面部表情强度计算模型的形成方法及系统与流程
本发明涉及图像处理领域,尤其涉及面部面部表情处理方面,更具体地说,涉及一种面部表情强度计算模型的形成方法及系统。
背景技术:
随着图像处理技术的进步,目前出现了许多方法,能够根据采集到的面部图像,识别面部表情,将表情进行分类:如分为高兴、悲伤以及中间态,再如分为激动、平静,或者分为疑惑、害怕、伤心、吃惊等等。分类的方式很多,但是目前这些方法只能针对表情进行粗略的分类,无法获知表情分类下的具体强度,如有多高兴、多悲伤等等,即未基于表情识别做出表情强度的估计。
技术实现要素:
本发明要解决的技术问题在于,针对上述的目前的方法只能针对表情进行粗略的分类,无法获知表情分类下的具体强度的技术缺陷,提供了一种面部表情强度计算模型的形成方法及系统。
根据本发明的其中一方面,本发明为解决其技术问题,提供了一种面部表情强度计算模型的形成方法,所述面部表情强度计算模型用于估算表情分类下的面部表情强度,包含如下步骤:
s1、获取用于训练的包含面部部分的表情数据库,所述数据库包含具有面部表情强度标签的数据库与无面部表情强度标签的数据库;
s2、对所述表情数据库中的图像数据进行预处理,提取出面部部分的数据;
s3、对提取出的面部部分的数据分别进行面部几何特征、局部二值模式和gabor小波变换三种模式的特征提取;
s4、分别使用全监督模式、半监督模式和无监督模式对步骤s3输出的数据进行训练,得到特征与面部表情强度的关系;
s5、将所述训练后形成的数据分别作为序数随机森林算法的输入进行训练,分别得出面部表情强度计算子模型,将k1*a1+k2*a2+k3*a3作为最终的面部表情强度计算模型,其中系数k1、k2、k3的取值范围均为(0,1),且k1+k2+k3=1,a1、a2、a3分别为同一输入条件下全监督模式、半监督模式和无监督模式对应的输出值。
在本发明的面部表情强度计算模型的形成方法中,步骤s2中预处理包括:面部特征点定位、面部识别、图像剪切和直方图均衡化;方案采用主动形状模型asm获取面部特征点,利用瞳孔间的连线与水平线的夹角,旋转图像使得瞳孔间连线为水平,之后调用opencv库中面部识别框架获取图像数据中面部部分,并且剪切面部区域为m*n像素,最后对所有剪切后图像数据进行直方图均衡化处理;其中,m、n均为正整数且均大于3。
在本发明的面部表情强度计算模型的形成方法中,步骤s3中还包括步骤:采用主成分分析方法,分别对三种模式提取的特征进行处理以降低特征数据的维度。
在本发明的面部表情强度计算模型的形成方法中,步骤s3中对于任意一帧:是以该帧中下巴与鼻尖的像素间距离为标准值,将嘴角、下巴、眼角、上下眼皮之间的像素间的相互距离与标准值的该帧中比值作为面部几何特征。
在本发明的面部表情强度计算模型的形成方法中,步骤s3中采用局部二值模式提取图像特征时,具体是指将步骤s2中提取出的面部部分的数据分割得到的面部图像均匀分为p*q块,得到p*q块(m/p)*(n/q)的区域,对每一区域进行3*3邻域像素的处理,对比所有像素临近的8个像素的灰度值,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0,得到8个二进制数,将8位二进制数转换为10进制,得到该像素点的lbp值,最终按行拼接p*q块图像的lbp值,得到图像的局部二值模式特征;其中,p、q、m、n均为正整数,m、n分别为面部部分的图像数据的横向、纵向的像素大小。
在本发明的面部表情强度计算模型的形成方法中,p=q=5,m=n=10。
在本发明的面部表情强度计算模型的形成方法中,步骤s3中采用gabor小波变换进行特征提取具体是指,将的剪切后形成的m*n像素的面部图像进行多尺度多方向的gabor小波变换,每幅图像得到(v*r)*m*n维的特征,v为尺度数,r为方向数。
在本发明的面部表情强度计算模型的形成方法中,在所述步骤s4的训练过程中:
全监督模式:采用具有表情数据库的强度值标签的unbc-mcmaster肩部疼痛图像数据作为全监督模式的表情数据库,将该unbc-mcmaster肩部疼痛图像数据中原有的0~15级别重新分为0~k共(k+1)种级别进行训练;
半监督模式:采用带标签的数据库以及没强度值注释的数据库作为半监督模式的表情数据库;
无监督模式:采用没强度值注释的extendedck和bu-4dfe图像数据作为无监督模式的表情数据库。
在本发明的面部表情强度计算模型的形成方法中,所述序数随机森林算法中:对于参与训练的数据库中的图像序列中每一帧,首先进行序数回归分析,预测该帧在各个强度值上的分布比,然后在随机森林算法对该图像序列中的帧进行回归分析时,对每个决策树得到的强度值q进行加权,所加权重为该帧在单独进行序数回归分析时,分析结果中强度值q所占的比例。
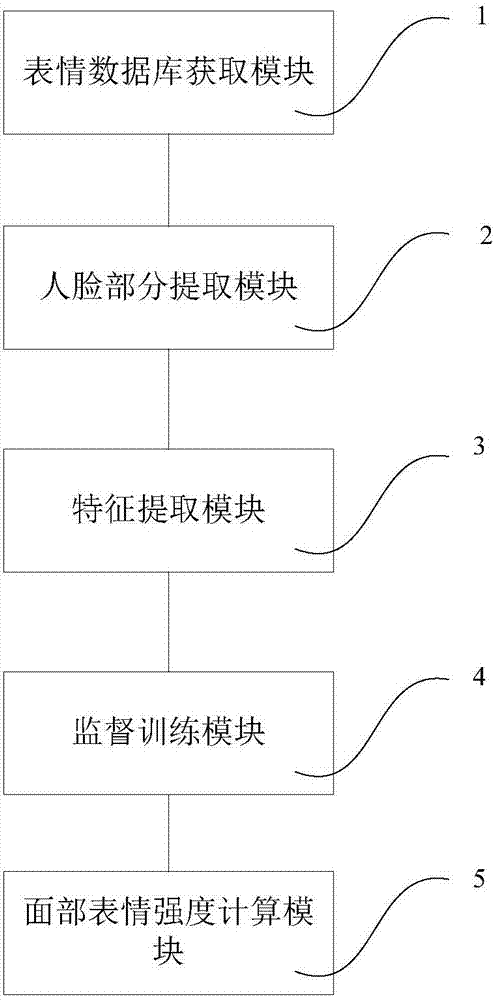
根据本发明的另一方面,本发明为解决其技术问题还提供了一种面部表情强度计算模型的形成系统,所述面部表情强度计算模型用于估算表情分类下的面部表情强度,包含如下模块:
表情数据库获取模块,用于获取用于训练的包含面部部分的表情数据库,所述数据库包含具有面部表情强度标签的数据库与无面部表情强度标签的数据库;
面部部分提取模块,用于对所述表情数据库中的图像数据进行预处理,提取出面部部分的数据;
特征提取模块,用于对提取出的面部部分的数据分别进行面部几何特征、局部二值模式和gabor小波变换三种模式的特征提取;
监督训练模块,用于分别使用全监督模式、半监督模式和无监督模式对特征提取模块输出的数据进行训练,得到特征与面部表情强度的关系;
面部表情强度计算模块,用于将所述训练后形成的数据分别作为序数随机森林算法的输入进行训练,分别得出面部表情强度计算子模型,将k1*a1+k2*a2+k3*a3作为最终的面部表情强度计算模型,其中系数k1、k2、k3的取值范围均为(0,1),且k1+k2+k3=1,a1、a2、a3分别为同一输入条件下全监督模式、半监督模式和无监督模式对应的输出值。
实施本发明的面部表情强度计算模型的形成方法及系统,利用数据库训练出该表情分类下的面部表情强度计算模型,利用该模型对图像数据进行处理,就可以获取该训练完毕的表情分类下的强度。当需要获取多个不同的表情分类下的面部表情强度计算模型时,只需要采用对应的数据库采用本发明的形成方法及系统分别进行训练即可。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明的面部表情强度计算模型的形成方法的一实施例的流程图;
图2是本发明的面部表情强度计算模型的形成系统的一实施例的原理图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
如图1所示,其为本发明的通面部表情强度计算模型的形成方法的一实施例的流程图。本实施例的面部表情强度计算模型的形成方法中面部表情强度计算模型用于估算表情分类下的面部表情强度,包含如下步骤:
s1、获取用于训练的包含面部部分的表情数据库,数据库包含具有面部表情强度标签的数据库与无面部表情强度标签的数据库。在本实施例中,其中表情数据库由unbc-mcmaster肩部疼痛、extendedck、bu-4dfe组成。其中肩部疼痛数据包含200个自发表情序列,并且每帧被标识了疼痛强度值,ck+包含593个表情序列,其中有7种基本表情,但无强度注释,bu-4dfe包含606个图像序列,其中有6种基本表情,也无强度注释。基于这些数据库,可训练出前部疼痛表情下的面部表情强度计算模型。
s2、对表情数据库中的图像数据进行预处理,提取出面部部分的数据。在本步骤中,由于在数据库中图像数据所包含的用户的头部姿势、拍摄光照强度等因素会导致图像质量有差别,因此首先要进行图像预处理,包括面部特征点定位、面部识别、图像剪切和直方图均衡化。方案采用主动形状模型asm获取面部特征点,利用瞳孔间的连线与水平线的夹角,旋转图像使得瞳孔间连线为水平,之后采用opencv库中面部识别框架获取图像中面部部分,并剪切面部区域为100*100像素,最后对所有图像数据进行直方图均衡化处理,以此减弱光照等干扰因素的影响。
s3、对提取出的面部部分的数据分别进行面部几何特征、局部二值模式和gabor小波变换三种模式的特征提取,然后采用主成分分析方法,分别对三种模式提取的特征进行处理以降低特征数据的维度。本实施例对于任意一帧以下巴与鼻尖的距离为标准,将嘴角、下巴、眼角、上下眼皮之间的相互距离与该帧的标准的比值作为面部几何特征;对于任意两帧,其各自的标准值可能相同,也可能不同,具体视每一帧中内容而定。局部二值模式提取图像特征时,将前面步骤分割得到的100*100的面部图像均匀分为5*5块,得到25块20*20的区域,对每一区域进行3*3邻域像素的处理,即对比所有像素临近的8个像素的灰度值,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0,得到8个二进制数,将8位二进制数转换为10进制,得到该像素点的lbp值,最终按行拼接25块图像的lbp值,得到图像的局部二值模式特征。在提取图像gabor小波变换特征时,我们将100*100的面部图像进行5尺度(v=0,1,2,3,4)8方向
s4、分别使用全监督模式、半监督模式和无监督模式对步骤s3输出的数据进行训练,得到特征与面部表情强度的关系。全监督模式是指采用带有强度标签的图像数据作为该模式的表情数据库;半监督模式是指,采用部分带有强度标签部分不带有强度标签的图像数据作为该模式的表情数据库;无监督模式是指,采用不带有强度标签的图像数据作为该模式的表情数据库。在本实施例中,在全监督实验中,采用有强度值标签的unbc-mcmaster肩部疼痛图像数据作为该模式的表情数据库,为了使数据集具有更平衡的强度级别,将该数据中原有的0-15级别重新分为0~5共6种级别,随机选取60%的图像数据作为该模式的表情数据库。在半监督模式中,训练用的表情数据库每个图像序列中平均采用10%的带标签图像进行训练。在无监督试验中,采用没强度值注释的extendedck和bu-4dfe,利用训练用的数据库中的某一帧距离顶点帧的相对距离来计算该帧的相对强度值,具体做法是:图像序列的每一帧均有一个序列号j,将图像序列的起点帧(序列号为1)和顶点帧(序列号为p)的强度分别标识为min和max(本实施例中min=0,max=10),那么图像序列中序列号为j的帧的强度q定义为
s5、将所述训练后形成的数据分别作为序数随机森林算法的输入进行训练,分别得出面部表情强度计算子模型,将k1*a1+k2*a2+k3*a3作为最终的面部表情强度计算模型,其中系数k1、k2、k3的取值范围均为(0,1),且k1+k2+k3=1,a1、a2、a3分别为同一输入条件下全监督模式、半监督模式和无监督模式对应的输出值。在训练表情强度估计模型时,我们秉承了传统机器学习分类方法中的随机森林,将关注图像帧间序列关系的序数回归与随机森林相结合,提出序数随机森林算法。随机森林是由多个决策树组成,每个决策树由强度值信息生成,在回归分析时对每个输入数据得到一个预测值,最终的回归结果为所有决策树预测值的平均值。而序数回归是利用序列的顺序关系进行回归分析,不考虑序列的值(也就是随机森林回归分析时所关心的强度值信息)。本发明将两者结合,对于图像序列中某一帧,首先进行序数回归分析,预测该帧的强度值在min~max之间的分布比,然后在随机森林对图像序列中任意一帧进行回归分析时,对每个决策树得到的强度值q进行加权,所加权重为该帧在单独进行序数回归分析时,分析结果中强度值q所占的比例。本实施例通过寻找最优的参数和回归范围等,训练出了既注重标签信息又注重图像序列关系的模型。
参考图2,其为本发明的面部表情强度计算模型的形成系统的一实施例的原理图。本实施例的面部表情强度计算模型的形成系统中,面部表情强度计算模型用于估算表情分类下的面部表情强度,其包含如下表情数据库获取模块1、面部部分提取模块2、特征提取模块3、监督训练模块4、面部表情强度计算模块5。表情数据库获取模块1用于获取用于训练的包含面部部分的表情数据库,所述数据库包含具有面部表情强度标签的数据库与无面部表情强度标签的数据库;面部部分提取模块2用于对所述表情数据库中的图像数据进行预处理,提取出面部部分的数据;特征提取模块3用于对提取出的面部部分的数据分别进行面部几何特征、局部二值模式和gabor小波变换三种模式的特征提取;监督训练模块4用于分别使用全监督模式、半监督模式和无监督模式对特征提取模块输出的数据进行训练,得到特征与面部表情强度的关系;面部表情强度计算模块5用于将所述训练后形成的数据分别作为序数随机森林算法的输入进行训练,分别得出面部表情强度计算子模型,将k1*a1+k2*a2+k3*a3作为最终的面部表情强度计算模型,其中系数k1、k2、k3的取值范围均为(0,1),且k1+k2+k3=1,a1、a2、a3分别为同一输入条件下全监督模式、半监督模式和无监督模式对应的输出值。各模块的具体工作原理具体可参考上述方法中的实施例,这里不再赘述。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!