量的情况下,所述第一预设模型即可输出所述第一预测值。
步骤404、所述电子设备判断所述待识别文章的文本量是否大于或等于目标数值,若是,则执行步骤405,若否,则执行步骤410。
本实施例对所述目标数值的大小不做限定,只要在所述待识别文章的文本量大于或等于所述目标数值时,所述电子设备确定所述待识别文章为长篇文章,在所述待识别文章的文本量小于所述目标数值时,所述电子设备确定所述待识别文章为短文本即可。
本实施例以所述目标数值为150为例进行示例性说明。
步骤405、所述电子设备抽取所述待识别文章的文本特征。
本实施例中,在电子设备确定出所述待识别文章为长篇文章时,所述电子设备可抽取所述待识别文章的文本特征。
其中,本实施例对所述文本特征不做限定,只要所述文本特征能够表征文章是否为垃圾文章即可。
本实施例所示的所述文本特征是基于文字定义的特征,例如,所述文本特征为字、词、句的堆砌长度、无意义词语占比、长词语的占比、中文字符占比、正常英文单词占比、词语最大连接度等。
步骤406、所述电子设备将所述待识别文章的文本特征以及所述第一预测值输入至第二预设模型。
所述第二预设模型的具体说明请详见上述实施例所示,具体在本实施例中不做赘述。
所述电子设备在将所述待识别文章的文本特征以及所述第一预测值输入至第二预设模型后,所述电子设备即可获取所述第二预设模型输出的用于指示所述待识别文章的属性的第二预测值,所述第二预设模型用于识别所述待识别文章的文本特征。
步骤407、所述电子设备判断所述第二预测值是否大于或等于预设数值,若是,则执行步骤408,若否,则执行步骤409。
本实施例对所述预设数值的大小不做限定,本实施例以所述预设数值为0.5为例进行示例性说明。
在所述电子设备确定出所述第二预测值大于或等于预设数值的情况下,则所述电子设备即可确定所述待识别文章的属性为正类属性,即所述待识别文章为垃圾文章。
在所述电子设备确定出所述第二预测值小于预设数值的情况下,则所述电子设备即可确定所述待识别文章的属性为负类属性,即所述待识别文章为正常文章。
步骤408、所述电子设备确定出所述待识别文章的属性为正类属性。
步骤409、所述电子设备确定出所述待识别文章的属性为负类属性。
步骤410、所述电子设备抽取所述待识别文章的页面特征。
所述电子设备抽取所述待识别文章的页面特征,本实施例所示页面特征包括但不限于视频,音频,图片的特征、文字颜色和背景色特征、空白行特征等。
步骤411、所述电子设备将所述待识别文章的页面特征以及所述第一预测值输入至第三预设模型。
本实施例所示的所述第三预设模型的具体说明,请详见上述实施例所示,具体在本实施例中不做赘述。
所述第三预设模型在接收到所述待识别文章的页面特征以及所述第一预测值的情况下,所述第三预设模型即可输出用于指示所述待识别文章的属性的第三预测值,所述第三预设模型用于识别所述待识别文章的页面特征。
步骤412、所述电子设备判断所述第三预测值是否大于或等于所述预设数值,若是,则执行步骤413,若否,则执行步骤414。
本实施例对所述预设数值的大小不做限定,本实施例以所述预设数值为0.5为例进行示例性说明。
在所述电子设备确定出所述第三预测值大于或等于预设数值的情况下,则所述电子设备即可确定所述待识别文章的属性为正类属性,即所述待识别文章为垃圾文章。
在所述电子设备确定出所述第三预测值小于预设数值的情况下,则所述电子设备即可确定所述待识别文章的属性为负类属性,即所述待识别文章为正常文章。
步骤413、所述电子设备确定出所述待识别文章的属性为正类属性。
步骤414、所述电子设备确定出所述待识别文章的属性为负类属性。
可见,采用本实施例所示的所述文章属性识别方法,能够基于待识别文章的高级特征定义,即包括文本特征和页面特征相结合对待识别文章的属性进行识别,从而提升了对待识别文章进行识别的准确性,若只是单纯的依据基于文本特征训练以得到的所述第一预设模型进行待识别文章属性的识别,则所述第一待测试数据集s1的准确率和召回率分别为0.963,0.976。经过线上的真实数据预测结果反馈,所述第一预设模型的效果并不理想。一是因为垃圾文本的词库更新比较快,如果要更新词袋,需要标注新的垃圾样本,成本很高;二是因为较多的文章中文本比较少,导致词袋特征较少,单纯的词袋模型预测结果波动较大;而只是单纯的依据所述第二预设模型进行待识别文章属性的识别,所述第一待测试数据集s1的准确率和召回率分别为0.978,0.981。经过线上的真实数据预测结果反馈,所述第二预设模型对长文本的预测结果达到预期要求,但是对于短文本(文本字符数小于n的文章,在实践中n取值为150)的预测结果依然不理想。原因是所述第二预设模型是基于词袋特征和抽取的文本特征建立模型,都是依赖文本文字的,由于短文本文字信息不够丰富,所以预测结果也容易波动,而采用本实施例所示的结合所述第一预设模型、所述第二预设模型以及所述第三预设模型对所述待识别文章进行识别,则能够准确的识别出待识别文章是否为垃圾文章,且在所述第二待测试数据集s2上的准确率和召回率分别为0.823,0.810。经过线上的真实数据预测结果反馈,所述第三预设模型对短文本的预测结果达到预期要求。
本实施例所示的方法在模型训练的过程中,使用了正常文章和垃圾文章之间的差异,即文本特征和页面特征,从而基于已训练完成的模型对待识别文章进行识别时,能够准确的识别出待识别文章是否为垃圾文章,即本实施例所示的方法在对待识别文章的属性进行识别时,具有较高的准确性。
以下对本发明实施例所示的方法可能的应用领域进行示例性说明,需明确的是,以下对本实施例所示的方法所应用的领域的说明为可选的说明,不做限定。
以下结合具体的应用场景对本申请所提供的文章属性识别方法的具体执行过程进行说明:
本申请所示的方法可应用至微信领域,即运行在微信后台的电子设备实现环境是spark集群环境,其中,spark是专为大规模数据处理而设计的快速通用的计算引擎。所述电子设备可调用spark-mllib算法包以实现图2所示的对所述第一预设模型、所述第二预设模型以及所述第三预设模型的训练过程,所述第一预设模型、所述第二预设模型以及所述第三预设模型的具体训练过程,请详见图2所示的实施例,具体不做赘述。
在具体应用中,所述电子设备的cpu可使用20核,每个核申请10g内存,从而实现上述图4所示的待识别文章的属性识别过程,具体识别过程,请详见图4所示的实施例,具体不做赘述。
可见,在将本实施例所示的方法应用至微信领域时,所述电子设备能够对公众号所发表的文章进行识别,且能够准确的识别出公众号所发表的垃圾文章,且识别的准确性高,效率快,在识别出垃圾文章后,所述电子设备可将所述垃圾文章进行屏蔽,若任一公众号所发布的垃圾文章的数目超过预设阈值,则所述电子设备可将该公众号进行屏蔽,从而使得垃圾文章不会在微信搜索结果中出现,从而提升了正常文章搜索的效率,提升了对正常文件进行搜索的效率,进而提升了微信搜索的用户体验。
又如,本实施例所示的方法可应用至浏览器引擎领域,即运行在浏览器后台的电子设备可执行本实施例图2所示的对所述第一预设模型、所述第二预设模型以及所述第三预设模型的训练过程,运行在浏览器后台的电子设备能够对网站所发布的文章进行识别,且能够准确的识别出网站所发布的垃圾文章,且识别的准确性高,效率快,在识别出垃圾文章后,所述电子设备可将所述垃圾文章进行屏蔽,若任一网站所发布的垃圾文章的数目超过预设阈值,则所述电子设备可将该网站进行屏蔽,从而使得垃圾文章不会在浏览器搜索结果中出现,从而提升了正常文章搜索的效率,提升了对正常文件进行搜索的效率,进而提升了浏览器搜索的用户体验。
以下结合图5所示对能够实现图2所示的模型训练的具体过程的电子设备的具体结构进行详细说明:
所述电子设备包括:
第一处理单元501,用于将待识别文章进行向量化处理以转换为词袋向量,所述词袋向量所包括的任一数值为词语在所述待识别文章中的词频逆向文件频率tf-idf值;
第二处理单元502,用于通过第一模型对所述词袋向量进行处理,获取所述第一预设模型输出的第一预测值;
第三处理单元503,用于通过第二模型对所述第一预测值以及所述待识别文章的文本特征进行处理,获取所述第二预设模型输出的第二预测值,或通过第三模型对所述第一预测值以及所述待识别文章的页面特征进行处理,获取所述第三预设模型输出的第三预测值,所述第二预测值和所述第三预测值用于指示所述待识别文章的属性。
可选的,所述第三处理单元503还用于,判断所述待识别文章的文本量是否大于或等于目标数值,若是,则所述第三处理单元503通过第二模型对所述第一预测值以及所述待识别文章的文本特征进行处理,若否,则所述第三处理单元503通过第三模型对所述第一预测值以及所述待识别文章的页面特征进行处理。
可选的,所述第二处理单元502还用于,接收第一待测试数据集,所述第一待测试数据集所包括的任一文章的文本量大于或等于所述目标数值,所述第一待测试数据集包括m个正类属性的文章以及n个负类属性的文章,所述m以及所述n为大于1的正整数,获取分词处理后的所述第一待测试数据集,计算分词处理后的所述第一待测试数据集所包括的任一词语的所述tf-idf值,将所述m个正类属性的文章所包括的词语与所述n个负类属性的文章所包括的词语去重后得到第一测试词袋向量,所述第一测试词袋向量所包括的任一数值为词语在所述第一待测试数据集中的所述tf-idf值,通过逻辑回归lr模型对所述第一测试词袋向量进行处理,得到所述第一预设模型。
可选的,所述第二处理单元502还用于,确定第一排序列表,所述第一排序列表包括所述m个正类属性的文章所包括的词语,且所述第一排序列表按照词语的所述tf-idf值由大到小的顺序进行排序,确定第二排序列表,所述第二排序列表包括所述n个负类属性的文章所包括的词语,且所述第二排序列表按照词语的所述tf-idf值由大到小的顺序进行排序,将所述第一排序列表中排序在前a位的词语与所述第二排序列表中排序在前b位的词语去重后得到第一测试词袋向量,所述a以及所述b为大于1的正整数。
可选的,所述第三处理单元503还用于,抽取所述第一待测试数据集的文本特征,通过逻辑回归lr模型对所述第一待测试数据集的文本特征和所述第一测试词袋向量的预测值进行处理,获取所述第二预设模型。
可选的,所述第三处理单元503还用于,接收第二待测试数据集,所述第二待测试数据集所包括的任一文章的文本量小于所述目标数值,所述第二待测试数据集包括m个正类属性的文章以及n个负类属性的文章;获取分词处理后的所述第二待测试数据集;计算分词处理后的所述第二待测试数据集所包括的任一词语的所述tf-idf值;将所述m个正类属性的文章所包括的词语与所述n个负类属性的文章所包括的词语去重后得到第二测试词袋向量,所述第二测试词袋向量所包括的任一数值为词语在所述第二待测试数据集中的所述tf-idf值;抽取所述第二待测试数据集的页面特征;通过逻辑回归lr模型对所述第二待测试数据集的页面特征和所述第二测试词袋向量进行处理,得到所述第三预设模型。
可选的,所述第三处理单元503还用于,确定第三排序列表,所述第三排序列表包括所述m个正类属性的文章所包括的词语,且所述第三排序列表按照词语的所述tf-idf值由大到小的顺序进行排序;确定第四排序列表,所述第四排序列表包括所述n个负类属性的文章所包括的词语,且所述第四排序列表按照词语的所述tf-idf值由大到小的顺序进行排序;将所述第三排序列表中排序在前a位的词语与所述第四排序列表中排序在前b位的词语去重后得到第二测试词袋向量,所述a以及所述b为大于1的正整数。
可选的,所述第一处理单元501还用于,获取分词处理后的所述待识别文章;计算分词处理后的所述待识别文章所包括的任一词语的所述tf-idf值,获取所述词袋向量。
可选的,所述第三处理单元503还用于,判断所述第二预测值是否大于或等于预设数值;若判断出所述第二预测值大于或等于所述预设数值,则确定所述待识别文章的属性为正类属性;若判断出所述第二预测值小于所述预设数值,则确定所述待识别文章的属性为负类属性。
可选的,所述第三处理单元503还用于,判断所述第三预测值是否大于或等于预设数值;若判断出所述第三预测值大于或等于所述预设数值,则确定所述待识别文章的属性为正类属性;若判断出所述第三预测值小于所述预设数值,则确定所述待识别文章的属性为负类属性。
本实施例所示的电子设备可用于执行图2以及图4所示的方法,具体执行过程,请详见图2以及图4所示,具体不做赘述。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
在本申请所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,电子设备,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!