一种利用非对称的多面排序网络学习解决社区问答任务的方法与流程
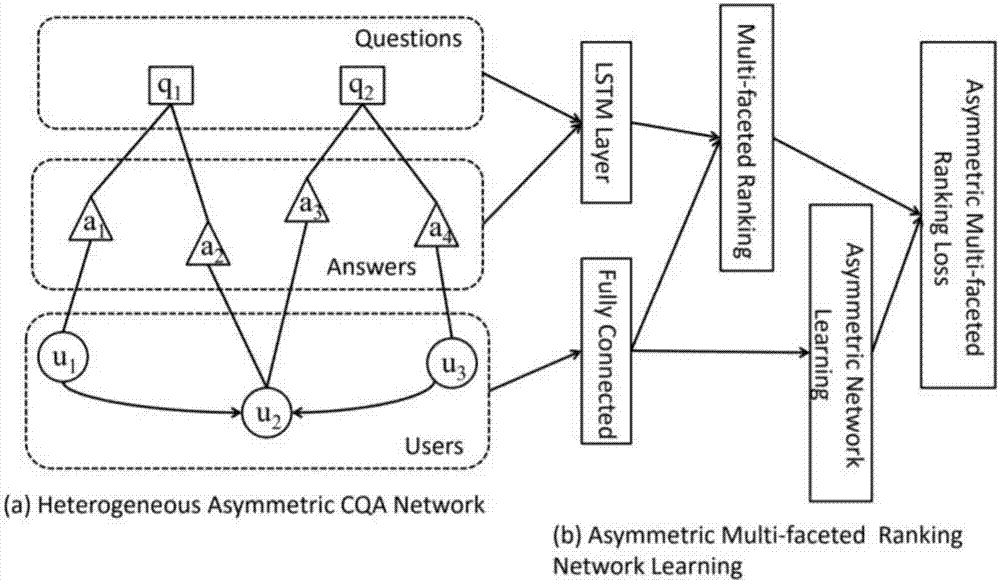
本发明涉及社区问答任务,尤其涉及一种利用非对称的多面排序网络学习解决社区问答任务的方法。
背景技术:
随着以社区为基础的问答网站的蓬勃发展,以社区为基础的问答网站服务已经成为一项重要的网络服务,该服务可以针对于用户提出的问题,让其余用户进行解答并显示在网站上,而针对于每一个问题,通常会有许多用户提出不同的答案,则对于不同答案的排序便成为了该类型网站的重要任务之一,但是目前问答网站中已有该项功能的效果并不是很好。
现有的技术主要是将问题答案匹配作为一种问答语义匹配的任务来做,该方法主要是通过学习出问题与答案的语义表达,从而将与问题相关度最高的答案排在前面,该方法仅仅考虑到了问题与答案的语义关联度,并没有利用到社区问答网站中的用户相互关系。为了克服这个缺陷,本方法将同时利用到问题答案的语义匹配信息与社区网站中的用户关系。
本发明将首先利用已有的用户、问题、答案之间的关系及用户之间的相互关系构建异质的非对称社区问答网络,之后通过LSTM网络来获取问题及答案的语义表达,利用随机初始化得到用户表达,之后结合用户表达及问题答案的语义表达得到关于用户问答语义映射相关性的损失值。之后通过构建的非对称社交问答网络中的用户之间相互关注的关系,得到用户之间相互影响矩阵,并利用该矩阵与用户表达得到反映用户之间相互关系的损失项值。将用户问答语义映射相关的损失值与反映用户相互关系的损失值结合,得到最终的损失目标函数,经过训练,得到最终社区问答网站中问题答案之间的相关程度信息。
技术实现要素:
本发明的目的在于解决现有技术中的问题,为了克服现有技术中仅仅关注到问题答案之间的语义关联程度没有关注到社区问答网站中用户之间相互关系的问题,本发明提供一种利用非对称的多面排序网络学习解决社区问答任务的方法。本发明所采用的具体技术方案是:
利用非对称的多面排序网络学习解决社区问答任务的方法,包含如下步骤:
1、针对于一组社交网络用户及其提出的问题与相关答案,构建包含用户、问题与答案之间相互关系的异质的非对称社区问答网络。
2、利用单词映射网络及LSTM网络获取问题与答案的语义表达,利用随机初始化获取用户的映射表达。之后结合用户表达及问题答案的语义表达获取反映用户问答语义映射相关性的损失值。利用步骤1构建的非对称社区问答网络中的用户之间相互关注的关系,得到用户之间相互影响矩阵,并利用该矩阵与用户表达得到反映用户之间相互关系的损失项值。两者结合得到最终的损失函数。
3、经过训练,得到最终的多面排序标准函数,根据该函数可以对于任意问题及用户提出的答案进行排序,将更适合问题的答案排在前列。
上述步骤可具体采用如下实现方式:
1、对于所给出的用户、用户提出的问题、用户提出的答案及相互之间关系集合,形成异质的非对称社区问答网络。
2、对于所给出的问题、答案,利用如下方法获得每个问题与答案的映射表达:首先利用预训练好的单词映射方法获得问题答案中单词的对应映射,对于问题xi的第t个单词,得到其映射为xit。之后将问题的单词映射序列{xi1,...,xin}作为LSTM的输入,将所有问题的单词全部输入之后,进行训练,将最后一层的输出作为问题的语义表达,记为qi。对于答案yi,将答案中的每一句话的所有单词的单词映射序列{yi1,...,yin}输入到LSTM网络中,将每一句话的最后一层的输出作为该句话的语义表达,之后在该答案的所有句子的语义表达输出上面增加一最大池化层,将最大池化层的输出作为该答案的语义表达,记为ai。
3、通过随机初始化得到用户的映射矩阵U={u1,u2,...,ul},根据步骤1获得的异质的非对称社区问答网络,获得关于问题及相关答案和用户的限制集合R={(i,j,k,o,p)},该集合中的每一条数据(i,j,k,o,p)代表的含义为“针对于问题i而言,由用户k提出的答案j可以比由用户p提出的答案o获得更多的支持,更加符合问题的要求。”
针对于R={(i,j,k,o,p)}中的每一条数据,按照如下公式构建反映用户问答语义映射相关性的损失函数Lr:
其中,c代表提前定义好的权衡最大距离值的参数,0为与进行最大值比较防止结果小于0的限定值;代表高质量答案对应的问答对的多面排序函数,代表低质量答案对应的问答对的多面排序函数,与的计算公式如下:
其中,qi为问题i的对应映射表达,ak为答案k的对应映射表达,uj为用户j的对应映射表达,ap为答案p的对应映射表达,uo为用户o的对应映射表达,M∈Rd*d为用来计算问题与答案映射之间的语义关联程度的排序度量矩阵。
4、根据步骤1获得的异质的非对称社区问答网络中用户之间相互关注的关系,构建非对称的用户相互关系矩阵Sl*l,其中,l为总体的用户数目,且若用户i在社区问答网络中关注了用户j,则sij=1,否则,sij=0。根据步骤1获得的异质的非对称社区问答网络中用户之间相互关注的关系,构建对角矩阵F=diag(|F1|,|F2|,...,|Fl|),对角矩阵中的元素|Fi|代表用户i所关注的用户数目。根据矩阵S与矩阵F构建矩阵W=F-1S。
5、利用步骤4构建的矩阵W与用户的映射U={u1,u2,...,ul},按照如下公式构建反映用户之间相互关系的损失项值:其中,代表2阶范数,wij代表矩阵W的第ij号元素。则再结合步骤3所得到的反映用户问答语义映射相关性的损失函数Lr,得到最终的损失函数如下式所示:
其中,λ为用来平衡反映用户问答语义映射相关性的损失函数与反映用户之间相互关系的损失项的权衡参数。
6、将模型中所有的参数集合设为θ,以如下公式作为最终的目标函数:
其中,α代表模型损失函数与模型参数的权衡参数。本发明采用随机梯度下降的方式对于模型进行优化,且斜率变量以AdaGrad的方法进行更新。
7、经过模型优化之后,得到能够反映一组问题答案对相关程度的多面排序标准函数fM(q,u,a),通过该函数便可比较对于相同问题,不同用户提出的不同答案与该问题的相关程度。
附图说明
图1是本发明使用的利用所给出的用户、用户提出的问题、用户提出的答案及相互之间关系集合,形成的异质非对称社区问答网络的整体示意图。图2是本发明所使用的用来进行社区网络问答的异质非对称多面排序网络示意图。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步阐述和说明。
如图1所示,本发明一种利用非对称的多面排序网络学习解决社区问答任务的方法包括如下步骤:
1)针对于一组社交网络用户及其提出的问题与相关答案,构建包含用户、问题与答案之间相互关系的异质的非对称社区问答网络;
2)利用单词映射网络及LSTM网络获取问题与答案的语义表达,利用随机初始化获取用户的映射表达,之后结合用户表达及问题答案的语义表达获取反映用户问答语义映射相关性的损失值,利用步骤1)构建的非对称社区问答网络中的用户之间相互关注的关系,得到用户之间相互影响矩阵,并利用该矩阵与用户表达得到反映用户之间相互关系的损失项值,两者结合得到最终的损失函数,利用该损失函数进行训练,得到最终的多面排序标准函数;
3)利用步骤2)学习得到的最终的多面排序标准函数对于关于任意问题不同用户提出的对该问题的答案进行相关性排序预测。
所述的步骤2)采用非对称的多面排序网络获得多面排序标准函数,其具体步骤为:
2.1)对于步骤1)获得的异质的非对称社区问答网络,利用其中包含的关于问题及相关答案和用户的限制集合,利用单词映射,LSTM网络训练的方法构建出反映用户问答语义映射相关性的损失函数;
2.2)对于步骤1)获得的异质的非对称社区问答网络,利用其中包含的用户之间的相互关注的关系,构建出反映用户之间相互关系的损失项;
2.3)利用步骤2.1)得到的反映用户问答语义映射相关性的损失函数与步骤2.2)得到的反映用户之间相互关系的损失项得到最终的目标函数,并训练得到最终的多面排序标准函数;
所述的步骤2.1)具体为:
针对于步骤1)获得的异质的非对称社区问答网络,针对于其中的问题、答案,利用如下方法获取其映射表达:
对于所给出的问题、答案,利用预训练好的单词映射方法获得问题答案中单词的对应映射。即对于问题xi的第t个单词,得到其映射为xit,之后将问题的单词映射序列{xi1,...,xin}作为LSTM的输入,将所有问题的单词全部输入之后,进行训练,将最后一层的输出作为问题的语义表达,记为qi。对于答案yi,将答案中的每一句话的所有单词的单词映射序列{yi1,...,yin}输入到LSTM网络中,将每一句话的最后一层的输出作为该句话的语义表达,之后在该答案的所有句子的语义表达输出上面增加一最大池化层,将最大池化层的输出作为该答案的语义表达,记为ai。
之后,通过随机初始化得到用户的映射矩阵U={u1,u2,...,ul},根据步骤1)获得的异质的非对称社区问答网络,获得关于问题及相关答案和用户的限制集合R={(i,j,k,o,p)},该集合中的每一条数据(i,j,k,o,p)代表的含义为“针对于问题i而言,由用户k提出的答案j可以比由用户p提出的答案o获得更多的支持,更加符合问题的要求。”
针对于R={(i,j,k,o,p)}中的每一条数据,按照如下公式构建反映用户问答语义映射相关性的损失函数Lr:
其中,c代表提前定义好的权衡最大距离值的参数,0为与进行最大值比较防止结果小于0的限定值;代表高质量答案对应的问答对的多面排序函数,代表低质量答案对应的问答对的多面排序函数,与的计算公式如下:
其中,qi为问题i的对应映射表达,ak为答案k的对应映射表达,uj为用户j的对应映射表达,ap为答案p的对应映射表达,uo为用户o的对应映射表达,M∈Rd*d为用来计算问题与答案映射之间的语义关联程度的排序度量矩阵。
所述的步骤2.2)具体为:
根据步骤1获得的异质的非对称社区问答网络中用户之间相互关注的关系,构建非对称的用户相互关系矩阵Sl*l,其中,l为总体的用户数目,且若用户i在社区问答网络中关注了用户j,则sij=1,否则,sij=0。根据步骤1获得的异质的非对称社区问答网络中用户之间相互关注的关系,构建对角矩阵F=diag(|F1|,|F2|,...,|Fl|),对角矩阵中的元素|Fi|代表用户i所关注的用户数目。根据矩阵S与矩阵F构建矩阵W=F-1S。之后按照如下公式构建反映用户之间相互关系的损失项值:其中,代表2阶范数,wij代表矩阵W的第ij号元素。
步骤2.3)具体为:
结合步骤2.1)所得到的反映用户问答语义映射相关性的损失函数Lr与步骤2.2)所得到的反映用户之间相互关系的损失项值,得到最终的损失函数如下式所示:
其中,λ为用来平衡反映用户问答语义映射相关性的损失函数与反映用户之间相互关系的损失项的权衡参数。之后将模型中所有的参数集合设为θ,以如下公式作为最终的目标函数:
其中,α代表模型损失函数与模型参数的权衡参数。本发明采用随机梯度下降的方式对于模型进行优化,且斜率变量以AdaGrad的方法进行更新。经过模型优化之后,得到能够反映一组问题答案对相关程度的多面排序标准函数fM(q,u,a)。通过该函数便可比较对于相同问题,不同用户提出的不同答案与该问题的相关程度。
下面将上述方法应用于下列实施例中,以体现本发明的技术效果,实施例中具体步骤不再赘述。
实施例
本发明在社交问答网络Quora上构建实验数据进行实验,并且通过Twitter获取用户之间相互关注的信息。所使用的Quora数据集中共包括444138条问题数据、95915个用户数据和887771条答案数据,并且使用网站中各个答案所获得的点赞与反对数目作为该答案与问题之间相关程度的指标。为了客观地评价本发明的算法的性能,本发明在所选出的测试集中,使用了Precision@1,nDCG,Accuracy这三种评价标准来对于本发明的效果进行评价,且分别针对60%、70%、80%比例的训练数据进行训练并进行实验求解。按照具体实施方式中描述的步骤,不同比例训练数据针对于nDCG标准所得的实验结果如表1所示,不同比例训练数据针对于Precision@1标准所得的实验结果如表2所示,不同比例训练数据针对于Accuracy标准所得的实验结果如表3所示,本方法表示为AMRNL:
表1本发明针对于nDCG标准的测试结果
表2本发明针对于Precision@1标准的测试结果
表3本发明针对于Accuracy标准的测试结果。
- 还没有人留言评论。精彩留言会获得点赞!