一种分布式的聚焦网络爬虫网页爬取方法及系统与流程
本发明属于网络爬虫领域,具体涉及一种分布式的聚焦网络爬虫网页爬取方法及系统,能够对不同网站发送不同方式的请求,解析不同结构的数据。
背景技术:
网络爬虫能够有效使用现有的各种资源自动抓取互联网中大量网页信息的程序,有时也被叫成“网络蜘蛛(spider)”。聚焦网络爬虫也可被称为主题网络爬虫,是有目的地爬取数据,根据特定的主题来爬取相关的页面。与通用网络爬虫相比,这类爬虫并不是漫无目的地爬取整个网络的数据,而是选择性的爬取,这样既能减少爬取网页的数量,同时也提升了网页更新的效率,从而使得这类爬虫对爬取速度和存储空间的要求不是很高,但是需要有良好的爬行策略来评价页面或链接是否需要被爬取。
由于聚焦网络爬虫爬取过程中需要获取请求url、发送web请求下载页面、从网页中解析结构化数据、重复数据过滤、种子任务处理5个环节,每个环节消耗资源各不相同,且每个环节出现问题都会影响整个爬虫系统效率及稳定性。另外,随着互联网技术的日新月异,网站越来越多,信息越来越多,而且大部分网站数据均为异步请求;或是部分网站在服务端对数据进行加密处理,前端执行js脚本对数据解密处理,因此缺少一种兼容各种网站、各类数据的爬虫系统。
技术实现要素:
本发明提出一种分布式的聚焦网络爬虫网页爬取方法及聚焦网络爬虫系统,能够支持多种类型的网页请求方式,结构化数据解析配置灵活。爬取过程模块化、职能化,大大提升数据抓取效率,具有高度的内聚性和透明性。
本发明将分布式技术利用到聚焦网络爬虫系统中,将5个处理环节模块化并且每个模块职能单一,从而提高了整个系统的工作效率,使得系统水平扩展更方便简单。另一方面,本发明中引入kafka消息队列用于模块之间的解耦,kafka也具备高吞吐、高可用、易扩展的特点,因此引入kafka这种存储介质也大大提高了本发明的效率和稳定性。
本发明引入selenium自动化测试工具调用浏览器或伪浏览器来加载数据;而对于加密数据则通过调用js引擎执行js脚本对数据解密从而爬取数据。
本发明采用的技术方案如下:
一种分布式的聚焦网络爬虫网页爬取方法,包括以下步骤:
1)任务生成模块,根据种子任务获取数据抓取的入口链接,生成待下载任务;
2)网页下载模块,根据待下载任务,判断是要以传统的http请求、selenium调用浏览器或伪浏览器还是需要使用js引擎执行js脚本的方式请求网页内容;
3)网页解析模块,从杂乱无章的下载的网页源码内容中利用正则表达式提取出设定的目标结构化数据。如,获取某网站的在线点评数据,网页解析的目的则是从点评页面源码中获取点评数据的集合,其中点评数据的集合即为最终想要的目标结构化数据;
4)数据排重模块,在本次下载的数据中过滤掉与之前下载重复的数据,并根据数据的重复情况,判断是否继续爬取种子任务;
5)种子任务迭代模块,从种子任务队列取出待下载的种子任务生成待下载任务,并重复上述1)-5)步。
进一步地,步骤1)从数据库中获取所需爬取数据的入口链接,并根据相应的链接拼接规则,拼接网页请求url,生成待下载任务,存入待下载任务队列中。
进一步地,步骤2)所述网页下载包括:下载器调度模块和下载器模块。
进一步地,所述下载器调度模块,用于将待下载任务从待下载任务队列取出,分发给下载器模块,以及接收下载完成任务存入待解析队列;所述下载器模块,接收到待下载任务,发送web请求下载网页数据,存储到mongodb数据库中,并将下载完成任务发送给下载器调度模块。
进一步地,步骤3)所述网页解析包括:解析调度模块和解析模块。
进一步地,所述解析调度模块,用于将待解析任务从待解析任务队列取出,通过nginx负载均衡发送给解析模块,以及接收解析完成任务存入待排重任务队列;所述解析模块,接收到待解析任务,根据任务中信息,在redis中获取解析模板,在mongodb中获取下载网页,解析出目标结构化数据,发送给解析调度模块。
进一步地,所述解析模板用于从下载网页内容中提取出目标结构化数据,由正则表达式集合组成的xml格式的文件,其中每个正则表达式均可从下载的网页内容中匹配出目标结构化数据的一个属性。由于各个网站的网页结构各不相同,且从每个网站上抓取的数据也不尽相同,每个网站均有与之相对应的解析模板。因此数据爬取的过程需要根据网页结构和目标结构化数据的数据结构确定出解析模板的内容,然后再利用解析模板对该网页进行解析。
进一步地,步骤4)所述数据排重包括:排重调度模块和排重模块。
进一步地,所述排重调度模块,用于将待排重任务从待排重任务队列取出,通过nginx负载均衡发送给排重模块,并接收排重完成任务。最终将排重完成任务存入排重完成队列,新下载数据添加到对应数据存储队列,种子任务添加到种子任务队列;所述排重模块,接收到待排重任务,根据任务中信息,在redis中获取排重模板,过滤重复数据,并判断是否继续下载种子任务,发送给排重调度模块。
进一步地,所述排重模板用于表示不同网站数据过滤重复数据和种子任务是否继续下载的规则。
进一步地,步骤4)所述种子任务迭代,将种子任务队列中种子任务生成待下载任务,存入待下载任务队列。
本发明的有益效果如下:
本发明提出的一种分布式的聚焦爬虫系统,能够支持多种类型的网页请求方式,结构化数据解析配置灵活。爬取过程模块化、职能化,大大提升数据抓取效率,具有高度的内聚性和透明性。
附图说明
图1是本发明实施例的爬虫系统的架构图。
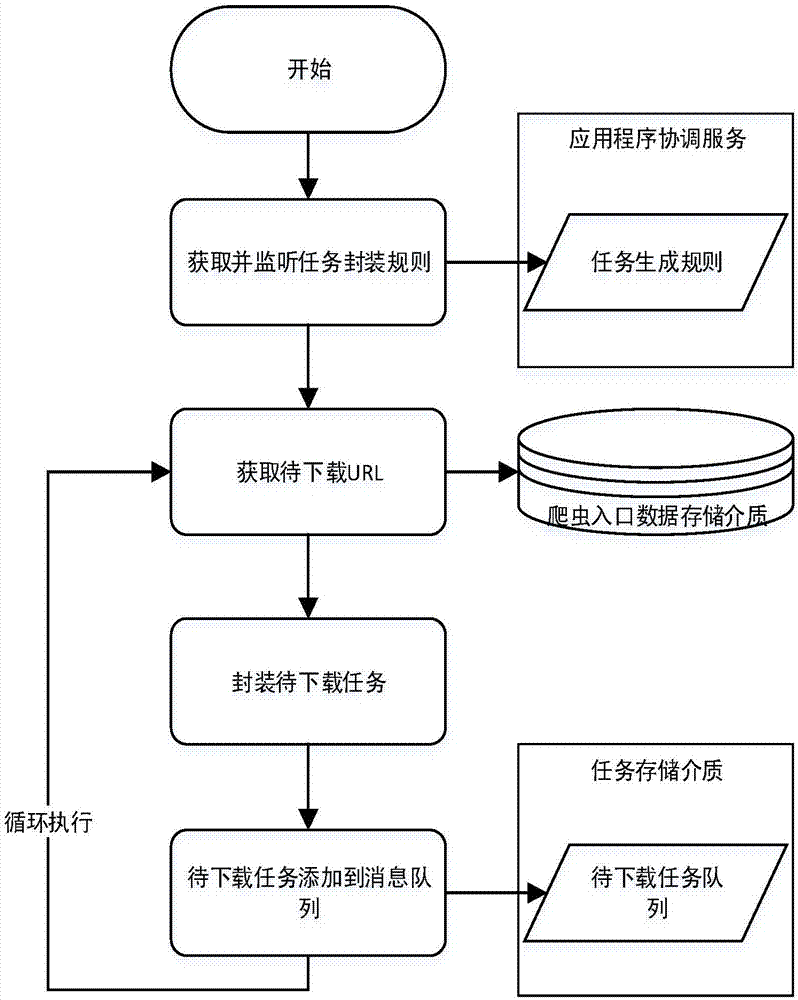
图2是本发明实施例的爬虫系统任务生成模块的流程图。
图3是本发明实施例的爬虫系统网页下载模块的架构图。
图4是本发明实施例的爬虫系统网页解析模块的架构图。
图5是本发明实施例的爬虫系统数据排重模块的架构图。
图6是本发明实施例的爬虫系统种子任务迭代模块的流程图。
具体实施方式
下面通过具体实施例和附图,对本发明做进一步说明。
图1是本发明实施例的爬虫系统的架构图。如图1所示,爬虫系统总共分为任务生成模块、网页下载模块、网页解析模块、数据排重模块、种子任务迭代模块5个功能模块协作完成网页爬取工作,模块之间采用kafka消息队列实现模块解耦的目的。kafka消息队列只是一种存储任务的存储介质,对本领域的技术人员来说,其它存储介质也能达到相同的目的和效果。例如,mq存储消息队列、redis数据库,但是kafka在吞吐量、扩展性、可用性等方面具有明显优势。另一方面,本发明中的爬虫系统兼容各个网站,对不同的网站具有不同的任务生成规则、网页下载规则、网页解析规则、数据排重规则,本发明中爬虫系统将所有规则存储在zookeeper中。zookeeper是一个分布式的应用程序协调服务,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。本发明中爬虫系统将各类规则存储在zookeeper,一旦网站改版,规则发生变更,zookeeper能立即推送新规则到爬虫系统中,保证了数据抓取的稳定性。
图2是本发明实施例的爬虫系统任务生成模块的流程图。如图2所示,网站数据需要爬取时,任务生成模块便将网站起始url根据任务生成规则创建成待下载任务,存入待下载任务队列中。数据爬取过程中,会发现有些目标数据是异步请求的,爬取此类数据时,本发明中爬虫系统需要使用异步请求的ajaxurl下载网页,因此引入任务生成规则,用于将待爬取的网站起始url转换成请求数据的ajaxurl。
以抓取**网站x酒店点评为例,x酒店url为http://hotel.***.com/city/beijing_city/dt-x/,而该酒店点评数据异步加载的ajaxurl为http://review.***.com/api/h/x/detail/v1/page/1,爬取该网站点评数据时,任务生成模块需将x酒店url转换成点评数据异步加载的ajaxurl。对应的任务生成规则及描述(如表1)如下所示:
表1为规则描述表
图3是本发明实施例的爬虫系统网页下载模块的架构图。如图3所示,网页下载模块包含下载器调度模块和下载器模块,下载器调度模块有且仅能存在一个,下载器模块则可根据网页下载模块的负载情况任意添加。下载器调度模块启动后,首先收集zookeeper中的可用下载器模块,再从待下载任务队列获取待下载任务,依次分发给可用下载器模块,并接收下载器模块下载完成的任务,添加到待解析任务队列。为防止爬取过程中web请求被目标网站禁止,每个下载器模块请求同一个网站均有一个最大并发上限,也就是说当下载器a访问***网站并发数达到上限时,下载器调度模块会将其余访问***网站的任务分发给另一个并发数未达到上限的下载器模块。本发明实施例的爬虫系统,采用限制访问各个网站的最大并发数的机制,实现网页下载模块的负载均衡。下载器模块启动后,将自身信息注册到zookeeper中,从而达到通知下载器调度模块的目的,下载器调度模块监听到下载器模块注册的信息,便将待下载任务分发给该下载器,下载器模块则会接收到待下载任务,并根据特定的方式发送请求,下载网页存储于mongodb中,最后将任务完成情况发送给下载器调度器。
本发明实施例爬虫系统中的下载器调度模块和下载器模块,二者之间采用socket通信机制,大大降低了网络传输成本。下载器模块启动时将自身信息注册到zookeeper中,从而通知下载器调度模块,并且利用zookeeper的心跳检测机制,检测下载器模块运行状态,一旦下载器模块停止运行,下载器调度模块通过zookeeper立即监听到,便不再给该下载器模块分发待下载任务,从而保证了系统的稳定性。
本发明实施例的下载器模块一方面能够支持普通http请求方式下载网页,另一方面也是不同寻常之处,则是采用selenium自动化测试技术调用chrome、firefox、phantomjs浏览器或伪浏览器的方式下载网页。另外,还能自动执行页面中js代码生成请求cookie或token,以及对请求参数加密或是响应数据解密操作。
图4是本发明实施例的爬虫系统网页解析模块的架构图。如图4所示,网页解析模块包含解析调度模块和解析模块,解析调度模块和解析模块两个模块之间通过nginx负载均衡实现任务调度,解析调度模块和nginx仅需部署一个,解析模块可根据系统压力部署多个。解析调度模块从待解析任务队列取出待解析任务,通过nginx负载均衡分发给解析模块,待任务处理完成后接收解析结果,添加到待排重任务队列。解析模块启动时获取并监听zookeeper中各个网站的数据解析模板,接收到待解析任务后,在mongodb中获取该任务对应的网页内容,利用相应的解析模板将网页内容转换成结构化的目标数据,返回给解析调度模块。
本发明实施例爬虫系统的网页解析模块采用nginx做负载均衡,能持续保持低资源低消耗高性能高并发,并且具备安装简单、配置容易,bug极少,启动方便等优点,更重要的是保证不间断服务的情况下对服务进行版本升级。
本发明实施例爬虫系统的网页解析将解析模板存储于zookeeper中,解析模块对zookeeper中的解析模板达到实时监听,从而能够在网站改版后,无需中断服务立即更新系统中的解析模板,保证了数据抓取的稳定性,同时也大大降低了系统的运维成本。
解析模板示例及说明(如表2)如下所示:
表2为规则介绍表
图5是本发明实施例的爬虫系统数据排重模块的架构图。如图5所示,数据排重模块包含排重调度模块和排重模块,排重调度模块和排重模块两个模块之间通过nginx负载均衡实现任务调度,排重调度模块和nginx仅需部署一个,排重模块可根据系统压力部署多个。排重调度模块从待排重任务队列取出待排重任务,通过nginx负载均衡分发给排重模块,待任务处理完成后接收排重结果,并将排重结果拆分成排重完成任务、需要存储数据、需要继续抓取种子任务,分别添加到排重完成任务队列、数据存储队列、种子任务队列。排重模块启动时获取并监听zookeeper中各个网站的数据排重规则,接收到待排重任务后,利用相应的排重规则生成该网站数据具有唯一性的hash值,并利用mongodb排重数据库中查找该hash值是否存在,若存在则说明该网站的数据曾经爬取过,需要过滤掉;若不存在则说明该数据从未爬取过,需要同排重完成任务一并返回给排重调度模块。另外,排重模块还会计算本次爬取到的数据与存储队列中已存储数据的重复率,从而决定是否继续爬取种子任务。如果重复率较低,需将种子任务同排重完成任务一并返回给排重调度模块。
本发明实施例爬虫系统的数据排重模块采用nginx做负载均衡,优势与解析模块相同。
本发明实施例爬虫系统的数据排重将排重规则存储于zookeeper中,排重模块能够对zookeeper中的排重规则达到实时监听,从而能够在网站改版后,变更数据唯一标识计算方法时,无需中断服务立即更新系统中的排重规则,保证了数据抓取的稳定性,同时也大大降低了系统的运维成本。
排重规则示例及说明(如表3)如下所示:
表3为规则介绍表
图6是本发明实施例的爬虫系统种子任务迭代模块的流程图。当种子任务队列中存在需要爬取的种子任务时,种子任务迭代模块便将种子任务根据任务生成规则创建成待下载任务,存入待下载任务队列中。此过程任务生成规则与任务生成模块中介绍的任务生成规则一致。种子任务可以是原任务请求页面中的url,也可以由ajaxurl拼接生成,如http://review.***.com/api/h/x/detail/v1/page/1请求回结果为json结构,种子任务无法从请求结果中获取,需通过任务生成规则获取到种子任务http://review.***.com/api/h/x/detail/v1/page/2。
本发明的分布式聚焦爬虫,整个数据爬取过程分成五个模块,处理过程模块化、职能单一化,且模块之间采用kafka消息队列解耦,任务处理时利用nginx负载均衡,大大提高爬虫系统的效率。数据下载时既能支持普通http请求又能兼容chrome、firefox、phantomjs浏览器或伪浏览器请求网页,与此同时还可以自动执行页面中js代码获取http请求参数。另外解析模板和排重规则均存储于zookeeper中,系统能够实时监听规则变化,无需中断服务便能立即更新系统内存中数据,保证了数据抓取的稳定性,同时也大大降低了系统的运维成本。
以上所述仅为本发明的优选实施例,并不用于限制本发明,对于本领域技术人员而言,本发明可以有各种改动和变化。凡在本发明的原理之内所作的任何修改、替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!