基于峰值阈值、旋转校准和混合特征的纺织品瑕疵检测方法与流程
本发明涉及纺织品瑕疵检测技术领域,特别是涉及一种基于峰值阈值、旋转校准和混合特征的纺织品瑕疵检测方法。
背景技术:
传统的纺织品瑕疵人工识别准确率只有60-75%(参见文献:k.srinivasan,p.h.dastoor,p.radhakrishnaiah,etal..fdas:aknowledge-basedframeworkforanalysisofdefectsinwoventextilestructures,j.text.inst.83(1992)431–448.),机器自动识别纺织品瑕疵的方法具有实际应用需求。平坦纺织品表面的数字图像采样(以下简称纺织品图像)属于二维纹理,二维纹理已被证明可根据17种壁纸群(wallpapergroup)定义的图案排列方法生成(参见文献:h.y.t.ngan,g.k.h.pang,n.h.c.yung.motif-baseddefectdetectionforpatternedfabric,patternrecognit.(2008)1878–1894.),用于生成二维纹理的图案称为图格(lattice)(参见:https://en.wikipedia.org/wiki/wallpaper_group),图格内部图案称为motif。多数纺织品瑕疵自动检测方法只能处理墙纸群中p1类型的纺织品图像(参见文献:h.y.t.ngan,g.k.h.pang,n.h.c.yung.automatedfabricdefectdetection—areview,imageandvisioncomputing29(7)(2011)442–458.),仅有少数方法能处理p1类型以外的纺织品图像(参见文献:h.y.t.ngan,g.k.h.pang,n.h.c.yung.motif-baseddefectdetectionforpatternedfabric,patternrecognit.(2008)1878–1894.),例如基于小波预处理的基准图像差分方法(wavelet-pre-processedgoldenimagesubtraction,以下简称wgis)(参见文献:h.y.t.ngan,g.k.h.pang,n.h.c.yung,etal.,waveletbasedmethodsonpatternedfabricdefectdetection,patternrecognit.38(4)(2005)559–576.),共生矩阵方法(参见文献:c.j.kuo,t.su,grayrelationalanalysisforrecognizingfabricdefects,text.res.j.73(5)(2003)461–465.),布林带方法(bollingerbands,以下简称bb)(参见文献:h.y.t.ngan,g.k.h.pang,novelmethodforpatternedfabricinspectionusingbollingerbands,opt.eng.45(8)(2006)087202-1–087202-15.),规则带方法(regularbands,以下简称rb)(参见文献:h.y.t.ngan,g.k.h.pang,regularityanalysisforpatternedtextureinspection,ieeetrans.autom.sci.eng.6(1)(2009)131–144.),elo评估方法(eloratingmethod,以下简称er)(参见文献:c.s.c.tsang,h.y.t.ngan,g.k.h.pang,fabricinspectionbasedontheeloratingmethod,patternrecognit.51(2016)378–394.)等。尽管这些方法可以处理p1以外的纺织品图像,但它们的计算方法多是建立在基于人工选择的类似格的图案(以下简称图格)之上。例如wgis要求人工选择图格的尺寸和纹理,bb,rb和er要求人工定义图格的尺寸。这些先验知识在一定程度上降低了机器识别纺织品瑕疵的自动化程度。
技术实现要素:
本发明所要解决的技术问题是:为了提高机器识别纺织品瑕疵的自动化程度,本发明提供一种基于峰值阈值、旋转校准和混合特征的纺织品瑕疵检测方法,主要包括设计一种自动分割纺织品图像为图格的方法以及基于图格并混合特征提取方法hog、glcm和gabor相结合的瑕疵识别方法。
为使陈述清楚明了,现集中定义本发明所涉及的部分符号和概念。
若
{ai}表示由索引i确定的由元素ai组成的集合或多重集。
|s|表示集合s中的元素个数,若s为向量,则|s|表示向量所含元素个数,|s|称为向量长度。
avg(s)或mean(s):计算集合或多重集s的均值,s的元素均为实数。
std(s):计算集合或多重集s的标准差,s的元素均为实数。med(s):计算集合或多重集s的中位值,s的元素均为实数。mod(s):计算多重集s的众数,s的元素均为实数。max(s)表示找出集合或多重集s的元素最大值,例如max(ic)代表ic中像素的最大灰度值。max(s「条件)表示找出符合条件的
argmaxsf(s)表示在函数f的定义域内变量s的取值范围中,使得函数f(s)取最大值的s。
argminsf(s)表示在函数f的定义域内变量s的取值范围中,使得函数f(s)取最小值的s。
argmaxsf1(s),2(s)表示在函数f1和f2的定义域交集内变量s的取值范围中,使得函数f1(s)和f2(s)取最大值的s。
argmodi({ai})表示对应多重集{ai}众数mod({ai})的索引。
dimx(i)表示二维图像i的总行数,dimy(i)表示i的总列数。
图像原点:图像中像素行列索引开始的位置,该位置假设在图像左上角并且值为(1,1)。
i(x,y)表示在二维图像i中具有行列索引(x,y)的像素值。行索引
图像边界:具有行索引dimx(i)的行和列索引dimy(i)的列。
纺织品图像卡通成分ic:对一幅灰度化的纺织品图像,应用基于曲波(curvelet)和离散余弦变换(localdiscretecosinetransform,以下简称dct)的形态成分分析方法(morphologicalcomponentanalysis,以下简称mca)所计算的具有光滑边缘图案的图像称为卡通成分ic,ic是一幅灰度图像。
dct尺寸:mca在图像局部应用dct,即首先将图像划分为不重叠且具有固定大小的矩形区域,然后对每个区域应用dct,矩形区域的大小称为dct尺寸,单位为像素,区域内一行的像素数称为dct尺寸的宽,一列的像素数称为dct尺寸的高。
阈值系数fc:用于二值化ic的参数,该参数由步骤2计算得到。
二值化卡通成分itc:使用fc·max(ic)作为阈值二值化ic所得到的二值图像,其中1表示前景像素,即ic中灰度值不小于阈值的像素,0表示背景像素。itc与ic的行数和列数相同。
横向投影
纵向投影
二值对象质心:itc中二值对象所包含前景像素图像行索引的平均值和列索引的平均值。
图格索引(ir,ic):当图像分割为不重叠的图格后,根据图格在图像中的排列位置,每个图格具有唯一的图格行索引ir和唯一的图格列索引ic,图像中左上角图格索引为(1,1),紧邻该图格的右侧图格索引为(1,2),紧邻索引为(1,1)图格的下侧图格索引为(2,1),依此类推。
图格像素索引:图格由像素组成,因此图格是一副图像,图像原点和像素行列索引的定义也适用于图格像素索引。
图格尺寸:图格所含像素行数与列数。
图格纹理种类:基于图格分割和纺织品灰度图像产生图格纹理的种类,如图9所示,居中的图像根据图格分割产生了5×7个图格,按照图格的纹理,35个图格可分为3类。
图格矩阵:以图格为单位的矩阵,即矩阵中每个元素都是一个图格。如图10所示,每个图像包含2×2的图格,对应一个2×2的图格矩阵,即矩阵中元素索引与图格索引相同。
特征矩阵:使用特征提取方法计算图格矩阵中的每个元素的特征向量,以特征向量为单位组成矩阵,即矩阵中每个元素都是一个图格的特征向量,矩阵中元素索引与其对应的图格在图格矩阵中的索引相同。
训练样本集:n副图像i1,i2…in的分辨率相同,所有图像根据图格分割产生的图格纹理种类及其数量都相同且排列角度均为0°,若图格纹理种类数为
测试样本集:与训练样本集类似,所有图像分辨率相同,且根据图格分割产生的图格纹理种类及其数量都相同,每幅图像图格的排列方式与训练样本集定义中描述的一致,与训练样本集不同的是,测试样本集中的图像含有位置随机且纹理不属于图格纹理种类的不规则区域,该区域定义为瑕疵。测试样本集中的图像称为测试样本。
特征提取方法名称有序集合t:表示特征提取方法f1,f2…f|t|的名称集合,例如t={hog,lbp},那么|t|=2且f1表示hog方法,f2表示lbp方法。
maxx(a)表示包含行列索引(x,y)的集合a中,行索引x的最大值。minx(a)表示包含行列索引(x,y)的集合a中,行索引x的最小值。maxy(a)表示包含行列索引(x,y)的集合a中,列索引y的最大值。miny(a)表示包含行列索引(x,y)的集合a中,列索引y的最小值。
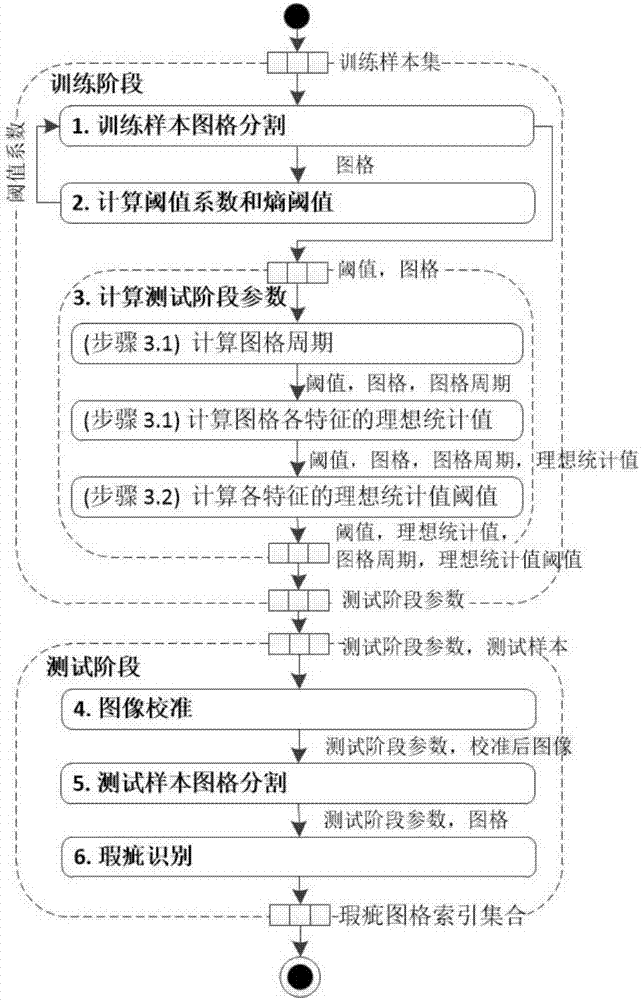
在以上定义的基础上,本发明解决其技术问题所采用的技术方案是:一种基于峰值阈值、旋转校准和混合特征的纺织品瑕疵检测方法,包括两个阶段:训练阶段和测试阶段。训练阶段根据一系列无瑕疵纺织品图像(以下简称无暇图像)分割图格并计算瑕疵识别所需参数;测试阶段根据训练阶段得到的参数对一副纺织品图像进行图格分割并判断图格是否包含瑕疵,最后标记含有瑕疵的图格。本发明方法假设纺织品图像具有如下特点:相对于纺织品图像的行和列,图格依图像行的方向横向排列,并按列的方向纵向排列;在mca的卡通成分ic中,图格具有几何形状并与背景像素在灰度上有显著差异。
训练阶段包含三个步骤:步骤1训练样本图格分割,步骤2计算阈值系数和熵阈值,步骤3计算测试阶段参数。测试阶段包含三个步骤:步骤4图像校准,步骤5测试样本图格分割和步骤6瑕疵识别。
步骤1训练样本图格分割。对于一个训练样本,使用形态学成分分析方法(mca,出自文献jial.,liangj.,fabricdefectinspectionbasedonisotropiclatticesegmentation,journalofthefranklininstitute354(13)(2017)5694-5738)计算训练样本卡通成分ic,使用阈值fc·max(ic)二值化ic得到二值图像itc,由moore-neighbor跟踪算法(moore-neighbortracingalgorithm,出自文献jial.,liangj.,fabricdefectinspectionbasedonisotropiclatticesegmentation,journalofthefranklininstitute354(13)(2017)5694-5738)获取itc中对象的闭合边缘。对于每个具有闭合边缘的对象,找出该对象行列索引的极值,如果该对象行索引极值之差的绝对值超过0.75·dimx(itc),或列索引极值之差的绝对值超过0.75·dimy(itc),则从itc中删除该对象。统计itc每行和每列的背景像素个数,按行和列的索引分别排列背景像素个数构成背景像素的横向投影
其中xi∈s′h,i为数值连续的正整数。作为图格分界集合sh的初始值,其定义如下。
类似地,可以计算
根据理想行数
其中
步骤2计算阈值系数和熵阈值。对于训练样本集i1,i2…in和n′个fc的可选值c1,c2…cm,根据其中任意训练样本ii(i=1,2…n),通过步骤1可计算n′个理想行数
对于ii,如果ch(i,l)与cv(i,l)相同,则相应索引(i,l)保存在集合
对于每个
其中ch(i,l)的索引
步骤3计算测试阶段参数。该步骤具体包括以下三个步骤:步骤3.1计算图格周期;步骤3.2计算图格各特征的理想统计值;步骤3.3计算各特征的理想统计值阈值。
步骤3.1计算图格周期。对于训练样本集i1,i2…in中的第i(
步骤3.2计算图格各特征的理想统计值。该步骤包括四个子步骤:步骤3.2.1计算特征统计值,步骤3.2.2计算特征统计值排序,步骤3.2.3计算稳定特征元素,步骤3.2.4计算理想统计值。
步骤3.2.1计算特征统计值,根据步骤3.1计算训练样本集i1,i2…in的图格周期t。对于第i个训练样本ii,根据步骤2分割ii得到图格
其中
步骤3.2.2计算特征统计值排序。计算训练样本i1,i2…in之间基于fj的
对于f1,f2…f|t|,可得对应的d(1),d(2)…d(|t|)。对于第k类图格纹理和第j个特征提取方法fj(即固定索引k和j),根据i1,i2…in,步骤3.2.1可产生n个
若
对于索引k和j的所有固定组合,对于每个
步骤3.2.3计算稳定特征元素。对于第k类图格纹理和第j个特征提取方法fj(即固定索引k和j),根据上述步骤和i1,i2…in计算的n个
将s(j,k)(if)按索引if升序排列则得到第k类图格纹理基于fj的稳定值向量s(j,k)。若参数nf表示预定义的最小特征向量长度,那么当nf<fj成立时,应用自适应聚类算法对s(j,k)(1),s(j,k)(2)…s(j,k)(fj)进行聚类,若将自适应聚类算法产生的类别按从1开始的正整数依次编号,第if个稳定值s(j,k)(if)所属类别编号记为ls(if),则这些编号定义集合ls。若定义预设参数最小特征数
步骤3.2.4计算理想统计值。对于第k类图格纹理和第j个特征提取方法fj(即固定索引k和j),根据上述步骤和i1,i2…in可计算
步骤3.3计算各特征的理想统计值阈值。根据训练样本集和上述步骤,可计算基于第j个特征提取方法fj的第k类图格纹理的第iu个子类图格纹理的理想统计值
对于
对于索引j,k和iu的所有固定组合,重复上述
步骤4图象校准。对于图格排列角度未知的测试样本i,使用canny边缘检测方法计算i的边缘,使用hough变换将边缘投影到参数空间中,取参数空间中前nθ个峰值所对应的直线斜率的角度θ,根据所取θ旋转i,得到nθ个旋转图像,根据每个旋转图像的
步骤5测试样本图格分割。对步骤4产生的校准结果,根据步骤2得到的阈值系数重复步骤1得到测试样本校准结果的行分割位置
步骤6瑕疵识别。对测试样本的任意图格
其中阈值系数
本发明的有益效果是:本发明提供的一种基于峰值阈值、旋转校准和混合特征的纺织品瑕疵检测方法,该方法分析基于照明光源下平坦纺织品表面的数字图像像素灰度信息,将图像分割为互不重叠的网格,计算每个网格的irm,hog,glcm和gabor特征值,根据特征值分布自动定位纺织品表面瑕疵。本发明特别适用于自动识别在稳定照明光源下采集的纺织品平坦表面灰度数字图像中的纺织品表面瑕疵。
附图说明
下面结合附图和实施例对本发明作进一步说明。
图1是本发明的总流程示意图;图2是本发明的假设条件示意图;图3是本发明的步骤1训练样本图格分割的流程示意图;图4是本发明的步骤1中计算sh初始值的基本原理示意图;图5是本发明的步骤2中纹理相同但方向各异的纺织品图像背景像素分布示意图;图6是本发明的步骤4中图像校准示意图;图7是本发明的步骤4中图像旋转示意图;图8是本发明的步骤3.1中计算图格周期流程示意图;图9是本发明的步骤3.2.1中计算每个无暇纺织品灰度图像的特征统计值流程示意图;图10是本发明的步骤3.2.2中训练样本集示意图;图11是本发明的步骤3.2.2中排序流程示意图;图12是本发明的步骤3.3中计算各特征的理想统计值阈值流程示意图;图13是本发明的步骤6中瑕疵识别过程示意图;图14是步骤1图格分割算法流程图;图15是步骤2计算阈值系数和熵阈值算法流程图;图16是步骤3.1计算图格周期算法流程图;图17是算法a.1计算特征矩阵算法流程图;图18是算法a.2计算距离算法流程图;图19是算法a.3计算信号周期算法流程图;图20是步骤3.2.1计算特征统计值算法流程图;图21是步骤3.2.2计算特征统计值排序算法流程图;图22是步骤3.2.3计算稳定特征元素算法流程图;图23是步骤3.2.4计算理想统计值算法流程图;图24是步骤3.3计算各特征的理想统计值阈值算法流程图;图25是步骤4图像校准算法流程图;图26是算法a.4图像旋转算法流程图;图27是步骤6瑕疵识别算法流程图。
具体实施方式
现在结合附图对本发明作详细的说明。此图为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
本发明计算方法的实施方式由编写计算机程序完成,具体实施过程涉及的自定义算法由伪代码描述。程序输入为灰度化的纺织品图像,程序输出为含瑕疵的图格集合。本发明的实施方案包括六个步骤,前三个步骤为训练阶段,后三个步骤为测试阶段。
所述训练阶段包括以下步骤:步骤1:使用形态学成分分析方法计算训练样本卡通成分ic,将ic按索引所在的行与列进行分割,获得训练样本图格;步骤2:根据步骤1中获得的训练样本图格,计算任意训练样本的理想行数和理想列数,以获得阈值系数,然后根据训练样本的横向投影和纵向投影计算熵阈值,重复上述步骤以计算得到所有训练样本的阈值系数和熵阈值;步骤3:对于训练样本集中任一训练样本,根据步骤2中所计算的阈值系数和熵阈值,采用hog特征提取方法计算图格的特征向量,由特征向量计算距离矩阵,将距离矩阵经过傅里叶变换得到计算图格周期;根据图格周期计算图格各特征的理想统计值;
所述测试阶段包括以下步骤:步骤4:图像校准,对于图格排列角度未知的测试样本,使用canny边缘检测方法计算测试样本的边缘,使用hough变换将边缘投影到参数空间中,取参数空间中前nθ个峰值所对应的直线斜率的角度θ,根据所取θ旋转测试样本,得到nθ个旋转图像,根据每个旋转图像的横向投影和纵向投影计算横向投影熵和纵向投影熵的最大值对应的角度
如图2所示,本发明方法假设纺织品图像具有如下特点:相对于纺织品图像的行和列,图格依图像行的方向横向排列,并按列的方向纵向排列;在mca的卡通成分ic中,图格具有几何形状并与背景像素在灰度上有显著差异。图2中显示三种情况,每一行显示了一种情况,每行第一列是纺织品图像,第二列是ic,第三列是ic的三维mesh图,第四列是二值化卡通成分每行背景像素的个数分布,第四列图的横坐标是行索引,纵坐标是背景像素个数。图2中第一行纺织品图像的图格没有几何形状,这导致了背景像素分布缺乏明显的周期性;第二行纺织品图像的图格虽然有几何形状,但图格中的形状与背景在ic中的差异小,即相应的mesh图大部分区域几乎是平坦的,这导致背景像素数量过多,背景像素分布缺乏明显的周期性;第三行纺织品图像图格具有几何形状并在ic中与背景的差异大,其背景像素分布具有周期性。
以下分别对这六个步骤展开说明。
1、训练阶段
如图1所示,训练阶段首先根据一系列无暇纺织品灰度图像计算图格分割所需参数,而后对无暇图像进行图格分割并计算测试阶段所需参数。训练阶段包含三个步骤:步骤1训练样本图格分割,步骤2计算阈值系数和熵阈值,步骤3计算测试阶段参数。本发明提出的图格分割方法根据步骤2得到的参数,通过步骤1分割图格。
步骤1训练样本图格分割。如图3所示,对于一幅给定的纺织品图像,根据如图14所示的图格分割算法,使用mca计算ic和纹理成分,根据如图15所示的计算阈值系数和熵阈值的算法,计算得到的阈值系数fc,使用阈值fc·max(ic)二值化ic得到itc。图3中显示了ic的mesh图,ic中的二维图案在mesh图中显示为三维“山峰”,二值化ic相当于用一个灰色平面截断山峰,山峰平面上方的部分所对应的像素保存为1,山峰平面下方的部分所对应的像素保存为0,这个二值化结果为itc,即图3右下方箭头“使用阈值二值化ic得到itc”所指的图案。
假设纺织品图像至少由4个图格构成,那么itc中对应图格的对象尺寸应小于图像尺寸的一半,因此如果出现了尺寸过大的情况,那么这个对象则不是图格,应从itc中删除尺寸过大的对象,即:由moore-neighbor跟踪算法(moore-neighbortracingalgorithm,出自文献jial.,liangj.,fabricdefectinspectionbasedonisotropiclatticesegmentation,journalofthefranklininstitute354(13)(2017)5694-5738)获取itc中对象的闭合边缘。对于每个具有闭合边缘的对象,找出该对象行列索引的极值,如果该对象行索引极值之差的绝对值超过0.75·dimx(itc),或列索引极值之差的绝对值超过0.75·dimy(itc),则从itc中删除该对象,即将尺寸过大的对象的像素置为0。
纺织品图像图格的几何形状被itc中的二值对象所描述,图格的丰富多样导致了二值对象几何形状的多样性,但二值对象之间背景像素的分布受其形状影响小,即:不同形状的二值对象,如果其沿相同方向的分布相同,那么背景像素在该方向上的分布相似。如图3所示,统计二值化卡通成分每行和每列的背景像素个数,按行和列的次序分别排列背景像素个数即构成了背景像素的横向投影
为获取这些峰值而过滤其他峰值,对
由于数据的随机性,
由于瑕疵等因素的干扰,s′h和s′v中的行列索引不一定准确反映图格的分界。因此,需要评估s′h中是否存在具有稳定行间距的行索引,以及s′v中是否存在具有稳定列间距的列索引,这些行列索引作为图格的分界以分割图格。对于s′h,将s′h中元素做升序排列,行索引间距的多重集定义为
其中xi∈s′h,i为数值连续的正整数,例如i可以取2,3,4,但不能只取2和4。由于可能存在多个符合
如图4所示,显示了以一副纺织品图像横向投影
类似地,可以计算
因为sh与sv初始值所对应的
其中
步骤2计算阈值系数和熵阈值。图格分割的一个重要参数是阈值系数fc,如图3所示,ic的二值化是基于阈值fc·max(ic)完成,而该阈值取决于fc。对于训练样本集i1,i2…in的ii应用基于不同fc取值的图格分割算法(其流程如图14所示)能得到多个
对于ii,如果ch(i,l)与cv(i,l)相同,则相应索引(i,l)保存在集合
对于每个
其中ch(i,l)的索引
步骤3计算测试阶段参数。该步骤具体包括以下三个步骤:步骤3.1计算图格周期;步骤3.2计算图格各特征的理想统计值;步骤3.3计算各特征的理想统计值阈值。
步骤3.1计算图格周期流程详见图8。根据训练样本集i1,2…in和步骤1.3可计算图格理想尺寸行数
步骤3.2包括四个子步骤:步骤3.2.1计算特征统计值,步骤3.2.2计算特征统计值排序,步骤3.2.3计算稳定特征元素,步骤3.2.4计算理想统计值。
步骤3.2.1计算每个无暇纺织品灰度图像的特征统计值。根据上述步骤计算训练样本集i1,i2…in的图格周期t,即纹理相同图格的排列规律。对于第i
其中
步骤3.2.2计算特征统计值排序。虽然i1,i2…in为同一训练样本集的无暇样本,但训练样本集的定义并不保证每个样本中第一个图格l1,1的纹理相同。如图10所示的训练样本集,该训练样本集包含4副无暇图像i1,i2,i3和i4,其中i3中l1,1的纹理和其它样本中的第一个图格纹理不同。如果所有训练样本的第一个图格的纹理不同,那么步骤3.2.1计算特征统计值就需要重新排序。如图11所示,训练样本集包含训练样本i1,i2,i3,i4,i5和i6,其中i4的l1,1与其它样本的第一个图格纹理不同,导致特征统计值与其它样本的排序也不同。如果所有训练样本的第一个图格纹理都相同,那么排序则没有意义。为了检测排序是否必要,计算训练样本i1,i2…in之间基于fj的
对于f1,f2…f|t|,可得对应的d(1),d(2)…d(|t|),相应地,在完成排序后可再次根据上式计算d′(1),d′(2)…d′(|t|),比较前后两组距离平均值,若d(j)≥d′(j)对于1≤j≤|t|都成立,则保留排序结果,否则恢复排序前的状态。排序流程如图11所示。对于第k类图格纹理的n个
若
对于索引k和j的所有固定组合,对于每个
步骤3.2.3计算稳定特征元素。根据训练样本集中i1,i2…in的t种图格纹理可计算基于fj的n×t组特征统计值,对于第k(
将s(j,k)(if)按索引if升序排列则得到第k类图格纹理基于fj的稳定值向量s(j,k)。若参数nf表示预定义的最小特征向量长度,本方法nf取值为nf=8,那么当nf<fj成立时,应用自适应聚类算法对第k类图格纹理基于fj的fj个稳定值进行聚类,若将自适应聚类算法产生的类别按从1开始的正整数依次编号且第if个稳定值s(j,k)(if)所属类别的编号记为ls(if),则这些编号定义集合ls。若定义预设参数最小特征数
其中δ为狄拉克δ函数,
步骤3.2.4计算理想统计值。对于训练样本集中i1,i2…in的第k(
步骤3.3计算各特征的理想统计值阈值。对于训练样本集中i1,i2…in,根据步骤3.2.4可得到第k(
因此,对于第k类图格纹理基于fj的第iu个子类图格纹理的理想统计值
对于索引j,k和iu的所有固定组合,重复上述
2、测试阶段
在训练阶段得到的参数基础上,测试阶段对测试样本集中的一副图像进行瑕疵检测和定位。测试阶段包含三个步骤:步骤4图象校准,步骤5测试样本图格分割和步骤6瑕疵识别。
步骤4图象校准。对于图格排列角度未知的测试样本i,将i依次旋转θ=1°,2°,3°…360°并计算相应的
上述计算
虽然图像旋转可以通过仿射变换完成,但由仿射变换的图像的边角部分为空,如图7所示。图7中从左往右数依次排列了5幅图像,第一幅显示了图格按37°排列的纺织品图像i,第二副显示了应用仿射变换旋转负37°得到的图像(原始ir),该图像中出现了留空(像素值为0)的4个三角形区域
步骤5测试样本图格分割。对步骤4产生的校准结果,根据步骤2得到的阈值系数重复步骤1得到测试样本校准结果的行分割位置
步骤6瑕疵识别,流程如附图13所示。对于一副给定纺织品灰度图像i,由步骤5产生i的图格,对i中的任意图格
当所有图格基于fj的标记结束,检查每个有瑕疵图格ll的8临域
其中
步骤6流程详见图27所示瑕疵识别算法流程图。
本发明的高效性实验证明:
本发明方法的瑕疵检测效果评估中使用了香港大学电气和电子工程系工业自动化实验室提供的56幅像素大小为256×256的24位彩色纺织品图像,在实验中这些图像被转换为8位的灰度图像。56幅图像包括一种图案:箱形图像。箱形图像包括26幅无瑕疵和30幅有瑕疵图像。对每个有暇纺织品图像使用算法a.4以随机角度生成10幅旋转图像,然后删除存在严重伪影的图像,最终得到251张图格按随机方向排列的有暇纺织品图像作为测试样本集和未经旋转的26张无暇纺织品图像作为训练样本集。训练样本集包括5种瑕疵类型:断端(brokenend),孔洞(hole),网纹(nettingmultiple),粗条纹(thickbar)和细条纹(thinbar),每种瑕疵类型的具体数量详见表1的第一列。所有瑕疵图像都有相同大小的瑕疵基准图(ground-truthimage),瑕疵基准图为2值图像,其中1表示瑕疵,0表示背景。用于比较的算法包括wgis,bb,rb和er,这些算法的参数设置与文献(jial.,liangj.,fabricdefectinspectionbasedonisotropiclatticesegmentation,journalofthefranklininstitute354(13)(2017)5694-5738)相同。本发明方法基于该数据集的参数选择为:最小特征数nf=8,类别数极限nk=5,阈值系数γ=0.93,t={“hog”,“glcm”,“gabor”}。
用于评估的指标包括真阳性(truepositive,以下简称tp),假阳性(positiverate,以下简称fpr),真阳性率(truepositiverate,以下简称tpr),假阳性率(positiverate,以下简称fpr),阳性预测值(positivepredictivevalue,以下简称ppv)和阴性预测值negativepredictivevalue,以下简称npv)。tpr衡量瑕疵基准图中表示瑕疵的像素被算法正确标定为瑕疵的比例,fpr衡量瑕疵基准图中表示背景的像素被算法错误标定为瑕疵的比例,ppv衡量算法输出的瑕疵中瑕疵基准图中的瑕疵所占比例,npv衡量算法输出的背景中瑕疵基准图中的背景所占比例。对于tpr,ppv和npv,指标值越大越好,对于fpr则越小越好。相关数学定义可以在文献(m.k.ng,h.y.t.ngan,x.yuan,,etal.,patternedfabricinspectionandvisualizationbythemethodofimagedecomposition,ieeetrans.autom.sci.eng.11(3)(2014)943–947)中找到。本发明方法,wgis,bb,rb和er的指标计算方法与文献(jial.,liangj.,fabricdefectinspectionbasedonisotropiclatticesegmentation,journalofthefranklininstitute354(13)(2017)5694-5738)相同。实验硬件平台为含处理器intelcoretmi7-3610qm230-ghz和8.00gb内存的笔记本电脑,软件为windows10和maltab8.4。
表1罗列了箱形图像瑕疵检测结果,其中标记瑕疵类型的每行指标值为对应方法对该瑕疵类型所有测试样本运算结果的指标平均值。根据表1概况一栏,本发明方法具有最优的全局tpr(0.724)和全局npv(0.994),其全局tpr比wgis次高的全局tpr(0.558)高很多,但wgis的全局fpr较低。对于孔洞,网纹和细条纹类型的瑕疵,本发明方法的tpr达到最优,同时fpr偏大。断端和粗条纹tpr(0.68;0.85)比wgis(0.98;1.00)低,但fpr(0.2,0.3)比wgis(0.12,0.16)高。综上,本发明方法达到了全局最优tpr和npv,其全局fpr较大,同时本发明方法特别适用于检测箱形图像的孔洞,网纹和细条纹类型的瑕疵。
表1箱形图像瑕疵检测结果
以上述依据本发明的理想实施例为启示,通过上述的说明内容,相关的工作人员完全可以在不偏离本发明的范围内,进行多样的变更以及修改。本项发明的技术范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
- 还没有人留言评论。精彩留言会获得点赞!